

Nach einer langen Ära intensiver Forschung erleben die Modelle des Maschinellen Lernens eine Blütezeit. Sie ermöglichen es, betriebliche Ereignisse treffsicher zu prognostizieren. Beispielsweise werden Modelle des Maschinellen Lernens erfolgreich im Predictive Maintenance eingesetzt.
Auf Basis von Sensordaten prognostizieren sie den Ausfall von Anlagen. Damit sind notwendige Wartungsarbeiten bereits vor einem kostspieligen Ausfall durchführbar. Ein weiteres Beispiel ist ihr Einsatz im Customer Churn Management. Hier sagen sie die Abwanderungswahrscheinlichkeit vonKunden voraus, sodass vorbeugende Maßnahmen rechtzeitig eingeleitet werden können.
Das Ziel von Business Analytics ist die Ableitung von Wissen aus Daten und dessen Veredelung für betriebliche Entscheidungsprozesse [ChG17]. Als eine Quelle für entscheidungsrelevantes Wissen bieten sich die Modelle des Maschinellen Lernens an. Allerdings stellt sich die Frage, ob diese Modelle neben der Prognose überhaupt für Erklärungs- und Gestaltungszwecke nutzbar sind. In letzter Zeit wird diese Frage immer häufiger aufgeworfen und speist sich aus dem Wunsch, das Wissen über betriebliche Zusammenhänge aus den „lernenden Maschine“ zu extrahieren. Dadurch erhofft man sich, organisationale Lernprozesse zu initiieren, bei denen sowohl Ursachen als auch erfolgskritische Maßnahmen identifiziert werden können, um sie anschließend betrieblich einzusetzen.
Bei der Ableitung von Wissen aus den Modellen des Maschinellen Lernens sind einige Hürden zu überwinden. Eine große Hürde ist ihr Black-Box-Charakter: Die Nutzer kennen zwar die Input-Faktoren und die Prognose, aber die Arbeitsweise des Modells ist für sie nicht nachvollziehbar. Explainable Artificial Intelligence (XAI) widmet sich diesem Problem. Durch den Einsatz verschiedener Methoden wird die Black Box geöffnet und ihre Nachvollziehbarkeit erhöht.
White- und Black-Box-Modelle
Die häufig eingesetzten Modelle des Maschinellen Lernens basieren auf überwachten und unüberwachten Algorithmen. Zu den überwachten Algorithmen gehören Entscheidungsbäume, Ensemble-Verfahren und Neuronale Netze. Hierbei werden Modelle auf Basis gelabelter Daten trainiert und anschließend für Prognosen verwendet. Wenn keine gelabelten Daten verfügbar sind, werden üblicherweise die unüberwachten Algorithmen genutzt. Diese Algorithmen sind darauf spezialisiert, eigenständig Muster in den Daten zu finden. Prominente Vertreter dieser Algorithmen sind k-Means und der A-priori-Algorithmus, der häufig für Verbundkaufanalysen herangezogen wird.
Im Prinzip sind die Parameter aller Modelle des Maschinellen Lernens unmittelbar einsehbar.Trotz dieser Transparenz sind sie für Menschen nicht in gleicher Weise nachvollziehbar. Während White-Box-Modelle für den Menschen gut verständlich sind, entziehen sich Black-Box-Modelle einem unmittelbaren Zugang.
Ein Beispiel für eine White Box ist ein Entscheidungsbaum (siehe Abbildung 1). Ein Entscheidungsbaum besteht aus Knoten und Blättern: An den Knoten des Entscheidungsbaums werden die Werte eines Input-Faktors überprüft, während an den Blättern die Prognose erfolgt. Aufgrund dieser transparenten Struktur können die Regeln eines Entscheidungsbaums direkt abgelesen werden.
Ein paradigmatisches Beispiel für eine Black Box ist ein Neuronales Netz [Alp07]. Ein Neuronales Netz ist dem menschlichen Gehirn nachempfunden und besteht aus einer Vielzahl künstlicher Neuronen, die über mehrere Schichten miteinander verbunden sind (vgl. Abbildung 2). Die erlernten Regeln eines Neuronalen Netzes verbergen sich vor allem in seinen Gewichten. Sie drücken die Stärke der Verbindungen zwischen den Neuronen aus und bestimmen maßgeblich die Prognose. Für alle Neuronalen Netze lässt sich immer angeben, welche Gewichte antrainiert worden sind. Aber aufgrund der Vielzahl der Gewichte und der Komplexität des Neuronalen Netzes ist man häufig mit dessen Interpretation überfordert.
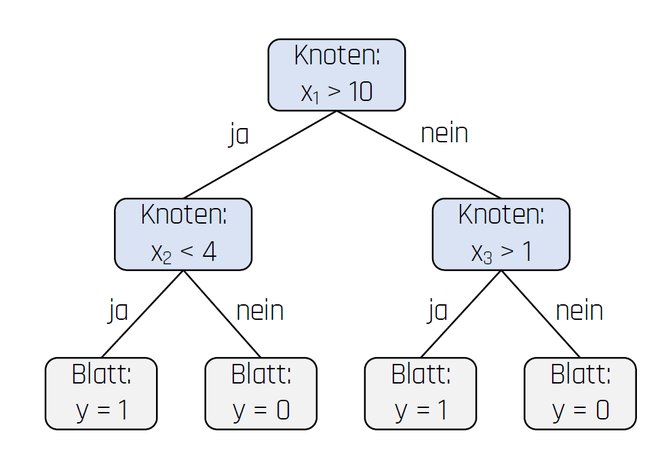
Abb. 1: Entscheidungsbaum
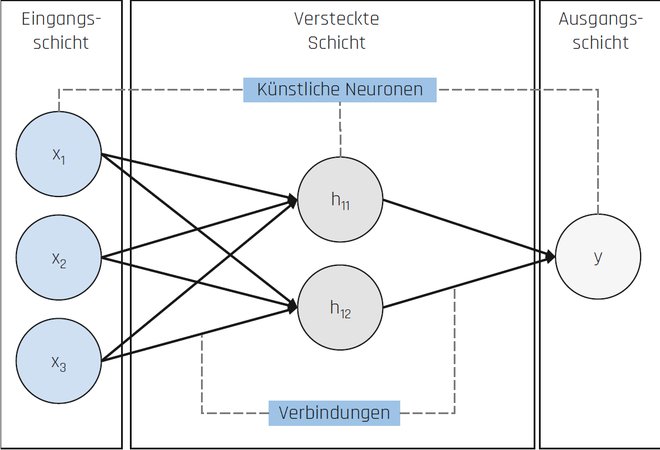
Abb. 2: Neuronales Netz
Prognosegüte versus Nachvollziehbarkeit
Je einfacher ein Modell ist, desto leichter lässt es sich nachvollziehen. Entgegen der weit verbreiteten Auffassung führen einfache Modelle aber nicht zwangsläufig zu schlechteren Prognosen. Denn gemäß dem „No-Free-Lunch“-Theorem gibt es keinen Algorithmus, der immer zu den besten Modellen führt. Vielmehr hängt die Leistungsfähigkeit eines Algorithmus davon ab, wie er mit den Daten zurechtkommt. In bestimmten Fällen dominiert eine White Box, in anderen Fällen ein Deep-Learning-Netz.
Wie ist aber vorzugehen, wenn für bestimmte Daten eine Black Box hinsichtlich der Prognosegüte ihren White-Box-Konkurrenten deutlich überlegen ist? In diesem Fall ist zwischen Prognosegüte und Nachvollziehbarkeit abzuwägen. Entweder man entscheidet sich für die Black Box mit hoher Prognosegüte und geringer Nachvollziehbarkeit. Oder man verwendet die White Box und versteht dafür unmittelbar ihre Regeln. XAI setzt genau an diesem Punkt an. Das Ziel ist die Erreichung einer hohen Prognosegüte bei gleichzeitiger Nachvollziehbarkeit des Modells.
Öffnen der Black Box
In jüngster Zeit ist ein sehr großes Interesse am Thema XAI [Sam19] spürbar. Zwar stand das Öffnen der Black Box schon immer im Fokus des Maschinellen Lernens. Denn Modellentwickler mussten auch in Vergangenheit ihre Modelle verstehen, um beispielsweise Fehler zu beheben, Schwächen im Feature Engineering zu entdecken und das Modell zu optimieren. Jedoch ist mit zunehmendem Einsatz des Maschinellen Lernens auch der Bedarf an Erklärungen erheblich gestiegen. Die Modellentwickler stehen daher oft in der Rechenschaftspflicht. Sie müssen nichttechnischen Stakeholdern (beispielsweise Nutzern und Fachexperten) die Arbeitsweise ihrer Modelle erläutern, um Transparenzanforderungen zu erfüllen und dadurch das Vertrauen in ihre Modelle zu steigern.
Daneben hat die Europäische Kommission mit ihrer Ethik-Leitlinie die Anforderungen für den ethischen Umgang mit Künstlicher Intelligenz (KI) formuliert [EuK19]. Hiernach sollen unfaire Verzerrungen und Diskriminierungen beim Einsatz von KI vermieden werden. Die Prüfung dieser Anforderung setzt voraus, dass die Arbeitsweise der eingesetzten Modelle für alle Beteiligten nachvollziehbar ist.
Um diese Nachvollziehbarkeit herzustellen, lassen sich eine Fülle von Methoden finden, die die Interpretation der Arbeitsweise von Black-Box-Modellen ermöglichen [HaG18]. Die Methoden können danach unterschieden werden, ob sie Auskunft über den Gesamtmechanismus geben (globale Interpretation) oder Gründe für einzelne Prognosen liefern (lokale Interpretation).
Eine Methode zur globalen Interpretation der Arbeitsweise eines Modells sind Partial Dependence Plots. Ein Partial Dependence Plot beschreibt, wie sich die Prognose ändert, wenn die Input-Faktoren des Modells bei durchschnittlichem Einfluss der nicht betrachteten Input-Faktoren variiert werden.
Abbildung 3 stellt die Arbeitsweise eines Neuronalen Netzes zur Prognose der Kundenabwanderung mit Hilfe eines Partial Dependence Plot dar. Das Neuronale Netz hat offensichtlich einen nichtlinearen negativen Zusammenhang zwischen der Dauer einer Kundenbeziehung und der Abwanderungswahrscheinlichkeit erlernt.
Aufgrund der Wechselbeziehungen zwischen den Input-Faktoren eines Modells können solche Darstellungen täuschen. Daher lassen sich mit Hilfe von Partial Dependence Plots auch Interaktionen zwischen den Input-Faktoren visualisieren. In Abbildung 4 ist neben der Dauer der Kundenbeziehung auch der Einfluss der monatlichen Zahlungen abgebildet. Es ergibt sich ein differenzierteres Bild: Zwar sinkt immer noch die Abwanderungswahrscheinlichkeit mit der Dauer einer Kundenbeziehung, jedoch setzt eine entgegengesetzte Tendenz mit der Höhe der monatlichen Zahlungen ein.
Ein Beispiel für einen lokalen Interpretationsansatz ist die SHAP-Methode (SHapley Additive exPlanations) [Lun20]. Diese Methode bedient sich des Shapley-Werts aus der kooperativen Spieltheorie. Der Shapley-Wert ist ein Lösungskonzept, das jedem Mitglied einer Gemeinschaft seinen Anteil am Ertrag zuweist. Diese Grundidee wird auf die Interpretation von Modellen des Maschinellen Lernens übertragen: Eine Prognose wird als Gemeinschaftsleistung aller Input-Faktoren angesehen. Bei der Interpretation eines Einzelfalls wird für jeden Input-Faktor sein Mehrwert (SHAP-Wert) unter Berücksichtigung von Interaktionseffekten berechnet. Die Prognose ergibt sich dann als Summe der einzelnen SHAP-Werte.
Abbildung 5 visualisiert beispielhaft die Interpretation einer einzelnen Prognose mit Hilfe der SHAP-Methode. Die roten Pfeile symbolisieren die Input-Faktoren, die die Abwanderungswahrscheinlichkeit erhöhen. Die blauen Pfeile repräsentieren hingegen die Faktoren mit reduzierendem Effekt. Hier wird der Einfluss von Anrufen im Callcenter deutlich. Die prognostizierte Abwanderungswahrscheinlichkeit von 70 Prozent bei dem betrachteten Kunden resultiert insbesondere aus den zahlreichen Anrufen.
Die SHAP-Methode dient primär der Interpretation einzelner Prognosen. Allerdings erlaubt die Gesamtbetrachtung der einzelnen Interpretationen zusätzliche Einsichten, beispielsweise besonders wichtige Input-Faktoren (Feature Importance) und strukturell ähnliche Kundengruppen.
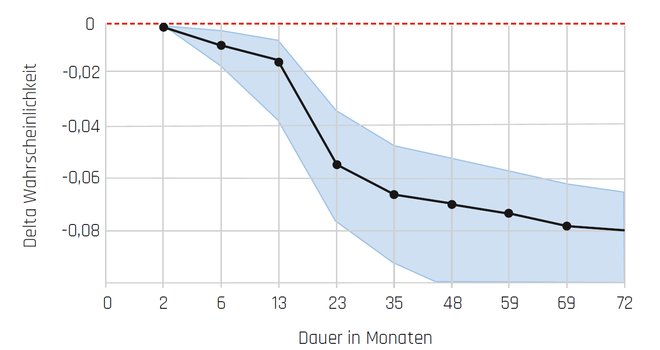
Abb. 3: Partial Dependence Plot mit einem Input-Faktor
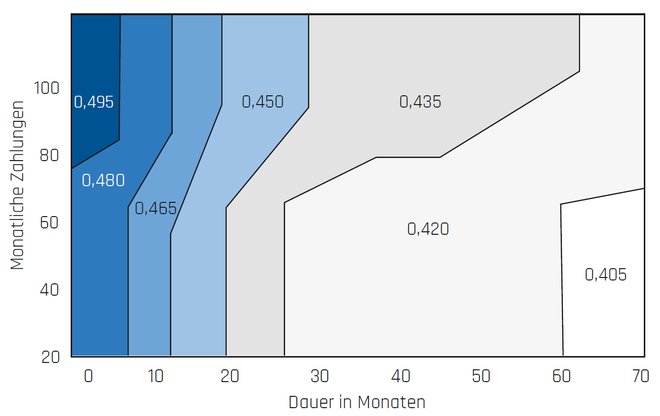
Abb. 4: Interaktion von zwei Input-Faktoren
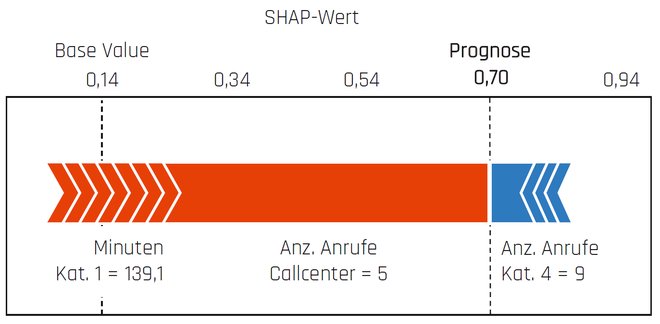
Abb. 5: Interpretation einer einzelnen Prognose (SHAP-Methode)
Chancen und Grenzen
Explainable Artificial Intelligence ermöglicht die Interpretation der Arbeitsweise einer Black Box. Damit eröffnen sich viele Chancen für Business Analytics, um neue Einsichten über betriebliche Zusammenhänge zu gewinnen. Beispielsweise erlauben Partial Dependence Plots die Ableitung von Tendenzaussagen. Solche Regeln sind in Form von heuristischen Aussagen häufig die Grundlage für betriebliche Entscheidungen. Außerdem identifiziert die SHAP-Methode die Input-Faktoren mit verstärkendem Einfluss. Diese Informationen könnten in Dashboards integriert werden, um wirkungsvolle Maßnahmenbündel gegen die Abwanderung einzelner Kunden auszuwählen.
Korrelation ist nicht Kausalität
Es wäre aber fatal, diese extrahierten Regeln unreflektiert in Entscheidungsprozesse einfließen zu lassen. Denn die vorgestellten Modelle (sowohl White- als auch Black-Box-Modelle) sind darauf optimiert, Korrelationen und Ähnlichkeiten in den Daten zu erkennen. Sie sind nicht dafür konstruiert, kausale Beziehungen zu identifizieren. Sie können also nicht erklären, warum ein Ereignis (zum Beispiel Kündigung) eingetreten ist [Shm10]. Dieses Wissen über Ursache und Wirkung ist unbedingt erforderlich, um wirkungsvolle Maßnahmen auszuwählen. Beispielsweise liegt die Ursache für eine Kündigung weder in der Dauer einer Geschäftsbeziehung noch in der Anzahl der Callcenter-Anrufe.
Eine Kündigung resultiert vielmehr aus einem Zusammenspiel verschiedener Faktoren, wie zum Beispiel der Erwartungen des Kunden bezüglich Preis und Qualität sowie des Verhaltens der Mitbewerber. Das Mantra der Ungleichheit von Korrelation und Kausalität kann nicht häufig genug wiederholt werden. Andererseits ist die heuristische Bedeutung von Korrelationen nicht zu unterschätzen. Korrelationen geben zwar keine Antwort auf die Frage, warum etwas passiert, sie deuten jedoch darauf hin, dass etwas passiert [MaC13]. In diesem Sinn können sie beispielsweise auf erklärungsbedürftige Kündigungen aufmerksam machen und den Bedarf für weitere Analysen verdeutlichen.
Konsistenzprüfung
Diese Einschränkung macht eine sorgfältige Analyse der extrahierten Regeln erforderlich. Eine solche Analyse sollte sich unter anderem darauf beziehen, ob die Regeln konsistent sind zu den bekannten Hypothesen über Ursache und Wirkung [Ros20]. Eine Bestätigung der Konsistenz ist kein Beweis für die Gültigkeit der vermuteten Beziehungen. Denn die extrahierten Zusammenhänge können auch durch andere Ursachen hervorgerufen worden sein. Jedoch zeigt diese Bewährungsprobe auf, dass die eigenen Hypothesen nicht gänzlich falsch sind.
Suche nach Anomalien
Menschen tendieren zunächst einmal dazu, immer jene Beispiele zu finden, die ihre liebgewonnenen Denkmuster bestätigen (Confirmation Bias). Um nicht in diese Falle zu tappen, ist insbesondere nach Anomalien zu suchen. Der Begriff Anomalie steht hier für einen prägnanten Widerspruch zwischen den explizierten Regeln und den eigenen Hypothesen. Übertragen auf das Churn-Management-Beispiel können solche Widersprüche aus unerwarteten Verhaltensweisen von Kunden in bestimmten Preissegmenten und Regionen resultieren.
Was für Wissenschaft im Allgemeinen gilt, ist auch im Unternehmenskontext zutreffend: Die Hypothesen über Ursache und Wirkung sind umgeben von einem „Meer von Anomalien“ [Fey76]. Neue Einsichten werden erst durch die Auseinandersetzung mit diesen Anomalien und deren Integration in den bestehenden Wissenskorpus generiert. Daher sind die aufgedeckten Anomalien nicht als Gefahr zu begreifen. Vielmehr sind sie eine Chance, um von den „lernenden Maschinen“ zu profitieren.
Instrumentelle Unterstützung
Die instrumentelle Unterstützung bei den Analysen bietet Business Analytics: Ihre Methoden und Technologien können darüber Aufschluss geben, wann es zu einer Anomalie gekommen ist (Descriptive Analytics) und warum diese Anomalie eingetreten ist (Diagnostic Analytics). Daneben stellt die Statistik eine Fülle fundierter Methoden bereit, um Ursachen für eine Abweichung zu ergründen und schließlich kausale Zusammenhänge zu identifizieren.
Fazit
XAI gewährt einen Blick in die Black Box. Hierdurch werden die komplexen Regeln der Black Box nachvollziehbar. Im Rahmen von Business Analytics können diese Regeln als eine weitere Quelle für die Ableitung von entscheidungsrelevantem Wissen genutzt werden.
Aber es ist nicht möglich, dieses Wissen auf Knopfdruck zu generieren. Denn die Modelle erlernen ihre Regeln beispielsweise auf Basis von Korrelationen und nicht durch kausale Analysen. Daher kann XAI nur ein Ansatzpunkt für die Herleitung von entscheidungsrelevantem Wissen sein. Es sind zwingend kritische Prüfungen und weitere Analysen erforderlich. Erst durch das Zusammenspiel von lernender Maschine und Mensch können effektive organisationale Lernprozesse angestoßen und tiefer gehende Einsichten über betriebliche Zusammenhänge gewonnen werden.
Weitere Informationen
[Alp07]
Alparslan, A. et al.: Systeme und Kriterien des Finanzratings. In: Achleitner, A.-K. et al. (Hrsg.): Finanzrating – Gestaltungsmöglichkeiten zur Verbesserung der Bonität, Gabler 2007, S. 95–121
[ChG17]
Chamoni, P. / Gluchowski, P.: Business Analytics – State of the Art. In: Controlling & Management Review, 4-2017, S. 8–17
[EuK19]
Europäische Kommission: Ethik-Leitlinien für eine vertrauenswürdige KI. Brüssel 2019
[Fey76]
Feyerabend, P. K.: Wider den Methodenzwang. Suhrkamp 1976
[HaG18]
Hall, P. / Gill, N.: An Introduction to Machine Learning Interpretability. O’Reilly 2018
[Lun20]
Lundberg, S. M. et al.: From local explanations to global understanding with explainable AI for trees. In: Nature Machine Intelligence, 10-2020, S. 56–67
[MaC13]
Mayer-Schönberger, V. / Cukier, K.: Big Data – Die Revolution, die unser Leben verändern wird. Redline 2013
[Ros20]
Roscher, R. et al.: Explainable Machine Learning for Scientific Insights and Discoveries. In: IEEE Access, 8-2020, S. 42200–42216
[Sam19]
Samek, W. et al. (Hrsg.): Explainable AI: Interpreting, Explaining and Visualizing Deep Learning. Springer 2019
[Shm10]
Shmueli, G.: To Explain or to Predict? In: Statistical Science, 25-2010, S. 289–310









