

Digitale Transformation und digitale Geschäftsmodelle zählen zu den Trendthemen der Softwareentwicklung. Gleichzeitig verkürzt sich die Time-to-Market, was auch kürzere Entwicklungszyklen zur Folge hat. Somit steht bis zum Go-Live für Entwicklung und Test von Softwareprodukten weniger Zeit zur Verfügung.
Um weiterhin eine gleichbleibend hohe Softwarequalität gewährleisten zu können, bietet sich der Einsatz von KI-basierten Testwerkzeugen an, welche eine Effizienzsteigerung des Softwaretests versprechen. Verglichen mit klassischen Werkzeugen lassen sich in gleicher Zeiteinheit mittels KI mehr Testfälle erstellen. Eine höhere Testabdeckung ermöglicht eine fundiertere Einschätzung der Softwarequalität.
Aktuelle Einsatzgebiete von KI im Softwaretest
Wie eine von uns durchgeführte Recherche [Win19] ergab, lassen sich sowohl klassische als auch aktuell verfügbare KI-basierte Testwerkzeuge einer oder mehreren Phasen des Testprozesses zuordnen (siehe Abbildung 1). Es zeigte sich, dass bereits heute eine große Auswahl an KI-basierten Werkzeugen für die Testausführung (TAU) zur Verfügung steht, jedoch nur wenige für die Testfallerstellung und Testergebnisanalyse.
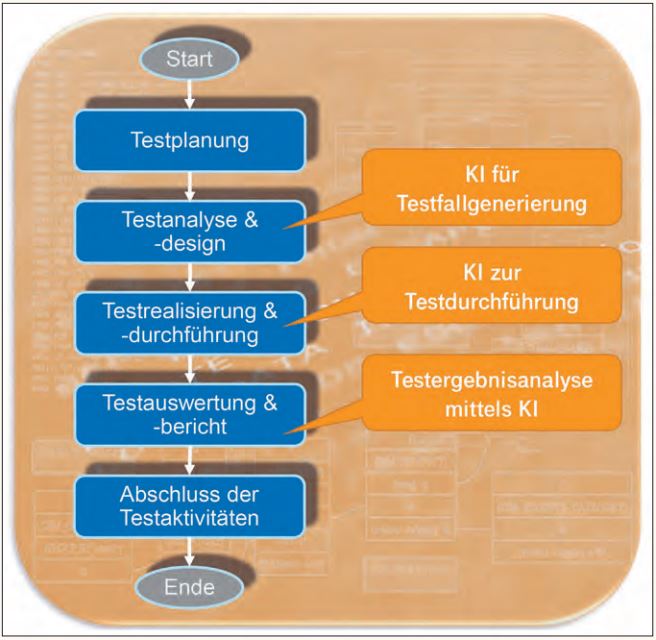
Abb. 1: Drei potenzielle Einsatzgebiete von KI im Softwaretest
Die große Anzahl an TAU-Werkzeugen mit KI-Unterstützung könnte auf eine gewisse Reife in diesem Bereich hindeuten. Daher erscheint es lohnenswert zu untersuchen, ob KI-basierte gegenüber klassischen TAU-Werkzeugen Vorteile bieten. Vorstellbar wäre, dass mithilfe von KI – ähnlich wie in anderen Bereichen [Hil19] – die Effizienz und Effektivität der Testausführung erhöht werden könnte. Beide Aspekte wollen wir im Folgenden genauer beleuchten.
Testskripte sind essenziell für eine automatisierte Testdurchführung. Allerdings stellt ihre manuelle Implementierung oft ein Nadelöhr – insbesondere in agilen Projekten – dar.
Angenommen, wir könnten diese zumeist zeitintensive Tätigkeit mithilfe von KI ebenfalls automatisieren, so würde dies die Effizienz drastisch steigern. Wie diese Vision in der Realität umsetzbar ist, wollen wir weiter unten aufzeigen.
Kann KI die Effizienz und Effektivität der Testausführung steigern?
In einer Fallstudie [Win19] untersuchten wir eine mögliche Effizienz- und Effektivitätssteigerung durch KI-basierte TAU-Werkzeuge. Aufgrund des bereits heute großen Angebots an solchen Werkzeugen konnten wir nicht alle Werkzeuge im Detail betrachten. Daher konzentrierten wir uns auf TAU-Werkzeuge zum Test von Webapplikationen, wie Testcraft [TestC], Testim [Testi], TestComplete [SmartB], Mabl [mabl] und Applitools [AppliT]. Diese Werkzeuge erkennen visuelle Abweichungen anhand einer Gegenüberstellung von Screenshots der Soll- und Ist-Zustände einer Webseite. Zur Versuchsdurchführung diente uns die Demo-Applikation „Parabank“ [ParaB], welche ein typisches Onlinebanking-Portal nachbildet und Funktionen, wie Überweisungen und Konteneröffnungen, bereitstellt.
Die Untersuchung der ausgewählten Werkzeuge nahmen wir anhand unterschiedlicher Testszenarien basierend auf den bereitgestellten Funktionen, zum Beispiel User-Login, der Demo-Applikation vor. Hierzu fügten wir mittels der Error-Seeding-Methode künstlich Fehler in die Demo-Webapplikation ein (siehe Abbildung 2). Mit diesem Versuchsaufbau evaluierten wir drei ausgewählte Testwerkzeuge in jeweils rund 80 Testdurchläufen. Hierbei führten wir in verschiedenen Kombinationen sechs Testfälle1 mit 15 künstlichen Fehlern, in Bezug auf Position, Farbe und Größe der Webelemente, durch. Als Konsequenz wurden im Layout der Applikation Veränderungen, wie in Abbildung 2 zu sehen, vollzogen. Dabei durchlief jedes Testwerkzeug, ob ML-basiert oder klassisch, die exakt selbe Anzahl und Konstellation der Testdurchläufe.
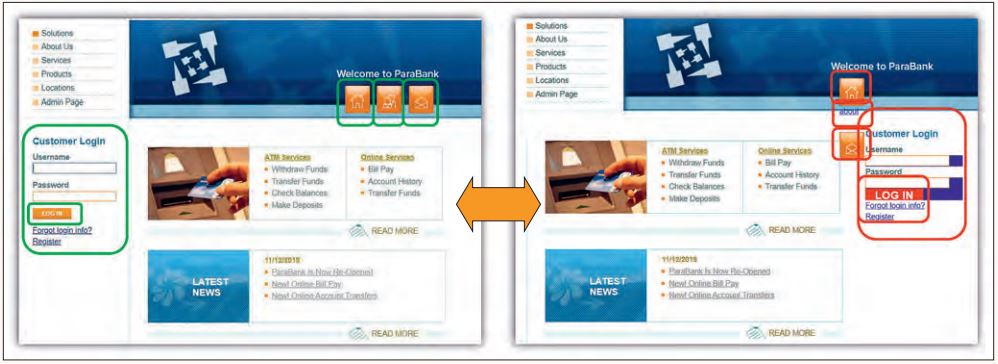
Abb. 2: Soll- vs. Ist-Zustand der Demo-Applikation
Der Fokus der Fallstudie lag bewusst auf dem Vergleich der ausgewählten ML-unterstützten Testautomatisierungswerkzeuge zu klassischer Testautomatisierung auf Selenium/Java-Basis, welche zur Sicherstellung der Vergleichbarkeit um regelbasierte, visuelle Prüfungen ergänzt wurden. Vergleiche zu fortschrittlicheren Technologien, wie dem
modellbasierten Testen, waren dabei nicht Gegenstand der Betrachtung.
Sind Effizienz und Effektivität von KI messbar?
Zur Messung der Effizienz und Effektivität der zu untersuchenden TAU-Werkzeuge wurden von uns geeignete Metriken festgelegt, welche wir anhand der von uns formulierten Qualitätsziele2 mittels der Goal-Question-Metrics-Methode (GQM) definierten. Mit diesen Metriken erfassten wir einerseits die benötigte Zeit für Erstellungs- und Wartungsaufwände (Spalten 7 und 8 in Tabelle 1), um eine Aussage zur Effizienz treffen zu können. Andererseits maßen wir mit der Metrik der Fehlerauffindungsrate die Effektivität der untersuchten Testwerkzeuge.

Tabelle 1: Gesamte Fehlerhäufung der untersuchten Werkzeuge sowie die ermittelten Zeitersparniswerte
Das Testautomatisierungswerkzeug klassifiziert dabei die Zustände der Webseite anhand der binären Klassifikation wie folgt:
Klasse 1 Fehler: Fehlerhafte Zustände der Demo-Applikation
- TP: True-Positive (1,1) = Fehlerhafter Zustand und wurde auch als solcher klassifiziert
- FN: False-Negative (0,1) = Fehlerhafter Zustand und wurde vom Klassifikator auch als korrekt klassifiziert
Klasse 2 Fehler: Korrekte Zustände der Demo-Applikation
- FP: False-Positive (1,0) = Korrekter Zustand und wurde als fehlerhaft klassifiziert
- TN: True-Negative (0,0) = Korrekter Zustand und wurde auch als solcher klassifiziert
Die Rate der Fehlerauffindung wurde dabei mittels bedingten Wahrscheinlichkeiten bestimmt [Alt94] (siehe Kasten 1).
Kasten 1
Das sind die Ergebnisse
Tabelle 1 zeigt die von uns gemessenen Gesamtergebnisse der untersuchten Werkzeuge auf. In den ersten sechs Spalten der Tabelle sind bezüglich der Effektivität zum einen die klassifizierten Fehlerhäufigkeiten (Spalten 1 bis 4) und die daraus berechneten Sensitivitäts- respektive Spezifitätsraten (Spalten 5 und 6) aufgezeigt.
Zum anderen ist in den Spalten 7 und 8 die prozentuale Zeitersparnis der Erstellungsund Wartungsaufwände der einzelnen Tools gegenüber klassischer Testautomatisierung dokumentiert. Als Vergleichswerte zur klassischen Testautomatisierung dienten Werte aus einer intern durchgeführten Aufwandsstudie von Testautomatisierungsexperten.
Jedes Testwerkzeug konnte in der gesamten Durchführung der verschiedenen Testdurchführungen maximal 52 künstlich eingefügte Fehler auffinden (True-Positive/False-Negative, Tabelle 1, Spalte 1/3). Darüber hinaus war es möglich, maximal 160 Zustände als korrekt zu klassifizieren.
Den Ergebnissen in Tabelle 1 ist zu entnehmen, dass Tool 1 im Rahmen der Effektivität alle künstlich eingefügten Fehler finden konnte und demnach eine berechnete Sensitivität von 100 Prozent erreichen konnte. Demgegenüber stehen Tool 2 und 3, welche jeweils jeden zweiten eingesetzten Fehler finden konnten, sodass eine Sensitivitätsrate von 50 Prozent errechnet wurde (Tabelle 1, Spalte 7).
Auffallend ist, dass beide Tools (2 und 3) nur jeweils 50 Prozent der eingesetzten Fehler auffinden konnten. Bei den nicht aufgefundenen Fehlern handelte es sich immer um künstlich eingesetzte Fehler, welche nicht in unmittelbarem Zusammenhang mit einem durchzuführenden Testschritt eines Testfalls standen. Abbildung 2 zeigt den Beispiel-Testfall Login: Eingabe Benutzerkennung; Eingabe Passwort; Login-Button klicken. Nicht im Zusammenhang mit den Testschritten wäre beispielsweise der positionsveränderte Home-Button.
Hinsichtlich Spezifität klassifizierten die Tools 2 und 3 die korrekten Zustände richtig, sodass diese hierbei eine Rate von 100 Prozent erreichten konnten (Tabelle 1, Spalte 8). Demgegenüber steht das Ergebnis des Tools 1, welches darüber hinaus eine hohe Anzahl an korrekten Zuständen der Webseite fälschlicherweise als inkorrekt klassifizierte und somit eine Spezifitätsrate von 33 Prozent erreichte. Tool 1 reagierte sensitiv auf sämtliche Veränderungen der Webseite wie dynamische Wertänderungen (z. B. aktueller Kontostand), sodass hierbei mehr Fehlerhäufigkeiten gezählt werden konnten als bei den beiden anderen Werkzeugen.
Was bedeuten diese Ergebnisse?
Die Ergebnisse unserer Fallstudie (Tabelle 1, Spalten 7 und 8) zeigen auf, dass die betrachteten Werkzeuge eine deutliche Zeitersparnis gegenüber einer klassisch realisierten Testautomatisierung (Selenium/Java) erzielten. Somit ist für KI-basierte TAU-Werkzeuge hinsichtlich der Effizienz eine deutliche Reduzierung der Erstellungsaufwände für Testskripte zu erkennen. Dies ist auch auf die Capture & Replay-Funktion der Werkzeuge rückführbar.
Mit einer Sensitivitätsrate von jeweils 50 Prozent sind die Tools 2 und 3 für den täglichen Praxiseinsatz nicht zufriedenstellend, da die Auffindung von nur jedem zweiten Fehler inakzeptabel ist. Demgegenüber überzeugte das Tool 1 mit einer Sensitivität gegenüber den künstlich eingesetzten Fehlern von 100 Prozent. Allerdings war bei diesem Werkzeug eine erhöhte Falschklassifizierung von korrekten Zuständen zu verzeichnen (Tabelle 1, Spalte 4). So führten die False-Positive-Ergebnisse zu einer Spezifitätsrate gegenüber korrekten Zuständen von rund 33 Prozent. Das bedeutet, dass rund ein Drittel der eigentlich korrekt dargestellten Webobjekte fälschlicherweise als falsch klassifiziert wurde. Im Hinblick auf die Fehlerklassifizierung zeigt sich demnach, dass für KI-basierte TAU-Werkzeuge noch Verbesserungspotenzial besteht.
KI-basierte TAU-Werkzeuge: Top oder Flop?
Künstliche Intelligenz (KI) und insbesondere Maschinelles Lernen (ML) kommen bereits im Softwaretest zum Einsatz und werden von den Herstellern der Testwerkzeuge stark angepriesen. Die KI-basierten TAU-Werkzeuge verhelfen aufgrund ihrer Erweiterung der Fehlerauffindung um das visuelle Spektrum dabei, eine höhere Testabdeckung zu erreichen.
Unserer Meinung nach ist die erhebliche Reduzierung der Erstellungsaufwände als durchweg positiv zu betrachten. Die hohe Anzahl an Fehlklassifizierungen der vom Werkzeug erkannten Objekte führte jedoch zu beachtlichen Aufwänden für eine manuelle Überprüfung der inkorrekt klassifizierten Webobjekte. Daher erscheinen die verwendeten KI-Modelle der untersuchten Testautomatisierungswerkzeuge noch nicht ausreichend trainiert. Die untersuchten KI-basierten Testautomatisierungswerkzeuge konnten daher momentan noch nicht vollständig überzeugen. Allerdings erwarten wir mittelfristig noch ein größeres Verbesserungspotenzial durch ein intensiveres Training der verwendeten KI-Modelle. Dies sollte sich dann positiv auf die Sensitivität- und Spezifitätsrate der Fehlerklassifizierungen auswirken.
Die Ergebnisse unserer Fallstudie zeigen auf, dass gute Ansätze für TAU-Werkzeuge mit KI-Unterstützung vorhanden sind, jedoch die eingesetzten Technologien noch nicht zur Gänze ausgereift erscheinen. Hervorzuheben ist, dass in der Qualitätssicherung ein deutlicher Trend in Richtung KI- beziehungsweise ML-Einsatz erkennbar ist.
Effizientere Testautomatisierung mithilfe von KI
Wie bereits hervorgehoben wurde, kann KI nicht nur bei Testautomatisierungswerkzeugen genutzt werden, sondern ihr Einsatz kann auch bei der Erstellung von Testskripten hilfreich sein. Die manuelle Erstellung solcher Skripte (siehe Abbildung 3) ist meist zeitintensiv und stellt somit einen der größten Aufwandstreiber im Softwaretest dar.
Abb. 3: Manuelle Erstellung von ausführbaren Testskripten
Daher reicht die in agilen Projekten zur Verfügung stehende Zeit oft nicht aus, um alle in einem Sprint benötigten Testskripte zu erstellen. Wenn überhaupt werden die verbleibenden Testfälle lediglich manuell durchgeführt und können aufgrund fehlender Testskripte nicht in einen automatisch ablaufenden Regressionstest aufgenommen werden.
Testskriptgenerierung: Ein weiteres Anwendungsgebiet für KI
Könnte KI dazu genutzt werden, um ausführbare Testskripte in der jeweils benötigten Programmiersprache für ein beliebiges TAU-Werkzeug automatisch zu erzeugen, wäre dies eine wegweisende Innovation für die Testautomatisierung. Hierdurch würde nicht nur die zeitintensive manuelle Erstellung von Testskripten entfallen, sondern es wären auch wesentlich mehr Skripte in der verfügbaren Zeit erstellbar.
KI und NLP – Ein starkes Team
Stellen wir uns ein Szenario vor, bei dem bestehende manuelle Testfälle, die in natürlicher Sprache beschrieben sind, in kürzester Zeit in automatisch ausführbare Testskripte überführt werden könnten. Mit dieser Möglichkeit würde man nicht nur Zeit sparen, sondern auch die Qualität der Testskripte deutlich erhöhen. Dies kann nur mit einer fortschrittlichen KI-gesteuerten und auf Natural Language Processing (NLP) basierenden Technologie ermöglicht werden.
Allerdings stellt der Einsatz unterschiedlicher Testautomatisierungswerkzeuge in Projekten eine Herausforderung dar, da deren Testskripte für gewöhnlich in einer werkzeugspezifischen Programmiersprache zu erstellen sind. Daher scheint die Realisierung einer Out-of-the-Box-Generierung von Testskripten als unmöglich; es wird eine flexible und schnell adaptierbare Lösung zur Generierung benötigt.
Die Lösung
Die Kombination von KI und NLP konnte bereits für unterschiedliche Einsatzszenarien, wie Chat-Bots und E-Commerce [Gen17], erfolgreich eingesetzt werden, neu ist aber ihre Anwendung zur automatischen Generierung von Testskripten. Basierend auf vorhandenen Testfallbeschreibungen, ob tabellarisch oder als Textdokumente, ermöglicht die in Abbildung 4 gezeigte Lösung Manual to Script (M2S), automatisiert ausführbare Testskripte für beliebige Zielsprachen zu erzeugen.
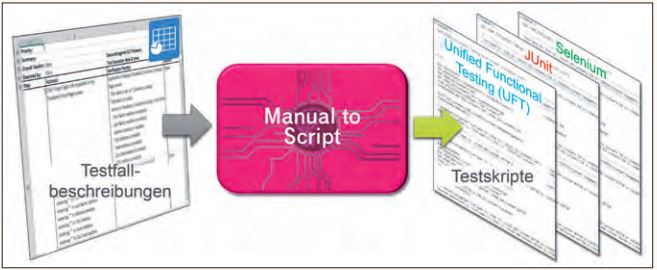
Abb. 4: Manual to Script – eine Lösung zur Transformation von manuellen in ausführbare Testfälle
Im Gegensatz zum regelbasierten NLP erlaubt die KI-basierte Verarbeitung der Eingabedaten eine wesentlich flexiblere Erkennung der unterschiedlichen syntaktischen Bestandteile eines Satzes. So lassen sich gezielt konkrete Testaktionen, Verifikationen und Testdaten erkennen und ableiten. Diese Daten werden anschließend von einem Code-Generator genutzt, um ausführbare Testskripte in der gewünschten Zielsprache zu erzeugen.
Dank seines modellbasierten Ansatzes, bei dem die Code-Generierung auf Modell-zu-Text-Transformationstemplates basiert, ist eine schnelle und flexible Adaptierung für neue Zielsprachen möglich. Die von M2S generierten Testskripte implementieren das Page Object Pattern und sind mit manuell erstellten Testskripten, die ebenfalls dieses Pattern anwenden, vergleichbar.
Vielversprechendes Einsparungspotenzial
Um das mit M2S erzielbare Einsparungspotenzial zu ermitteln, haben wir unter anderem einen Proof of Concept im Automotive-Umfeld durchgeführt. Hierzu wurden für 20 vorhandene Testfälle einerseits manuell und anderseits automatisiert mittels M2S Testskripte für Micro Focus UFT erzeugt.
Statt 64 Stunden für eine manuelle Implementierung benötigten wir mit M2S nur 32,8 Stunden für die Generierung von UFT-Testskripten. Somit ergab sich für M2S ein Einsparungspotenzial von ca. 50 Prozent. Hieraus schließen wir, dass mit der vorgestellten KI-basierten Lösung Tests in der zur Verfügung stehenden Zeit automatisiert und die hierfür notwendigen Aufwände merklich reduziert werden können. Daraus resultiert auch eine kürzere Time-to-Market mit erhöhter Testqualität.
Ein Ausblick
Ob KI-basierte TAU-Werkzeuge zukünftig effizienzoptimierend einsetzbar sind, ist aktuell noch mit ein paar Fragezeichen zu versehen. Für all jene, die bereits in naher Zukunft ein solches Werkzeug nutzen möchten, empfiehlt sich, vorab eine detaillierte Werkzeuganalyse durchzuführen. Nur so ist eine fundierte Abschätzung zwischen Werbeversprechen und dem tatsächlichen Nutzen möglich.
Wie anhand unserer Lösung Manual to Script aufgezeigt, ist gegenüber dem Einsatz von TAU-Werkzeugen bereits heute ein Mehrwert von KI zur Generierung von Testskripten aus manuellen Testfallbeschreibungen erzielbar. Daher werden wir diese Lösung zukünftig in weiteren Projekten und Branchen einsetzen.
Aufgrund der von uns aufgezeigten positiven Ergebnisse gehen wir davon aus, dass zukünftig der Einsatz von KI- beziehungsweise ML-Technologien im Softwaretest stark vorangetrieben wird und sich auch die Zahl entsprechender Werkzeuge in allen Bereichen des Tests erhöhen dürfte.
Referenzen
[Alt94] D. G. Altman, J. M. Bland, Diagnostic tests. 1: Sensitivity and specificity, in: BMJ: British Medical Journal, 11.6.1994, S. 1552
[AppliT] https://applitools.com/
[Gen17] P. Gentsch, Künstliche Intelligenz für Sales, Marketing und Service: Mit AI und Bots zu einem Algorithmic Business – Konzepte, Technologien und Best Practices, Springer. 2017
[Hil19] W. Hildesheim, D. Michelsen, Künstliche Intelligenz im Jahr 2018 – Aktueller Stand von branchenübergreifenden KI-Lösungen: Was ist möglich? Was nicht? Beispiele und Empfehlungen, in: Künstliche Intelligenz (S. 119-142), Springer, 2019
[mabl] https://www.mabl.com/
[ParaB] https://parabank.parasoft.com/parabank/overview.htm
[SmartB] https://smartbear.de
[TestC] https://www.testcraft.io/
[Testi] https://www.testim.io/
[Win19] K. Winkler, Analyse zur Auswirkung von Machine Learning Algorithmen auf Effektivität und Effizienz in Testautomatisierungswerkzeugen, Hochschule für Telekommunikation Leipzig, 2019









