

Geschwindigkeit ist eine der absolut wichtigsten Eigenschaften eines jeden IT-Teams, doch wie kommt es, dass wir so schlecht darin sind? Wir verwechseln Geschwindigkeit mit Effizienz. Unsere Organisationen und Architekturen sind zu oft auf Effizienz ausgerichtet: Backend/ Frontend-Teams, zentrale Datenbanken, gemeinsame, einheitliche Datenformate. Alles Vorgehensweisen, die uns effizienter machen, aber ausbremsen. Zu viele Unternehmen haben sich daraufhin zu sorglos in die vermeintlich alles lösenden Ansätze, wie den Hype um Microservices und Single-Page Applications, gestürzt, und werden nun durch eine noch komplexere Organisation und Architektur weiter ausgebremst. Zu übereilt ist die vermeintlich falsche Architektur als Ursache für die fehlende Geschwindigkeit eingestuft. Um diesen Trugschluss zu vermeiden, lässt sich nach dem Vorgehen der „Responsible Architecture“ eine Architektur finden, die kurzfristig und langfristig für Geschwindigkeit, Effektivität und Freude sorgt.
Unabhängigkeit
Das „Responsible“ in „Responsible Architecture“ steht nicht für Nachhaltigkeit, sondern für Verantwortung – vollumfängliche, unternehmerische, von Ende zu Ende gehende, kundenorientierte, messbare Verantwortung. Denn nur dadurch lässt sich das Commitment erzeugen, was benötigt wird, um Geschwindigkeit zu gewinnen und auch zu halten. „Responsible Architecture“ beschreibt nicht die eine Architektur, die man definiert, dokumentiert und dann implementiert. Ganz im Gegenteil, sie beschreibt den Weg, um zu seiner eigenen, ganz persönlichen Architektur zu finden. Wenn man so will, einen Pilgerweg, den es zu beschreiten gilt, um zu sich selbst zu finden. Bei einigen, sehr wenigen Unternehmen kann dies heißen, dass am Ende des Wegs eine Microservice-Architektur steht. Und bei anderen wird ein Monolith die passende Wahl sein.
Doch diese Reise zur eigenen Architektur beginnt nicht mit der Technik, sie endet damit. Am Anfang des Wegs steht die Frage nach dem Business-Modell und dem Value Stream der Unternehmung. Über diese Fachlichkeit gelangen wir zur Frage der Organisation, Kultur und Arbeitsweise der Firma. Und kommen dann erst am Ende, wie versprochen, zu Herangehensweisen der Technik.
Geführt wird diese Reise von Architekten, die uns an Gabelungen mit den richtigen Methoden, Werkzeugen und Fragestellungen ausstatten, damit wir uns selbst für den passenden Pfad entscheiden. Es sind nicht die Architekten, die für uns entscheiden, doch sie machen uns die Konsequenzen unserer Entscheidungen in allen genannten Bereichen bewusst. Ein Architekt muss somit mehr als nur die Technik betrachten, System Thinking ist gefragt. Mit der „Responsible Architecture“ hat er einen Werkzeugkasten, um auf jegliche Hürden entlang des Wegs reagieren zu können. Bevor wir uns aber mit dem ersten Bereich der Fachlichkeit beschäftigen, noch ein wichtiger Disclaimer.
Disclaimer
Meine langjährige Erfahrung zeigt: Ohne, dass das Management, und manchmal gar der Inhaber, die Reise anführt, wird man nicht zu seiner „Responsible Architecture“ finden. Die langfristigen Veränderungen sind auf Gesamtunternehmensebene einfach zu groß, als dass man diese allein bewältigen kann. Das soll nicht heißen, dass man den Ball nicht ins Rollen bringen kann, aber man wird auf dem Weg das Management nicht nur überzeugen, sondern als Treiber gewinnen müssen.
Die Art der Führung spielt nämlich eine absolut zentrale Rolle, die der Reise die Leitplanken gibt und ohne die kein Erfolg eintritt. „Transformational Leadership“ – Hier geht es vor allem darum, eine Vision zu vermitteln, das Team positiv zu motivieren und ein Umfeld zu schaffen, in dem kollaboriert wird. Wer dazu tiefer ins Detail gehen möchte, dem empfehle ich „Leadership Is Language“ von L. David Marquet [Mar20]. Wenn wir während der gesamten Reise an dieser Art der Führung arbeiten, können wir inhaltlich in die „Responsible Architecture“ eintauchen und beginnen mit den Fragestellungen zur Fachlichkeit.
Fachlichkeit
Das zentrale Element der „Responsible Architecture“ ist die Frage nach Unabhängigkeit. Über Unabhängigkeit lässt sich Verantwortung erzeugen. Nur wenn ich ein Thema selbstständig, unabhängig bearbeiten kann, kann ich auch wirklich verantwortlich dafür sein. Auf der anderen Seite ist ein gesamtes Produkt mit allen seinen fachlichen Anforderungen und Funktionen viel zu groß, um es zu überblicken. Daher suchen wir Architekten immer wieder nach Möglichkeiten, ein Produkt zu zerschneiden.
Und genau hier wird es spannend, denn Schnitte zu wählen, die Unabhängigkeit der einzelnen Teile erzeugen, ist nicht einfach. Architekten neigen aus der Natur ihrer Rolle heraus zu technischen Schnitten. Diese Schnitte sind aber nur in den seltensten Fällen unabhängig. Um diesen Fehler zu vermeiden, beginnt die „Responsible Architecture“ mit der Fachlichkeit und endet mit der Technik.
Denn nur, wenn die einzelnen Teile für sich genommen allein wieder ein Produkt darstellen, welches dem Kunden Mehrwert bietet, hat man einen Schnitt gefunden, der unabhängig ist. Wichtig: Hier ist der Kunde des Unternehmens, nicht der interne Kunde gemeint. Ein sehr einfaches Negativbeispiel ist die Trennung seines Produkts in „Anzeige von Datum X“ und „Persistenz von Datum X“. Keiner der beiden Teile kann ohne den anderen einen Kundenmehrwert bieten. Man kann argumentieren, dass die Persistenz allein einen Mehrwert bieten kann und ohne die Anzeige auskommt. Aber das gilt nicht überall. Es kommt also mal wieder drauf an, in diesem Fall auf seine spezifischen fachlichen Anforderungen und Kunden. Im E-Commerce-Bereich ist es zum Beispiel üblich, dass man zwischen erstens Suche, Produktliste und zweitens Produktdetailseite, Warenkorb und drittens Checkout schneidet. So entstehen drei unabhängige Teilbereiche, die auch ohne die anderen einen eigenständigen Mehrwert darstellen. Für den weiteren Teil des Artikels Erkunden, Entscheiden und Erfüllen genannt (siehe Abbildung 1). Es gibt eine Vielzahl an Methoden, die helfen, um einen Schnitt zu finden, der diesen Ansprüchen gerecht wird. Ich möchte hier nicht jede Methode im Detail besprechen, aber einen Überblick und Verweise auf Details geben.
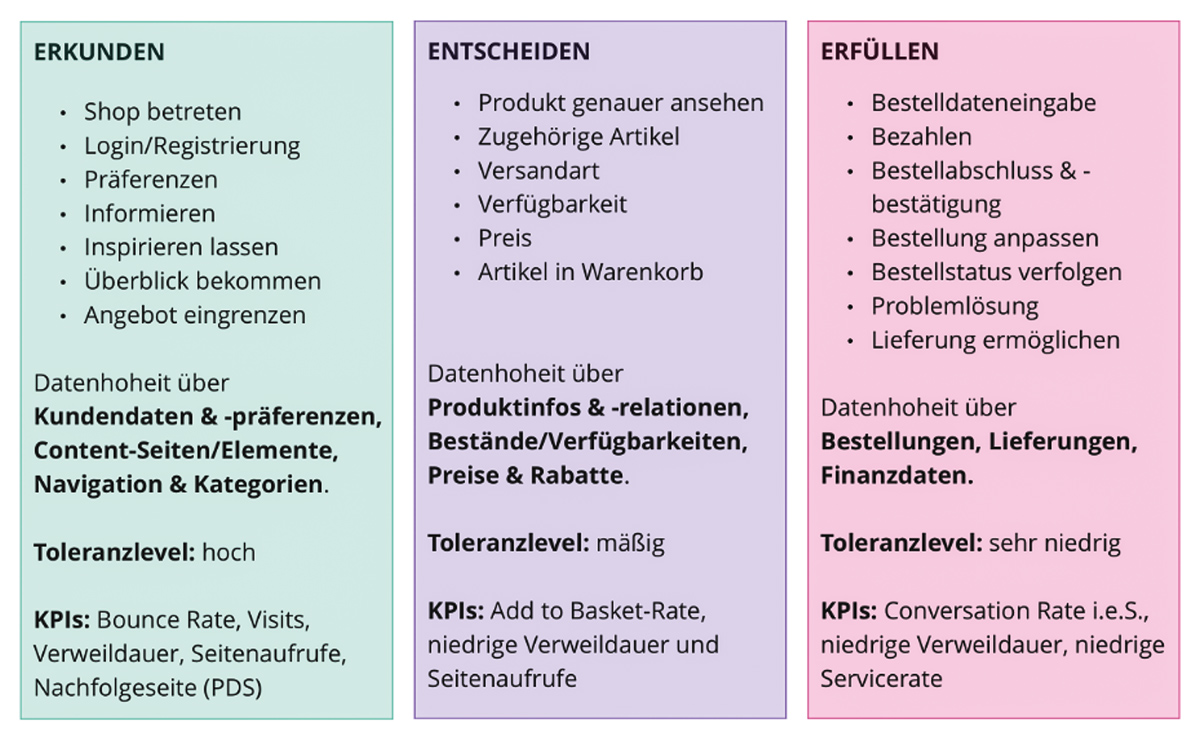
Abb. 1: Unabhängige Trennung einer E-Commerce Shop Customer Journey
Value Stream Mapping
Mithilfe von Value Stream Mapping lässt sich die Wertschöpfungskette der Unternehmung abbilden. Diese hilft dann, unabhängige Schnitte zu finden, da meist einzelne Teile des Value Stream unabhängig von vorherigen oder nachfolgenden Teilen agieren können. Diese Methode bildet meist den aktuellen Stand der Dinge ab. Sie reicht nicht aus, um einen vollständigen Blick auf den Schnitt zu werfen.
Business Model Canvas
Die Methode Business Model Canvas ermöglicht, einen Blick in die Zukunft zu werfen und neue Geschäftsfelder zu ergründen. Das Wissen um mögliche neue Geschäftsfelder kann ein wichtiger Impuls für den richtigen Schnitt sein. Dieses Vorgehen ist sehr aus der Unternehmenssicht geprägt und bedarf weiterer Methoden, um einen vollumfänglichen Blick zu erlangen.
Jobs to be done
Mit dieser Methode kann man herausfinden, welche Bedürfnisse die Unternehmung beim Kunden erfüllt, und ableiten, ob diese Bedürfnisse auch anders erfüllt werden könnten. Oft wird durch diese Methode auch klar, wer die eigentlichen Wettbewerber sind. Zum Beispiel ist der größte Konkurrent eines Buchhändlers nicht ein anderer Buchhändler, sondern ein Video-Streaming-Anbieter. Auch dieses Wissen hilft, den Schnitt in Richtung Zukunft und vor allem Kunde auszurichten und damit nicht am aktuellen Stand hängen zu bleiben.
Three Horizon Model
Dieses Modell soll veranschaulichen, welchen Zeithorizont bzw. Reifegrad welchen Themen zugeordnet ist. Mithilfe dieses Wissens lässt sich entscheiden, ob man Funktionen schon in die zu erstellende Architektur aufnimmt oder außerhalb, in eigenen Architekturen umsetzt. Durch diese Methode entsteht Fokus, was grundsätzlich für die Gesamtarchitektur einen enormen Vorteil bietet.
Wardley Mapping
Wardley Mapping ist eine weitere Methode, um neue Geschäftsfelder zu ergründen. Man könnte behaupten, sie wäre ein Ersatz für die in die Jahre gekommene Methode Business Model Canvas.
Strategisches Domain-Driven Design
Mit Domain-Driven Design tauchen wir eine Flughöhe tiefer ein als vorherig genannte Methoden und können so den Makro-Schnitt bestätigen und auch innerhalb der bereits gefundenen Schnitte auf Mikro-Ebene erneut schneiden.
Wir wissen alle, nicht nur fachliche Anforderungen spielen eine wichtige Rolle, wenn es um den optimalen Schnitt geht. Sondern nicht funktionale Anforderungen bestimmen häufig, ob ein Schnitt überhaupt realisierbar ist. Erst über die nicht funktionalen Anforderungen wird klar, ob ein Produkt betrieben werden kann. Daher muss schon in diesem Schritt berücksichtigt werden, welche fachlichen SLAs unsere Teilprodukte erfüllen sollen. Abschließend ist zu berücksichtigen, dass die wenigsten Produkte heutzutage zunächst vollständig konzipiert und dann umgesetzt werden. Sondern es wird vielmehr parallel konzipiert und umgesetzt. Man veröffentlicht iterativ kleine, minimale Funktionen und baut diese aus. Oft hört man in diesem Zusammenhang den Spruch „Wir müssen das Zielbild schon mal mitdenken, damit wir uns nichts verbauen“. Ich halte diese Aussage für sehr gefährlich und irreführend. Daher schlage ich eine andere Fragestellung vor: „Wir müssen den Weg zu unserem unbekannten Ziel schon mal mitdenken, damit wir uns nichts verbauen“. Diese Alternative betont, dass unser Ziel nicht zu Beginn bekannt sein muss und es auch in der Realität nie ist, aber der Weg dorthin Berücksichtigung in unserem Schnitt finden muss. Der Weg, wie wir unser Ziel finden wollen, ist etwas, was nicht in der Zukunft, sondern der Gegenwart liegt und sich damit viel einfacher einbeziehen lässt. Im Buch „Lean Startup“ von Eric Ries [Rie21] sind diverse Methoden beschrieben, wie ein solcher Weg zu beschreiten ist. Die bekannteste unter ihnen ist das „A/B-Testing“. Unser Produktschnitt sollte also zumindest darauf ausgelegt sein, möglichst schnell viele dieser Tests durchführen zu können. Nur wenn wir die Build-Meassure-Learn-Kurve mit unserer Anwendung möglichst häufig und schnell durchlaufen können, werden wir langfristig erfolgreich sein.
Organisation
Nachdem die Fachlichkeit auf individuelle, unabhängige Bereiche aufgeteilt ist, stellt sich die Frage nach der Organisation: Also wer bearbeitet diese Bereiche und auf welche Art und Weise?
Zunächst muss, um die gewonnene Unabhängigkeit nicht zu gefährden und auch auf organisatorischer Ebene Verantwortung zu ermöglichen, jeder Bereich exklusiv mit Mitarbeiter-Stellen besetzt werden. Sobald ein Mitarbeiter in mehreren fachlichen Teilbereichen tätig ist, geht das Gewonnene verloren. Auch dynamische Teams zu bilden, die sich permanent neu zusammensetzen, verhindert Verantwortung. Was aber nicht dagegen spricht, Kollegen isoliert, in längeren Abständen, Teams wechseln zu lassen.
An dieser Stelle ein Hinweis: Es gibt mittlerweile neue Bewegungen, die aufgrund der nicht Vermeidbarkeit von sich ändernden Teams einen Ansatz von „Embrace Change“ fahren. Mehr dazu im Buch „Dynamic Reteaming“ von Heidi Helfand [Hef19]. Dazu habe ich allerdings bisher keine persönliche Erfahrung gemacht. Damit wir jeden Bereich eigenständig besetzen können, müssen wir auf interdisziplinäre Teams setzen. Sprich, ein Team besteht aus verschiedenen Disziplinen oder Rollen. Beispielsweise aus einem Produkt-Owner und einigen Full-Stack-Entwicklern. Andere Zusammensetzungen sind auch möglich, solange alle Aufgaben des Teams mit Rollen abgedeckt sind. Vorsicht: Hier geht es vor allem um Rollen, nicht um Stellen. Eine Stelle kann mehrere Rollen einnehmen. Im aufgeführten Beispiel sind die Entwickler ebenfalls für die Qualitätssicherung zuständig. Im Buch „Team Topologies“ von Matthew Skelton und Manuel Pais [Ske19] werden neben den eben erwähnten „Streamaligned teams“ weitere Möglichkeiten der Team-Zusammensetzung im Detail erörtert. Meiner Erfahrung nach sollte das Ziel aber sein, den Großteil der Teams, wie beschrieben, anhand der fachlichen Teilbereiche zu strukturieren (siehe Abbildung 2). Ist das Team besetzt, stellt sich die Frage, wie das Team arbeiten sollte. Hier gibt es diverse, bereits ausführlich diskutierte Methoden aus dem agilen Umfeld. Ob Kanban oder Scrum ist im Grunde völlig egal. Wichtig ist nur, diese Arbeitsweise nicht nur im Entwicklungs-Bereich anzuwenden. Wenn wir wieder an System-Thinking denken, können wir nicht effektiv Richtung Kunde agieren, wenn wir nur einen Teil der am Prozess beteiligten Personen in unsere Arbeitsweise einbeziehen. Hier wird klar, warum die Unterstützung der gesamten Geschäftsführung oder des Inhabers nötig ist, denn dieser Umstand führt uns automatisch dazu, dass wir unsere Teams auch mit Kollegen aus dem Stakeholder-Bereich besetzen sollten oder zumindest unsere Arbeitsweise übergreifend organisieren sollten. Wer sich in diesem Bereich tiefer informieren möchte, dem empfehle ich, das Modern Agile Framework zu analysieren [MA].
Eine meiner Erfahrung nach sehr erfolgreiche Methode, unabhängig von Scrum oder Kanban, ist das Mob Programming. Hier arbeitet nicht ein Entwickler allein an seinem Rechner oder, wie beim Pair Programming, zwei Kollegen gemeinsam, sondern das gesamte Team. Das mag im ersten Moment wenig effizient klingen, ist aber extrem effektiv. Und die Effizienz leidet weniger als man denkt. Ich persönlich habe die Erfahrung gemacht, dass diese Arbeitsweise sogar langfristig deutlich effizienter ist als Einzel- oder Pair Programming, man denke hier an Urlaube, Krankheitstage oder spontane Hilfestellungen für andere Teams. Sozusagen eine Win-Win-Situation. Obacht: Bei größeren Teams eignet sich diese Methode natürlich nicht. Mehr dazu kann man im Buch „Remove Mob Programming“ von Jochen Christ, Simon Harrer und Martin Huber [Chr20] oder auf der Internetseite [RMP] nachlesen.
Um den Bereich Organisation abzuschließen, schauen wir auf die Kultur unserer entstandenen Teams, denn nur, wenn wir unsere Arbeitsweise dauerhaft in die Kultur des Unternehmens verankern und eine Performance orientierte Kultur etablieren, können wir die angesprochenen Vorteile vollständig nutzen. Performance orientierte Kultur nach Ron Westrum bedeutet sehr knapp zusammengefasst:
- hohe Kollaboration,
- Überbringung kritischer Informationen wird gefördert,
- Risiken werden offen geteilt,
- fachbereichsübergreifende Arbeit wird ermutigt,
- Misserfolge werden untersucht und aufgeklärt,
- Neuerungen werden begrüßt und umgesetzt.
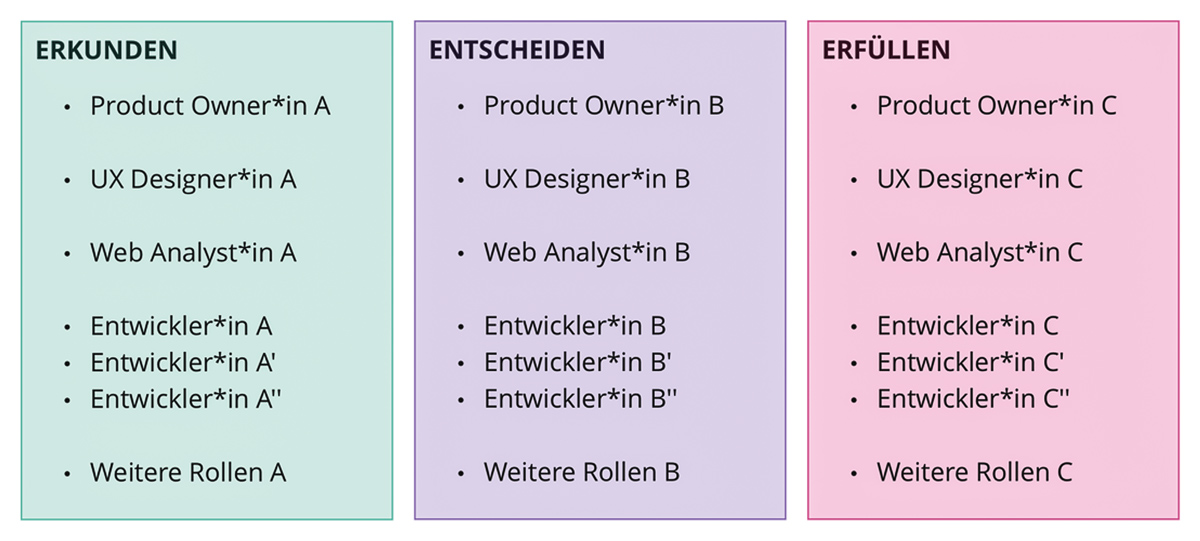
Abb. 2: Interdisziplinäre besetzte Teams, die sich keine Stelle teilen
Zuletzt ein erneuter Verweis auf den Disclaimer, denn Leadership setzt den Rahmen für die Organisation und ermöglicht uns erst, die beschriebenen Arbeitsweisen anzuwenden und eine Performance orientierte Kultur zu fördern.
Technik
Witzig, oder? Wer bis hierhin durchgehalten hat, muss feststellen, dass wir bisher absolut gar nicht über technische Fragestellungen gesprochen haben. Klar, das war angekündigt, aber ist es nicht wahnsinnig interessant, wie viel wir über Architektur gesprochen haben, ohne Technik zu erwähnen?
Ganz ohne über Technik zu sprechen, kommen wir dann natürlich nicht aus. Auch hier geht es wieder darum, die gewonnene Unabhängigkeit nicht zu verlieren. Und wie schon in der Einleitung erwähnt, tendieren wir schnell zu Microservices als Lösung für diese Herausforderung. Doch dabei vergessen wir, dass ein System nur mit der Summe seiner Teile funktioniert und auch nur als Ganzes optimiert bzw. weiterentwickelt werden kann. Für echte Unabhängigkeit ist eine lose gekoppelte Architektur essenziell und um Microservices lose zu koppeln kauft man sich enormen Overhead ein. Denn eine synchrone Schnittstelle zwischen zwei Services ist keine lose, sondern eine sehr harte Kopplung, die es also zu vermeiden gilt. Wenn es um Daten geht, bekommt man das hin, indem man die von der Schnittstelle benötigten Daten nicht synchron abfragt, sondern repliziert. Also eine Kopie davon in beiden Services vorhält. Das Kopieren ist nicht synchron an die Anwendungsfälle des Service gebunden und so entsteht eine lose Kopplung. Dies kann über diverse Mechanismen geschehen, HTTP-Feed, Queues oder direkt per SQL, Event basiert oder per Chron. Eigentlich ist es fast schon egal, welchen dieser Mechanismen man verwendet, solange er die nicht funktionalen Anforderungen erfüllt.
Vom SQL Database Copy würde ich allerdings abraten, da der doch eine gewisse Kopplung auf Datenstrukturebene mit sich bringt, und sollte man sich für Queues entscheiden, würde ich keinen geteilten ESB/Cluster aufbauen, sondern auch diesen aufteilen und jeweils in die Verantwortung des Daten bereitstellenden Teams geben. Denn von wem würde der geteilte Cluster betrieben werden? Wer fühlt sich verantwortlich? Wenn es nur eine Infrastruktur-Komponente ist, dann ist das Team darum nicht am Kunden orientiert und kann keine unternehmerische Verantwortung aufbauen und ist erst recht nicht unabhängig.
Wenn ich diese Replikation nun für meine diversen Microservices mache, dann werde ich nicht besonders effektiv sein, da ich die meiste Zeit nicht an Funktionen für den Kunden, sondern an Funktionen für meine Architektur arbeite. Doch was ist dann ein guter Schnitt auf technischer Ebene?
Eine gute Faustregel ist, hier pro Team ein System zu bauen. Dies könnte man als Makroservice oder Self-Contained System [SCS] bezeichnen. So reduziert sich der Aufwand der Replikation auf wenige Systeme, die Systeme selbst werden nicht zu komplex und bieten für sich selbst, quasi unabhängig, einen Kundenvorteil. Es kann aber auch hilfreich sein, dieser Faustregel nicht strikt zu folgen, sondern über Methoden wie dem taktischen Teil von Domain-Driven Design (hier schließt sich ein Kreis) zu Bounded Contexts zu finden. Man könnte dann für jeden dieser Contexts ein eigenes System entwickeln. Ein Beispiel dazu: Im Bereich „Fachlichkeit“ haben wir den Schnitt Erkunden, Entscheiden und Erfüllen betrachtet. Nun könnten wir für jedes Team je ein System bauen. Oder wir stellen fest, dass Produkt-Listen und Produkt-Detailseiten für uns verschiedene Bounded Contexts sind. Dann würden wir in Erkunden zwei Systeme entwerfen und in Entscheiden und Erfüllen bei einem bleiben. Die Systeme könnten „Finden“ und „Informieren“ heißen und jeweils für sich selbst dem Kunden Mehrwert bieten. Beide teilen sich dieselben Basisdaten, nämlich Produkte, was nicht dramatisch ist. Wir machen eines der beiden zum Owner der Daten und das andere repliziert sich den Teil der Daten, den es benötigt. Damit der angesprochene Kundenmehrwert erzeugt werden kann, muss so ein System natürlich aus mehr als nur Datenhaltung bestehen. Es bedarf auch eines Frontends, und nicht zu vergessen, muss das System auch irgendwo aktiv ausgeführt werden. Wir trennen hier also ähnlich wie bei der Fachlichkeit vertikal und nicht horizontal. Ein Self-Contained System beinhaltet Frontend, Backend und Operations (siehe Abbildung 3).
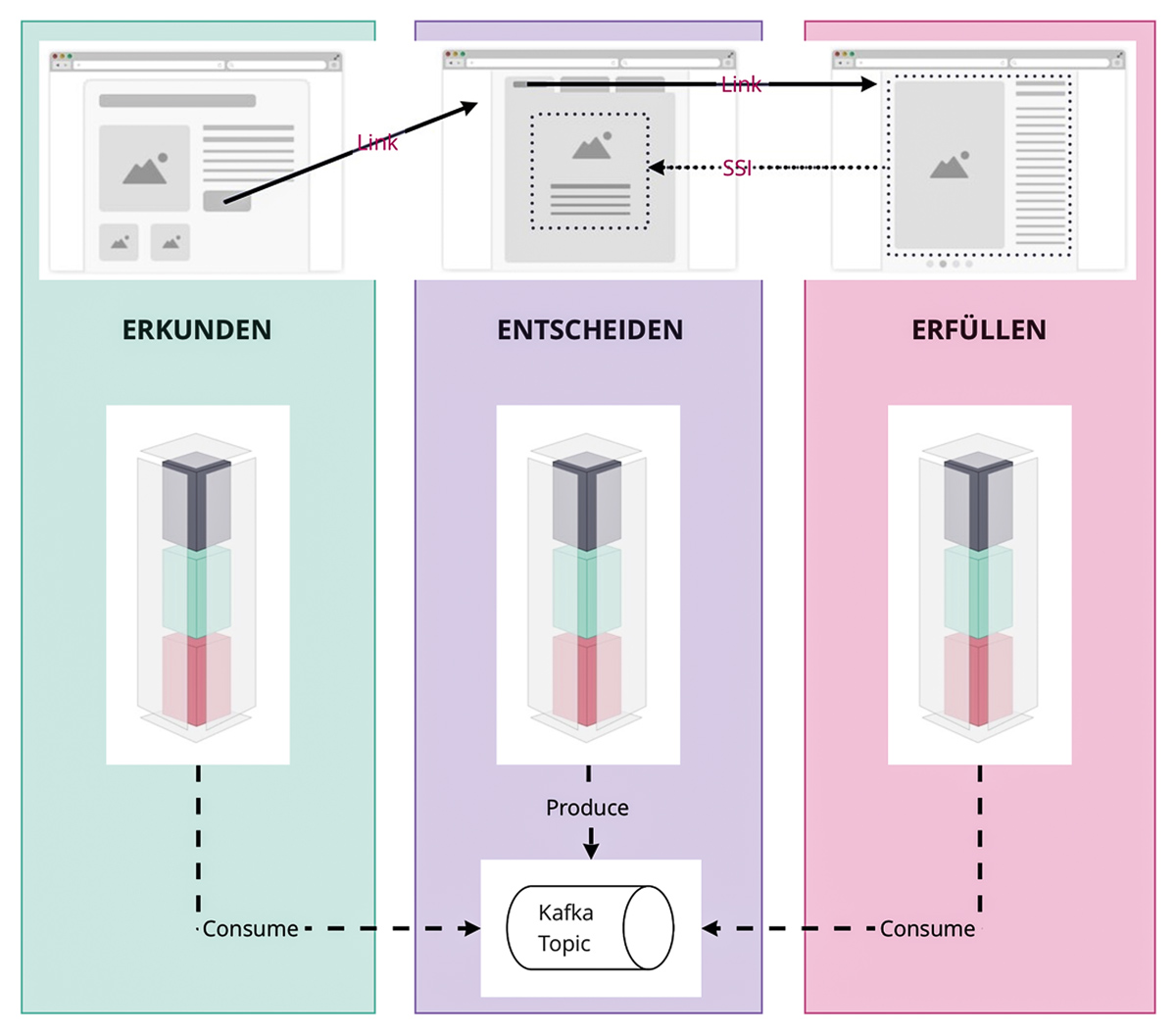
Abb. 3: Lose gekoppelte Self-Contained Systems mit Frontend- und Backend-Integration
Wie wir Daten lose austauschen, haben wir uns bereits angeschaut, aber wie funktioniert lose Kopplung eines Frontends? Ist das nicht ein Widerspruch? Was lose Kopplung im Frontend angeht, kann man auf eine Vielzahl an Möglichkeiten zurückgreifen, die wir hier alle gar nicht im Detail besprechen können. Michael Geers beschreibt in seinem Buch „Micro Frontends“ [Gee20] Vor- und Nachteile sowie Strategien jeder der Möglichkeiten und bietet damit einen super Anknüpfungspunkt.
Hier möchte ich nur die klassischste Variante der „Links“ und „Server-Side-Includes“ erwähnen. Sprechen wir von einer Webapplikation, bieten Links einen wunderbaren Mechanismus, um zwei Systeme lose gekoppelt zu integrieren. Jedes System hat seine eigene URL, hinter einem Proxy vereint, auf eine Domain gemappt. So kann durch einen Link zwischen zwei Systemen gewechselt werden, ohne dass der Anwender dies merkt. Nur auf ein gemeinsames Visuelles Design muss man sich verständigen.
Geht es darum, Teile einer Seite von einem anderen System zu beziehen, lässt sich der erwähnte Proxy um Server-Side-Includes erweitern und so durch ein Pseudo-HTML-Tag ein Template-Include aus einer anderen Quelle machen. Quasi wie ein Bild, nur dass eben kein Bild, sondern HTML zurückkommt und das Tag nicht im Browser, sondern vom Proxy aufgelöst wird. So kann sowohl das System der Seite als auch das System des Teilbereichs eigenständig dessen Frontend weiterentwickeln. Ebenso lässt sich eine solche Integration auch per AJAX im Browser lösen und an dieser Stelle möchte ich dann auf das Buch von Michael verweisen [Gee20], weil wir sonst die Büchse der Pandora öffnen. Es gibt noch diverse weitere Aspekte, die zu berücksichtigen sind, um sich die Unabhängigkeit zwischen den technischen Systemen nicht zu zerstören. Als besonders wichtig erachte ich noch das „Share-Nothing“-Prinzip, welches ich hier anreißen möchte. Nicht nur synchrone HTTP-Schnittstellen sind eine harte Kopplung, sondern auch geteilte Dependencies, wie eine geteilte Bibliothek. Eine solche verursacht per se eine sehr harte Kopplung zwischen beiden Systemen und wirft die Frage auf: Wer ist für die Library verantwortlich? Und schon haben wir ein Problem. Natürlich gibt es neben den erwähnten Web-Schnittstellen und Libraries noch weitere Arten solcher Kopplungen. Eine schöne Übersicht über diese bietet uns der strategische DDD-Teil, der mithilfe von Context Maps und deren Kopplungsarten Probleme aufzeigen oder vorweg verhindern kann.
Weitere Aspekte einer losen Architektur lassen sich bei den ISA-Principles [ISA] nachlesen. Und wir wollen jetzt zu einem weiteren Themenbereich kommen, der für unsere „Responsible Architecture“ essenziell notwendig ist: Continuous Everything. Nun haben wir die Unabhängigkeit über Makro-Architektur-Regeln sichergestellt und können etwas tiefer in den Mikro-Architektur-Bereich blicken, der uns Geschwindigkeit bringt. Hier ist vor allem entscheidend, dass jedes Team von Continuous Everything Gebrauch macht. Das heißt, über CI/CD-Pipelines nicht nur Applikationen, sondern auch Infrastruktur und weitere Konfiguration zu deployen. Damit dies gelingt, empfiehlt sich eine ausgiebige Testautomatisierung und die Nutzung von Infrastruktur-Plattformen, wie Public Clouds und/oder Kubernetes, sowie Trunk Based Development.
Es gilt die Regel, alles was mehrfach ausgeführt wird und einem festen Ablauf folgt, zu automatisieren. Das ist auf kurzen Zeitraum betrachtet aufwendig, zahlt sich aber schon schnell aus. Ich kenne ehrlich gesagt wenige Systeme, die nur so einen kurzen Zeitraum entwickelt werden, dass sich Automatisierung nicht lohnt. Selbst beim Programmieren von Wegwerf-Prototypen zahlt sich der Aufwand einer rudimentären CI/CD-Pipeline aus.
Off topic: Wen das Thema Architektur an dieser Stelle etwas überwältigt, dem empfehle ich die Seite von Simon Brown [Bro] als Anlaufstelle, um sich in das Thema reinzudenken.
Fazit
Um unsere eigene, bestmögliche Architektur zu finden, sind diverse Bereiche zu betrachten. Die Technik ist nur ein kleiner Teil, der sogar erst zuletzt betrachtet werden sollte. Architekten müssen ihre Rolle und vor allem ihren Horizont erweitern und alt Gelerntes neu denken. Effizienz spielt eine immer geringere Rolle als noch vor einigen Jahren, und Unabhängigkeit der Teilbereiche wird immer entscheidender. Es reicht nicht aus, nur Technologie zu studieren, sondern man muss sich auch Wissen über fachliche und organisatorische Methoden aneignen. Nur, wer alle Disziplinen kombiniert und nicht blind einem Konferenz-Hype folgt, wird am Ende eine Architektur finden, die Verantwortung, Geschwindigkeit, Effektivität, Spaß und damit unternehmerischen Erfolg hervorbringt.
Weitere Informationen
[Bro] S.Brown, https://softwarearchitecturefordevelopers.com
[Chr20] J. Christ, S. Harrer, M. Huber Remove Mob Programming, innoQ Deutschland GmbH, 2020
[Gee20] M. Geers, Micro Frontends in Action, Manning, 2020
[Hef19] H. Helfand, Dynamic Reteaming, Reteam, 2019
[ISA] https://isa-principles.org
[Mar20] L. David Marquet, Leadership Is Language, Penguin, 2020
[Rie21] E. Ries, The Lean Startup, Currency, 2021
[RMP] https://www.remotemobprogramming.org
[SCS] http://scs-architecture.org
[Ske19] M. Skelton, M. Pais, Team Topologies, IT Revolution Press, 2019









