

Die Anforderungen an den Betrieb von Modellen des Machine Learning (ML) fallen je nach Kontext unterschiedlich aus. Typischerweise müssen sich die Betreiber zum Beispiel um Fragen der Server, des Netzwerks, der Sicherheit, der Ausführungsumgebung, des Build & Deployment oder der Hochverfügbarkeit kümmern. Auch sollten sich die verwendeten Ressourcen ohne manuelle Eingriffe automatisch anpassen. Hinzu kommen Fragen des Logging: Wenn der Inferenz-Service etwa auf mehr als einer Instanz läuft, wäre eine Aggregation wünschenswert, die das Suchen und Filtern ermöglicht. Und nicht zuletzt das Monitoring & Alerting: Minimalanforderungen sind hier üblicherweise Informationen über die Anzahl der Aufrufe und Fehler sowie Benachrichtigungen, wenn der Anteil der Fehler einen definierten Schwellenwert überschreitet. Data Scientists kommen mit all diesen Anforderungen kaum zurecht – dafür ist ein Team notwendig, das über all diese Infrastruktur-Kompetenzen verfügt.
Aber es geht auch einfacher. Hier wird in Folge ein pragmatischer Ansatz vorgestellt, der es ML-Praktikern erlaubt, Modelle selbständig in Produktion zu bringen, während sie sich weiterhin auf ihre Modelle fokussieren. Abhilfe schafft die Cloud.
Die serverlose Lösung
Jeder große Cloud-Provider bietet heutzutage mehrere Dienste an, die für den Betrieb von Modellen interessant sind. Die gängigste Variante besteht darin, eine virtuelle Maschine zu mieten und den Inferenz-Service darauf zu installieren. Damit übernimmt die Cloud die Aufgabe, sich um Server, Netzwerk und Sicherheit zu kümmern. Die gemietete virtuelle Maschine kann neben einem Betriebssystem auch mit der für ML typischen Laufzeitumgebung ausgestattet sein – etwa Python, Scikit-Learn, Tensorflow, Pytorch und Flask. Die Aspekte Build & Deployment, Hochverfügbarkeit, Logging und Monitoring & Alerting müssen bei diesem Ansatz aber weiterhin zusätzlich gelöst werden.
Einen wesentlich komfortableren Weg stellt der Ansatz „Function as a Service“ (FaaS) zur Verfügung. Neben der Bereitstellung von Modellen müssen sich die Data Scientists dann nur um die Paketierung kümmern. Den Rest übernimmt der Cloud-Service. Aber woraus bestehen diese Cloud-Funktionen und was bieten sie im Detail? Im Wesentlichen lassen sie sich durch zwei Eigenschaften definieren: Zum einen sind Cloud-Funktionen im hohen Maße vorinstallierte und präkonfigurierte Ausführungsumgebungen. Zum zweiten laufen Cloud-Funktionen nicht im 24/7-Betrieb. Vielmehr starten die Anwender sie nach Bedarf, erledigen ihre Aufgabe und beenden sie dann wieder.
Zurzeit bieten Amazon Web Services, Google Cloud, Azure Cloud, Firebase, Oracle Cloud und IBM Bluemix solche Cloud-Funktionen an. Eine Übersicht der wichtigsten Eigenschaften zeigt Abbildung 1. Für das ML-Einsatzgebiet sind insbesondere Python-Laufzeitumgebungen interessant, die so gut wie alle Anbieter bereitstellen.
Der Weg zur Cloud-Funktion
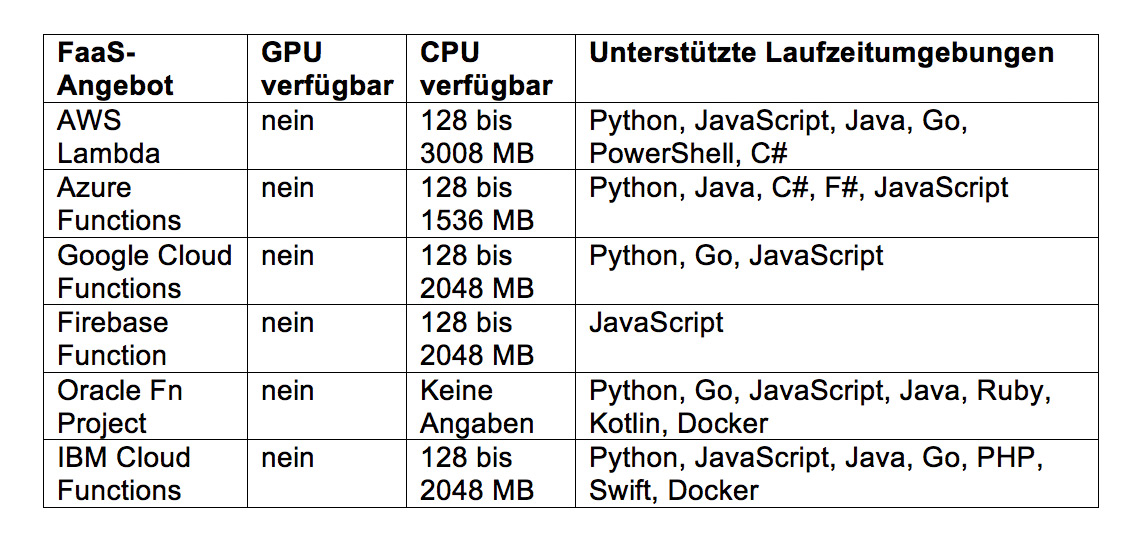
Abb. 1: Angebote von Cloud-Funktionen
Eine Bereitstellung der Inferenz-Funktion als Cloud-Funktion besteht im Wesentlichen aus vier Schritten:
- Benutzerkonto einrichten und CLI-Tool zur Verwaltung von Cloud-Ressourcen installieren
- Signatur der Funktion Cloud-konform anpassen
- Diverse Laufzeiteinstellungen wählen – per Descriptor-Datei oder per Aufrufparameter im CLI-Tool
- Paketierung aller Abhängigkeiten sorgen. Dies ist bei manchen Anbietern unkompliziert, da zum Beispiel FaaS-Angebote von Google und Microsoft den Paketmanager pip unterstützen.
Die Abbildungen 2 und 3 zeigen jeweils ein Beispiel einer Cloud-Funktion für Google. Genaue Anleitungen sind bei den jeweiligen Cloud-Anbietern zu finden.

Abb. 2: Inferenz-Code als Cloud-Funktion

Abb. 3: Deployment einer Cloud-Funktion
Sobald Inferenz-Funktionalität als Cloud-Funktion vorhanden ist, bietet dies mehrere Vorteile, welche die Cloud üblicherweise mit sich bringt: Hochverfügbarkeit und automatische Skalierung: Eine Instanz der Funktion wird gestartet, sobald ein Aufruf erfolgt. Erfolgt ein weiterer Aufruf, während der erste noch nicht verarbeitet ist, wird eine weitere Instanz der Funktion gestartet.
Transparenz: Log-Ausgaben aller Instanzen werden indexiert und sind über eine Konsole verfügbar und durchsuchbar.
Monitoring: Charts mit Informationen über Anzahl und Art der Aufrufe sowie über verbrauchte Ressourcen stehen zur Verfügung. Die Konfiguration von Alerts basierend auf diesen Werten ist einfach.
Integration: Es existieren vielfältige Möglichkeiten, die Funktion mit anderen Cloud-Diensten zu integrieren, falls diese bereits genutzt werden. So kann zum Beispiel die Funktion automatisch gestartet werden, wenn es im Blob-Storage ein neues Objekt gibt, ein Eintrag in der Datenbank geändert wird oder ein HTTP-Aufruf erfolgt. Es ist zudem möglich, auch andere Cloud-Dienste aus der Funktion aufzurufen. Dafür stellt der Cloud-Anbieter üblicherweise Client-Bibliotheken zur Verfügung.
Evaluierung
Doch taugen diese Cloud-Funktionen überhaupt für den Betrieb von ML-Modellen? Um dies zu testen, wurden drei verschiedene Modelle trainiert: das erste für die Bildklassifizierung mit Tensorflow. Trainiert wurde dabei ein MobileNet-Modell mit vier Millionen Koeffizienten. Das zweite Modell diente der Sentiment Analysis von Tweets mit Spacy und „word vectors“. Das Modell umfasst zehn Millionen Koeffizienten. Das dritte Modell unterstützt die Vorhersage von Diabetes durch strukturierte Daten. Genutzt wurde Scikit-learn und ein Random-Forest-Modell mit etwa 1.000 Koeffizienten.
Ziel war es, diese Modelle in der Cloud von Amazon, Google und Microsoft als Funktion zum Laufen zu bringen. Insgesamt gibt es fünf funktionierende Beispiele. Diese sind im Repository des Tests [innoq-ml-serverless] zu finden. Für jedes Beispiel waren zwischen 0,5 und 3 Tage Personenaufwand nötig.
Insgesamt haben sich alle Modelle als tauglich für Cloud-Funktionen erwiesen und alle drei Cloud-Angebote als tauglich für ML – allerdings mit einigen Einschränkungen, die für den einen oder anderen Anwendungsfall relevant sein können:
- Es ist nicht möglich, die Cloud-Funktionen auf der GPU auszuführen.
- Die Gesamtgröße aller Artefakte (Inferenz-Code, Bibliotheken, Modell) darf ein von der Cloud definiertes Limit nicht überschreiten. Dies bereitet Schwierigkeiten bei AWS, wenn ein großes Framework wie Tensorflow ausgeführt werden soll. Es gibt Möglichkeiten, mit denen sich das Paket mit pip und bash auf die binären Dateien einschränken lässt, die nötig sind. Damit wird die Paketierung aufwendiger, funktioniert dafür problemlos. Genaue Verfahren sind in [serverless-ephemeral] und [lambda-layer] beschrieben.
- Die wahrscheinlich wichtigste Einschränkung bei der Nutzung von Cloud-Funktionen ist der sogenannte „cold start“. Dies bedeutet, dass es eine Neu-Initialisierung bei jedem Start der Funktion gibt. Dadurch kommt es bei einem großen Modell zu erheblichen Wartezeiten. Abhilfe können die Anwender schaffen, wenn sie wissen, dass Cloud-Funktionen nach der Benutzung zeitweise im „Cache“ der Cloud bleiben, da sie möglicherweise bald wieder gebraucht werden. Dies ist ein undokumentiertes, aber wohlbekanntes Verhalten. Mehr dazu liefert ein Blogbeitrag von Mikhail Shilkow [cold-start]. Wer teure Ressourcen als globale Variablen definiert, in diesem Fall Modelle, vermeidet die erneute Initialisierung, wenn die Funktion noch im Cache ist. Die Antwortzeiten der Beispielmodelle im hiesigen Fall sind in Abbildung 4 zu sehen.
- Ein weiterer Nachteil der Cloud-Funktionen: Es gibt keine Standardisierung. Das bedeutet, dass sowohl die API, über welche die Cloud die Funktion aufruft, als auch Paketierung und Deployment Cloud-Anbieter-spezifisch sind. Wer zu einem anderen Cloud-Anbieter wechseln will, sollte deshalb den Aufwand für diese Migration einplanen. Da es sich normalerweise um eine Umgestaltung nur weniger Aufrufe handelt, hält sich dieser Aufwand in der Regel aber in Grenzen.
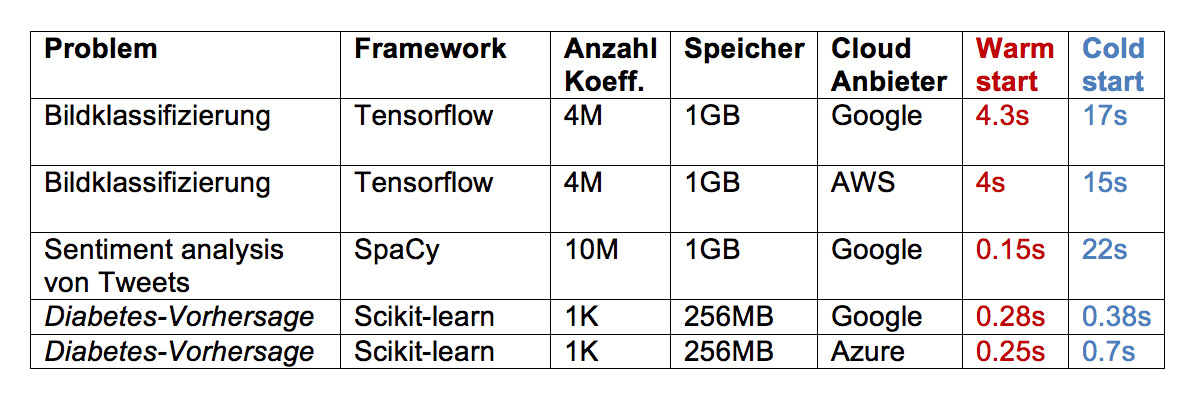
Abb. 4: Ergebnisse der Performance-Messungen
Auch der Faktor „Kosten“ darf nicht vergessen werden. Anwendungsfälle mit viel Last, also vielen Anfragen, ressourcenintensiven Anfragen oder beidem, wären im Betrieb mit Cloud-Funktionen teurer als mit einer Virtual Machine (VM) derselben Ausstattung. Anwendungsfälle mit mittlerer oder kleiner Last wären im Gegenzug billiger als der Betrieb einer VM im 24/7-Betrieb oder gar kostenlos, da viele Cloud-Anbieter ein kostenloses Kontingent an CPU-Zeit zur Verfügung stellen. Eine Schätzung anfallender Kosten bietet zum Beispiel ein entsprechender Rechner im Web [serverless-calc].
Mögliche Alternativen
Moderne Alternativen zu Cloud-Funktionen sind vor allem diverse Container-basierte Lösungen, die auf Docker aufbauen. Einige davon sind Mehrzweck-Lösungen wie etwa Kubernetes-Angebote bei verschiedenen Cloud-Providern. Andere Angebote sind speziell für ML-Inferenz konzipiert, zum Beispiel AWS Sagemaker [sagemaker] oder Seldon [seldon]. Generell haben solche Lösungen mehr Freiheiten und weniger Einschränkungen als Cloud-Funktionen. Andererseits erfordern sie mehr Infrastruktur-Know-how sowie Zeit für die Einrichtung und Instandhaltung, sind aber in jedem Fall einen Blick wert.
Fazit
Cloud-Funktionen sind ein in vielen Kontexten tauglicher Ansatz, damit ML-Modelle mit wenig Aufwand den modernen Anforderungen an den Betrieb gerecht werden. Besonders gut eignen sich dafür „leichtgewichtige“ Modelle. Sobald auch für andere Funktionalitäten im System Cloud-Dienste verwendet werden, lassen sich weitere Vorteile durch eine einfache Integration mit diesen erzielen.
Weitere Informationen
[innoq-ml-serverless] https://github.com/innoq/ml_serverless
[serverless-calc] http://serverlesscalc.com/
[serverless-ephemeral] https://github.com/Accenture/serverless-ephemeral/blob/master/docs/build-tensorflow-package.md
[lambda-layer] https://github.com/antonpaquin/Tensorflow-Lambda-Layer
[cold-start] https://mikhail.io/2018/08/serverless-cold-start-war/
[sagemaker] https://aws.amazon.com/de/sagemaker/
[seldon] https://www.seldon.io/









