Was war noch gleich Serverless?
Wie der Name schon sagt: Es gibt keine Server mehr – zumindest keine, um die sich gekümmert werden muss. Populär wurde der Ansatz durch die Serverless Computing-Plattform Lambda bei Amazon Web Services (AWS).
Mit Serverless können Anwendungen – oft Funktionen genannt – ausgeführt werden, ohne dass zuvor Maschinen hochgefahren werden müssen. Die Anwendung kann automatisch nahezu beliebig horizontal skalieren. Lediglich der von der Funktion benötigte Speicher (und somit die CPU-Leistung) muss angegeben werden. Die Kosten basieren auf Ausführungsdauer, Anzahl der Aufrufe sowie auf benötigtem Speicher und nicht wie bei klassischen Ansätzen auf Basis der verwendeten Maschinen. Serverless beschränkt sich jedoch nicht auf Computing. Allein bei AWS gibt es zahlreiche Serverless-Services im Bereich der Datenhaltung und Messaging. Bekannte Vertreter sind etwa Simple Storage Service (S3) zur Speicherung Datei-ähnlicher Objekte, DynamoDB, eine NoSQL-Datenbank, sowie Simple Queue Service (SQS), um Nachrichten zuverlässig zwischen Anwendungen auszutauschen. Nahezu alle Cloud-Anbieter bieten ähnliche Serverless-Produkte an.
Zu erkennen sind diese häufig an ihrem Bezahlmodell. Die Kosten werden nicht anhand der Maschinen berechnet, sondern nach dem tatsächlichen Verbrauch – auch Pay as you go genannt. So werden in S3 die Kosten auf Basis der Menge an gespeicherten Objekten sowie dem Datentransfer berechnet. In DynamoDB ist neben der Datenmenge auch die gewünscht Lese- und Schreibkapazität, also wie viele Anfragen pro Sekunde möglich sein sollen, entscheidend. In SQS basiert die Preisgestaltung auf der Menge der verschickten und empfangenen Nachrichten. Andere Serverless-Produkte folgen einem ähnlichen Muster. Auch ohne Serverless lassen sich Kosten so gestalten, dass diese genau dem Bedarf entsprechen. Etwa indem genau die richtige Anzahl an Maschinen, Größe der Festplatten usw. gewählt wird. Ein Findungsprozess, der aufwendig und fehleranfällig sein kann. Ein klassisches Auto-Scaling der Maschinen im Computing- Bereich ist zwar ein gangbarer Weg, stößt aber in anderen Bereichen wie Datenhaltung, Messaging und Co. schnell an Grenzen. Um diese Skalierbarkeit zu ermöglichen, ist Serverless jedoch auch von Kompromissen und Einschränkungen gekennzeichnet und stellt selten eine Allzwecklösung dar. Viele Anwendungen lassen sich kaum ausschließlich durch Serverless realisieren. Ein triviales Beispiel sind langlebige Jobs, die mehrstündige Berechnungen durchführen; die Ausführungszeit von Serverless-Anwendung ist üblicherweise auf wenige Minuten begrenzt.
Warum kommt Serverless so selten zum Einsatz?
Trotz der möglichen Vorteile sind reine Serverless-Architekturen in der Praxis immer noch eine Rarität. Gerade Anwendungen monolithischer Natur lassen sich schwer durch Serverless abbilden. Lange Startzeiten sowie hoher Speicherverbrauch sind im Bereich Serverless ein No-Go. Eigenschaften, die Monolithen leider allzu oft aufweisen. Die Konsequenzen im Bereich Serverless sind zu hohe Kosten und ein merklicher Verzug bei der Verarbeitung vieler Anfragen in kurzer Zeit (immer dann, wenn es zu sogenannten Cold Starts kommt).
Ein weiterer großer Punkt ist die Datenhaltung. SQL-Datenbanken sind aus gutem Grund immer noch die erste Wahl. Zwar können Serverless-Anwendung auch mit SQL-Datenbanken kommunizieren, jedoch stoßen diese schnell auf technische Probleme, wie etwa die Anzahl der offenen Datenbankverbindungen. Lösungen von AWS wie etwa RDS Proxy (Pooling von Verbindungen) können zwar helfen, zeigen jedoch letztlich nur auf, dass gerade übliche SQL-Datenbanken nicht im gleichen Maße wie Serverless horizontal skalieren können. Eine Migration auf eine Serverless-Datenbank, meist NoSQL, ist indessen selten praktikabel.
Zudem benötigt Serverless ein generelles Umdenken bezüglich Anwendungsarchitektur. Alte Denkmuster zu ändern und existierende Anwendungen nach Serverless zu migrieren, ist ein zeitaufwendiges Unterfangen, das trotz der potenziellen Vorteile von Serverless nicht immer zu rechtfertigen ist. Ein behäbiger Monolith lässt sich selten mal eben in kleinere Serverless-Funktionen zerteilen. Die Vergangenheit hat gezeigt, dass selbst das Zerschneiden in Microservices bereits eine große Herausforderung darstellt. Serverless erhöht diesen Schwierigkeitsgrad noch einmal. Serverless lohnt sich rein aus Kostengründen häufig nicht. Ist die Last auf der Anwendung bekannt und folgt einem vorhersehbaren Muster, ist der Verzicht auf Serverless meist deutlich günstiger. Bekannte Lastspitzen, wie das Saisongeschäft zur Weihnachtszeit oder spezielle Ereignisse wie der Black Friday, lassen sich über einfaches, händisches Skalieren ausreichend abfangen. Auch wenn sich Lastspitzen über einen längeren Zeitraum, etwa mehrere Minuten oder Stunden, aufbauen, sind die schnellen Skalierungsmöglichkeiten von Serverless selten notwendig.
Abbildung 1 zeigt ein Szenario, bei dem Serverless wenig Mehrwerte im Hinblick auf Kosten und Skalierung bringt. Vorhersehbare Last lässt sich über Skalierung von Maschinen gut abfangen. Ist die Last hingegen schwer vorhersehbar und Anfragen können jederzeit in großer Anzahl erfolgen, sollen jedoch schnell beantwortet werden, können die Vorteile von Serverless ausgespielt werden. So eine Last tritt in der Praxis jedoch seltener als erwartet auf. Meist reicht hier eine automatische, von der Last abhängige Skalierung von Maschinen.

Abb. 1: Vorhersehbare Last lässt sich über Skalierung von Maschinen gut abfangen
Wo geht die Reise hin?
Meiner Beobachtung nach fristet Serverless noch immer ein Nischendasein. Der anhaltende Trend Richtung Microservices scheint für Serverless jedoch eine große Chance zu sein. Zwar wird nicht jeder Microservice ein guter Kandidat für einen vollständigen Serverless-Ansatz, dennoch gibt es häufig Services, wo die flexible Skalierung von Serverless Mehrwerte bringen kann. Dieser selektive Einsatz war in typischen Monolithen zuvor nur schwer möglich.
Für einige Web-Frameworks gibt es inzwischen Adapter, die bestehende HTTP-Schnittstellen mit Serverless kompatibel machen. Durch dieses Vorgehen müssen keine oder wenige Änderungen am Anwendungscode vorgenommen werden, damit die Anwendung alternativ auch Serverless bereitgestellt werden kann. Dadurch wird die Entscheidung, ob Serverless verwendet wird, lediglich eine Frage der Deployment-Konfiguration. Hierdurch ergeben sich auch interessante Möglichkeiten, etwa wenn es darum geht, einen Hybrid-Modus zu fahren, in dem sowohl Web-Server als auch eine Serverless-Anwendung parallel zum Einsatz kommt. Bezogen auf Skalierung kann damit die Grundlast der Anwendung mit einer Handvoll Maschinen abgedeckt werden, während nicht vorhersehbare Lastspitzen mit Serverless abgefangen werden. Abbildung 2 zeigt eine mögliche Lastverteilung, bei der sich ein solcher Ansatz lohnen kann. Auch neuartige Datenbankdienste auf Basis von SQL, die speziell für Serverless gedacht sind, machen einen reinen Stack ohne Server attraktiver. Bekannte Vertreter sind Amazon Aurora Serverless, CoackroachDB oder PlanetScale. Es muss also in Serverless nicht mehr komplett auf die gewohnten SQL-Funktionalitäten verzichtet werden. Üblich für Serverless, verfolgen diese ebenfalls ein bedarfsgerechtes Bezahlmodell. Einen Schritt weiter geht Serverless Edge Computing, eine Variante von Serverless, bei der die Ausführung so nah wie möglich am Endnutzer geschieht. Im klassischen Serverless wie etwa AWS Lambda wird beim Deployment festgelegt, in welcher geografischen Region die Ausführung stattfindet (z. B. Zentraleuropa). Bei der Edge-Variante hingegen wird die Anwendung in mehreren, weltweit verstreuten Rechenzentren bereitgestellt. Das sorgt für eine massive Reduzierung der Latenz und somit ein bessere User Experience. Im Serverless Edge Computing werden Flaschenhälse jedoch deutlich schneller sichtbar. Spricht eine solche Anwendung etwa mit einer Datenbank, die geografisch nicht verteilt ist, wird die Antwortzeit nach unten begrenzt. Die Verbindung von der Edge zur, im schlechtesten Fall, weit entfernten Datenbank ist gewissermaßen das schwächste Glied. Um also vollständig von Serverless Edge Computing zu profitieren, sollte die gesamte Anwendung diesem Paradigma folgen. Mindestens so, dass ein großer Teil der Anfragen nicht die Edge verlassen muss.
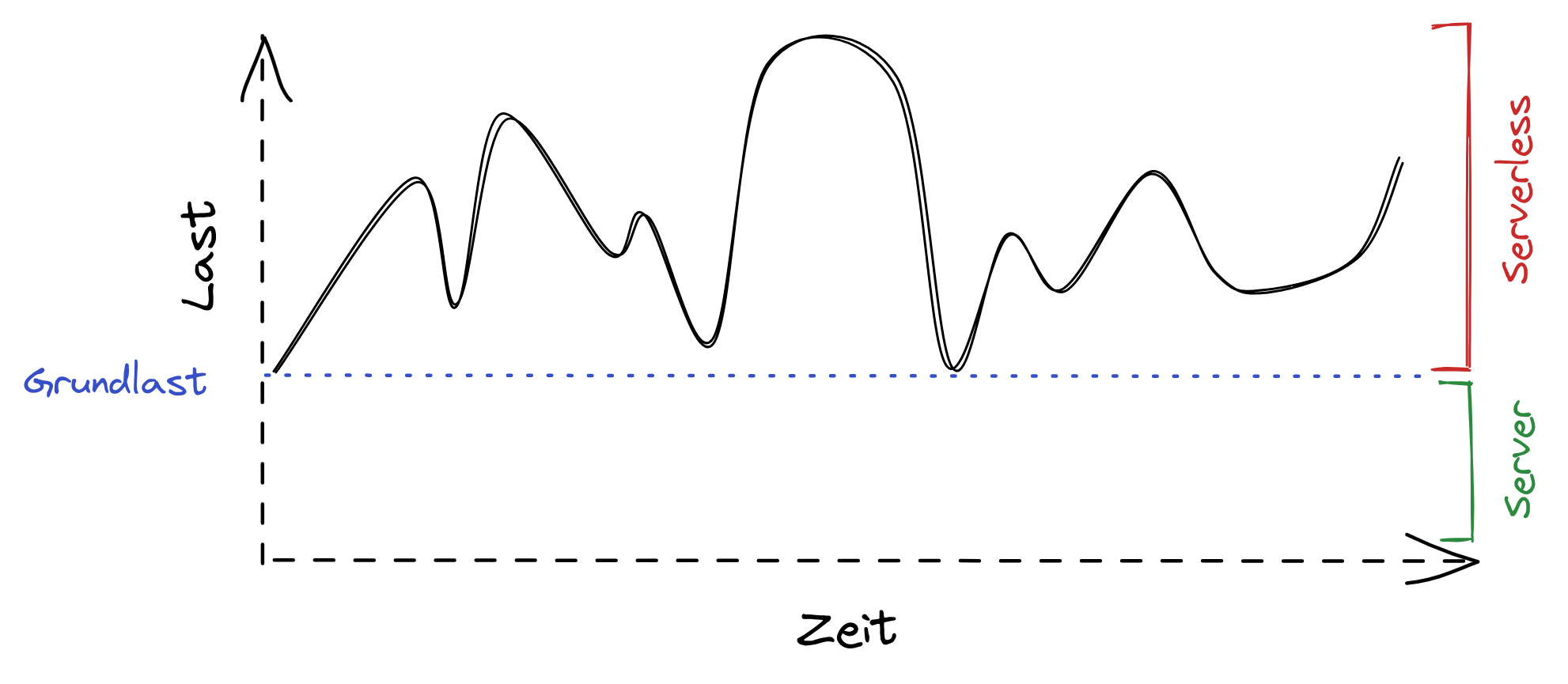
Abb. 2: Lastverteilung, bei der es sich lohnen kann, plötzliche Lastspitzen via Serverless abzufangen, wobei die Grundlast über gewöhnliche Web-Server bedient wird
Da das Umfeld Serverless Edge Computing sehr jung ist, ist die Verbreitung bei den Cloud-Anbietern aktuell noch sehr gering. Als Vorreiter tut sich aktuell Cloudflare hervor. Neben Computing mit Cloudflare Workers stehen mit KV, einer Key-Value- Datenbank, und D1, einer verteilten Variante von SQLite, auch auf Serverless Edge ausgelegte Services zur Datenhaltung bereit. Kann eine gegebene Anwendung tatsächlich rein mit Technologien im Bereich Serverless Edge Computing umgesetzt werden, ist es auf einfache Weise möglich, eine global verteilte, hochskalierbare Anwendung zu realisieren. Dies mit anderen Cloud-Services zu ermöglichen – Serverless eingeschlossen –, ist nur mit enormem Aufwand möglich. Serverless Edge Computing ist also durchaus als eine technologische Neuheit zu bezeichnen. Wie sehr es sich jedoch wirklich durchsetzt, wird erst die Zeit zeigen.
Fazit
Ob Serverless in Edge oder nicht, vollends durchgesetzt, gerade im typischen Enterprise-Umfeld, hat sich das Ganze noch nicht. Ausnahmen bestätigen hier zum Glück aber die Regel. Dennoch scheint gerade durch Microservices und Co. die Hürde für Serverless kleiner geworden zu sein. Auch Web-Frameworks, die Integrationen für die üblichen Serverless-Anbieter bereitstellen, geben Anlass zur Hoffnung, dass der anfängliche Hype um Serverless nun doch endlich in der Realität ankommt – zumindest in den Fällen, wo es sich auch wirklich lohnt.