

Welche Eigenschaften würden einen Muffin zu einem qualitativ hochwertigen Muffin machen? Sicherlich Schokoladenstreusel oben drauf! Kommen wir direkt zu unserem ersten Vergleich mit der Qualitätssicherung: So wie die Schokolade erst über den fertigen Muffin gestreut wird, so testen wir auch die Qualität von Software erst nach dem Programmieren. Das Problem in beiden Fällen: Es ist keine Schokolade (Qualität) im Muffin (Software).
In diesem Artikel wollen wir uns Methoden und Prozessen zuwenden, die uns zeigen, wie man sich möglichst früh in der Softwareentwicklung um Qualität kümmern kann, oder anders gesagt, wie man die Schokolade direkt in die Muffins einbackt.
Man kann bereits erahnen, dass die unterschiedlichen Methoden und Prozesse das Feld der Quality-Analysten, im Folgenden „QAs”, enorm erweitern (siehe auch [Lin18]), sodass wir aus unserer Rolle als „Qualitätssicherung” heraustreten und wahre „Product Quality Specialists” werden.
Wie Veränderungen im Prozess die Qualität verbessern
Wenn wir uns die Prozessschritte eines typischen agilen Teams genau ansehen, erkennen wir, was dort im Detail vor sich geht.
Im ersten Schritt („Analyse”) planen wir, Wert zu schaffen. Wir schreiben dafür eine Story, die wir dann in einem „Backlog“ ablegen, um nichts weiter damit zu tun. Oder anders formuliert: Wir verschwenden Zeit. Im besten Fall ist eine analysierte Story noch aktuell, wenn sie implementiert wird. Oft sind Storys zu dem Zeitpunkt aber schon veraltet.
Im nächsten Schritt („Development“) fügen wir dann dem Produkt den geplanten Mehrwert hinzu. Danach wartet die Story wieder in einem Prozessschritt „Warten auf QA”, also wird auch hier nur Zeit verschwendet. Das Team wartet, bis ein QA den geplanten Wert überprüft und diesen an die Anwender liefern kann.
Als QAs haben wir wenig Einfluss auf den Prozessschritt „Backlog“, aber „Warten auf QA“ gehört “uns”. Und warum sollten wir einen Prozessschritt im Team haben, in dem lediglich Zeit verschwendet wird? Das Entfernen dieses Schritts hat sehr positive Auswirkungen auf Geschwindigkeit und Qualität, wenn wir sie mit einem anderen Werkzeug koppeln: Work-in-progress-Limits [Rad].
Die Idee lautet wie folgt: Wenn es keinen Prozessschritt „Warten auf QA“ gibt, hat eine Entwicklerin keinen Platz, um eine Story abzulegen und eine neue zu beginnen. Daher muss die Entwicklerin sicherstellen, dass die Story an einen verfügbaren QA übergeben wird. Diese erzwungene Übergabe erleichtert die direkte Kommunikation. Der QA erhält wertvollen Kontext von der Entwicklerin und diese selbst kann mit dem QA überprüfen, ob tatsächlich alle Abnahmekriterien einer bestimmten Story erfüllt sind. Dies ist bereits ein großer Gewinn für die Qualität.
Wir haben Limits in verschiedenen Entwicklungsteams in unterschiedlichen Zusammenhängen angewendet. In einem Fall konnten wir den Zeitraum von „Analyse“ bis „Fertig“ für Storys von 13 Tagen auf 4 Tage verkürzen, ohne dass jemand „härter“ arbeiten musste. Denn weniger Storys im Development erfordern keine ständigen Kontextwechsel. Nacheinander können die Aufgaben schneller abgearbeitet und beendet werden. Die Einschränkung des „Work-in-progress” wirkt sich positiv auf die Konzentration der Teams aus und somit nicht nur auf die Zeit, sondern auch auf die Qualität eines Produktes.
Synergie der Analysten: Wie „Business” und „Qualität” zusammenarbeiten
Um wirklich mit Business-Personen (Business-Analyst, Product Owner oder Product Manager) zusammenzuarbeiten, ist es wichtig, alle beteiligten Perspektiven zu verstehen:
Unsere Business-Analysten (BAs) sind in der Regel sehr darauf bedacht, Software schnell zu veröffentlichen. Denn ein späterer Start eines (Software-) Produkts führt zu höheren Kosten und geringerem Einkommen.
Die Aufgabe der QAs besteht im Gegensatz dazu darin, sicher zu sein, dass ein solides und fehlerfreies Produkt auf den Markt gebracht wird.
Es geht also darum, die goldene Mitte zwischen Geschwindigkeit und Qualität zu finden. Hierzu hat die NASA einmal aufgeschlüsselt, wo genau die meisten Kosten von Fehlern entstehen. In Abbildung 1 ist leicht zu erkennen, wo die Kosten für Fehler im Bereich der Produktion explodieren. Eine typische erste Reaktion besteht darin, alles noch einmal gründlich zu prüfen, bevor es in die Produktion geht. Dies sind die automatisierten Testfälle in unseren CI/CD-Systemen.
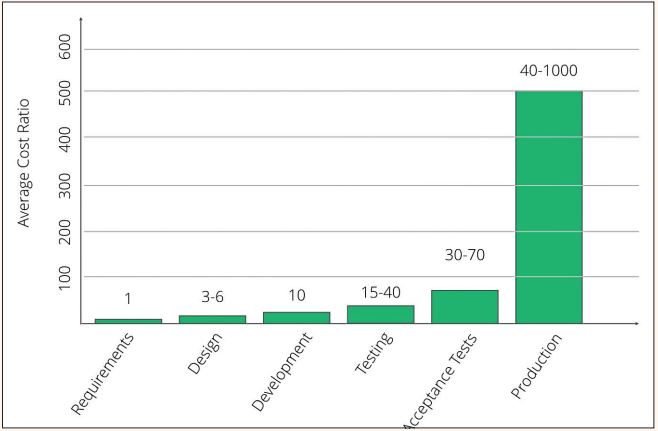
Abb. 1: Kosten von Fehlern in der Softwareentwicklung, Quelle: [NASA]
Bei genauerer Betrachtung legt Abbildung 1 nahe, dass es am günstigsten ist, Fehler frühestmöglich zu beheben und von Anfang an hochwertige Qualität zu liefern. Also während der Analyse und nicht erst während der Tests.
Meiner Erfahrung nach erreicht man das am besten, wenn QAs und BAs tatsächlich neben- einandersitzen und gemeinsam an Anforderungen arbeiten, die sie dann in kurzen Planungsmeetings dem Team präsentieren. Das Wissen über Anforderungen („Edge Cases” und „SadPaths”) kann so bereits vor der Implementierung mit dem ganzen Team geteilt werden. Die QAs können sicher sein, dass die wichtigsten „Sad Paths” bereits in der Implementierung berücksichtigt und automatisiert auf Regression getestet werden.
Auf diese Weise wird der Aufwand für manuelles Testen erheblich reduziert. So führen wir – im Gegensatz zum Code-Freeze-Test unter Zeitdruck – unsere Produkte früher bei gleichzeitig deutlich besserer Qualität auf dem Markt ein.
Sei proaktiv
Idealerweise arbeitet man gemeinsam mit den Entwicklerinnen daran, die Regressionstests von Unit- bis End-to-End-Test nach der Testpyramide zu strukturieren. Allerdings ist es ganz egal, wie ausgeklügelt man diese Tests gestaltet, sie werden immer erst nach der Implementierung ausgeführt.
Um Qualität von Anfang an zu erhöhen, versuchen wir in allen Teams eine einfache Regel anzuwenden: Jeder Commit geht nach Produktion.
Dies bringt ein paar Vorteile mit sich:
Wenn man diese Regel festlegt, erhöht sich die Qualität jedes einzelnen Commits. Denn sobald QAs nicht mehr die letzten Wächter über mögliche Fehler sind, verwenden Entwickler mehr Zeit darauf sicherzustellen, dass ihre Tests die wichtigsten Dinge abdecken. Und da QAs die Experten für Tests sind, wird die Push-and-Pull-Beziehung zwischen Entwicklerinnen und QAs durch diese neue Regel umgekehrt:
Bislang wurden Tickets zu den QAs gepusht, um getestet zu werden. Nun bitten Entwicklerinnen während und insbesondere auch vor der Implementierung um Beratung durch die QAs, wie sie die Tests am besten strukturieren.
Ein zweiter großer Vorteil ist, dass man in Notfällen deutlich handlungsfähiger ist. Normalerweise hat man im klassischen Releasemanagement einen komplizierten Plan, wie ein Release durchgeführt wird. Falls etwas schief geht, gibt es einen Hotfix-Cherry-Pick-Branch-Release-Prozess, der die meisten Sicherheitsmaßnahmen und Qualitätssicherungen umgeht. Das klingt nicht besonders vertrauenserweckend.
In unseren Team-Setups brauchen wir das nicht mehr. Mit Release-Zyklen von 30 Minuten oder weniger können wir sehr schnell ohne Hotfixes oder Branches auf Probleme in der Produktion reagieren.
Die wirklich interessante Frage ist dann, wie man das Monitoring so gestaltet, dass man Probleme früher findet. Dies enthält mindestens die Visualisierung der Fehleranzahl sowie der Server-/Datenbankenantwortzeiten. Wenn man auf ein wirklich professionelles Niveau möchte, kann man über die vollautomatisierte Erkennung von Anomalien nachdenken.
Dadurch haben wir deutlich weniger Probleme mit den Releases, während wir neue Funktionen auf sehr kontrollierte Weise mithilfe von „FeatureTogglen“ [Fow10] aktivieren. So liefern wir nicht nur schnell neuen Wert für unsere Anwender, wir erreichen gleichzeitig auch höhere Qualität.
Wie eine vertrauensvolle Fehlerkultur den ultimativen Qualitätsboost bringt
Jedes Team macht Fehler, das ist menschlich und gut, denn aus Fehlern lernen wir. Da QAs sich außerordentlich viel mit dem Risiko und Einfluss von Fehlern beschäftigen, können sie dem Team helfen, in einer sicheren Umgebung schnell Fehler zu machen – und somit schnell zu lernen. Das wiederum erhöht nicht nur die Sicherheit und das Vertrauen im Team sowie die Qualität der Software, sondern fast nebenbei auch das Innovationspotenzial des Teams.
Eine Methode, die wir sehr intensiv einsetzen – und als QAs vom Team einfordern –, ist das Pair Programming. Es hilft uns insbesondere, kleine Flüchtigkeitsfehler zu vermeiden, den Klassiker sozusagen. Es gibt wahrscheinlich 100 von ihnen in diesem Artikel. Eine effiziente Schadensminderung ist das „Pairing” von zwei Personen, meist Entwicklerinnen.
Flüchtigkeitsfehler sind allerdings nicht die einzige Motivation zum Pairing. Kennen Sie den „Aha-Moment”, den man hat, sobald man etwas einfach mal ausprobieren kann und dadurch versteht, wie etwas funktioniert? Wir versuchen, es dem Team möglichst leicht zu machen, solche Momente durch „Ausprobieren” (= gezielt Fehler provozieren) zu erleben.
Zu guter Letzt gilt es noch sicherzustellen, dass Ihr Team Spaß hat.
„Spaß”, werden Sie fragen – „wirklich?”
Ja: Stellen Sie sich zwei verschiedene Teams vor. In einem Team sind die Menschen sehr begeistert. Sie kommen glücklich zur Arbeit und begrüßen sich am Morgen. Sie kommunizieren und teilen miteinander, woran sie arbeiten, wie und warum. Dann gibt es ein anderes Team, bei dem die Leute es vorziehen, morgens eine To-do-Liste zu erhalten und ansonsten in Ruhe gelassen zu werden.
Was glauben Sie, welches Team ein besseres Produkt bauen wird? Welches Team wird am Ende weniger Fehler machen? Welches Team wird eher eine Deadline halten?
Quality Specialists sind in der Regel das Verbindungsstück zwischen Entwicklerinnen und den Fachbereichen. Wir verbinden die Menschen und deren Perspektiven. Das hilft beim Aufbau einer vertrauensvollen Kultur. Es sind die kleinen Dinge, die eine großartige Kultur ausmachen. Und wir Quality Specialists sind normalerweise mittendrin.
Durch die Kombination einer positiven Teamatmosphäre mit einer starken Zusammenarbeit von QA und BA sowie einer exzellent geformten Testpyramide und einem Prozess, der hilft, Software schnell nach Produktion zu bringen, werden Sie und Ihr Team letztendlich stärker, schneller und solidere Produkte in höherer Qualität liefern.
Referenzen
[Fow10]
M. Fowler, FeatureToggle, 29.10.2010, siehe: https://martinfowler.com/bliki/FeatureToggle.html
[Lin18]
L. Linke, St. Drewes, 3 Schritte in die Cloud und die Metamorphose vom Testmanager zum Quality Specialist, in: German Testing Magazin, 2/2018
[NASA]
NASA, Error Cost Escalation Through the Project Life Cycle, Seite 2, siehe:
https://ntrs.nasa.gov/archiv e/nasa/casi.ntrs.nasa.gov/20100036670.pdf
[Rad]
D. Radigan, Putting the ‚flow’ back in workflow with WIP limits, siehe:
https://www.atlassian.com/agile/kanban/wip-limits









