

Der Erfolg vieler auf dem Internet basierender Geschäftsmodelle fußt auf einer API-Ökonomie rund um eine Plattform. Doch auch modernere Content-Management oder Shop-Produkte sind von vornerein als „headless” konzeptioniert. Dadurch wird es einfacher, diese zu integrieren oder an die wachsenden Ansprüche einer responsiven Oberfläche anzupassen und den Zugriff über die unterschiedlichen Kanäle einzubinden.
Oft werden diese APIs als REST-Schnittstelle angeboten. Mit GraphQL und OpenAPI existieren inzwischen Standards, die die Einbindung, das Testen und die Qualitätssicherung der Schnittstellen vereinfachen. ThoughtWorks hat GraphQL schon seit ein paar Jahren in seinen Technology-Radar aufgenommen. Gleichzeitig warnt ThoughtWorks, ähnlich wie bei den API-Gateways, davor, die Nutzung von GraphQL zu überfrachten. Deswegen sollte man sich mit den Chancen und Risiken dieser Open-Source-Datenabfrage- und Manipulationssprache beschäftigen.
Ein großer Vorteil von GraphQL ist die mögliche Schema-Evolution und dass der Client nur die von ihm benötigten Felder und Daten beim Server anfordern muss. Gleichzeitig sind die Graph-QL-Abfragen stark typisiert, sodass hier Fehler wie bei reinen JSON-basierten REST-Anfragen früher vermieden werden können. Mit GraphQL können unterschiedliche Backendsysteme für die Anforderungen von unterschiedlichen Clients zur Verfügung gestellt werden (s. Abb. 1). Dadurch ist GraphQL eine Alternative zu den Gateway- und Backend-for-Frontend-Mustern, ohne sich zunächst an eine konkrete Implementierung zu binden. Das macht Graph-QL auch für Frontend-Entwickler attraktiv, da diese loslegen können, sobald das Schema vorliegt und hier Mocktestdaten zur Verfügung gestellt werden, bevor diese komplett umgesetzt oder die Backendsysteme angebunden sind.
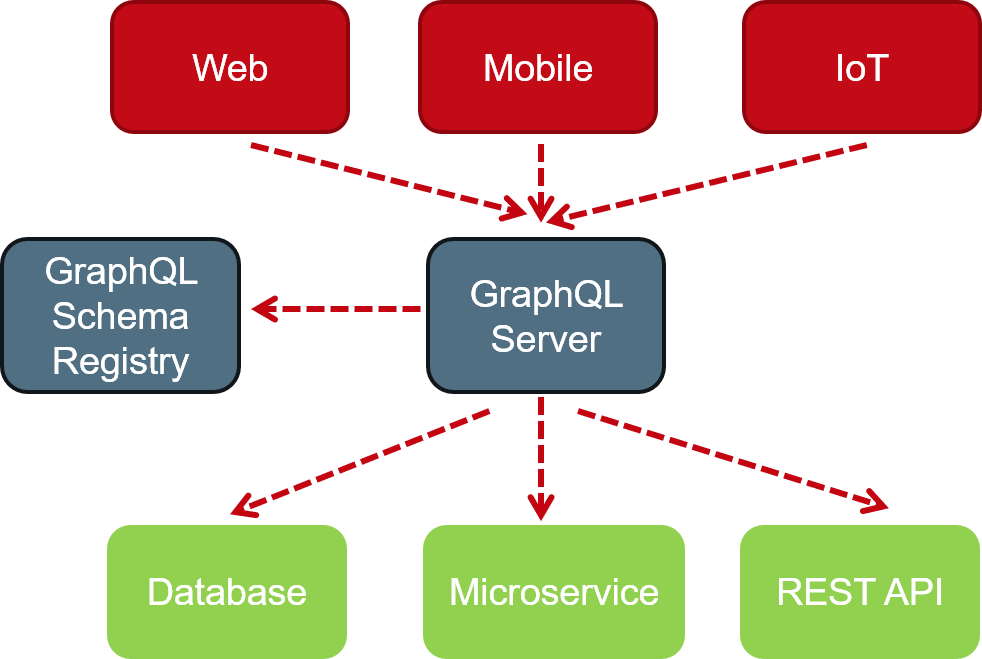
Abb. 1: Mehrere Quellen und unterschiedliche Clients
Wofür GraphQL?
GraphQL steht für „Graph Query Language” und wurde ursprünglich von Facebook entwickelt. Seit 2015 werden die GraphQL-Spezifikation [GraphSpec] (aktuell das Release June 2018 unter dem Open Web Foundation Agreement, OWFA v1.0.) und die zugehörigen Unterprojekte von der GraphQL Foundation [GraphFnd], die zur Linux Foundation gehört, weiterentwickelt. Ein wichtiges Unterprojekt dabei ist das GraphiQL-Entwicklerwerkzeuge-Projekt, das sich um das GraphQL Language Server Protocol und Plug-ins für verschiedene IDEs kümmert. Naturgemäß wird JavaScript (ebenso als Referenzimplementierung) am besten unterstützt. Doch sowohl für den Server als auch den Client gibt es verschiedene Implementierungen in mehreren Programmiersprachen [GraphCode] und Produkten.
Abbildung 2 gibt einen groben Überblick über die Graph-QL-Stiftungsmitglieder (AWS, IBM, Facebook, Twitter, PayPal, Airbnb, Shopify, neo4j), -Werkzeuge und -Produkte. Die am weitesten verbreiteten Produkte sind – neben dem Altair Editor – der Apollo-Server, Hasura als GraphQL-Server für Datenbanken (PostgreSQL, mySQL, MS SQL), das Relay-Framework für React und AWS AppSync und Amplify. Inzwischen gibt es nicht nur für viele IDEs, sondern auch für beliebte Testwerkzeuge, wie Linter und JMeter, Introspektion-GraphQL-Scanner für die Burp-Suite und Postman [POSTMAN] eine GraphQL-Unterstützung. Es gibt sogar eine OWASP GraphQL-Checkliste [OWASP], um typische Sicherheitsfallen mit GraphQL zu vermeiden. Wer sich in der Apollo-Welt bewegt, findet in der Cloud mit dem Apollo Studio eine komfortable, aber kostenpflichtige Lösung, die sogar eine Registry und die Messdaten des Apollo-Servers an einer Stelle integriert.
Abb. 2: GraphQL Foundation Landschaft [GraphLand]
Die Referenzimplementierung für Java ist GraphQL-Java [GraphJava]. Dieses wird auch für die GraphiQL Java Tools und den GraphQL Starter for Spring Boot [GraphJava] verwendet. Auch für Micro-Profile gibt es Implementierungen für die eigene GraphQL-Spezifikation 1.0 [MICGRAPH]. Diese wird zum Beispiel über SmallRye in OpenLiberty, WildFly oder Quarkus umgesetzt.
Inzwischen gibt es eine Stiftung [GraphFnd], die sich nicht nur um die Weiterentwicklung der Spezifikation [GraphSpec], sondern auch um die Verbreitung von GraphQL kümmert. Neben spezialisierten GraphQL-Anbietern, wie Apollo und Hasura, arbeiten in der Stiftung viele namhafte Firmen, wie IBM, AWS und neo4j, mit [GraphLand], was die Bedeutung des GraphQL-Standards unterstreicht. Der grundsätzliche Unterschied zwischen REST und GraphQL ist, wer bestimmt, was ausgeliefert wird. Bei REST stehen die Anforderungen einer Ressource im Vordergrund und der Client kann nur über das Auslieferungsformat, aber nicht über den Inhalt entscheiden. Bei GraphQL hingegen kann er entscheiden, welche Felder aus einem veröffentlichten Schema angefragt und zurückgegeben werden sollen (s. Abb. 3). Die REST-Aufrufe sind meist zwischen Microservices in einem LAN-Netz optimiert (Ost-/West-Kommunikation), hingegen weniger mit Nord-/Süd-Kommunikation zu verschiedenen Clients in eher unzuverlässigen Netzen mit geringen Bandbreiten. Das hat bei typischen REST-Aufrufen ein Over- und Under-fetching zur Folge. Was bedeutet, dass der Benutzer oft zu lange auf die Ergebnisse warten muss und zu viele unnötige Daten mit mehreren statt einer gezielten Abfrage übertragen werden müssen.
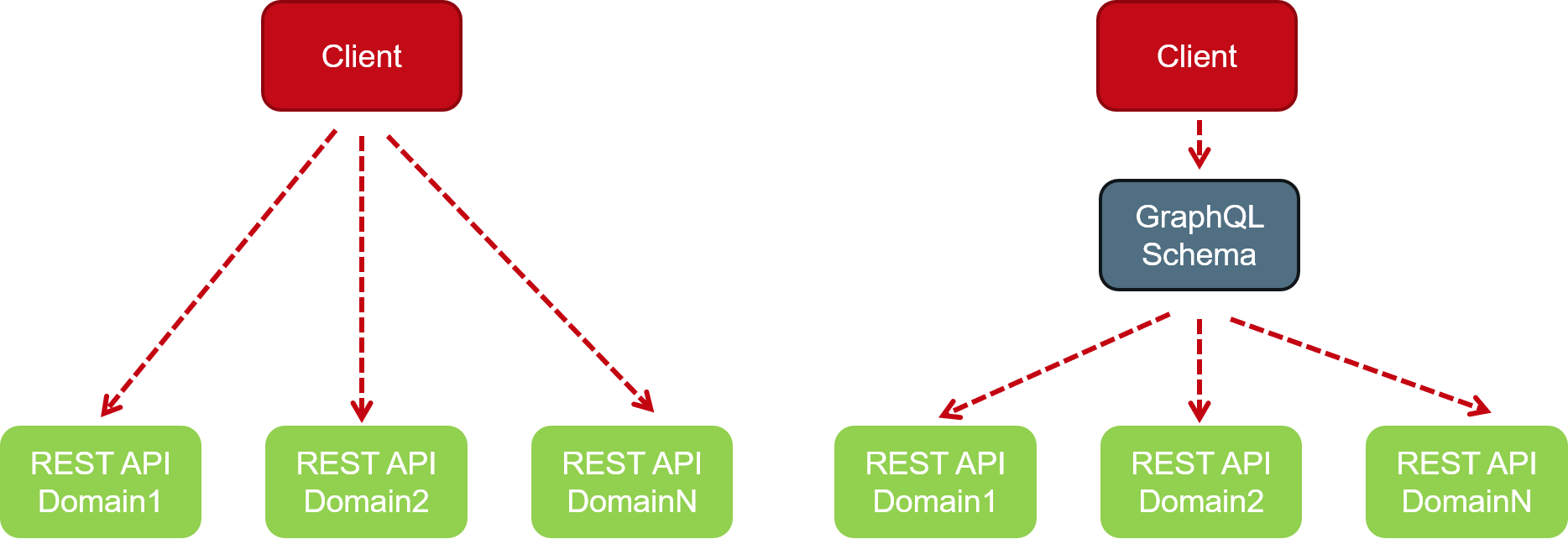
Abb. 3: Ressourcen vs. Schema orientiert
Tabelle 1 fasst die Vorteile von GraphQL gegenüber OpenAPI zusammen. Ein Nachteil von GraphQL gegenüber OpenAPI ist der größere Aufwand für die Implementierung der Abfrage und Update-Logik. Außerdem benötigt man spezialisierte Clients und Bibliotheken, um mit GraphQL arbeiten zu können. Hier hat REST weniger Anforderungen, aber auch mehr Freiheiten, was eine Governance schwieriger macht.

Tabelle 1: Vorteile von GraphQL gegenüber OpenAPI
Wie bei jeder guten Programmierschnittstelle sollte man auch bei GraphQL vermeiden, zu viel von den internen Implementierungsdetails nach außen zu geben, da das sowohl die Nutzung als auch die Anpassbarkeit und Austauschbarkeit der Implementierung erschwert. Ein großer Vorteil, gerade wenn viele Clients mit unterschiedlichen Anforderungen die Schnittstelle nutzen, liegt darin, dass Sie Ihre Abfragen an den Bedarf anpassen können, ohne dass am Server etwas geändert werden muss. Insbesondere bei der mobilen Nutzung erhält man hier mit weniger Abfragen und einer reduzierten Rückgabemenge schneller die wirklich benötigten Daten, was bei langsamen Verbindungen ein großer Vorteil ist.
Was ist zu beachten?
Um REST-APIs zu verwenden, gibt es nicht den einen „richtigen“ Ansatz. Es ist auch ein Unterschied, ob jedes Projekt diese Entscheidungen autonom trifft oder es hier Unternehmensvorgaben gibt. Auch wenn die Umsetzung eines REST-Diensts mit vielen Programmiersprachen möglich ist, lohnt es sich bei verteilten Diensten, sich auf einen einheitlichen Beschreibungsstandard, wie OpenAPI oder GraphQL, zu einigen. Das macht vor allem das Schema- und Versionsmanagement erheblich einfacher.
Traditionell kommt bei Alt- oder Fremdanwendungen oft das Adapter- oder Gateway-Muster zum Einsatz. Dieses hilft den Nutzern, sich von funktionalen Änderungen des Dienstanbieters etwas zu entkoppeln oder nur die Nutzung auf ausgewählte Felder zu konzentrieren. Andererseits muss so eine zentrale Komponente, wie ein API-Gateway, wiederum separat verwaltet und betrieben werden, was die Vorteile eines möglichst unabhängigen Microservice etwas einschränkt. Ein GraphQL-Server ist hier flexibler als klassische Gateway-Produkte. Ein großer Nachteil bei einer starken Nutzung ist die Skalierbarkeit und Ausfallsicherheit. Hier kann sich der einzelne GraphQL-Server schnell zum Engpass entwickeln.
Die Flexibilität der Abfragen hat auch Nachteile bei der Skalierbarkeit, da es schwieriger wird, Ergebnisse sowohl auf dem Client als auch auf dem Server zu cachen oder vorzuberechnen. Das ist bei reinen RESTvollen Diensten besser, erfordert jedoch auch ein anderes Abfrage- und Ergebnisdesign. Bibliotheken wie Relay oder Apollo Client erleichtern das Arbeiten mit GraphQL und ermöglichen gleichzeitig auch, den Antwortgraphen effizient zu cachen.
Hier ist es hilfreich, dass GraphQL-Server, wie Apollo, die Möglichkeiten des Monitorings bieten, um sich bei der Optimierung auf die häufigsten oder die langsamsten Abfragen zu konzentrieren, wodurch man die Gesamtperformanz optimieren kann. Doch auch für Spring Boot gibt es Möglichkeiten, einfache Metriken abzufragen oder ein Tracing einzubauen.
Für das effiziente Arbeiten mit GraphQL hat Apollo zehn Prinzipien (angelehnt an die 12 Factor App von Heroku) erstellt [PRINC]. Diese lauten:
- Nur ein unifizierter, konsistenter und stabiler Graph statt vieler.
- Verteilte Implementierung des Graphen, sollte in den einzelnen Fachdomänen stattfinden.
- Das GraphQL-Schema sollte zentral in einem Register zur Verfügung gestellt werden, als einzige zentrale „Quelle der Wahrheit“.
- Das Schema sollte die Implementierung abstrahieren, aber genügend flexibel für den Nutzer sein.
- Das Schema soll sich inkrementell weiterentwickeln können.
- Die Performanz soll inkrementell verbessert werden.
- Der Graph soll ausreichend Metadaten für die Introspektion durch die Entwickler zur Verfügung stellen.
- Zugriffsrechte sollten pro Client vergeben werden.
- Strukturiertes Logging der Graph-Abfragen, für bessere Optimierung und Fehlererkennung.
- Aufteilung der GraphQL-Schichten in mehrere Unterschichten.
Herausforderungen dezentraler Datenhaltung – vom Flickenteppich zur Föderation
Diese zehn Prinzipien werden besonders wichtig, wenn man Graph-QL an vielen Stellen und Diensten einführen möchte. Ein Problem von vielen Mikrodiensten [NETFLIX] ist, dass diese oft für operationale Anwendungsfälle entwickelt wurden, jedoch für analytische Abfragen eher wenig geeignet sind.
Weil für Berichte oder Auswertungen jedoch oft die Daten aus mehreren Domänen kombiniert werden müssen, muss hier eine weitere Infrastrukturebene eingeführt werden, um die verteilten Daten wieder in einen Datensee einzufangen und zu konsolidieren. Das führt jedoch oft dazu, dass hier ein größerer Integrations- und Datenqualitätssicherungsaufwand betrieben werden muss, um die verschiedenen Domänenmodell miteinander synchron zu halten. Im strategischen DDD-Design gibt es hierzu einige Ansätze, doch wäre es hilfreich, solche Anforderungen gleich innerhalb der Domäne zu berücksichtigen. So einen Ansatz möchte die noch neue DataMesh-Disziplin [DAT20] bieten. Ziel ist, dass von einer Domäne auch analytische Schnittstellen angeboten werden, die zusammen zu neuen Diensten flexibel kombiniert werden können.
Einen ähnlichen Ansatz gibt es bei GraphQL schon. Das sogenannte Stitching (Zusammennähen, [STITCH]) versucht, für bestehende GraphQL-Schemata ein besser passendes übergreifendes Schema zu definieren. In Abbildung 4 wird ein neues Schema auf Basis der Felder der Schemata Filme, Produktion und Schauspieler zusammengestellt. Da dies rein deklarativ erfolgt, muss hier kein zusätzlicher Transformationscode geschrieben und bei Änderungen angepasst werden. Das erleichtert nicht nur die Umsetzung, sondern hilft auch, schneller an die Daten heranzukommen. Dadurch dass jedes einzelne Schema sich unabhängig voneinander weiterentwickeln kann, werden auch die unterschiedlichen Anforderungen berücksichtigt, ohne sich gegenseitig zu behindern.
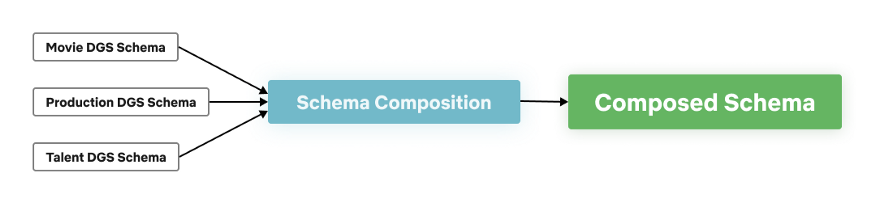
Abb. 4: Das Schema-Stitching am Beispiel
Ein Problem kann bei größeren Datenmengen die Performanz sein, sodass einzelne Daten nur inkrementell geladen werden müssen oder eine Vorberechnung (Resolver) eingeführt werden muss. Ein typisches Problem wäre zum Beispiel eine Suche über mehrere Domänen. Hier können die Teilmodelle als eine neue Oberdomäne mit Schema präsentiert werden, ohne sich mit den Beziehungsdetails zwischen den Modellen beschäftigen zu müssen. Selbst wenn sich die Teilmodelle ändern, muss nicht das Oberschema angepasst werden, sondern nur die daraus generierten Abfragen der Teilmodelle.
Die verteilte GraphQL-Spezifikation [aFEDER] und ihre Umsetzung sind noch neu und eher für Abfragen als für Datenänderungen geeignet. Neben dem Apollo-Server, der mit node.js läuft, gibt es mit Apollo Federation on the JVM [APOLLOj] eine Graph-QL-Starter-Implementierungen für Spring Boot. Das erst vor Kurzem freigegebene Netflix-Framework Domain Graph Service (DGS) [NETFDGS] für Spring Boot basiert auf graphql-java und soll mit Annotationen (Code-first) die Verwendung von verteilten Graph-QL-Diensten erleichtern. Hier wäre es zu wünschen, wenn es in Zukunft noch mehr Implementierungen geben würde, um von einem unabhängigen Standard zu sprechen.
Fazit
Mit GraphQL gibt es eine implementierungsunabhängige Möglichkeit, seine Daten zu beschreiben. Die Clients können mit unterschiedlichen Programmiersprachen umgesetzt werden und die von ihnen benötigten Daten optimal abfragen. Dabei sind die Clients weniger von Erweiterungen des Schemas betroffen, sodass weniger Anpassungs- und Abstimmungsaufwände nötig sind. Je mehr Firmen nicht nur software-, sondern auch datengetrieben vorgehen, werden APIs und ihre Daten immer mehr als Produkt angesehen. Dadurch wird auch der Bedarf nach einem DataMesh immer stärker wachsen.
Über die verteilte GraphQL-Spezifikation wird es möglich, ein vereinheitlichtes Schema für verschiedene Microservices anzubieten, ohne dass diese selbst GraphQL sprechen. Bisher existieren neben Apollo noch nicht so umfangreiche Implementierungen, die alle Funktionen des verteilten GraphQL abdecken. Doch mit der wachsenden Verbreitung von GraphQL und damit der zunehmenden Größe seiner Modelle wird der Bedarf zunehmen. Deswegen lohnt sich auf jeden Fall ein Blick auf dessen neue Möglichkeiten.
Weitere Informationen
[aFEDER]
Apollo Federation specification,
https://www.apollographql.com/docs/federation/managed-federation/overview/,
https://www.apollographql.com/docs/federation/federation-spec/,
https://www.apollographql.com/docs/federation/migrating-from-stitching/
[APOLLOj]
Apollo Federation on the JVM,
https://github.com/apollographql/federation-jvm
[DAT20]
Z. Dehghani, Data Mesh Principles and Logical Architecture, 2020,
https://martinfowler.com/articles/data-mesh-principles.html,
https://martinfowler.com/articles/data-monolith-to-mesh.html, s. a.
https://www.thoughtworks.com/de/radar/techniques/data-mesh,
https://www.thoughtworks.com/insights/blog/data-mesh-its-not-about-tech-its-aboutownership-and-communication
[GraphCode]
GraphQL, Werkzeuge und Programmiersprachen, https://graphql.org/code/
[GraphFnd]
GraphQL Foundation, https://foundation.graphql.org/
[GraphLand]
GraphQL Foundation Landscape, https://landscape.graphql.org/
[GraphSpec]
GraphQL specification, https://github.com/graphql/graphql-spec
[GraphJava]
GraphQL Java implementation, https://www.graphql-java.com/
[GraphJavaT]
GraphQL Java Tools, GraphQL Starter for Spring Boot, https://www.graphql-java-kickstart.com
[Hun17]
M. Hunger, GraphQL mit Java, in: JavaSPEKTRUM, 4/2017
[MICGRAPH]
MicroProfile GraphQL 1.0, https://download.eclipse.org/microprofile/microprofile-graphql-1.0/
[NETFLIX]
T. Shikhare,
https://netflixtechblog.com/how-netflix-scales-its-api-with-graphql-federation-part-1-ae3557c187e2, 9.11.2020, und
https://netflixtechblog.com/how-netflix-scales-its-api-with-graphql-federation-part-2-bbe71aaec44a, 11.12.2020
[NETFDGS]
P. Bakker, K. Srinivasan, Netflix Domain Graph Service (DGS) framework,
https://netflixtechblog.com/open-sourcing-the-netflix-domain-graph-service-framework-graphql-for-spring-boot-92b9dcecda18
https://netflix.github.io/dgs/
[OWASP]
OWASP GraphQL Cheat Sheet, https://cheatsheetseries.owasp.org/cheatsheets/GraphQL_Cheat_Sheet.html
[POSTMAN]
Postman GraphQL support, https://www.postman.com/graphql/
[PRINC]
Principled GraphQL, https://principledgraphql.com/
[STITCH]
Schema-Stitching, https://www.graphql-tools.com/docs/schema-stitching/









