

Diese Arbeitsprinzipien aus den 1980er-Jahren gelten prinzipiell auch heute noch. Aber die typische und althergebrachte Data-Warehouse-Landschaft befindet sich im Umbruch. Zu den wichtigsten Einflussfaktoren zählen:
- Verbesserte Technologien: Dazu gehört vor allem eine gesteigerte Performance durch zunehmende Rechenleistung, Parallelisierung, In-Memory-Technologie und mehr Arbeitsspeicher zu sinkenden Preisen. Die erhöhte Leistung ermöglicht neue Anwendungen.
- Neue Anforderungen der Nutzer: Die Nutzer erwarten schnelle Releases von Entwicklungen und die damit verbundene schnellere Bereitstellung der angeforderten Informationen.
- Integration neuer Quellen: Big Data und IoT spülen riesige Mengen an polystrukturierten Daten in die Data Lakes. Aber wie lassen sich daraus wertvolle Informationen gewinnen?
- Integration unterschiedlicher Analyseverfah- ren: Gefragt sind Verfahren wie Standard-Reporting, Self-Service und Data Science, um so den Mehrwert der Unternehmensdaten zu erhöhen.
- Cloud-Entwicklung: Die Cloud-Entwicklung befindet sich beim Thema Data Warehouse noch in den Anfängen. Sie gewinnt aber an Bedeutung und macht DWH-Themen noch komplexer.
Im Folgenden skizzieren wir sieben Entwicklungen, die das „Data Warehouse von morgen“ prägen werden, und erläutern, wie Unternehmen damit umgehen sollten. Diese Trends haben nicht den Anspruch auf Vollständigkeit, sondern spiegeln Erfahrungen aus zahlreichen realen Kundensituationen wider.
Verteilte DWH-Landschaften für ein „Net of Truth“
Die DWH-Landschaft im Unternehmen stellt sich als Monolith dar, in dem der „Single Point of Truth“ liegt. Dieses ursprüngliche Bild gilt nicht mehr. In den meisten Unternehmen gibt es längst mehrere Data Warehouses. Der große Nachteil: Diese Data-Warehouse-Systeme kennen sich nicht untereinander und können daher nicht kooperieren.
Dadurch werden Synergien und Potenziale verschenkt. Um dem entgegenzuwirken, sollten zukunftsfähige Data-Warehouse-Systeme von vornherein als verteilte DWH-Landschaft konzipiert werden. Dabei entstehen mehrere kleine oder große Data-Warehouse-Systeme, die sich kennen und so untereinander kommunizieren können. Sie bilden ein sogenanntes „Net of Truth“, das die Architektur eines einzigen logischen Data Warehouse repräsentiert [Sha17; MeB11]. Für die einzelnen Komponenten muss es eine klare Definition über Inhalt und Form der Kommunikation geben. Die technischen Systeme dürfen dabei unterschiedlich sein, was auch der Realität in den Unternehmen entspricht.
Ein solcher Ansatz hat vier Voraussetzungen:
- Einen architektonischen Gesamtblick
- Zentrale Metadaten
- Ein System, das die Kommunikation und Orchestrierung zwischen den beteiligten Systemen organisiert
- Eine Governance, die die Richtlinien und Rahmenbedingungen für das logische DWH beschreibt
Abbildung 1 zeigt beispielhaft eine mögliche Ausgestaltung eines Data Warehouse. Alle beteiligten Komponenten beherbergen analytische Informationen, die in ihrer Gesamtheit ein logisches Data Warehouse, das Net of Truth, bilden.
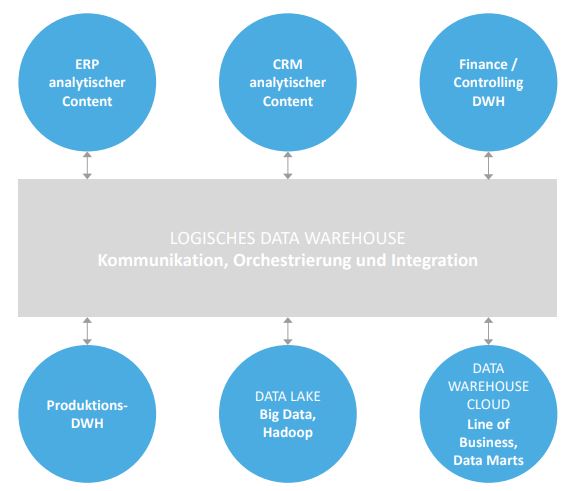
Abb. 1: Mögliche Ausgestaltung eines Data Warehouse
Integration von Big Data und IoT mit dem klassischen DWH
Die Technologien rund um Big Data und das Internet of Things liefern riesige Mengen an polystrukturierten Daten. Diese werden in entsprechend dafür geeigneten Datenhaltungssystemen in Form von Data Lakes gespeichert und mit entsprechenden Data-Science-Methoden analysiert und ausgewertet – dazu gehören zum Beispiel Machine Learning und Predictive Analytics. Die hier verwendete Speicherung, Organisation und Verwendung der Daten unterscheiden sich deutlich vom klassischen Data Warehouse. Themen wie Data Governance und alternative Daten-Modellierung folgen eben anderen Grundsätzen. Dies führt dazu, dass viele Unternehmen die Themen auch getrennt voneinander behandeln, sodass es wenig Kooperation und selten Synergien gibt. Eine Integration beider Ansätze – klassisches DWH und Data Lakes – steigert den Wert künftiger Informationen [Kri13]. Dies erfordert aber, dass beide Ansätze unter einem gemeinsamen konzeptionellen Dach laufen. Dabei sollten die jeweiligen technologischen und methodischen Ansätze ihre grundlegenden Eigenschaften behalten. Die Informationen dieser beiden Welten sollten jedoch integriert und kombiniert werden können.
In der Umsetzung gibt es dazu zwei grundlegende Möglichkeiten:
- Informationen in verschiedenen Systemen vorhalten: Zum Beispiel kann das klassische Data Warehouse in einer relationalen Datenbank vorgehalten werden, der Data Lake in Systemen, die polystrukturierte Daten speichern können, zum Beispiel Hadoop. Um eine Integration dieser Welten zu ermöglichen, sind ein übergreifendes Management der Metadaten,eine geeignete Technologie für die Kommunikation und logische Integration sowie entsprechende organisatorische Rahmenbedingungen erforderlich.
- Alle Informationen auf eine einheitliche Plattform bringen: Innerhalb dieser Plattform können dann beide Varianten, klassisches Data Warehouse und Data Lake, in separaten Bereichen implementiert werden. Dies wird in der Folge eine Integration der beiden Welten vereinfachen. Anbieter solcher Systeme sind zum Beispiel Snowflake on Azure oder SAP HANA Cloud. Beide Plattformen sind cloudbasiert.
Wie auch immer die technische Lösung im Detail aussieht, wichtig ist es, die Themen Big Data, IoT und klassisches Data Warehouse eng zu verzahnen und unter ein gemeinsames konzeptionelles, vielleicht auch organisatorisches Dach zu stellen.
Das Data Warehouse wandert in die Cloud
Cloud ist die strategische Ausrichtung nahezu aller Plattformanbieter für Data Warehousing (siehe SAP HANA Cloud oder Snowflake) und sollte aus zwei Perspektiven betrachtet werden:
- Welche DWH-Lösungen bieten Cloud-Anbieter? Neben der schon etablierten Variante „Platform as a Service“ (PaaS) steckt „Software as a Service“ (SaaS) erst in den Anfängen. In dieser Variante liegt das technische Management der Data-Warehouse-Umgebung beim Cloud-Anbieter. Ein SaaS-basiertes Data Warehouse wird sich ebenso in eine komplexe, verteilte Systemlandschaft integrieren müssen wie die On-Premises-Variante. Daher ist auch hier der Aspekt der Integrationsfähigkeit der SaaS-Lösung neben den technischen und kaufmännischen Aspekten in die Betrachtung einzubeziehen. Mit einer hohen Integrationsfähigkeit kann eine hohe Flexibilität in Hinblick auf Entwicklung und Verteilung von Data-Warehouse-Artefakten erreicht werden. Denkbar sind auch hybride Datenmodelle, in denen zum Beispiel fachbereichsbezogene Datenmodelle in der Cloud auf zentrale Datenmodelle bereitgestellt werden. Die Integration kann in diesem Fall bis hin zu virtueller Integration führen, sodass nicht zwingend Daten physisch redundant gehalten werden müssen.
- Wie richte ich die eigene DWH-Entwicklung auf die Cloud aus? Diesem Aspekt kommt in Zukunft eine sehr hohe Bedeutung zu – besonders dann, wenn hybride DWH-Landschaften entstehen. Sprich: Das Data Warehouse wird teils On-Premises entwickelt oder betrieben, teils in der Cloud. Um dies zu ermöglichen und die zwei Teile möglichst flexibel kombinieren zu können, muss eine Kompatibilität der Data-Warehouse-Entwicklungen gewährleistet sein. Abbildung 3 zeigt ein Beispiel, in dem Entwicklung und Test On-Premises erfolgen, der produktive Betrieb dann aber in der Cloud stattfindet. Es lassen sich leicht reale Situationen in Unternehmen vorstellen, in denen hybride Szenarien sinnhaft sind. So ist es recht wahrscheinlich, dass global agierende Unternehmen mehrere Data-Warehouse-Systeme betreiben. Für regionale Einheiten kann es jedoch aus verschiedenen Gründen zu einer unterschiedlichen Ausgestaltung der Data-Warehouse-Landschaft kommen. Eine Integration dieser Landschaften wird dann erleichtert, wenn die Entwicklung von Data-Warehouse-Lösungen so gestaltet werden, dass ein flexibles Deployment möglich wird. Dann können zum Beispiel zentral entwickelte Teile des Data Warehouse in die verschiedenen regionalen DWH-Systeme ausgeliefert und dort betrieben werden.
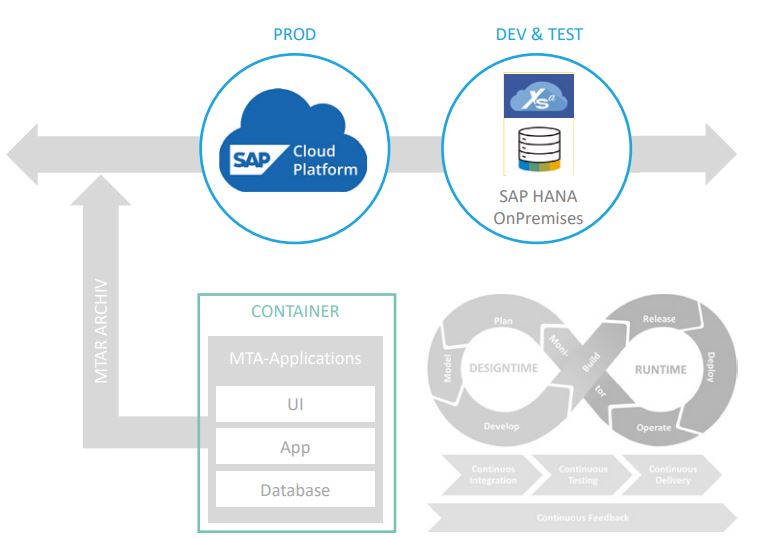
Abb. 3: Beispiel für eine hybride DWH-Landschaft
Neue Methoden und Werkzeuge zur DWH-Entwicklung
Für die Entwicklung eines Data Warehouse können Unternehmen auf ein breites Angebot von Methoden und Werkzeugen zurückgreifen – darunter ein wachsender Anteil von Open-Source-Angeboten. Eine moderne DWH-Entwicklung zeichnet sich durch folgende Eigenschaften aus:
- Modellgetrieben: Im modellgetriebenen Ansatz stehen die Datenmodelle im Zentrum der Entwicklung. Dies umfasst sowohl die konzeptionellen Modelle, die die Sicht der Fachbereiche auf ihre analytische Welt beschreiben, als auch die physischen Datenmodelle, die die Datenstrukturen in der Datenbank beschreiben (vgl. [AnP20]).
- Agil: Ein agiler Entwicklungsansatz führt zu schnelleren Auslieferungen und einer kürzeren Zeit bis zur Wertschöpfung. Er orientiert sich am DevOps-Ansatz (siehe Abbildung 2), der vor allem in der klassischen Softwareentwicklung angewendet wird [grundlegend Kim16; siehe auch FiP20].
- Cloud: Ziel einer Cloud-orientierten Entwicklung ist es, das Data Warehouse oder Teile davon in einer Cloud-Umgebung bereitzustellen und dort zu betreiben.
- Automation: Durch eine Standardisierung der Werkzeuge und Methoden erhält man die Möglichkeit, Teile des Entwicklungsprozesses zu automatisieren [vgl. ScP20].
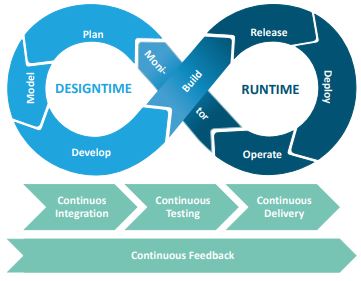
Abb. 2: Der DevOpsAnsatz
Wenn wir von neuen Methoden und Werkzeugen zur Data-Warehouse-Entwicklung sprechen, bedeutet dies letztlich, dass wir die zentralen Werkzeuge wie Modellierungs- und ETL-Tools ergänzen um Werkzeuge, mit denen die oben genannten Anforderungen realisiert werden können. Wichtig dabei ist, diese Werkzeuge dann so mit einer Methodik zu versehen, dass man hier zu einer optimalen Ausgestaltung des Entwicklungsprozesses kommt. Grundgedanke ist hierbei der DevOps-Ansatz. Dies führt Data-Warehouse-Entwicklung und Softwareentwicklung näher zusammen.
Orchestrierung komplexer analytischer Prozesse
Wie oben schon häufiger angesprochen [vgl. Kris13; Sha17], wird sich die Komplexität einer analytischen Landschaft künftig in den Unternehmen stark erhöhen. Die Hauptgründe dafür sind:
- Integration verteilter und möglicherweise sehr heterogener Systeme
- Kommunikation zwischen analytischen Services und operativen Prozessen
- Komplexe Bewirtschaftungsprozesse
- Integration und Management von Data-Science-Applikationen, die häufig in den Unternehmen dezentral und in unterschiedlichen Werkzeugen realisiert sind – Aspekte wie Data Preparation, Retraining und Modell-Life-Cycle spielen hier eine wichtige Rolle
Der Charakter von Data-Warehouse-Systemen wird sich ändern. Sie werden nicht nur Ort einer zentralen Datenhaltung sein, sondern künftig verteilte Systeme und komplexe Datenkommunikationsprozesse orchestrieren. Dazu sind neue Technologien notwendig, die diese Orchestrierung übernehmen [Blo19].
Innovative Nutzung analytischer Informationen
Bislang werden Data-Warehouse-Systeme hauptsächlich als Datenbasis für Reporting und Analyse verwendet. Gängige Techniken dafür sind Standard-Reports, Dashboards und Frontend-Werkzeuge, die interaktive Analysen ermöglichen. Um Agilität und Kollaboration bei analytischen Arbeitsprozessen zu fördern, erlangen intuitive Self-Service-Werkzeuge eine immer größere Bedeutung [Tho17; Sop18]. Diese Werkzeuge unterstützen erweiterte Analysen, die auf Data-Science-Methoden wie prädiktive Analysen oder Machine-Learning-Algorithmen basieren. Die Integration erweiterter Analysemöglichkeiten in die Frontend-Tools versetzt auch die Fachbereiche in die Lage, grundlegende Analysen dieser Art zu betreiben. Komplexe Analysen mit Data-Science-Methoden bleiben aber weiterhin den Data Scientists vorbehalten, die dafür ihre etablierten Umgebungen wie R oder Python nutzen. Noch eine wesentliche Veränderung: Informationen aus dem Data Warehouse werden nicht mehr nur von Menschen abgefragt (über Reports und Dashboards). Zusätzlich lassen sich analytische Informationen verstärkt in Unternehmensprozesse integrieren. Kurz gesagt: Informationen und Prozesse werden künftig verstärkt interagieren. Durch eine automatisierte Kommunikation entstehen intelligente Unternehmen. Sie können Prozesse und Entscheidungen durch analytische Systeme automatisieren und unterstützen. Eigenständige analytische Microservices bilden künftig die Basis für die Kommunikation zwischen analytischen und prozessorientierten Systemen.
Realtime Analytics
Der Trend zu Realtime-Analysen verstärkt sich (vgl. [Tho17]). Informationen müssen immer häufiger zeitnah analysiert werden, im besten Fall dann, wenn sie entstehen. Der klassische Ansatz, Daten zyklisch in Data-Warehouse-Systeme zu laden, reicht dann nicht mehr. Ebenso geben bisherige klassische DWH-Architekturen dies nicht her. Zusammenfassend lässt sich sagen, dass Realtime Analytics in nahezu allen Unternehmensbereichen einen Mehrwert erzielen kann. Bei der Modernisierung der BI-Landschaft sollten daher Aspekte der grundlegenden Architektur und Ausrichtung in die strategischen Betrachtungen einbezogen werden. Da es hier aber auch eine starke Wechselwirkung mit anderen Bereichen des Unternehmens gibt, ist eine bereichsübergreifende Ausrichtung notwendig, was eine Neuausrichtung der BI-Strategie in Abstimmung mit anderen Unternehmensbereichen erfordert, zum Beispiel mit der Unternehmensarchitektur.
Fazit
Unternehmen schöpfen Daten aus den Geschäftsprozessen, aus dem Markt und von den Kunden. BI-Tools verdichten diese Daten zu Informationen für die Planung und Überwachung und zur Gewinnung neuer Einsichten. Für die Datensammlung und Analyse bilden künftig Data Warehouse und Data Lake die zentrale Informationsbasis – ein Big Data Warehouse. Neue Technologien und Anforderungen verändern die Nutzung und die Potenziale des Big Data Warehouse. Diese Möglichkeiten sollten Unternehmen kennen. Und dabei sollten nicht nur schnellere Datenbanken und bessere Data Lakes im Mittelpunkt stehen. Vielmehr geht es darum, insgesamt neue Wege zu gehen, um den Nutzen von BI für das eigene Geschäft zu steigern. Der Trend führt vom klassischen Reporting-BI zu Analytics-BI.
Weitere Informationen
[AnP20]
Andzinski, T. / Peitz, M.: Modellgetriebenes SAP HANA SQL Data Warehousing.
https://isr.de/news/modellgetriebenes-sap-hana-sql-data-warehousing/, abgerufen am 1.9.2020
[Blo19]
Bloemen, J.: Modernizing the Data Warehouse: Challenges and Benefits. Research Study, BARC.
https://barc.de/docs/modernizing-the-data-warehouse, abgerufen am 30.10.2020
[FiP20]
Fischer, D. / Peitz, M.: DevOps.
https://isr.de/news/devops/, abgerufen am 1.9.2020
[Kim16]
Kim, G. et al.: The DevOps Handbook. IT Revolution Press 2016
[Kri13]
Krishnan, K.: Data Warehousing in the Age of Big Data (The Morgan Kaufmann Series on Business Intelligence). Elsevier Science & Technology 2013
[MeB]
Merv, A. / Beyer, M.: Mark Beyer, Father of the Logical Data Warehouse. Guest Post. Gartner Blog Network, 3.11.2011,
https://blogs.gartner.com/merv-adrian/2011/11/03/mark-beyer-father-of-the-logical-data-warehouseguest-post/, abgerufen am 30.10.2020
[ScP20]
Schulze, E. / Peitz, M.: Data Warehouse Automation – Was macht es attraktiv? 11.8.2020,
https://isr.de/news/data-warehouse-automation/, abgerufen am 30.10.2020
[Sop18]
Sopra Steria SE, BARC GmbH: biMA®-Studie 2017/18 – Zeit für eine neue Kultur durch Business Intelligence & Advanced Analytics. 1.6.2018,
https://www.soprasteria.de/newsroom/publikationen/studie/bima-studie-2017-18, abgerufen am 30.10.2020
[Sha17]
Shankar, R.: Enabling self-service BI with a logical data warehouse. Business Intelligence Journal 2017
[Tho17]
Thomas, J. et al.: Next generation business intelligence and analytics: a survey. 11.4.2017, arXiv preprint
arXiv:1704.03402









