

Ist der Kaufzeitpunkt gekommen, führt der Kunde einen letzten „Check“ im Autohaus durch und erwartet eine zügige bis sofortige Bereitstellung seiner Wunschkonfiguration. Automobilhersteller sind also angehalten, ihre Produktionsplanung verstärkt auf Ebene der Konfigurationswünsche der Kunden abzustimmen, um eine besondere Customer Journey zu erzielen.
Die steigenden Anforderungen der Kunden an individualisierte Fahrzeugkonfigurationen (Karosserie, Motorisierung, Farbe, Polster etc.) bei einer gleichzeitig hohen Erwartungshaltung hinsichtlich des Bereitstellungszeitpunktes stellen die Automobilhersteller vor eine große Herausforderung. So ist der Kunde über seine Online-Produktrecherchen und Beratungsgespräche mit Freunden und Verwandten bereits sehr gut informiert in Bezug auf die möglichen Kombinationen in der Fahrzeugkonfiguration und hat diese Vorstellung meist frühzeitig gefestigt [Mue15].
Diesen Anforderungen der Kunden nach individuellen Produkten stehen die wirtschaftlichen Herausforderungen der Hersteller nach optimaler Kapazitätsauslastung ihrer Fertigungsstraßen entgegen [SRE17]. Das bedeutet, dass es im Wettbewerbsinteresse der Automobilhersteller liegt, frühzeitig zu erkennen, welche Konfigurationspräferenzen sich im Internet herauskristallisieren, um so eine wirtschaftliche und gleichzeitig individuelle Massenproduktion in der Produktionsprogrammplanung zu berücksichtigen.
Der Einfluss von Social-Media- und Online-Quellen auf Kunden wird in der Produktionsplanung in anderen Branchen bereits berücksichtigt [PiW16] und sollte auch im Automotive-Bereich in die Planung integriert werden. Hierzu haben wir unter dem Aspekt der Farbe mittels eines Proof of Concept (PoC) einen Prototyp in einer Azure-Cloud-Umgebung aufgebaut. Die effektive Zeit (ohne Zeitaufwände für die Datenbeschaffung beim Automobilhersteller) für die Durchführung des PoC inklusive Aufbau der Infrastruktur betrug drei Monate mit 3,5 Full-Time Equivalents (FTE). Alle im Folgenden aufgeführten Algorithmen stammen aus den jeweiligen R- und Python-Bibliotheken und wurden individualisiert parametrisiert.
Aufbau eines Analytical Face
Die intelligente Auswertung von Social-Media- und Online-Quellen (zum Beispiel Auto-Konfiguratoren) sowie die Auswertung vergangener Kaufmuster aus den internen Datenbeständen der Automobilhersteller ermöglicht es, ein analytisches Abbild des Kaufverhaltens der Kunden abzuleiten. In Abbildung 1 wird der grobe fachliche Rahmen, die Vorgehensweise und die Datengrundlage für den vorliegenden PoC vorgestellt. Aufgrund der zeitlichen Vorgabe für die Durchführung des PoC wurde ein Teilausschnitt von relevanten Daten und geeigneten Algorithmen verwendet, die in Abbildung 1 blau hinterlegt dargestellt sind. Die grau hinterlegten Flächen geben einen Ausblick auf weitere Datenquellen und Algorithmen, um den vorliegenden Lösungsansatz auszubauen (zum Beispiel Anwendung von Operations-Research-Modellen).
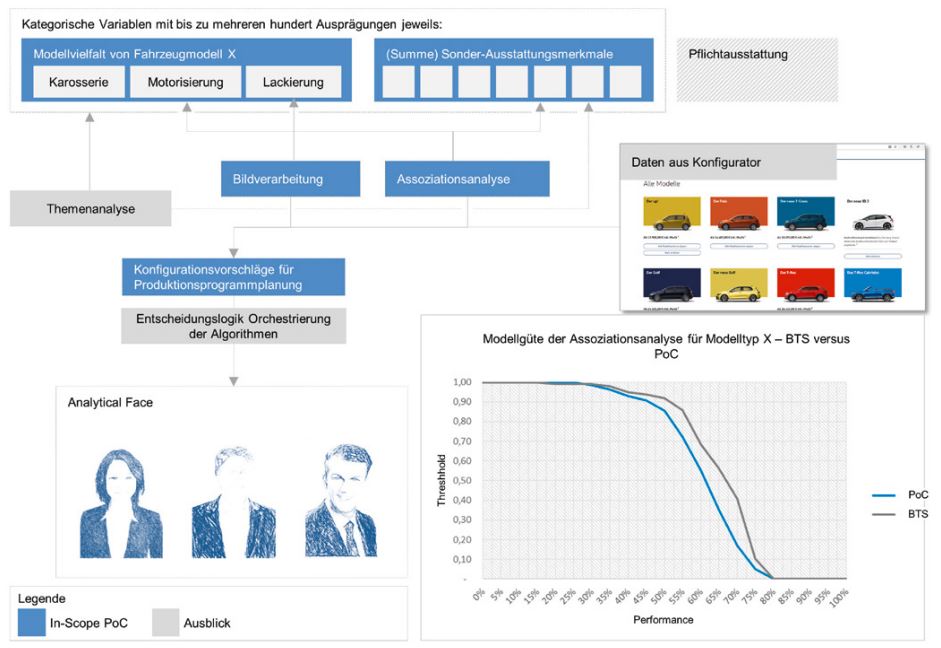
Abb. 1: Methodisches Vorgehen und Leitplanken des PoC zur Ermittlung des Analytical Face, Summe der Datengrundlage und Modellgüte des Prognosemodells
Für den PoC wurden Instagram-Daten und Absatzinformationen aus dem Testsystem eines Automobilherstellers verwendet. Die Aufbereitung dieser Social-Media-Daten unter Verwendung von Objekterkennungsverfahren wird im folgenden Abschnitt detailliert beschrieben.
Die Auswertung von Kaufmustern der Vergangenheit aus internen Datenbeständen erfolgte durch mehrere Assoziationsanalysen. Damit können starke Zusammenhänge zwischen Objekten in einer Transaktion aufgedeckt werden. Die wesentlichen Merkmale der jeweiligen Fahrzeuge können somit aufgelistet werden und werden als treibende Merkmale der Wunschkonfiguration interpretiert.
Der Datensatz des Automobilherstellers aus seinen internen Datenbeständen enthält Informationen von ca. 20.000 Fahrzeugvollkonfigurationen vergangener Build-To-Order-(BTO-)Verkäufe und ca. 6.000 Build-To-Stock-(BTS-)Verkäufe. Für die Ausarbeitung der jeweiligen Algorithmen wurde der vorliegende interne Datensatz in 80 Prozent Trainingsund 20 Prozent Testdaten aufgeteilt. Die Pflichtausstattungen wurden im Zuge des Trainings ausgeschlossen, da sie nicht von den Kunden direkt beinflussbar sind. Die Ergebnisse der Assoziationsanalyse sind in Abbildung 1 unten rechts anhand eines Beispiels Modelltyp X dargestellt. Das im Rahmen des PoC auf Grundlage der Assoziationsanalyseergebnisse trainierte Modell namens „PoC“ haben wir gegen die „BTS“-Ergebnisse, also die Produktionsplanungsergebnisse auf Grundlage der Vorhersagen, die die Hersteller in ihren Abteilungen durchführen, gespiegelt (siehe Abbildung 1).
Zur Evaluierung der Modellgüte vergleichen wir 1:1 die Sonderausstattungen der Fahrzeuge. Die Y-Achse „Threshold“ bezeichnet hierbei die prozentuale Übereinstimmung der Prognosen der jeweiligen Modelle „PoC“ und „BTS“ gegenüber den tatsächlichen Ereignissen von 0 Prozent (= Vorhersage korrekt für keine Teile je Fahrzeug) bis 100 Prozent (= Vorhersage korrekt für alle Teile je Fahrzeug), die X-Achse die Güte. Die Ergebnisse beider Modelle sind ähnlich, wobei die des BTS-Modells genauer sind. Dies kann auf den eingeschränkten Datensatz aus der Testumgebung zurückgeführt werden. Die Datenmengen aus Social Media liefern weitere wertvolle Informationen über die aktuellen Bedürfnisse von Kunden. Zwei solche Social-Media-Kanäle sind Twitter und Instagram. Einzelne Posts in Instagram oder Tweets in Twitter können unter Berücksichtigung der jeweiligen Sicherheitseinstellungen gelesen werden. Diese offene Gestaltung schafft einen hohen Grad an Publizität [Pfa16].
Instagram-Daten können über die von Instagram bereitgestellte API bezogen werden. Die Datenmenge eines Instagram-Beitrags gliedert sich in 150 kB je Bild und 50–100 kB für Kommentare und Metadaten. Eine Herausforderung stellte die Datenqualität dar. Wie auch bei Twitter-Daten können Instagram-Beiträge Tabulatoren, Zeilenumbrüche und spezielle Sonderzeichen wie Semikolon enthalten. Dies führte bei der Entwicklung des PoC zu einer geringeren Datenqualität und Mehraufwand, da die fehlerhaften Daten aufbereitet werden mussten.
Identifikation von Kundeninteressen mit KI
Für die Extraktion von Trends aus Instagram-Daten wird auf die Fahrzeugfarben fokussiert. Um aus den geposteten Bildern die Farben gezielter identifizieren zu können, müssen im ersten Schritt die Fahrzeuge erkannt (Objekterkennung) und separat gespeichert werden, sonst würde in der darauffolgenden Farberkennung zu viel Farbe des Hintergrunds analysiert oder fälschlicherweise ein anderes „Nicht-Fahrzeug“-Objekt mit entsprechender Farbe analysiert.
Dafür wurde ein vortrainiertes Convolutional Neural Network (CNN) verwendet. Ein CNN ist ein
Algorithmus, der speziell für die Erkennung von Formen in Bildern entwickelt wurde. In Summe erkennt ein CNN somit verschiedene Objekte wie Fahrzeuge hinreichend zuverlässig. Die Position dieser Objekte wird als Rechteck zurückgegeben, sodass dieser Bereich aus den ursprünglichen Bildern herausgeschnitten werden kann.
Um die Genauigkeit für die Fahrzeugfarben weiter zu erhöhen, wird nur ein Ausschnitt des Bildes betrachtet, genauer das innere Rechteck eines 3x3-Feldes (siehe Abbildung 2). In den zuvor erstellten Bildern befindet sich nun, gemäß den Vorgaben an das CNN, ein Ausschnitt eines Fahrzeugs, dessen Farbe ermittelt werden kann. Hierfür sind zehn mögliche Farben vordefiniert worden, auf die alle erkannten Farben abgebildet werden (siehe Abbildung 2). Eine Farbe wird dann auf die Farbe mit dem geringsten räumlichen Abstand zu ihrem RGB-Wert abgebildet. Diese Farbbestimmung wird für jedes Pixel im Bild verwendet, die häufigsten Farben werden ermittelt und gespeichert.

Abb. 2: Vorgehensweise zur Farberkennung von Fahrzeugen
Als Nächstes werden die erzeugten Ergebnisse mit einer regelbasierten Routine auf ihre Datenqualität überprüft. Nicht jede Fahrzeugfarbe kann aus fachlicher Sicht für jedes Modell vorkommen, und so muss der Eintrag entsprechend entfernt und in ein Re-training aufgenommen werden. Der so bereinigte Datensatz wird noch immer fehlerhafte Daten beinhalten. Um diese weiter zu reduzieren, kann ein Ensemble von Neuronalen Netzwerken trainiert werden, das nicht nur in der Lage ist, das Objekt „Auto“ zu erkennen, sondern auch dessen Marke, die entsprechende Modellserie sowie Positionen von Türen oder der Motorhaube.
Um die Genauigkeit der Farberkennung zu beurteilen, sind 150 Bilder zunächst manuell als Testdatensatz kategorisiert worden. Diese wurden anschließend von dem CNN bearbeitet und dessen Ergebnisse mit dem Soll-Ergebnis aus der händischen Kategorisierung verglichen. Die Ergebnisse richten sich nach den zehn Grundfarben in Anlehnung an die Zentrale-Fahrzeugregister-(ZFZR-)Methodik des Kraftfahrtbundesamtes [KBA19]. Das CNN konnte bei etwa 30 Prozent der 150 Bilder ein korrektes Ergebnis erzielen – durch bloßes Raten der Farbe hätte die Erfolgsrate bei zehn Farben lediglich bei etwa 10 Prozent gelegen (Würfelwahrscheinlichkeit). Gerade verschiedene Licht- und Verschmutzungsverhältnisse, aber auch Reflexionen auf dem Lack führen zu Abweichungen in der Messgenauigkeit und somit in der vorhergesagten Farbe.
Unsere nächsten Schritte zur Verbesserung der Vorhersagegenauigkeit bestehen in der oben angesprochenen weiteren Feature-Erkennung. Dadurch wird der Anteil der Lackfarbe erhöht und Störfaktoren, wie etwa die Reifenfarbe, entfernt. Durch einen Mehrheitsentscheid, das heißt den Vergleich der Häufigkeit der erkannten Farben je Bildausschnitt der gefundenen Objekte (zum Beispiel Motorhaube ist grün, Dach ist grün und Tür ist gelb, also ist das Auto wahrscheinlich grün) ist eine präzisere Erkennung möglich.
Technische Lösung – Umdenken in der Data-Science-Architektur
Für die Erfassung von Social-Media-Daten bieten sich moderne Cloud-Infrastrukturen an, da die Skalierbarkeit der Ressourcen variabel an den Bedarf angepasst werden kann. Mit Hinsicht auf die verschiedenen zu erwartenden Datenformate und den Bedarf nach einer Speicherung von Rohdatenformaten bietet sich als Architektur ein Data Lake an. Die Architektur unseres implementierten Systems in Azure teilt sich in verschiedene Zonen (Landing, Trusted, Data Science Engine, Refinement und Visualization) auf. Diese werden durch Technologien aus der Hadoop-Welt repräsentiert (siehe Abbildung 3) und zu unterschiedlichen Zeiträumen mit Daten, die den Anforderungen der atomaren Darstellung für Machine-Learning-Algorithmen entsprechen, befüllt.
Die Landing Zone (in Abbildung 3 links) wird durch das verteilte Datenhaltungssystem Hadoop Distributed File System, kurz HDFS, repräsentiert. Das HDFS erlaubt eine persistente und zuverlässige Speicherung über mehrere Server verteilt [Whi12]. Innerhalb der Landing Zone können Daten in Echtzeit oder durch Batchprozesse im Rohformat abgelegt werden. Die Daten können in nicht-, semi- und strukturierter Form vorliegen.
Im Fall des implementierten PoC werden die Daten wöchentlich im Text- und Bildformat über Python- und R-Skripte in den Hadoop-Cluster geladen. Von der Landing Zone werden die Daten in die Trusted Zone überführt. Für Daten, die aus strukturierten Quellen erfasst wurden, besteht der zusätzliche Vorteil darin, dass die Daten in typisierten Spalten und nicht nur als Zeichenfolgen verfügbar sind. Bei nicht strukturierten Quellen müssen die Daten verarbeitet werden, damit sie in die Trusted Zone gelangen. Zudem können fehlerhafte oder unvollständige Datensätze bereinigt und aufbereitet werden.
Zur Realisierung dieser Zone wurde Apache Hive genutzt. Dieses Werkzeug gestattet es, auch unstrukturierte Daten strukturiert darzustellen.
Über die Data Science Engine (siehe Abbildung 3) werden die Rohdaten unter Verwendung von fertig trainierten Machine-Learning-Algorithmen angereichert (Datenproduktion) beziehungsweise wird die selbstlernende Eigenschaft ebendieser Algorithmen ermöglicht. Zur Realisierung dieser Zone wurden sowohl die Cloudera Data Science Workbench (CDSW) als auch RStudio IDE genutzt. CDSW ist eine Umgebung, in der verschiedene Skriptsprachen wie R und Python ausgeführt werden können, während R Shiny zusätzliche Möglichkeiten zur Visualisierung und Analyse der Daten bietet.
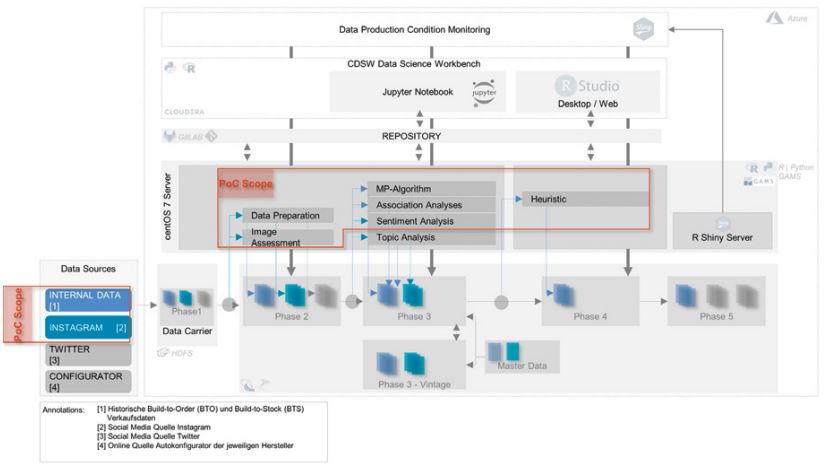
Abb. 3: Data-ScienceArchitektur für die Datenproduktion aus verschiedenen Algorithmen
Die darauffolgende Refinement Zone wird durch Apache Hive umgesetzt. Daten innerhalb dieser Zone werden in Themen gruppiert. In Abbildung 4 ist ein exemplarischer Instagram-Report für das Jahr 2018 und 2019 dargestellt, der auf Monatsebene die häufigsten Farben als Bilder und die Gewichtung der durch „Likes“ bewerteten Fahrzeugfarben in relativer Form automatisiert abbildet. Die Tabelle unten in der Grafik zeigt die Ergebnisse der Sentiment-Analyse der jeweiligen Instagram Posts. Dabei scheint im Jahr 2019 die Farbe Grau gegen Jahresende beliebter zu werden.
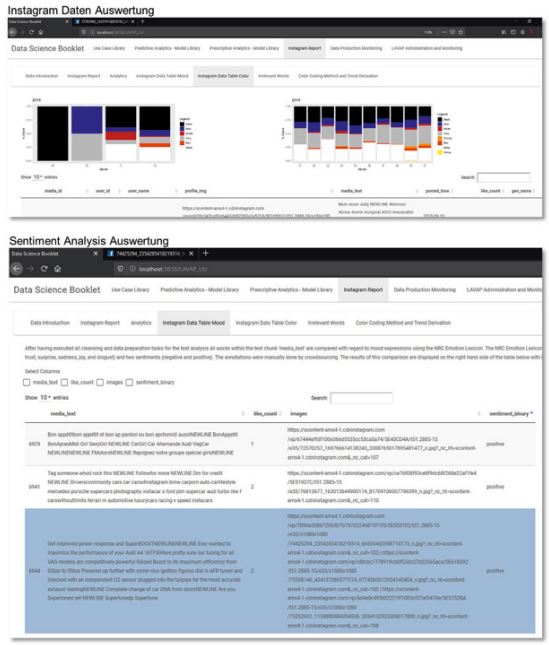
Abb. 4: Visualisierung von Instagram-Daten und Darstellung der Ergebnisse der Sentiment-Analyse, Screenshot aus R Shiny
Der gesamte ETL-Prozess inklusive der Anreicherung der Daten durch die Ergebnisse des CNN bis hin zur dargestellten Visualisierung läuft wöchentlich automatisiert durch und benötigt 1–2 Stunden Berechnungszeit. Dies ist abhängig von dem aufkommenden Datenvolumen und kann hinreichend gesteuert werden bei einer Erhöhung der Abzugsfrequenz.
Fazit
Der Kunde hinterlässt nicht nur bei seiner Online-Recherche Spuren, er wird auch bei entsprechendem Aufenthalt in bestimmten Online-Quellen (Social Media und Konfiguratoren) hinsichtlich seiner Kaufentscheidung beeinflusst. Im vorgestellten PoC haben wir aufgezeigt, wie Farbtrends und Stimmungen aus Instagram quantifiziert werden können und Kaufverhaltensmuster aus vergangenen Transaktionen sich eignen, um auf zukünftige Käufe zu schließen. Jedoch bedarf es darüber hinaus der Auswertung weiterer Quellen wie Daten aus den Auto-Konfiguratoren, welche neue Ausstattungsmerkmale abbilden, die es in der Vergangenheit noch nicht gab.
Abbildung 1 zeigt, dass eine Vielzahl von Algorithmen für die Prognose notwendig ist, um Kundenwünsche vorauszusehen. Damit letztendlich die Prognoseergebnisse in konkrete optimale Handlungen in der Produktionsprogrammplanung einfließen können, bedarf es einer durchdachten Orchestrierung der Algorithmen, zum Beispiel über ein Operations-Research-Modell. Diese Online-Quellen gilt es in kluger Art und Weise zu erfassen, um ein aktuelles Stimmungsbild der Kunden abzuleiten und daraus eine marktorientierte Konfiguration von Fahrzeugen abzuleiten. Das Wunschauto des jeweiligen Kunden vorherzusagen und im Händlershop zum richtigen Zeitpunkt bereitzustellen ist höchst unwahrscheinlich, jedoch kann das Wunschauto hinreichend annähernd vorhergesagt werden und dadurch folgende Mehrwerte bieten:
- Verringerung der Lagerhaltungs- und Kapitalbindungskosten durch marktorientierte Konfigurationen, die die Kunden ansprechen und somit frühzeitiger gekauft werden. Diese betrugen laut einer Studie des International Car Distribution Center (ICDP) im Jahr 2004 ca. 7 Prozent der Marge in Höhe von etwa 15 Prozent des Listenpreises [BuM05].
- Um ein Lagerfahrzeug mit einem geringen Deckungsanteil der Wunschkonfiguration der Kunden trotzdem verkaufen zu können, bieten die Händler große Preisnachlässe an, die laut der Studie des ICDP im Jahr 2004 ebenfalls etwa 7 Prozent der Marge in Höhe von etwa 15 Prozent des Listenpreises betrugen [BuM05]. Wird jedoch die Wunschkonfiguration hinreichend vorhergesagt, kann sich in Zukunft die Anzahl der Preisnachlässe verringern. Gleichzeitig steigt die Kundenzufriedenheit, da die Kunden ihr (nahezu) Wunschauto erhalten.
Ist die Herausforderung der Datenintegration gemeistert, können die Daten in Bezug auf Stimmungsbilder mit Hilfe von Machine-Learning-Algorithmen extrahiert werden und bilden so eine Datenproduktionsstrecke. Die beschriebene Anreicherung von Daten impliziert eine starke Verkettung der Ergebnisse der jeweiligen Algorithmen bzw. Analyseschritte und wird somit stark von der Datenqualität beeinflusst. Daher ist es unabdingbar, in der Data-Science-Architektur entsprechend geeignete Überwachungsmechanismen zu berücksichtigen, die den gesamten Datenfluss in jedem Produktionsschritt abbilden, sodass bei mangelnder Datenqualität entsprechende Maßnahmen eingeleitet werden können.
Literatur
[BuM05] Buzzavo, L. / Montagner, L. (2005): Dealermargin structures for new vehicles in Europe. ICDP Research Report 03/05, ICDP 2005
[KBA19] Kraftfahrtbundesamt,
https://www.kba.de/DE/Presse/Archiv/Farbschluesselnummern/farbschluesselnummern_node.html, abgerufen am 28.9.2019
[Mue15] Müller-von der Ohe, H.: Bestellvorschläge für die variantenreiche Lagerfertigung in der Automobilindustrie. 2015
[Pfa16] Pfaffenberger, F.: Twitter als Basis wissenschaftlicher Studien. Nürnberg, Springer Fachmedien Wiesbaden Gmbh 2016
[PiW16] Piller, F. / Walcher, D.: Leading Mass Customization and Personalization – 24 expert interviews: How to profit from service and product customization in e-commerce and beyond. Think Consult Publishing 2016
[SRE17] Schuh, G. / Riesener, M. / Ebi, M.: Cost-orientated Product Variant Evaluation using Similarity Analysis. In: 2017 Proceedings of PICMET ’17: Technology Management for Interconnected World, July 9–13, 2017, Portland/USA, Hrsg.: Kocaoglu, D., PICMET Portland International Center for Management of Engineering and Technology, Portland/USA 2017
[Whi12] White, T.: Hadoop: The Definitive Guide. O’Reilly Media Inc. 2012









