

Warum Quarkus?
Spring Boot [Spring] hat sich lange Zeit als Quasi-Standard zur Entwicklung von Java-Micoservices (teilweise auch im Cloud-Umfeld) etabliert. Das Framework bietet einen reichhaltigen Funktionsumfang an, um kleine, aber auch komplexere Services und Anwendungen zu entwickeln. Dabei ist die Benutzung einfach und intuitiv. Die Technologie wurde nicht mit dem Fokus auf Cloud-Umgebungen entwickelt, daher zeigen sich insbesondere im Cloud-Umfeld Nachteile. Zwei Nachteile sind die vergleichsweise langen Start-up-Zeiten sowie der große Memory-Footprint. Hier setzt Quarkus [Quar] an. Dieses von Red Hat unterstützte Framework ist speziell für die Cloud-native Entwicklung entworfen worden. Es glänzt dabei mit kurzen Startzeiten, hoher Performance und einem geringen Ressourcenverbrauch. Als Teil des Quarkus-Frameworks wird eine Build-Umgebung zur Verfügung gestellt, mit der ohne zusätzliches Tooling das Bauen von Containern ermöglicht wird.
Es bleibt die Frage, wie ein Service von Spring Boot auf Quarkus migriert werden kann. Das soll im Folgenden genauer betrachtet werden.
Beispiel: Anzeigetafel
Die Schritte zur Migration beziehungsweise die hierzu notwendigen Änderungen sollen anhand eines Beispiels demonstriert und beschrieben werden. Bei dieser Applikation handelt es sich um ein Dashboard, welches eingesetzt wird, um die Architekturqualität unserer verschiedenen Projekte darzustellen (s. Abb. 1).
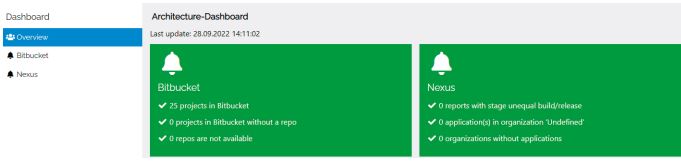
Abb. 1: Dashboard
Dazu werden verschiedene Tools zur Qualitätskontrolle über REST-Schnittstellen angefragt und die Ergebnisse übersichtlich aufbereitet dargestellt. Die Anwendung läuft in einer Cloud-Plattform. In unserem Fall ist das eine eigenständig betriebene Open-Shift Container Platform (OCP). Innerhalb der Plattform laufen sowohl die tatsächliche Applikation als auch deren Datenbank und der Buildserver. Denn selbstverständlich verwenden wir Prozesse zum Continuous Delivery und installieren neue Versionen der Software automatisch, sobald sich Änderungen ergeben und die Qualität durch automatische Tests bestätigt wurde.
Es wird eine klassische Drei-Schichten-Architektur, bestehend aus UI (Web/Template Engine), Applikationslogik (Application Services) und Persistenz, verwendet (s. Abb. 2).
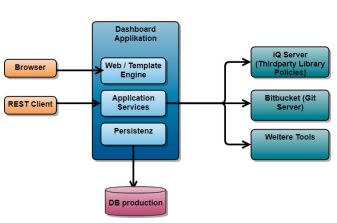
Abb. 2: Drei-Schichten-Architektur
Deployment
Die Anwendung wird in einem Container bereitgestellt, der innerhalb der OpenShift Container Platform (OCP) betrieben wird (s. Abb. 3). Die unterschiedlichen Umgebungen (development, test, production) werden über einen Deploymentserver (ArgoCD) mit den entsprechenden Container-Images versorgt. Die Container-Images der Applikation werden durch den Buildprozess, bestehend aus mehreren Pipelines im Buildserver (Jenkins), bereitgestellt. Der Buildprozess startet dabei einen entsprechenden Image-Build im OpenShift an. Das Image selbst wird in einer Image-Registry abgelegt. Diese dient später als Quelle, wenn beim Deployment die Plattform das Image bezieht. Das Image wird nach dem Erfüllen der notwendigen Quality-Gates in die jeweils nächste Umgebung propagiert.
Die Pipelines sind dabei nicht projektspezifisch; es wird eine eigens erstellte Pipelinebibliothek verwendet, welche von allen Projekten genutzt werden kann und die passend für den jeweiligen Service konfiguriert wird. Somit ist auch der Buildprozess vom Vorgehen und auch den entstehenden Ergebnissen (Artefakten) normiert.
Sämtliche Umgebungen werden über ein GitOps-Repository konfiguriert. In diesem sind zum einen die Templates für die Konfigurationsdateien (in Helm-Notation), zum anderen die jeweiligen Konfigurationswerte (z. B. auch die konkrete Version des zu verwendenden Images) hinterlegt. Dieser GitOps-Ansatz bietet dabei einige Vorteile. So sind beispielsweise jegliche Konfigurationsänderungen im Git-Repository versioniert und können historisch nachvollzogen werden. Auch ist bei einer vollständigen Umsetzung dieses Ansatzes ein Neuaufsetzen der Software (sogar auf eine beliebige ältere Version) einfach möglich, da alle dafür notwendigen Informationen abrufbar sind.
Es sollte noch erwähnt werden, dass Helm [Helm] sich als Template-Sprache für die Beschreibung von Konfiguration bei der Cloud-native Entwicklung etabliert hat und von vielen Tools unterstützt wird. In unserem Fall setzen wir ArgoCD (inkludiert im Red Hat OpenShift GitOps-Operator) ein. Die Helm-Templates werden durch das Tool übersetzt, das heißt, die Konfigurationswerte werden gefüllt und die entstandenen Konfigurationsinformationen werden an OCP übermittelt beziehungsweise dort angewendet.
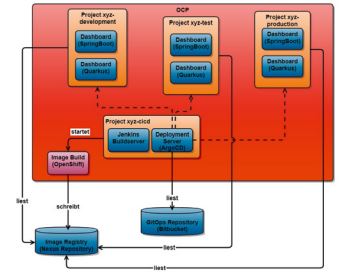
Abb. 3: Deployment in der OpenShift Container Platform (OCP)
Entwicklungsprozess
Die Software wird vom Entwickler auf seinem lokalen Rechner entwickelt. Änderungen werden ins GIT (bei uns Bitbucket) eingecheckt und an den zentralen Server übertragen (push). Im OCP läuft ein entsprechender Buildserver (Jenkins), der die Änderungen aufgreift, baut und, wenn alle Quality Gates erfüllt sind, im OCP bereitstellt. Dabei wird die Software abhängig vom Branch im GIT in unterschiedliche Umgebungen (Namespaces) im OCP installiert.
Sowohl Spring Boot als auch Quarkus sind Java-Frameworks. Dementsprechend wird der Quellcode der Anwendung vor dem Ablauf kompiliert. Daher sind die notwendigen Schritte sehr ähnlich. Ein wesentlicher Unterschied ist allerdings, dass Quarkus keine handprogrammierte Application-Klasse benötigt (s. Tabelle 1).
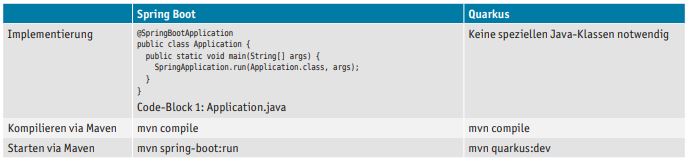
Tabelle 1: Ablauf
Cloud-native Development
Unter Cloud-native Development versteht man die Entwicklung von Software für den Ablauf innerhalb der Cloud. Dies stellt besondere Anforderungen beziehungsweise Bedingungen an die Software, um die Vorteile, die die Cloud-Plattform bietet, optimal ausnutzen zu können. In diesem Zusammenhang beziehen sich viele Anbieter auf die 12 Factor Apps, so zum Beispiel [Res21]. Die dort genannten zwölf Faktoren sollen helfen, Software zu entwickeln, die sich ideal in das Cloud-Umfeld einfügen. Ein Faktor ist beispielsweise die externe Konfigurationsmöglichkeit, idealerweise umgesetzt durch Umgebungsvariablen. Ein weiterer Faktor ist die horizontale Skalierbarkeit.
Ein wichtiger Erfolgsfaktor ist der hohe Grad an Automatisierung für die Prozesse rund um die Softwareentwicklung und Auslieferung (Buildprozesse mit automatischem Testen und Deployment, zum Beispiel über entsprechende Konfigurationstemplates, wie sie die Template-Sprache Helm für Kubernetes-Cluster bereitstellt).
Die Firma Pivotal erweitert diese Faktoren [Blo16]. Ein zusätzlicher wesentlicher Faktor ist die Telemetrie. Die Plattform muss die Möglichkeit haben, an der Applikation anzufragen, ob diese noch ordnungsgemäß läuft. Ist dies nicht der Fall, sollte der Container gestoppt und durch eine neue Instanz ersetzt werden. Um dies zu realisieren, sind Health-Checks innerhalb der Applikation notwendig. Beide Applikationsframeworks realisieren dies unter Zuhilfenahme von Monitoring-Bibliotheken. Aus Sicht der Plattform unterscheidet sich hier lediglich die URL, auf die zugegriffen werden muss (s. Tabelle 2).
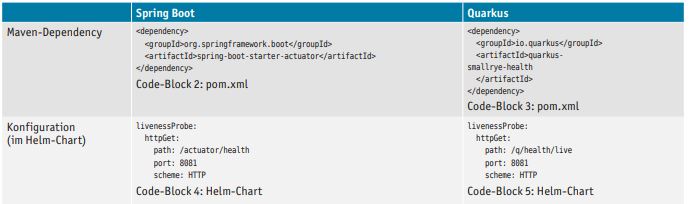
Tabelle 2: Development
Unterschiede
Thymeleaf-Unterstützung
In der Darstellungsschicht wird Thymeleaf als serverseitige Templating-Engine genutzt. Vorteil von Thymeleaf ist die Möglichkeit, die Templates direkt im Browser anzeigen zu lassen. Alternativ kann im Quarkus-Kontext die auf Quarkus abgestimmte Templating-Engine Qute verwendet werden.
Spring Boot bietet einen einfachen Mechanismus, um das benötigte Template zu liefern. In einer mit @Controller annotierten Klasse wird mittels @GetMapping der Template-Name zurückgegeben. Dieses Template muss sich im /resources/templates-Verzeichnis befinden. In Quarkus wird eine Hilfsklasse benötigt, die die Schnittstelle Renderable implementiert, um das geforderte Template zu ermitteln (s. Tabelle 3).
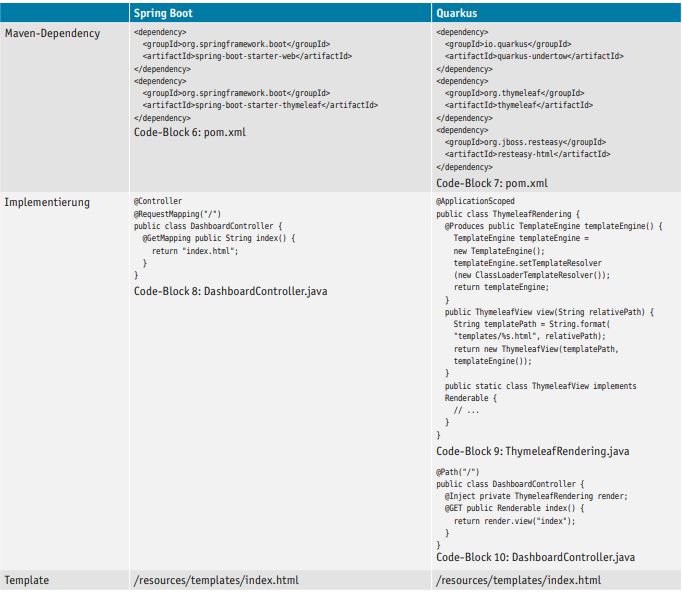
Tabelle 3: Thymeleaf-Unterstützung
REST-Endpunkt
Die Applikationsschicht bietet eine REST-Schnittstelle zum Hinzufügen von Testergebnissen, die innerhalb der Anwendung persistiert werden sollen. Diese REST-Endpunkte werden rollenbasiert mit Basic-Authentifizierung geschützt (weiter unten). Es sollen zwei Endpunkte vorhanden sein:
- /rest/testresult mit der HTTP-Methode GET und der Rolle „USER"
- /rest/testresult mit der HTTP-Methode POST und der Rolle „ADMIN"
Spring Boot definiert einen REST-Controller mittels der Annotation @RestController. Mit .@RequestMapping. wird ein Web-Request an diese Controller-Klasse gebunden. Die GET- beziehungsweise POST-Mappings werden über die Annotation .@GetMapping. beziehungsweise .@PostMapping. realisiert. Die GET-Methode kann über@PreAuthorize("hasRole('USER')") derart geschützt werden, dass nur Benutzername/Passwort-Kombinationen mit der Rolle „USER" Zugriff erhalten (POST-Methode analog).
Der REST-Controller in Quarkus wird über die Annotation @Path festgelegt (entsprechende Konfiguration an den Methoden). Die HTTP-Methode wird über @GET respektive @POST ausgewählt. Der Zugriffsschutz kann durch die Annotation @RolesAllowed festgelegt werden (s. Tabelle 4).

Tabelle 4: REST-Endpunkt
Basic auth
Bei Spring Boot liefert das Spring-Security-Framework die nötige Funktionalität. Dieses wird über eine Konfigurationsklasse gesteuert, über die der AuthenticationManagerBuilder und die HttpSecurity konfiguriert werden. Selbstverständlich würde in einem Echtsystem eine sicherere Methode zu Authentifizierung gewählt: Die Prüfung über hartcodierte Benutzernamen und Passwörter sollte durch ausgereifte Verfahren wie OpenIdConnect ersetzt werden.
Zur Verdeutlichung der Unterschiede ist diese Authentifizierungsmöglichkeit jedoch ausreichend. Bei der Konfiguration der HttpSecurity werden im Wesentlichen per antMatcher die benötigten Rollen festgelegt. Ändernde Operation darf nur ein Admin vornehmen. Da wir REST-Services einsetzen, muss die Cross Site Request Forgery (CSRF) ausgeschaltet werden (da die Service-Aufrufe keine Antwort auf eine Web-Seite sind und von daher kein entsprechendes Antwort-Token haben können). Zu beachten ist auch, dass die Actuator-URLs nicht geschützt sind. Dies ist wichtig für das Deployment im OpenShift.
Die Plattform prüft über den Liveness- und den Readiness-Endpoint des Actuators den Zustand des Service. Die Abfrage durch die Plattform erfolgt ohne Authentifizierung. Daher würde eine erzwungene Authentifizierung dazu führen, dass die Plattform den Container als nicht bereit ansieht, nach gewisser Zeit verwirft und einen neuen Container startet. Dies würde zu einer Schleife führen und der Service wäre nie verfügbar. Zudem sind die URLs der Weboberfläche ungeschützt, damit ein Zugriff ohne Authentifizierung stattfinden kann. Der Schutz wird über die Annotation @PreAuthorize("hasRole('ADMIN')") an dem konkreten Endpunkt umgesetzt; in diesem Fall wird die Rolle „admin" für den Zugriff benötigt.
Die Konfiguration der Rollen erfolgt in Quarkus in der zentralen Datei application.properties. Der Schutz wird über die Annotation @RolesAllowed("admin") an dem konkreten Endpunkt umgesetzt; in diesem Fall wird die Rolle „admin" für den Zugriff benötigt (s. Tabelle 5).

Tabelle 5: Basic auth
REST-Client
Es werden Endpunkte der externen Systeme Bitbucket und IQ-Server angefragt, um Informationen über die Architekturqualität zu erhalten. Die Anwendung fungiert demnach als REST-Client.
In Spring Boot wird ein RestTemplate im Rahmen einer Komponente (Annotation @Component) verwendet. Die notwendigen Konfigurationen werden in der Konfigurationsdatei application.properties hinterlegt und mittels der Annotation @Value eingelesen. Die Abfrage mittels RestTemplate gibt ein ResponseEntity-Objekt zurück; der tatsächliche Ergebniswert ist im Body. Eine weitere Möglichkeit zur Umsetzung einer REST-Client-Funktionalität wäre der Einsatz von Feign; hierdurch wäre jedoch das Einbinden einer weiteren Bibliothek notwendig.
Quarkus verwendet die Annotationen @Path zur Angabe des Pfades, @RegisterRestClient zur Festlegung eines Rest-Clients und @ClientHeaderParam, um automatisiert eine „Authorization" im Header zu übergeben. Die Autorisierung wird über eine default-Methode implementiert, die die erforderlichen Daten aus einer Konfigurationsdatei ermittelt. Alle GET-Endpunkte werden über die Annotation @GET mit Angabe des Unterpfades (Annotation @Path) und Information über das Ergebnis (Annotation @Produces) angegeben (s. Tabelle 6).
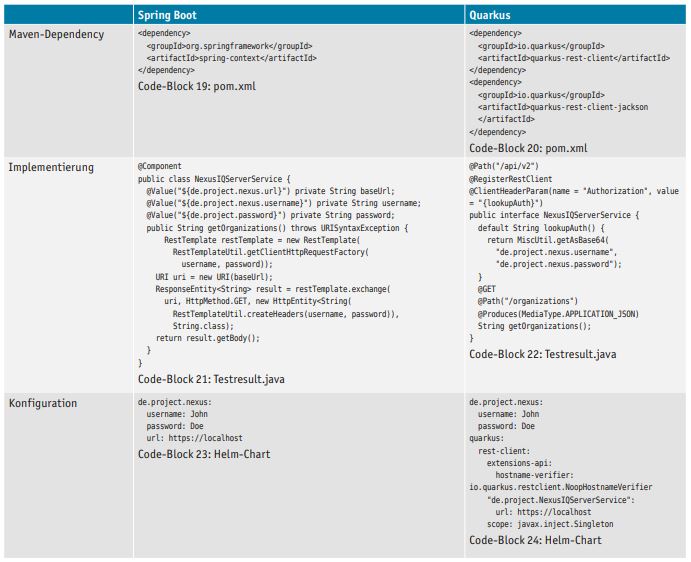
Tabelle 6: REST-Client
Datenbankanbindung
Es soll möglich sein, die Softwarequalität im Verlauf der Zeit zu betrachten, daher werden relevante Daten in einer relationalen Datenbank persistiert. Relationale Datenbanken – also das Speichern von beliebigen Daten in Tabellenform – sind auch heutzutage noch weit verbreitet. Zur Verbindung der zwei Paradigmen „Objekt" und „Tabelle" wird das Konzept der objektrelationalen Abbildung verwendet. Die hierfür verfügbaren Frameworks erlauben es auf eine sehr einfache Art, Objekte in einer relationalen Datenbank abzulegen.
Spring Boot bietet zur Speicherung ein Interface CrudRepository, welches generische CRUD-Operationen gegen ein Repository ermöglicht. Für die Grundfunktionalität (Laden, Speichern, ...) müssen keine spezifischen Methoden implementiert werden. Weitere Methoden können deklarativ umgesetzt werden, um zusätzliche Daten zu verarbeiten oder spezielle Suchen auszuführen.
Quarkus verwendet eine eigene Implementierung namens Panache. Ziel ist hier ebenfalls, generische CRUD-Operationen zur Verfügung zu stellen und weitere Methoden mit geringem Aufwand umzusetzen (s. Tabelle 7).
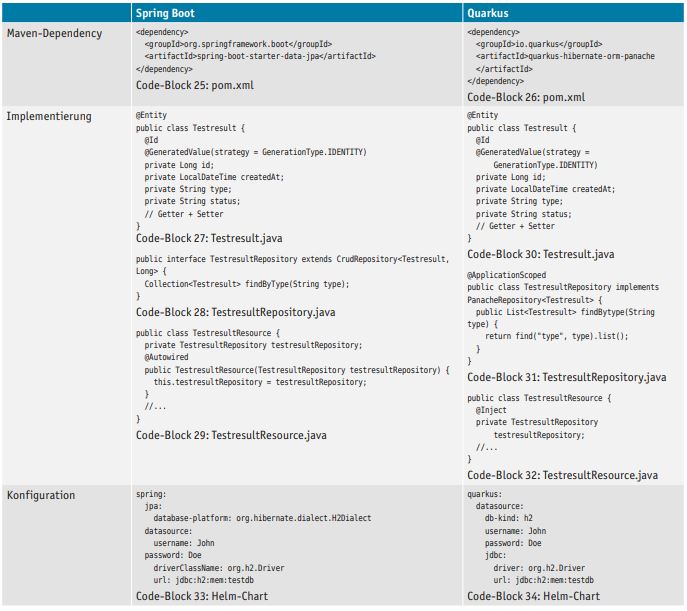
Tabelle 7: Datenbankverbindung
Links
[Blo16]
A. Bloom, Beyond the Twelve-Factor App, 2.6.2016,
https://tanzu.vmware.com/content/blog/beyond-the-twelve-factor-app
[Helm]
https://helm.sh/
[Res21]
B. Reselman, An illustrated guide to 12 Factor Apps, Red Hat, 18.2.2021,
https://www.redhat.com/architect/12-factor-app
[Quar]
https://quarkus.io









