

Entwicklung und anschließende Integration der neuen Modelle stellen die klassische Softwareentwicklung jedoch noch vor Herausforderungen. Neben den Anwendungen selbst müssen jetzt auch die Machine-Learning (ML)-Modelle und deren Code für Training und Evaluation den Ansprüchen an einen produktiven Betrieb genügen. Mithilfe des Open-Source-Tools DVC (Data Version Control, [DVC]) und einigen Faustregeln kann die Softwareentwicklung diesen Ansprüchen aber schon mit wenig Aufwand gerecht werden
Von der Forschung zum Handwerk
Von außen betrachtet unterscheidet sich Data-Science weniger stark von der Softwareentwicklung, als man vermuten mag. In beiden Disziplinen gibt es klar festgelegte Vorgehensmodelle und Prozesse, aus denen definierte Ergebnisse und Resultate hervorgehen. Der Unterschied wird im Detail deutlich:
- Während Softwareentwickler mit Handwerkern und Ingenieuren vergleichbar sind, die mit ihren Werkzeugen wie Programmiersprachen, Frameworks und Tools lauffähige Lösungen entwickeln,
- liegt der Fokus von Data-Scientists auf der Durchführung von Experimenten mit verschiedenen Technologien, Algorithmen, Parametern und Datasets, um mit jeder Trainingsiteration ihr Modell zu verbessern.
Wie im Handwerk haben sich auch in der Softwareentwicklung über die Zeit Standardvorgehen, -werkzeuge und -metriken durchgesetzt. Mit Continuous Integration und Delivery lassen sich beispielsweise per Commit Applikationen automatisch bauen, testen und auf verschiedenen Umgebungen verteilen. Ein Vorgehen, das im Data-Science-Bereich bisher nicht nötig war. Dies ändert sich, wenn ML-Modelle in datengetriebene Applikationen integriert und zusätzlich zu statischen Algorithmen genutzt werden, um neue Features zu implementieren. Es entstehen Lücken zwischen dem Handwerk Softwareentwicklung und dem experimentierfreudigen Data-Science-Bereich, die es zu füllen gilt.
Artefakte, Artefakte, Artefakte
Die erste Lücke entsteht durch neue Artefakte, die es in normalen Softwareprojekten nicht gibt. Während Applikationen häufig aus Code, Konfiguration und dem fertigen Binary bestehen, bringt die Integration von ML-Modellen zusätzliche Logik und Dateien mit sich. Dazu gehört sowohl der Code für das Training und die Vorverarbeitung als auch Modellgewichte und Trainingsdaten. Die kleinste Änderung führt zu einer neuen Modellversion und somit zu einem neuen deploybaren Artefakt.
Da Entscheidungen von ML-Modellen häufig schwer nachvollziehbar sind, kann nicht garantiert werden, dass sich ein neues Deployment über die gesamte Testmenge auch wirklich besser verhält. Aus diesem Grund muss jede dieser Stellschrauben nachvollziehbar versioniert werden. Damit kann für jede Permutation auch im Nachhinein eine transparente Reproduzierbarkeit sichergestellt werden.
Abbildung 1 zeigt, wie die einzelnen Artefakte in datengetriebenen Projekten zusammenspielen. Aus einem erfolgreichen Data-Science-Experiment resultiert, analog zur Binärdatei bei der Applikationsentwicklung, ein neues Modell als deploybares Artefakt. Das reicht jedoch noch nicht aus. Die Genauigkeit eines ML-Modells hängt stark von der Vorverarbeitung der Daten ab. Werden beispielsweise Trainingsdaten im Experiment skaliert, dann gehören auch produktive Daten skaliert. Daher muss nicht nur das Modell, sondern auch der Code für die Datenvorverarbeitung als Artefakt versioniert werden.
Im Gegensatz zu Quellcode erreichen Binärdateien wie Gewichte und Trainingsdaten oft Größen von mehreren Giga- bis Terabyte und sind damit nur schwer mit üblichen Versionskontrollsystemen (VCS) wie Git oder SVN versionierbar. Als Alternativen setzen sich immer mehr kostengünstige und ausfallsichere Cloud-Speicher durch, in denen die Daten abgelegt werden. Abbildung 2 fasst die Aufteilung zwischen Code und Binärdaten noch einmal zusammen.
Tools wie Git Large Filesystem (Git-LFS) und DVC helfen beim Management der Artefakte wie Trainingsdaten und Modellen, die zu groß für klassische VCS sind. Dabei integriert sich DVC beispielsweise nahtlos in Git und grenzt große Binärdateien wie Bilder, Archive oder Modelle vom eigentlichen Code ab. Jedes Experiment wird, wie Features auch, in einem eigenen Branch verwaltet. Große Dateien werden gar nicht erst vom VCS erfasst.
Im Repository finden sich lediglich Referenzen auf die Binärdateien. Die Daten selbst werden lokal in einem Cache und bei Bedarf auch in der Cloud persistiert.
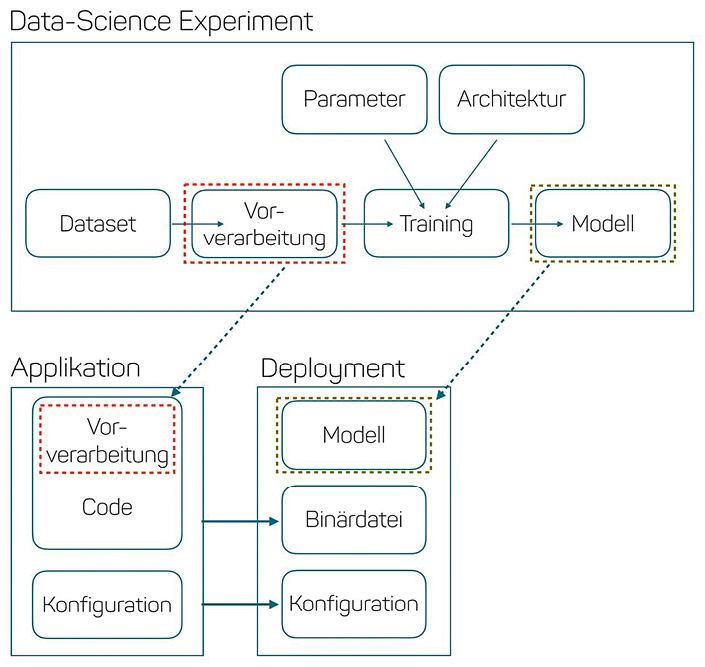
Abb. 1: Artefakte in datengetriebenen Projekten
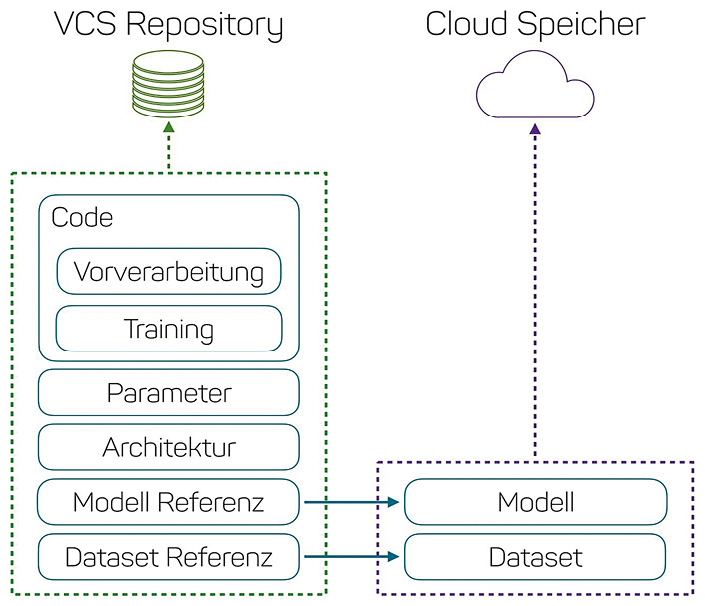
Abb. 2: Aufteilung der Daten auf das Versionskontrollsystem und den Cloud-Speicher
Faustregeln für erfolgreiche ML-Projekte
Weitere Lücken entstehen durch fehlende Praktiken bei der Validierung und dem reproduzierbaren Training von Modellen. Bereits im Jahr 2016 wurde der Artikel “What’s your ML Test-Score: A rubric for ML production systems” [Bre16] veröffentlicht. Er beschreibt Best Practices bei der Entwicklung von ML-Systemen.
Je nach Projektgröße müssen nicht alle der 28 genannten Faustregeln bis ins kleinste Detail berücksichtigt werden. Die folgenden Konzepte helfen jedoch in nahezu jedem datengetriebenen Projekt, die Arbeitsweisen von Softwareentwicklung und Data-Science mit wenig Aufwand näher zusammenzubringen.
Die Baseline als erstes Modell
Eine dieser Faustregeln ist die Entwicklung einer Baseline zu Beginn des Projekts. Große Softwareprojekte werden häufig testgetrieben entwickelt. Das bedeutet, vor der Entwicklung eines neuen Features wird ein Test entwickelt, der die Funktionalität des Features verifiziert. Der eigentliche Code wird dann während der Entwicklung fortlaufend durch den Test validiert.
Ein solcher Test hat weitreichende Auswirkungen. Wichtiger als Stabilität bei Änderungen zu gewährleisten, ist das Design, über das sich die Entwickler bei der Entwicklung der Tests gezwungenermaßen Gedanken machen müssen. Denn ein Test dokumentiert die fachliche Anforderung und legt fest, wie Daten in das System fließen und zurückgegeben werden.
Ähnlich wird auch in ML-Projekten vorgegangen. Noch bevor ein komplexes Modell entwickelt und trainiert wird, wird eine sogenannte Baseline erstellt. Sie ist ein möglichst simples Modell, das vielleicht nicht das beste Ergebnis liefert, dafür aber verständlich und schnell zu implementieren ist.
Die Baseline lässt sich am besten mit einem anschaulichen Beispiel aus der Bild-erkennung beschreiben: der Unterscheidung zwischen Bananen und Zitronen. Beide Obstsorten sind gelb und lassen sich schlecht anhand der Farbe unterscheiden. Jedoch ist eine Banane länglich und gleicht einer Linie, während eine Zitrone rund und kreisähnlich ist. Daraus lässt sich ein einfaches Modell ableiten. Wird auf einem vorgegebenen Bild ein Kreis gefunden, ist es eine Zitrone, in allen anderen Fällen ist es eine Banane. Ein solcher Algorithmus lässt sich mit Frameworks wie beispielsweise OpenCV [Bra00] in nur wenigen Zeilen Code lösen.
Auf dem frei verfügbaren Datensatz von Horea Muresan und Mihai Oltean [Mur18] hatte dieses einfache Modell bereits eine Genauigkeit von 95,8 Prozent. Damit wird schon zu Beginn des Projekts, noch bevor komplexe Modelle entwickelt werden, die Ausführung der gesamten Verarbeitungs-Pipeline vom Anfang bis zum Ende sichergestellt, um früh Stolpersteine aufzudecken. Nebenbei hilft dieses Vorgehen bei der genaueren Anforderungsdefinition und deckt damit Designschwächen, wie zum Beispiel eine fehlerhafte Behandlung mehrerer Früchte auf einem Bild, bereits zu Anfang des Projekts auf.
Experimente reproduzierbar durchführen
Durch die Kombination von konsequenter Versionierung und der frühen Validierung durch Baselines lassen sich Modelle von Anfang an reproduzierbar trainieren und evaluieren.
Dabei helfen Tools wie DVC mit einfach zu implementierenden Daten-Pipelines, dem Wust der anfangs erwähnten Stellschrauben Herr zu werden. DVC bietet, neben der Möglichkeit, Artefakte zu verwalten, auch eine leichtgewichtige Workflow-Engine. Ähnlich zu Workflow-Engines wie Apache Airflow [AirF] oder Spotify Luigi [Luigi] können mit DVC einzelne Prozessschritte wie Vorverarbeitung, Modelldefinition oder Training als eigenständige Komponenten, den sogenannten Tasks, implementiert werden. Im Gegensatz zu dessen bekannteren Vertretern sind Tasks in DVC losgelöst von Programmiersprachen, Technologien und Frameworks. Ein einfaches dvc run führt beliebige Befehle aus, die über definierte In- und Outputs Tasks zu komplexen ML-Workflows verbinden.
Ein einfaches Beispiel für eine Pipeline zeigt Listing 1. Der erste Aufruf von dvc run lädt mit curl den Fruits360-Datensatz (siehe [Mur18]) herunter und hinterlegt das Archiv anschließend in DVC. Beim zweiten Aufruf von dvc run wird das Archiv als Abhängigkeit referenziert und entpackt. Ist die Datei vorhanden, wird der zweite Befehl direkt ausgeführt, falls nicht, wird sie dem Abhängigkeitsbaum entsprechend, heruntergeladen.
Mit dvc repro lassen sich der gesamte Abhängigkeitsbaum aufbauen, Änderungen ermitteln und bei Bedarf Teile der oder die gesamte Pipeline neu ausführen. In Kombination mit Git können so-
mit unterschiedliche Modellarchitekturen, Parameter und Trainingsdaten in eigenen Branches verwaltet und jederzeit reproduzierbar ausgeführt werden.
Continuous Deployments für ML-Modelle
Versionierung, Baselines und Reproduzierbarkeit deuten bereits darauf hin – ein Modell wird nicht nur einmal trainiert und deployed, sondern, wie Quellcode auch, stetig weiterentwickelt und verbessert. Dabei existiert für das reine Deployment bereits eine Vielzahl von Lösungen. Das wohl bekannteste Beispiel ist TensorFlow Serving, eine Laufzeitumgebung für Modelle, die mit Googles TensorFlow [TensorF] erstellt wurden.
Trotzdem, während die Begriffe Continuous Integration (CI) und Continuous Deployment (CD) in Softwareprojekten zum Standard gehören, trifft man sie in datengetriebenen Projekten selten an. Erprobte Praktiken, die helfen, den Aufbau von Build- und Deployment-Pipelines für ML-Modelle zu erleichtern, werden in den nachfolgenden Abschnitten genauer betrachtet.
Modellvalidierung gegen den Ground-Truth
Listing 1: Workflows mit dvc run
Eine Praktik, die Entwicklern das automatisierte Deployment erleichtert, ist die Validierung neuer Modell-Releases gegen einen Ground-Truth. Der Ground-Truth ist ein kleines, dem Modell fremdes und gelabeltes Dataset. Der Test gegen den Ground-Truth prüft, ob ein neues Modell auch wirklich bessere Ergebnisse berechnet als dessen Vorgänger. Nur dann wird es auch deployed. Ein solches Quality-Gate ermöglicht einen hohen Automatisierungsgrad beim Deployment, ähnlich wie er bereits in Standardprojekten erreicht wird.
Wie der Ground-Truth mit dem Deploymentprozess zusammenspielt, zeigt Abbildung 3.
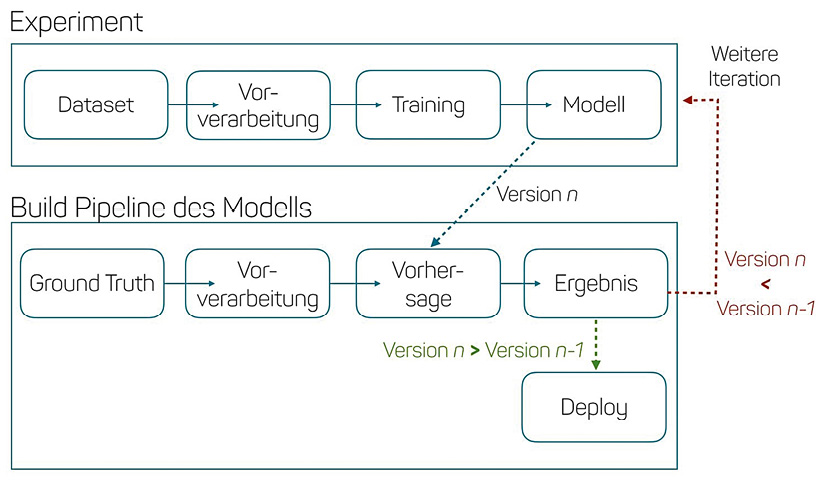
Abb. 3: Ground-Truth als Quality-Gate
Stabile Systeme durch Canary-Deployments
Ein validiertes Modell garantiert jedoch noch immer nicht, dass es auch dem Produktionsbetrieb und dessen Daten gewachsen ist. Damit ein neues Modell nicht gleich auf die gesamte Kundschaft losgelassen wird, haben sich in der Praxis sogenannte Canary-Deployments durchgesetzt. Das bedeutet, dass neue und alte Modelle parallel deployed und betrieben werden. Es wird jedoch nur ein kleiner Teil der Anfragen an das neue Modell weitergereicht. Sind die Ergebnisse über einen längeren Zeitraum valide, wird das neue Modell für alle Anfragen ausgerollt.
In TensorFlow Serving ist dies zum Beispiel sehr leicht durch sogenannte Versions-Label möglich. Dabei wird die Canary-Version mit dem Tag canary markiert. Die Laufzeitumgebung kümmert sich anschließend um das korrekte Routing der Anfragen. Verhält sich das neue Modell wider Erwarten schlechter als das vorherige Release, wird es zurückgerollt und die alte Version wird weiter verwendet.
Fazit
Trotz der immer größer werdenden Anzahl datengetriebener Projekte ist es immer noch schwierig, die Praktiken und Vorgehen aus der Softwareentwicklung mit Data-Science-Experimenten in Einklang zu bringen. Artikel und Tools wie “What’s your ML Test-Score“ [Bre16], DVC und TensorFlow Serving helfen, diesem Trend langsam entgegenzuwirken.
Denn mit nur wenigen Kniffen, wie dem konsequenten Versionieren der Artefakte, der Entwicklung von Baselines und dem Definieren eines Ground-Truth als Quality-Gate, lassen sich schnell hohe Automatisierungsgrade und kurze Deployment-Zyklen erreichen, wie man sie aus gut geführten Softwareprojekten kennt.
Weitere Informationen
[AirF] Apache Airflow, siehe: https://github.com/apache/airflow
[Bra00] G. Bradski, The OpenCV Library, in: Dobb’s Journal of Software Tools, 1.11.2000, siehe: http://www.drdobbs.com/open-source/the-opencv-library/184404319
[Bre16] E. Breck, Sh. Cai, E. Nielsen, M. Salib, D. Sculley, What’s your ML test score? A rubric for ML production systems, in: NIPS, 2016, siehe: https://storage.googleapis.com/pub-tools-public-publication-data/pdf/45742.pdf
[DVC] Data Version Control, Iterative.ai, siehe: https://dvc.org
[TensorF] Google TensorFlow, siehe: https://www.tensorflow.org
[Luigi] Spotify Luigi, siehe: https://github.com/spotify/luigi
[Mur18] H. Muresan, M. Oltean, Fruit recognition from images using deep learning, in: Acta Universitatis Sapientiae, Informatica 10 (Juni), S. 26 ff., siehe: https://doi.org/10.2478/ausi-2018-0002









