

Software wird immer noch von Menschen entwickelt und das macht sie anfällig für Fehler und Mängel. Daher werden Entwicklung und Testen in einen kontinuierlichen Prozess integriert (Continuous Integration und Dev-Ops), bei dem es vor allem um die Verkürzung der Feedback-Zyklen geht. Doch während die Entwicklung von Software immer einfacher wird, erweist sich nun die Qualitätssicherung als das nächste große Nadelöhr.
Testmanager stehen vor zwei Herausforderungen: Einerseits müssen sie ihre Ressourcen immer effizienter einsetzen und priorisieren. Andererseits benötigen die Entwickler immer schnelleres Feedback für ihre Arbeit, am besten schon in der Minute, in der sie den Code schreiben, auch wenn das komplette Testen des in Entwicklung befindlichen Systems mehrere Stunden dauern kann.
Alle größeren Softwareprojekte stehen vor dem gleichen Problem: Der Testaufwand wird derart groß, dass er mindestens abschreckend, wenn nicht sogar kontraproduktiv wirkt. Daher benutzen wir eine wachsende Zahl von Testwerkzeugen. All diese Tools produzieren immer mehr Daten, die wiederum immer mehr Zeit zur Analyse erfordern. Dieser Teufelskreis lässt sich nur durch Testautomatisierung durchbrechen.
In 5 Schritten von der manuellen zur vollautomatischen Qualitätssicherung
Die Entwicklung vom manuellen Testen hin zu einer KI-gestützten Qualitätssicherung kann man als eine Evolution betrachten, die in fünf Schritten abläuft. Sie reicht von einem Testsystem, das die Software nur anhand manuell geschriebener Tests versteht, bis hin zur Messung von Key Performance Indicators (KPI), aufgrund derer das System sich selbst bewertet und verbessert.
Mit jedem Schritt wird das Abstraktionsniveau des Testens erhöht. Es führt von den eigentlichen Softwarefunktionen bis hin zu den durch die Software gesteuerten Geschäftsfunktionen selbst. So erzeugt jeder Schritt auch mehr Komplexität im Testsystem selbst. Zu Beginn automatisieren die Skripte nur Entscheidungen auf wirklich niedriger Ebene, aber dann werden immer mehr Prozesse automatisiert und die Entscheidungen dem System selbst überlassen. Die einzelnen Schritte und ihre Kennzeichen sind in Tabelle 1 und Abbildung 1 zusammengefasst.
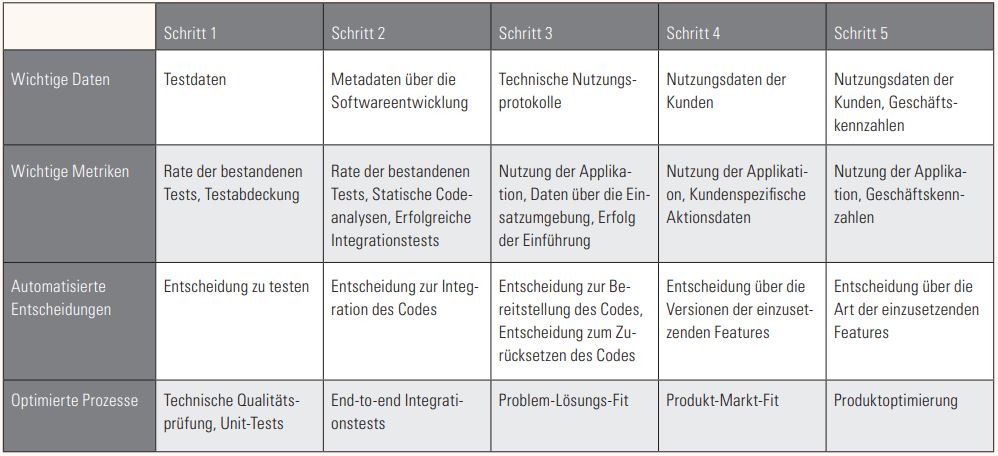
Tabelle 1: Die fünf Evolutionsstufen zur vollautomatischen Qualitätssicherung
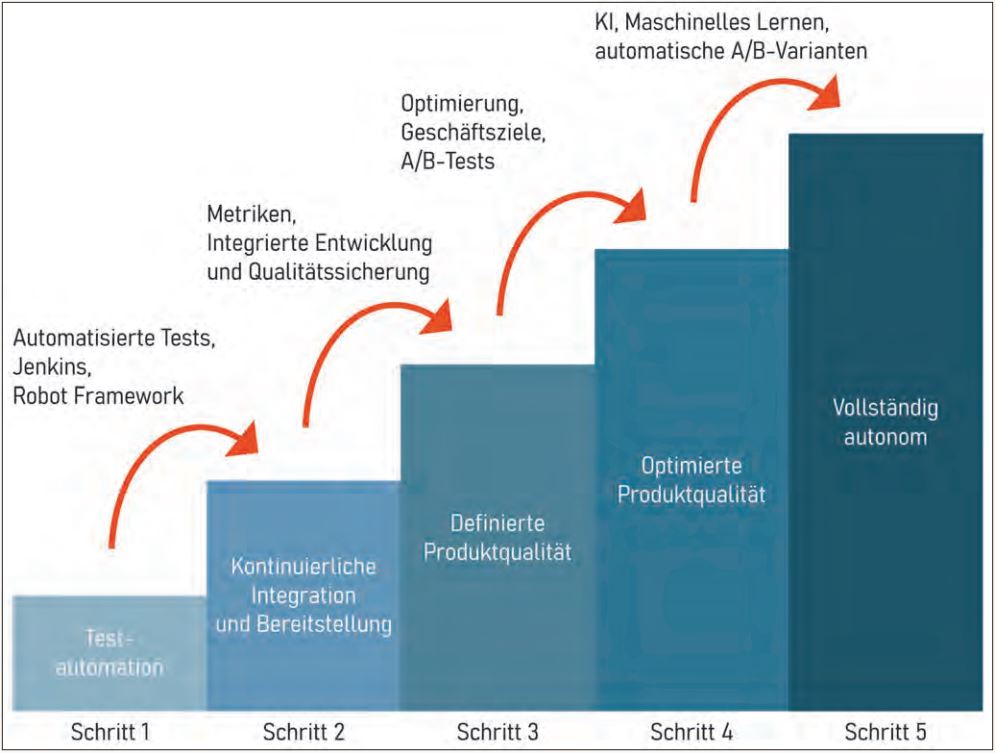
Abb. 1: Automatisierte Qualitätssicherung
Schritt 1 - Testautomatisierung
Schritt 1 findet in Softwareunternehmen immer mehr Akzeptanz. Tests werden mithilfe von Werkzeugen wie Jenkins automatisiert, sobald die Bereitstellung neuer Softwarefunktionen auf Testservern automatisiert wird. Ein gutes Beispiel dafür wäre ein Unternehmen, das git als Versionskontrollsystem einsetzt. Wenn ein Commit gemacht wird, löst Jenkins Tests aus, die mit dem Robot-Framework durchgeführt werden. Diese Daten werden dann an den Entwickler weitergeleitet.
In dieser Phase könnte der Freigabeprozess immer noch manuelle Testschritte beinhalten. Die Freigabeentscheidung wurde nicht automatisiert und ist noch immer vollständig unter menschlicher Kontrolle. Die zum Testen verwendeten Daten befinden sich größtenteils innerhalb der Testfälle, es werden noch keine statischen Analysen oder andere Qualitätssicherungsmechanismen verwendet.
Schritt 2 - Kontinuierliche Integration und Bereitstellung
In diesem Entwicklungsschritt sind alle Systeme innerhalb der Deployment-Pipeline miteinander verbunden und ihr Verhalten ist automatisiert. Das System kann neue Versionen automatisch bereitstellen und jede Funktion wird automatisch getestet, bevor ihr Code in den Hauptentwicklungszweig integriert wird. Hier werden Daten aus allen Teilen der Entwicklungs-Pipeline in die QS-Pipeline integriert. Die statische Analyse mit Werkzeugen wie Sonarqube wird zur Verifizierung der Codequalität verwendet. Diese Pipeline kann die neuen Funktionen ohne menschliches Eingreifen in der Produktion einsetzen.
Alle Daten über die Systemqualität werden im Entwicklungsprozess und nicht in der Produktionsumgebung gesammelt. Der Schwerpunkt der automatisierten Tests liegt meist auf der technischen Qualität der Software, nicht auf ihrem funktionalen oder geschäftlichen Wert. Die Entscheidung über den Einsatz kann auf der Grundlage der technischen Qualität automatisiert werden.
Schritt 3 - Definierte Produktqualität
Der nächste Schritt besteht darin, dass die Optimierung der Tests auf Basis der tatsächlichen Nutzung der Software erfolgt und nicht nur unter Verwendung von Entwicklungsmetriken. Dadurch verschiebt sich die Rolle des automatisierten Testsystems weg von der reinen technischen Qualitätsprüfung des Codes hin zur Validierung von Geschäftshypothesen. Dieser Schritt erfordert ein viel klareres Verständnis dafür, wie Geschäftsziele mit Softwareentwicklungszielen verknüpft sind.
In diesem Entwicklungsschritt wird der Einfluss der Software auf die tatsächliche Qualität des Geschäftsprozesses zur Grundlage des Testens. Dieser kann zum Beispiel in Webanwendungen mithilfe von Google Analytics oder ähnlichen Tools gemessen werden, wobei Nutzungsprotokolle und sogar Abrechnungsdaten analysiert werden. All diese Daten sollten zu einer einzigen Metrik aggregiert werden, mit der das Niveau der getesteten Version beurteilt werden kann.
Diese Daten dienen zur Erstellung von A/B-Tests, bei denen verschiedene Varianten der Software miteinander verglichen werden. Hier wird die Entscheidung darüber, welche Varianten oder Funktionen tatsächlich in das Produkt integriert werden sollen, automatisiert. A/B-Tests an sich erfordern weder ML noch KI. Automatisierungstools wie amazon fargate oder andere erlauben es, die zugeordneten Statistiken zu verfolgen. In diesem Schritt können Menschen ihre Entscheidungen immer noch auf der Grundlage der in den A/B-Tests gesammelten Daten treffen.
Schritt 4 - Optimierte Produktqualität
Auch in Schritt 4 werden die Metriken zur Produktqualität immer noch von Menschen definiert. Doch das DevOps-System kann jetzt automatisch eine Vielzahl neuer Code-Varianten erstellen, für die automatisch A/B-Tests durchgeführt und anhand der gewählten Metriken beurteilt werden. Die Fähigkeit zur automatischen Erstellung von A/B-Varianten muss mit strengen Regressionstests kombiniert werden, damit die Kernfunktionalität der Software funktionsfähig bleibt, während andere Versionen automatisch variiert werden können.
Da das System jetzt große Mengen an Varianten erzeugen kann, muss auch die Analyse mithilfe von ML- oder KI-Systemen automatisiert werden, da diese Muster in den Daten entdecken, die Menschen nicht so leicht finden können. Diese Art von Systemen wurden schon von einigen größeren Akteuren entwickelt, aber nur selten der Öffentlichkeit gezeigt. Facebook [FB18] und Netflix [Yu19] haben Vorträge über diesen Schritt der Automatisierung gehalten und die derzeitigen Implementierungen sind auf dem neuesten Stand der Technik.
Schritt 5 - Vollständig autonom
Der nächste logische Schritt ist es, die Erstellung der Regeln selbst zu automatisieren.
Dabei versucht das System, aus allen möglichen gesammelten Messungen eigenständig die Parameter und Ziele für weitere Optimierungen abzuleiten. Möglicherweise generiert das System anhand der wichtigsten KPI des Geschäfts Vorschläge, die das System selbst verändern, zum Beispiel die Optimierung von Recommender-Systemen. In diesem Schritt priorisiert das System die Geschäftsziele gegenüber dem Softwareartefakt. Es beginnt, sich selbst zu verbessern, um den Effekt und die Rentabilität der Softwareinvestition auf die Geschäftsziele zu maximieren. So könnte zum Beispiel eine vollständig autonome E-Commerce-Lösung testen (und entscheiden), ob Profitabilität, Umsatz oder Marktanteil oder eine Kombination davon maximiert werden soll.
Fazit
Betrachtet man diese fünf Schritte in der Evolution des Testens, so lassen sich drei wichtige Muster erkennen. Erstens bewegt sich die Validierung von klaren technischen Zielen mehr in Richtung abstrakter Geschäftsziele. Es geht nicht mehr nur um die Frage, ob eine Funktion genau das tut, was sie tun sollte, sondern was sie tatsächlich zum Erreichen der Geschäftsziele beiträgt.
Ein weiteres Muster ist die zunehmende Integration von Daten aus allen Phasen des Software-Lebenszyklus. In den ersten Schritten der Testautomatisierung werden nur Daten aus dem Test verwendet, während alle anderen Beurteilungen dem Menschen vorbehalten sind. Mit jedem weiteren Schritt werden mehr Daten gesammelt und zu einem riesigen Datensee verknüpft. Diese Daten können dann verwendet werden, um noch mehr Analysen in die Deployment-Pipeline zu integrieren, um die Validierung der Software zu automatisieren.
Das dritte Muster ist die Automatisierung von Schlüsselentscheidungen beziehungsweise die bessere Beantwortung der schwierigen Frage, was verbessert, was weggelassen, was neu entwickelt werden sollte. Hier gilt es, die Möglichkeiten der KI sinnvoll zu strukturieren, zum Beispiel in Hinblick auf die Bewertung von A/B-Varianten durch strenge Regressionstests. Ich sehe dies als den wichtigsten Fortschritt, der durch die Automatisierung ermöglicht wird. Ich glaube, dass die Evolution des Testens uns hilft, bessere Entscheidungen zu treffen und uns auf die Schaffung von Werten an den Stellen zu konzentrieren, an denen sie am meisten benötigt werden.
Referenzen
[FB18] Getafix: How Facebook tools learn to fix bugs automatically, 6.11.2018, siehe:
https://engineering.fb.com/developer-tools/getafix-how-facebook-tools-learn-to-fix-bugs-automatically/
[Yu19] A. Yu, How Netflix Uses AI, Data Science, and Machine Learning – From A Product Perspective, Becoming Human, 27.2.2019, siehe: https://becominghuman.ai/how-netflix-uses-ai-and-machine-learning-a087614630fe









