

Umfangreiche Sprachmodelle, Large Language Models (LLM) genannt, haben zahlreiche Lebensbereiche im Handumdrehen erobert. In der Softwareentwicklung spielen diese Modelle ebenfalls eine immer wichtigere Rolle, beispielsweise bei der Test- und Testdatengenerierung. Sprachmodelle sind in der Lage, natürlichsprachlichen Text zu verstehen und zu erzeugen. Dadurch sind sie gut geeignet, Anforderungen oder vorhandenen Code zu analysieren, um darauf aufbauend beispielsweise Unittests und die zugehörigen Testdaten zu erzeugen.
Das erlaubt es, auch große Mengen an Tests und Testdaten in kürzester Zeit zu erzeugen, da ein Großteil der manuellen Implementierung wegfällt. Dieser Zeitaufwand ist nämlich ein vielfach genutztes Argument gegen den Einsatz automatisierter Tests, was durch die Nutzung von Sprachmodellen deutlich entschärft wird. Dieses Vorgehen wirft in der Praxis allerdings die Frage auf, wer die Resultate der LLM überprüft und ob Tests für die Sprachmodelle an sich notwendig sind und wie sich diese Tests umsetzen lassen.
Diese drei Aspekte, die Test- und Testdatengenerierung sowie das Testen von Sprachmodellen, sind im Fokus dieses Artikels. Für den praktischen Teil kommt TypeScript als Beispielsprache zum Einsatz. Der Einsatz von LLM lässt sich aber problemlos auch auf andere Programmiersprachen erweitern.
Herausforderungen
LLM sind neuronale Netzwerke für maschinelles Lernen, die mit Daten-Inputs und -Outputs trainiert werden, um natürlichsprachliche Texte zu generieren und zu verstehen. Seit der Veröffentlichung von ChatGPT im November 2022 und Metas (Facebook) LLaMA im Februar 2023 haben LLM stark an Bedeutung gewonnen und kommen in verschiedenen Anwendungsfällen zum Einsatz. Dazu gehört unter anderem die Automatisierung von Aufgaben, die Unterstützung bei Kreativaufgaben oder in der Softwareentwicklung.
LLM können unter anderem automatisch Unittests sowie andere Tests erzeugen und lassen sich direkt in den Softwareentwicklungsprozess integrieren, um die Qualität und Effizienz der entwickelten Software zu verbessern. Zum Beispiel für die Codegenerierung, das Erkennen und Beheben von Fehlern und Code-Refaktorisierungen. Dabei gibt es etliche Herausforderungen, beispielsweise bezüglich der Entwicklungskosten von LLM, der Optimierung von Sprachmodellen auf spezifische Anforderungen sowie datenschutzrechtlichen Fragen.
Darüber hinaus ist der Test der LLM selbst eine nicht zu unterschätzende Aufgabe. Kommen Sprachmodelle im großen Umfang zum Einsatz, egal ob manuell oder automatisiert, sind geeignete Methoden zu ergreifen, um die Leistungsfähigkeit zu evaluieren. Unittests und Testdaten dürfen im besten Fall nicht von der individuellen Performance bei bestimmten Prompts oder Eingaben abhängen. Beispiele für den Test von LLM sind Reverse-Turing-Tests. Auch die Feinabstimmung von LLM für bessere Leistung in spezifischen Anwendungsfällen ist eine Maßnahme, die Qualität für ebendiese Anwendungsfälle zu verbessern.
Das Testen mit LLM
Ein Aspekt beim Testen von Software ist die Implementierung von Unittests. Sie spielen eine Schlüsselrolle bei der Gewährleistung der Korrektheit von Software. Ein Unittest ist eine Art von Softwaretest, der sich auf einzelne Komponenten oder Einheiten einer Software konzentriert [Fow14]. Das Ziel eines Unittests besteht darin, eine Entität im Code zu testen, sicherzustellen, dass sie korrekt codiert ist, ohne Fehler, und dass sie die erwarteten Ausgaben für alle relevanten Eingaben liefert. Eine Einheit kann eine Funktion, Methode, Modul, Objekt oder eine andere Entität im Quellcode einer Anwendung sein. Unittests bieten Feedback zur Codequalität, schützen vor Regressionen und ermöglichen Refaktorisierungen. Diese Tests werden in der Regel von Entwicklern durchgeführt und finden früh im Entwicklungsprozess statt, bevor der Code integriert und als Gesamtsystem getestet wird.
Diese Ausführung verdeutlicht, dass sich Unittests gut dafür eignen, automatisiert erstellt und ausgeführt zu werden. Der Grund ist, dass sich ein solcher Test in der Regel auf einen eher kurzen, wohldefinierten Teil des Codes bezieht. Dieser lässt sich automatisch analysieren und mit Tests sowie Testdaten abdecken. Die manuelle Erstellung von Unittests ist allerdings eine mühsame Aufgabe, was den Bedarf an Automatisierung verdeutlicht.
LLM kommen daher vermehrt in diesem Anwendungsfall zum Einsatz, indem sie automatisch den zu testenden Code analysieren und anhand weiterer Informationen, beispielsweise aus einer Dokumentation, die Testfälle erzeugen. LLM lassen sich auch zur Generierung von Testdaten nutzen. Sie können komplexe Datensätze erstellen, die verschiedene Szenarien und Randbedingungen abdecken, um die Robustheit der Software zu gewährleisten. Diese Aufgaben lassen sich bereits von allgemeinen LLM gut abdecken, die nicht durch Finetuning oder andere Methoden für den Anwendungsfall der Testerzeugung optimiert wurden. Darüber hinaus existieren zahlreiche spezialisierte Code-LLM, die für die Erzeugung von Code in verschiedenen Programmiersprachen optimiert sind. Beispiele sind Replit Code und Code Alpaca [AI-LLM].
Testgenerierung für TypeScript
In den nachfolgenden Beispielen kommt TypeScript zum Einsatz, eine von Microsoft entwickelte Programmiersprache, die auf JavaScript aufbaut und zusätzliche Typisierungsfunktionen bietet, die es ermöglichen, effizienteren und sichereren Code zu schreiben. TypeScript ist dabei eine Sprache von vielen, für die das automatische Erzeugen von Testfällen funktioniert.
Zahlreiche Beispiele, auch in der Forschung [Sch23], nutzen adaptive Testgenerierungsverfahren auf Basis von LLM. Beispielsweise die Anwendung TestPilot, die eine LLM namens Codex nutzt, um automatisch Unittests für ein gegebenes Programm zu generieren, ohne dass zusätzliches Training oder punktuelles Lernen anhand von Beispielen bestehender Tests erforderlich ist. In diesen Anwendungsfällen wird das Prompting genutzt, um das Sprachmodell mit Eingabeaufforderungen zu versorgen, die die Signatur und die Implementierung einer zu testenden Funktion sowie Anwendungsbeispiele aus der Dokumentation enthalten. Wenn ein generierter Test fehlschlägt, versucht die adaptive Komponente von TestPilot, einen neuen Test zu generieren, der das Problem behebt, indem sie das Modell mit dem fehlgeschlagenen Test und der Fehlermeldung erneut auffordert.
Die folgenden Beispiele sind mittels ChatGPT entstanden, um ein allgemein verfügbares und weitläufig genutztes Tool zu zeigen. ChatGPT, ein LLM von OpenAI, lässt sich sehr gut für die Testgenerierung für TypeScript-Code nutzen. Da es sich um ein allgemeines LLM handelt und nicht um ein spezialisiertes Modell, steuern wir es mittels Prompting über die bekannte Oberfläche von ChatGPT an.
Wir nehmen für das erste Beispiel an, dass es eine Funktion zur Berechnung der Fakultät einer Zahl gibt. Der Code ist in Listing 1 zu sehen.

Listing 1: Fakultät
ChatGPT lässt sich nun dazu nutzen, einen Unittest für diese Funktion zu generieren. Dazu wird die Aufgabe, einen Unittest zu erstellen, inklusive des Code-Beispiels als Prompt an ChatGPT übergeben. Der Prompt lautet wie folgt, mit dem TypeScript-Programm als Platzhalter, damit es an dieser Stelle nicht unübersichtlich wird:
Gegeben ist folgendes TypeScript-Programm:
"<TypeScript-Programm>"
Bitte erstelle dafür Unit-Tests.
Das Resultat von ChatGPT sind Unittests und eine Anleitung, was noch zu konfigurieren oder zu installieren ist, damit sich diese Tests ausführen lassen. Die erzeugten Unittests, auf Basis von Jest, sind in Listing 2 zu sehen.

Listing 2: Erzeugte Unittests, auf Basis von Jest
ChatGPT denkt sogar daran, eine Testbibliothek zu nutzen und unsere zu testende Funktion per Import-Statement einzubinden. Für das zweite Beispiel nehmen wir eine weniger komplexe Funktion zum Addieren von zwei Zahlen in TypeScript an, siehe Listing 3.
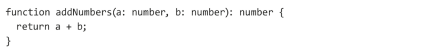
Listing 3: Addition
ChatGPT lässt sich auch hier dazu nutzen, Unittests für diese Funktion zu generieren. Listing 4 zeigt ein Beispiel für einen generierten Test.

Listing 4: Beispiel für einen generierten Test der Addition
In beiden Beispielen hat ChatGPT Unittests generiert, die verschiedene Testfälle abdecken und die Funktionalität der gegebenen TypeScript-Funktionen überprüfen. Im ersten Beispiel hat ChatGPT die Testfälle einzeln erzeugt, im zweiten alle zusammen in einem Test. Diese Generierung lässt sich gut über den Prompt steuern.
Testdatengenerierung
Testdaten sind ein wesentlicher Bestandteil des Softwaretestprozesses, da sie die Grundlage für die Überprüfung der Funktionalität, Leistung und Sicherheit einer Anwendung bilden. Die Qualität der Testdaten beeinflusst direkt die Vollständigkeit und Abdeckung der Tests, wodurch die Qualität der entwickelten Software sichergestellt wird. Die Generierung von Testdaten ist jedoch in vielen Fällen ebenso zeitaufwendig und komplex wie die Implementierung von Unittests, insbesondere bei der Verwendung von manuellen Methoden, um die Testdaten zu erzeugen.
LLM bieten viele Anwendungsfälle zur Generierung von Testdaten, indem sie die Merkmale und Struktur der erforderlichen Testdaten verstehen und relevante Datensätze erzeugen. Durch die Anwendung von LLM auf TypeScript-Code lassen sich auf diese Weise automatisch Testdaten erzeugen, die für verschiedene Testfälle und Szenarien relevant sind.
Ein Beispiel für die Verwendung von LLM zur Generierung von Testdaten ist die Optimierung eines Sprachmodells für die Klassifizierung von Serviceanfragen nach Dringlichkeit. In diesem Fall lässt sich ein LLM nutzen, um strukturierte Testdaten in Form von JSON-Dateien zu generieren, die zur Verbesserung des Sprachmodells beitragen. Die Vorteile der Verwendung von LLM zur Generierung von Testdaten umfassen eine schnellere und effizientere Erstellung von Testdaten, die Möglichkeit, komplexe und realistische Datensätze zu erstellen, und die Fähigkeit, Testdaten für spezifische Anwendungsfälle und Szenarien zu generieren.
Das nachfolgende Beispiel nutzt die Funktion addNumbers aus dem vorherigen Beispiel zur Erzeugung der Unittests. Um Testdaten für diese Funktion zu erstellen, bietet es sich an, verschiedene Testfälle und Szenarien zu berücksichtigen, die die korrekte Funktionsweise der Funktion überprüfen. ChatGPT erstellt beispielsweise die Testdaten aus Listing 5 über einen Prompt, der die Aufforderung enthält, Testdaten für den angegeben Code zu erzeugen.

Listing 5: Von ChatGPT erstellte Testdaten
Dabei erzeugt das LLM nicht nur die Eingabedaten, sondern auch die korrekten Ausgabedaten für die Tests. Das Sprachmodell hat somit nicht nur die Aufgabenstellung „verstanden“, sondern auch die Implementierung der zu testenden Funktion. Diese Kombination macht Sprachmodelle bei der Test- und Testdatengenerierung so mächtig.
Um die Robustheit der Funktion addNumbers zu testen, lassen sich zudem Testdaten erstellen, die Randbedingungen abdecken, wie zum Beispiel sehr große oder sehr kleine Zahlen. Das zeigt Listing 6, das ebenfalls mit ChatGPT erstellt wurde.

Listing 6: Generierter Test der Robustheit von addNumbers
In beiden Beispielen haben wir Testdaten erstellt, die verschiedene Eingabewerte für die Funktion addNumbers enthalten, zusammen mit den erwarteten Ausgabewerten. Diese Testdaten können dann in Unittests verwendet werden, um die korrekte Funktionsweise der Funktion zu überprüfen.
Eine Herausforderung bei der Verwendung von LLM zur Generierung von Testdaten besteht darin, dass LLM möglicherweise nicht immer die gewünschte Qualität oder Relevanz der Testdaten liefern. Um dieses Problem zu lösen, lassen sich LLM auf spezifische Anwendungsfälle feinabstimmen oder die Kombination von LLM mit anderen Testdatengenerierungsmethoden ist sinnvoll. Eine weitere Herausforderung besteht darin, dass die Verwendung von LLM zur Testdatengenerierung Datenschutz- und Sicherheitsbedenken aufwerfen kann, insbesondere wenn sensible Informationen in den Testdaten enthalten sind.
Das Testen von LLM
Es gibt zahlreiche Gründe, Sprachmodelle zu testen und so herauszufinden, ob sie für einen Anwendungsfall geeignete Antworten beziehungsweise Daten liefern. Beispielsweise ist die Genauigkeit und Zuverlässigkeit zu prüfen, da ungenaue Ergebnisse möglich sind. LLM können zudem Schwierigkeiten haben, domänenspezifisches Wissen zu erfassen und anzuwenden, was gerade bei Unittests und den Testdaten unabdingbar ist. Auch bezogen auf den Bias und die Fairness sind Tests der LLM notwendig, da die Gefahr besteht, dass die Testdaten bestehende Vorurteile aus den Trainingsdaten übernehmen, was zu unvollständigen oder ungenauen Tests führen kann.
Zur Bewertung von Sprachmodellen wurden mehrere Rahmenwerke entwickelt, aber keines von diesen Frameworks ist umfassend genug, um alle Aspekte des Sprachverständnisses abzudecken. Zu diesen Frameworks zählen beispielsweise Big Bench [BigB], GLUE-Benchmark [GLUE], OpenAI Modera-TION API [OPENAIMOD] UND SQUAD [SQUAD], sie haben ihre eigenen Vor- und Nachteile und sind alle valide Möglichkeiten, LLM zu bewerten, decken aber, wie erwähnt, nicht alle Aspekte von Sprachverständnis ab.
Ein oft genutztes Vorgehen ist es, verschiedene Modelle für die Erzeugung von Testfällen zu nutzen, um die Resultate zu vergleichen und so die Modelle zu bewerten.
Beispielsweise lassen sich drei generative Modelle wie CodeGen, Codex und GPT-3.5 nutzen, um damit Testfälle zu generieren. Bewertungskriterien können Kompilierungsraten, Testkorrektheit und Testabdeckung sein. Dabei lassen sich zudem Test-Smells, wie doppelte Asserts und leere Tests, aufspüren und ermitteln, in welchen Modellen das häufiger auftritt als in anderen [Sid23].
Der Einsatz von Sprachmodellen beim Testen von Software und beim Testen von LLM selbst lässt sich zudem durch die Philosophie von Ludwig Wittgenstein überprüfen. Wittgensteins Arbeit, insbesondere seine späteren "Philosophischen Untersuchungen", konzentriert sich auf die Bedeutung von Sprache und Kommunikation und tragen dazu bei, die Erwartungen an sprachverarbeitende KI-Systeme wie LLM zu formulieren [MoT]. Wittgensteins Konzept der „Sprachspiele“ kann auch als Grundlage für das Verständnis der verschiedenen Anwendungsfälle und Szenarien dienen, in denen LLM eingesetzt werden können.
Weitere bekannte Verfahren sind der Reverse-Turing-Test und LoRA (Low-Rank Adaptation). Der Reverse-Turing-Test ist eine Methode zur Evaluierung der Intelligenz von LLM. Im Gegensatz zum klassischen Turing-Test, bei dem ein Mensch versucht, zwischen einem menschlichen Gesprächspartner und einer KI zu unterscheiden, spiegelt der Reverse-Turing-Test die Intelligenz des menschlichen Interviewers wider. Dieser Ansatz ermöglicht es, die Fähigkeiten von LLM wie ChatGPT oder LLaMA besser zu verstehen und zu bewerten. LoRA ist eine Methode zur effizienteren Feinabstimmung von LLM, die mit dem Einfrieren von vortrainierten Modellgewichten arbeitet.
Ganz allgemein bleibt aktuell unklar, wie effektiv ChatGPT und ähnliche LLM bei der Generierung von Unittests sind. Dieser Bereich steht verstärkt im Fokus von Forschungsarbeiten, die beispielsweise empirische Studien durchführen, um die Fähigkeit von ChatGPT zur Generierung von Unittests zu bewerten. Dazu gehören auch quantitative Analysen und Benutzerstudien, um die Qualität der generierten Tests hinsichtlich Korrektheit, Hinlänglichkeit, Lesbarkeit und Benutzbarkeit systematisch zu untersuchen. Ein Resultat dieser Anstrengungen ist es, dass die von ChatGPT generierten Tests zwar immer noch unter Korrektheitsproblemen, einschließlich diverser Kompilierungsfehler und Ausführungsmängel, leiden. Dennoch ähneln die von ChatGPT generierten Tests den manuell geschriebenen, da sie eine vergleichbare Abdeckung, Lesbarkeit und manchmal sogar die Präferenz der Entwickler erreichen, was in der Praxis nicht zu unterschätzen ist [Yua23].
Unabhängig von diesen Methoden ist es wichtig, beim Einsatz von Prompts diese ebenfalls zu testen. Das Vorgehen ähnelt dabei stark dem Testen von Software. Komplexe Prompts lassen sich beispielsweise in kleine und weniger komplexe Prompts zerlegen. Das Resultat dieser Eingabeaufforderungen ist nicht so einfach überprüfbar wie bei deterministischen Funktionen, aber wir haben als Beispiel die Möglichkeit, Eigenschaften abzufragen. Erwarten wir bei Eingabe eines Prompts, dass die Ausgabe bestimmte Merkmale aufweist, können wir die Existenz dieser Merkmale abfragen. Dann ist es weniger relevant, wie genau die Ausgabe aufgebaut ist, wenn die Abfrage der Merkmale wichtig ist und für die Evaluation des Ergebnisses ausreicht.
Ausblick und Fazit
LLM haben das Potenzial, die Softwareentwicklung und verschiedene Berufsrollen erheblich zu beeinflussen und die Interaktion zwischen Menschen und Computer zu revolutionieren. Sie können den Entwicklungsprozess rationalisieren, die Produktivität steigern und die Innovation fördern.
Wie der Artikel gezeigt hat, lassen sich LLM dazu nutzen, automatisch Unittests für verschiedene Programmiersprachen wie Python, Java und JavaScript zu generieren. Ein Beispiel für ein solches Tool ist Tabnine, das kürzlich eine Unittest-Generierungsfunktion in der Beta-Version vorgestellt hat. Tabnine verwendet KI-Technologie, um automatisch Unittests für den Code zu erstellen und so die Codequalität und -stabilität zu verbessern. Ein weiteres Beispiel ist Pythagora, ein Tool, das auf GPT-4 basiert und Unittests für JavaScript-Code generiert. Mit Pythagora können Entwickler einfach einen Befehl ausführen, um Tests für eine bestimmte Funktion in ihrem Code zu erstellen.
Die zunehmende Verbreitung von LLM in der Softwareentwicklung wirft ethische Fragen auf, wie den Schutz der Privatsphäre, Markenintegrität und die Verstärkung bestehender Vorurteile. Um verantwortungsvolle KI-Forschung und -Anwendung zu realisieren, ist es wichtig, Ethik in den Forschungsund Entwicklungsprozess zu integrieren.
Weitere Informationen
[AI-LLM] Verschiedene Code-LLMs,
github.com/AI-LLM/ai-llm.github.io/blob/main/Code-LLM-alternatives.md
[BigB] Das Framework Big Bench,
github.com/google/BIG-bench
[Fow14] M. Fowler, UnitTest, 2014,
martinfowler.com/bliki/UnitTest.html
[GLUE] Das GLUE-Benchmark-Framework,
gluebenchmark.com/
[MoT] Die Philosophie von Ludwig Wittgenstein,
www.ministryoftesting.com/articles/ca67a167
[OpenAIMod] Das OpenAI API zur Moderation von LLMs,
platform.openai.com/docs/api-reference/moderations
[Sch23] M. Schäfer et al., An Empirical Evaluation of Using LLMs for Automated Unit Test Generation, 2023,
arxiv.org/abs/2302.06527
[Sid23] M. L. Siddiq, An Empirical Study of Using LLMs for Unit Test Generation, 2023,
arxiv.org/abs/2305.00418
[SQuAD] Das SQUAD-Framework, Stanford Question Answering Dataset,
rajpurkar.github.io/SQuAD-explorer/
[Yua23] Zhiqiang Yuan, No More Manual Tests? Evaluating and Improving ChatGPT for Unit Test Generation, 2023,
cs.paperswithcode.com/paper/no-more-manual-tests-evaluating-and-improving









