

Neuronale Netze in biologischen Systemen sind Netzwerke aus beliebig vielen Nervenzellen. Diese werden Neuronen genannt. Jedes kleine Netz ist im Zusammenschluss ein Teil eines komplexen Nervensystems. Jedes erfüllt genau eine Aufgabe. Im menschlichen Körper sind es nahezu 100 Milliarden Neuronen, welche ständig miteinander kommunizieren und innerhalb von Millisekunden untereinander Nachrichten austauschen. Dieser Nachrichtenaustausch findet über chemische und elektrische Prozesse statt.
Neuronale Netze
Die Neuronen verfügen dabei über Ein- und Ausgänge, diese nennt man Synapsen. Der sendende Fortsatz, der Ausgang, wenn man so möchte, nennt sich Axon. Die empfangenden Fortsätze, die Eingänge, werden Dendriten genannt. Sobald das Potenzial am Eingang einen bestimmten Schwellwert überschreitet, wird dies am Axon weitergeleitet und mithilfe von chemischen Botenstoffen an andere Neuronen weitergegeben.
Wenn Lebewesen lernen, erhöht sich die Menge der ausgeschütteten Botenstoffe. Es entstehen weitere Eingänge an den jeweiligen Empfängerstellen oder die Kontaktflächen der Synapsen wachsen. Einfach ausgedrückt ist Lernen bei Lebewesen die ständige Wiederholung einer Übung, die mit dem Ziel verbunden ist, die Tätigkeit zur Perfektion zu führen. Wenn beispielsweise Kinder in der Schule das Schreiben lernen, wird jeder Buchstabe so lange wiederholt, bis er der Vorgabe entspricht.
Mit künstlichen neuronalen Netzen werden biologische neuronale Netze als informationsverarbeitende Systeme nachgeahmt. Dabei kann man diese im Sinne der Graphentheorie darstellen.
Abbildung 1 zeigt den schematischen Aufbau eines künstlichen neuronalen Netzes. Es besteht aus einem gerichteten Graphen, in welchem die Knoten die künstlichen Neuronen sind und die Kanten die Verbindungen dazwischen. Die Neuronen werden eingeteilt in Eingabe-, Ausgabe- und versteckte Neuronen.
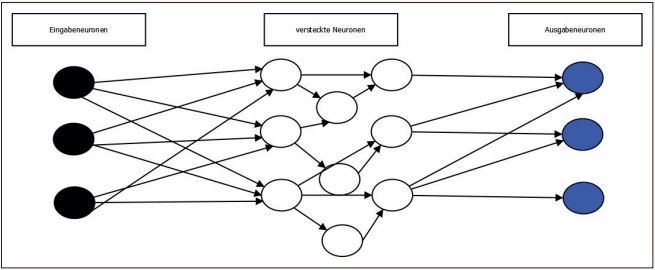
Abb. 1: Darstellung eines künstlichen neuronalen Netzes
Abbildung 2 zeigt eine schematische Darstellung eines einzelnen künstlichen Neurons. Die Verbindungen zwischen den Neuronen sind gewichtet. Hier sind diese Gewichte mit w1 bis w3 (weight) gekennzeichnet. Das Gewicht der einzelnen Verbindung stellt das künstliche Wissen dar. Jedes Neuron besitzt drei Zustandswerte: die Netzeingabe, die Aktivierung und einen Wert für die Ausgabe. Jedes Neuron hat zu seinen Statuswerten auch eine zugehörige Funktion (Netzeingabefunktion, Aktivierungsfunktion und Ausgabefunktion).
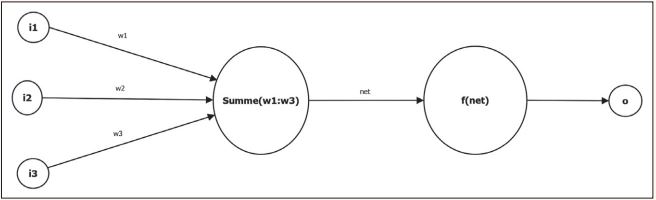
Abb. 2: Schematische Darstellung eines künstlichen Neurons
Die Netzeingabefunktion net entspricht der Summe der einzelnen Gewichte der Eingabeneuronen i1 bis i3. Die Aktivierungsfunktion f(net) bestimmt in Abhängigkeit der Eingabe den Wert der Ausgabe o (output). Die Ausgabe kann wiederum Eingabe für ein neues Neuron sein oder die Netzausgabe des kompletten Netzes darstellen.
Die Eingabeneuronen besitzen zusätzlich einen vierten Status, die sogenannte externe Eingabe.
Deep Learning
Das neuronale Netzwerk besteht nur aus mathematischen Funktionen. Die beschriebenen Zustandswerte und zugehörigen Funktionen führen dazu, dass das künstliche neuronale Netzwerk „lernen“ kann: Durch Veränderung der Gewichtung ist es möglich, die Eingangsfunktion der einzelnen Neuronen auf eine bestimmte Aufgabe hin zu sensibilisieren.
Dazu werden allerdings möglichst viele Trainingsbeispiele benötigt, aus welchen das Netzwerk seine „Erfahrung“ erzeugen kann. Innerhalb der vergangenen Beispiele und Versuche wird dabei bestimmt, welches Neuron aktiviert werden muss, um dazu beizutragen, möglichst immer die richtige Programmfunktion zu nutzen.
Dieses Training kann man theoretisch so lange vollziehen, bis die Parameter so eingestellt sind, dass die Erfolgschance nahezu 100 Prozent erreicht.
Deep Learning ist eine junge Teildisziplin des maschinellen Lernens. Deep Learning verwendet künstliche neuronale Netzwerke und sehr große Datenmengen, um ein gegebenes Ziel zu erreichen. Das Ziel ist die direkte Abbildung der Mechanismen unseres Gehirns. Auf Grundlage von bereits gesammelten Informationen kann das System das Erlernte immer wieder mit neuen Informationen verbinden und somit wiederum „lernen“. Damit ist das neuronale Netz dazu in der Lage, Prognosen oder Entscheidungen zu treffen und diese auch zu hinterfragen.
Deep Learning verbindet Big Data mit den Algorithmen, die auf künstlichen neuronalen Netzwerken angewendet werden. Die Daten aus sehr großen Datenbanken werden normalisiert und die Merkmale extrahiert. Danach werden die Ergebnisse erzeugt und wiederum in das Netzwerk gegeben, um ein noch besseres Ergebnis zu erzielen.
Deep Learning eignet sich dort besonders gut, wo große Datenmengen nach Patterns untersucht werden müssen. Aktuelle Anwendungsbeispiele sind die Gesichts- und die Spracherkennung. Besonders bei Letzterem kann man den Prozess des Deep Learnings sehr gut beobachten: Je öfter man mit dem Sprachassistenten von Apple spricht, desto besser kann Siri reagieren, teilweise sogar auf Dialekte. Die aufgenommenen Signale (in diesem Fall die Sprache) werden wieder in das Netzwerk geschickt, wodurch neue Sprachkonstrukte gelernt werden können und der Wortschatz stetig erweitert wird.
Wie testet man Lernen?
Die Verwendung von Algorithmen des Deep Learnings mithilfe von künstlichen neuronalen Netzwerken findet immer mehr Verbreitung und die Bandbreite der Applikationen wird immer größer – von Verkehrszeichenerkennung bis hin zu medizinischen Untersuchungen. Diese Applikationen und der Algorithmus des Lernens der jeweiligen Netze müssen wie andere Systeme auch getestet werden.
Heutzutage ist das Erstellen neuronaler Netzwerke kein großes Problem mehr: Man nimmt sich ein Framework (z. B. Caffe2), liest sich in die Dokumentationen ein und beginnt mit der Entwicklung.
Das Prinzip ist unabhängig vom jeweiligen Framework immer recht ähnlich: Man legt einen Zielzustand fest und gibt dem Netzwerk möglichst viele Daten. Das Netzwerk versucht nun, durch Veränderung der Zustandswerte und der Gewichtung das gegebene Ziel zu erreichen. Ob es einen Fehler oder eine Fehleinstellung gab, kann man feststellen, nachdem das Netz das Lernen abgeschlossen hat und man die Ergebnisse interpretieren kann. Wenn dann ein Fehler festgestellt wird, muss man diesen korrigieren und den Lernprozess erneut starten.
Mithilfe von Tests kann genau diese Zeit gespart werden und es können mögliche einfache Fehler vermieden werden. Beim Erstellen von neuronalen Netzen können nämlich Fehler entstehen, die mit statischen Methoden wie dem Lesen des Programmcodes nur schwierig auffindbar sind. In der Regel sind das dann algorithmische Fehler oder Fehler bei der Einstellung der Zustandsvariablen innerhalb des Netzes.
In der Regel findet man diese Fehler erst, wenn man die Werte über einen längeren Zeitraum gesammelt hat und diese dann auswertet. Man stellt dann aber nur fest, dass das Training des Netzes nicht zum gewünschten Ziel geführt hat.
Um diese Schwierigkeit zu demonstrieren, zeigt Listing 1 einen Code aus dem Git-Hub-Repository von Chase Roberts (siehe auch [Rob17]). Chase Roberts nutzt hier die Plattform TensorFlow und die Programmiersprache Python. TensorFlow ist eine Open-Source-Plattform, um maschinelles Lernen mithilfe unterschiedlicher Tools auszuführen.

Listing 1: In Python geschriebenes Convolutional (faltendes) neuronales Netz mit einem Fehler, nach Roberts
In Listing 1 wird mit sogenannten Convolutional Layern und den dazugehörigen Pooling-Layern ein neuronales Netz aufgebaut, welches zum Beispiel zur Bildererkennung genutzt werden kann. Das in Python geschriebene neuronale Netz enthält einen Fehler: Es ist nicht gestapelt und anstelle der Variable net wird oftmals der Parameter input_image verwendet (siehe Zeilen 3, 5, 6, 8, 10).
Diesen Fehler während der Ausführung zu entdecken, ist recht schwierig, da er sich nicht in einem Absturz, sondern nur in schlechten Trainingswerten äußert. Bei der Fehlersuche ist Chase Roberts nun wie folgt vorgegangen, er hat einen einzigen Trainingszyklus durchlaufen und die Werte der einzelnen Neuronen vorher und hinterher verglichen.
Listing 2 zeigt genau diesen Programmausschnitt. Er erstellt dafür das Netz, startet die Trainings-Session und speichert alle Variablen, welche trainiert werden sollen in die Variable before (Zeile 6). Nach der Trainingssession werden alle in die Variable after (Zeile 10) gespeichert. Innerhalb der for-Schleife in Zeile 11 können diese dann verglichen werden. In diesem Test und diesem einmaligen Trainingszyklus kann man mit einem einfachen assert() feststellen, dass sich alle Variablen verändert haben und trainiert wurden.

Listing 2: Fehlersuche nach Roberts, Test der Variablen vorher und nach dem Training
Listing 3 demonstriert einen weiteren einfachen und dennoch sehr wirksamen Test. Dabei wird geprüft, dass nur genau die Variablen verändert werden, die man auch trainiert hat.

Listing 3: Test auf trainierte Variablen nach Roberts
Der Optimizer hat eine Option, um alle Variablen zu verändern. Dies ist ein häufiges Problem, welches jedoch kaum auffällt. Listing 4 zeigt einen Test, mit dem dies geprüft wird. Dabei werden die Variablen vorher und nachher verglichen (siehe Zeilen 15 und 18).
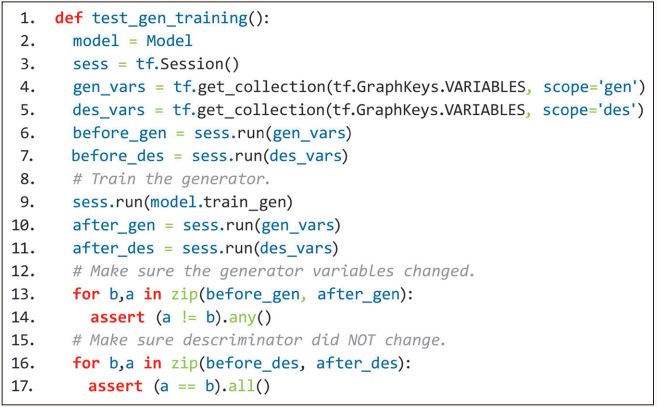
Listing 4: Test nach Roberts
Fazit
Da bei neuronalen Netzwerken sowohl Entwickler als auch Tester nahezu nur Black-Box-Tests erstellen können, sind alle Stunden, welche man in das Programmieren von Tests investiert, diese auch Wert. Eine Stunde Testen spart tagelanges Training des fehlerhaften Netzes in der Ausführung.
Referenzen
[Knn]
Künstliche Neuronale Netze – Das Gehirn hinter der KI, Meta Level Software AG, siehe:
http://www.meta-level.de/kuenstliche-neuronale-netze-knn/
[Rob17]
Chase Roberts, How to unit test machine learning code, 19.10.2017, siehe:
https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765
[Wiki]









