

„Herr Müller fährt jeden Morgen mit dem Auto ins Büro. Die Anzahl der Parkplätze vor dem Haus ist jedoch begrenzt. Ein schneller Blick auf seine App verrät ihm bereits beim Einsteigen ins Auto, dass alle Plätze schon belegt sind. Kurz vor der Ankunft erhält Herr Müller eine Push Notification an sein Smartphone, dass gerade ein Parkplatz frei geworden ist. Somit entfällt eine mühevolle Parkplatzsuche im Umkreis.”
Die Thematiken Parken und Mobilität sind im Themengebiet Smart City sehr bekannte Fragestellungen. Insbesondere in Parkhäusern mit klar definierten Stellplätzen ist die Digitalisierung in Form von intelligenten Leitsystemen besonders vorangeschritten. Auch Supermarktketten nutzen sehr intensiv das Monitoring ihrer Parkplatzbelegung, allerdings eher mit dem Ziel, unliebsame Dauerparker fernzuhalten.
Auf solchen überwachten Parkplätzen findet man sehr häufig Bodensensoren, welche geparkte Autos über ihnen registrieren und den Belegungszustand des Parkplatzes über die LoRaWAN-Funktechnologie (Lo ng Ra nge Wide Area Network) weiterführenden Services, wie im Beispiel der App von Herrn Müller, zur Verfügung stellen. Parkplatzbelegungen auf diese Art und Weise zu messen, benötigt einen Bodensensor pro Parkplatz. Gerade bei vielen Stellplätzen kann dies hohe Kosten für Sensoren und Wartungen verursachen.
Optimierte Algorithmen und Hardware ermöglichen eine enorme Verbesserung der Geschwindigkeit und Genauigkeit der Echtzeitdetektion von Objekten in Videos. Darauf aufbauend bietet Machine Learning (ML) für die Erkennung der Parkplatzbelegung einen alternativen Ansatz. In einem möglichen Szenario, welches in Abbildung 1 skizziert wird, werden in einem Kamerabild mittels Neuronaler Netze Objekte mit den zugehörigen Positionen erkannt. Mit diesen Informationen ausgestattet, lassen sich mit einer Kamera mehrere Stellplätze gleichzeitig überwachen.
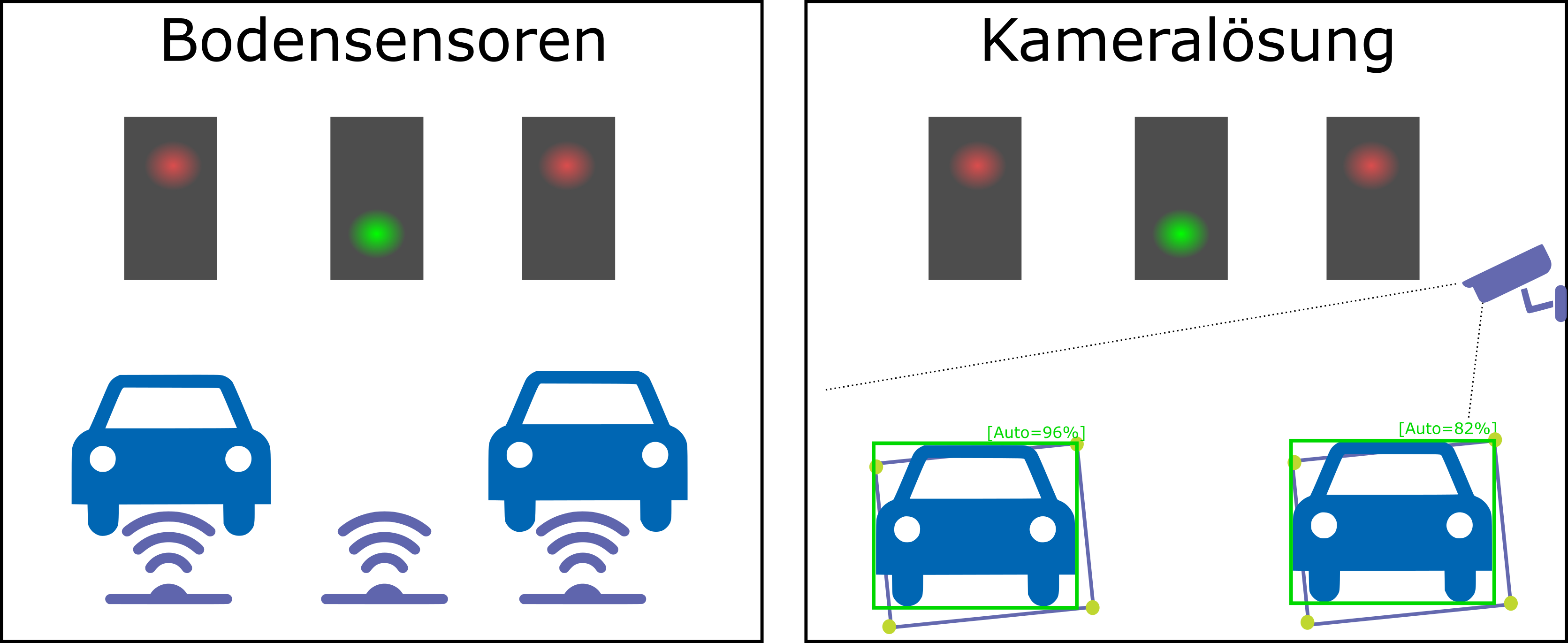
Abb. 1: Bodensensoren vs. kamerabasierte Parkplatzbelegung
Im Rahmen einer Machbarkeitsanalyse hat das IoT-Team der eXXcellent solutions GmbH, unterstützt unter anderem durch ein studentisches Projektteam des Studiengangs Software-Engineering an der Universität Ulm, eine Anwendung entwickelt. Diese nutzt die Objekterkennungsfunktion eines Neuronalen Netzes, um Autos zu erkennen. Die erkannten Autos werden anschließend mit einer hinterlegten Parkplatzkonfiguration abgeglichen, um den Belegungszustand des Parkplatzes zu ermitteln. Im folgenden Abschnitt werfen wir einen Blick auf die grundlegende Funktionsweise des Algorithmus, welcher die Erkennung der Autos ermöglicht.
YOLOv4 – Objekte erkennen in Bildern
Ein Repräsentant aus der Gruppe der Objekterkennungsalgorithmen in Bildern nennt sich YOLOv4 [Boc20]. Dieser Algorithmus hat nichts mit der hippen Version von carpe diem (“You Only Live Once”) zu tun, sondern steht für “You Only Look Once”. Dies ist ein Hinweis darauf, dass es sich hier um einen One-Stage Detector handelt. Diese Kategorie von Objektdetektor nimmt ein Bild als Input und erkennt „auf den ersten Blick” das Objekt. Im Gegensatz dazu lassen sich die Aufgabenstellungen Objektlokalisierung (Wo ist das Objekt?) und Objektklassifikation (Um was für ein Objekt handelt es sich?) jeweils in zwei Schritte aufteilen.
Wie der Name YOLOv4 vermuten lässt, handelt es sich bereits um die vierte Ausbaustufe des YOLO-Algorithmus (vgl. Tabelle 1), der sich durch eine sehr kurze Berechnungszeit auszeichnet. Auf einer Tesla V100, einem mit Tensor-Recheneinheiten ausgestatteten Grafikprozessor, lassen sich Bilder mit einer Geschwindigkeit von bis zu 65 FPS (Frames per Second) auswerten. Diese gute Performanz erlaubt es dem Anwender nun, den Algorithmus auch auf günstiger Hardware zu verwenden, um Videos in Echtzeit auszuwerten.

Tabelle 1: Evolution der Algorithmenklasse
Der YOLOv4-Algorithmus besteht aus vier Stufen (vgl. Abb. 2). In der ersten Stufe wird das Bild entgegengenommen, welches in der zweiten Stufe (Backbone) in verschiedenen Ebenen verarbeitet wird, um charakteristische Bereiche im Bild zu identifizieren. In der dritten Stufe (Neck) werden die in der zweiten Stufe erkannten Charakteristika gemischt, kombiniert und in verschiedenen Auflösungen abgebildet. Im letzten Schritt (Head) wird der Bereich um das Objekt (Bounding Box) erkannt, indem sehr viele verschiedene, überlappende Bereiche im Bild betrachtet werden. Die wahrscheinlichste Region für ein richtig erkanntes Objekt ist diejenige, bei der mehrere benachbarte Regionen dasselbe Objekt vermuten und es somit eine hohe Schnittmenge zwischen den Bereichen gibt (Intersection Over Union). Wenn diese Überschneidung einen Schwellwert übersteigt, meldet der Algorithmus das gefundene Objekt an der ermittelten Stelle zurück.
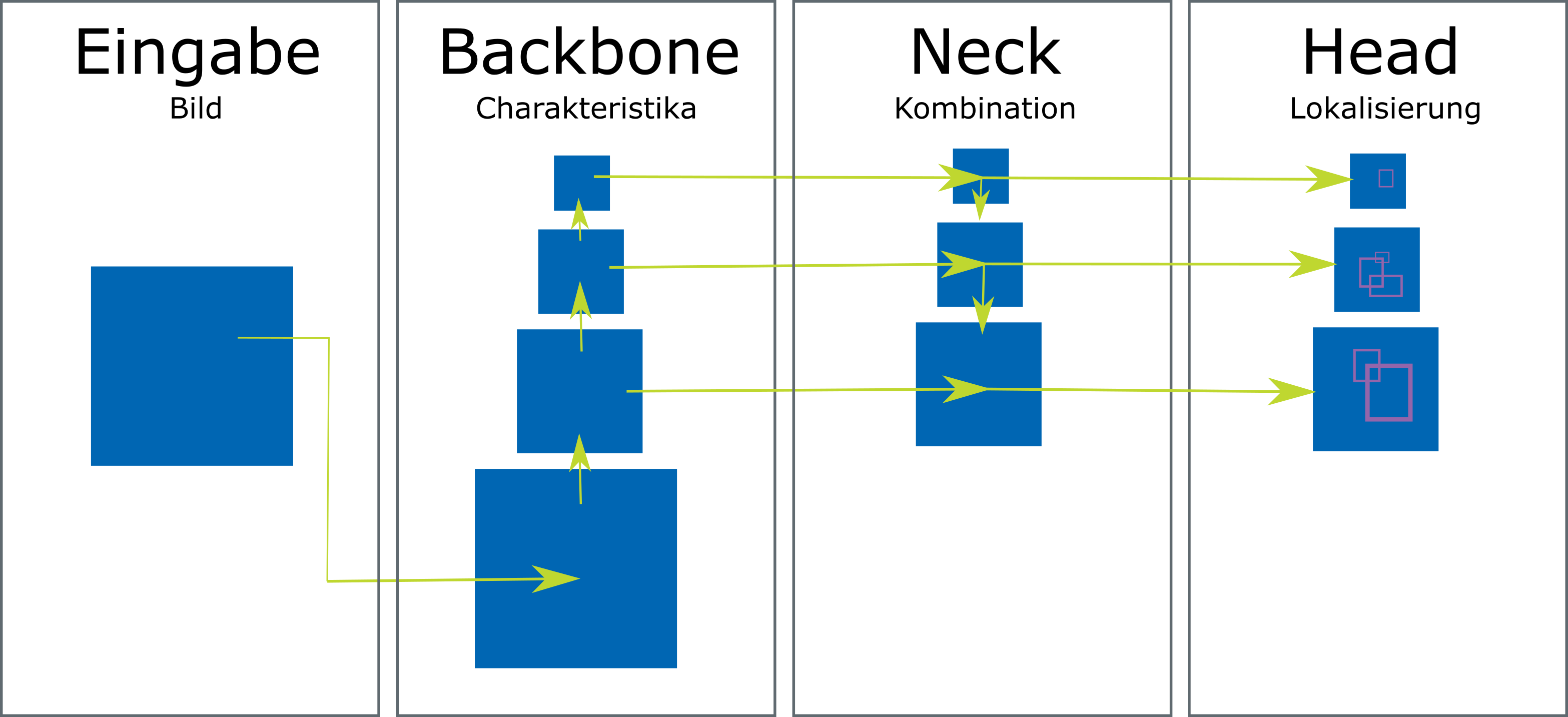
Abb. 2: Ablauf des YOLOv4-Algorithmus
Für den YOLO-Ansatz gibt es vortrainierte Neuronale Netze, die bereits eine Vielzahl von Objekten erkennen können. Ein oft verwendeter Datensatz ist Microsoft COCO (Co mmon Objects in Co ntext), welcher die Trainingsbasis für 80 verschiedene Objekte bietet. Unter anderem werden hier auch Bilder angeboten, bei denen die Objekte (Lastwagen, Motorrad und Auto) explizit markiert wurden (vgl. Abb. 3). Dieses Netz ist somit eine optimale Ausgangsbasis für unsere Anwendung, weil wir uns nicht um das weitere Training der Modelle kümmern müssen. Als finales Ergebnis liefert YOLOv4 für jedes Eingabebild eine Liste mit vermuteten Objekten. Diese Liste enthält neben den Objektnamen zusätzlich ihre Wahrscheinlichkeit als Indikator für die Sicherheit der Erkennung sowie den Objektbereich als Bounding Box (X- und Y-Position, Länge, Breite). Diese Liste ist nun die Ausgangsbasis für die entwickelte Anwendung, die im Folgenden skizziert wird.

Abb. 3: Testbilder aus COCO (entnommen aus https://cocodataset.org/#explore, vgl. [Lin14])
Die Anwendung
Ohne weitere Kontextinformationen repräsentieren die Ergebnisse aus der Objekterkennung nur Autos und deren Positionen in einem Videobild. Für eine Zuordnung zu Parkplätzen muss der Anwender innerhalb des Videobilds die Parkplätze markieren. Hierfür stellen wir eine Oberfläche bereit, bei der nacheinander vier beliebige Punkte gesetzt werden können, welche den Umriss des Parkplatzes definieren. Anschließend wird diese Information mit den Ergebnissen der Objekterkennung zusammengeführt.
Ein solches Ergebnis ist in Abbildung 4 zu sehen. In diesem Beispiel wurden zwei Parkplätze mit den Nummern 39 und 40 angelegt, die in der Mitte des Fotos mit einem orangenen Kasten visualisiert werden. Für jedes Auto gibt es eine Sicherheit der Erkennung (erster Eintrag in jeder Box auf der rechten Seite) sowie eine Überschneidung mit den konfigurierten Parkplätzen. In diesem Beispiel überschneidet sich die Fläche des weißen Autos zu 84,62 Prozent mit dem angelegten Parkplatz 39, deshalb wird dieser Parkplatz als belegt angenommen. Spannend zu sehen ist hier, dass das weiße Auto als Klasse LKW (truck, blaue Box) und als Klasse PKW (car, grüne Box) eingestuft wird, weil durch die Ansicht von oben eine gute Unterscheidung zwischen LKW und PKW nicht möglich ist.

Abb. 4: Screenshot aus der entwickelten Anwendung, welche die Überlagerung von Objektfläche und konfiguriertem Parkplatz zeigt
Der Aufbau unserer Anwendung ist in Abbildung 5 zu sehen. Sowohl die Aufzeichnung des Parkplatzes mit einer 4K Kamera (1) als auch die Auswertung der Bilder erfolgen auf einem mit Grafikkarte ausgestatteten Minicomputer (2) (Jetson Nano von NVIDIA, [Nvi20]). Dieser Computer hat mit 70 x 45 mm zwar nur Kreditkartenformat, bringt aber laut Hersteller eine Leistung von 472 GFLOPS und kann theoretisch mehrere Neuronale Netze parallel ausführen. Aufgrund der vielen Matrizenoperationen ist eine Grafikkarte essenziell für eine schnelle Berechnung von ML-Algorithmen. In unserer Anwendung werten wir das Eingabebild jede Minute neu aus, somit kommt der Jetson Nano nicht an seine Leistungsgrenze und böte das Potenzial für die Auswertung von weiteren Kamerabildern. Als Framework für YOLO verwenden wir eine Implementierung, die auf dem Open-Source-Framework Darknet [Red20] basiert. Dieses Framework ist in C und Cuda geschrieben und unterstützt GPU-Berechnungen. Die Ergebnisse der Objekterkennung werden anschließend über eine REST-Schnittstelle an das Backend (4) geschickt.
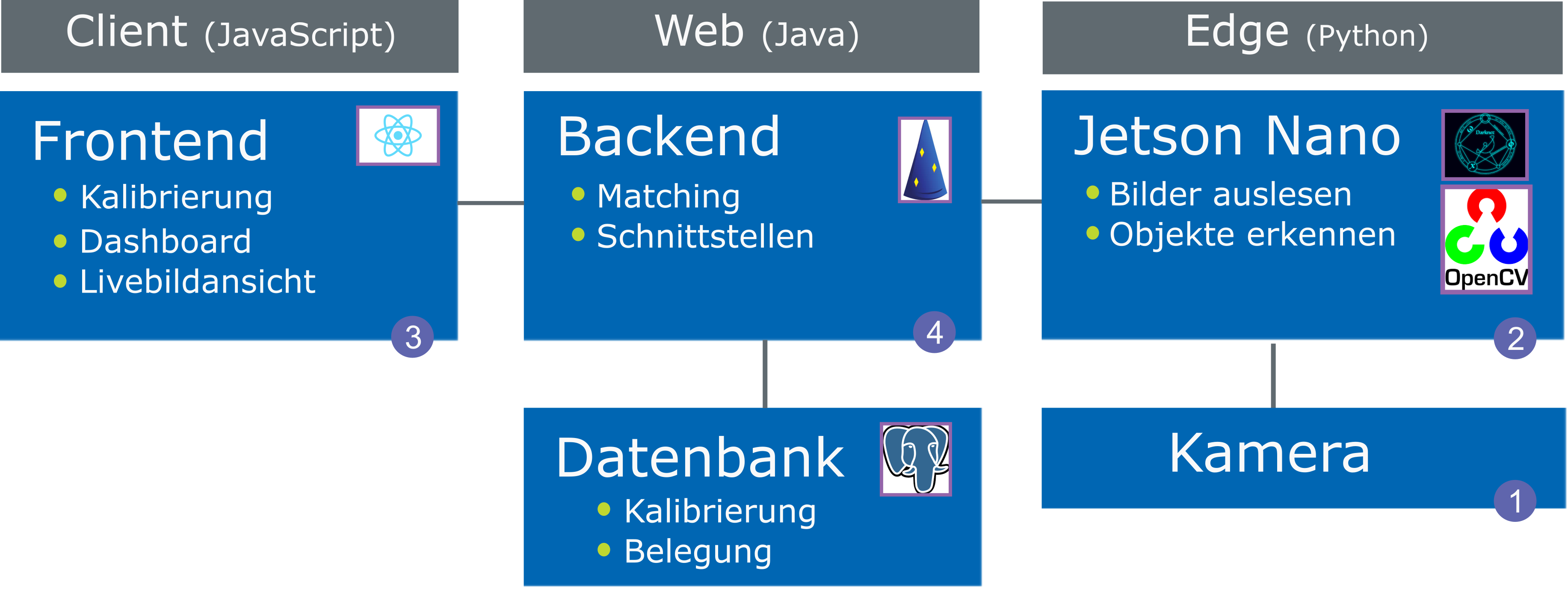
Abb. 5: Screenshot aus der entwickelten Anwendung, welche die Überlagerung von Objektfläche und konfiguriertem Parkplatz zeigt
Die zweite wichtige Information zum Ermitteln der Parkplatzbelegung wird im Frontend (3) durch die Markierung von Parkplätzen durch den Benutzer angegeben. Durch die Definition von vier Referenzpunkten ergibt sich ein Parkplatz. Die Fusion der zwei Objektbereiche mit den Parkplätzen erfolgt schließlich über ein Web-Backend (4), welches mit dem Java-Framework Dropwizard umgesetzt wurde. Zur Ermittlung der gemeinsamen Fläche des erkannten Objekts und des angelegten Parkplatzes verwenden wir die Java Topology Suite (JTS) [Loc20]. Die genaue Berechnung der prozentualen Überschneidung von Parkplatz und Objektfläche ist keine triviale Aufgabe, weil die markierten Parkplätze durch beliebige geometrische Trapeze repräsentiert werden können. Wie die Berechnung der Überschneidung im Code aussieht, zeigt Listing 1.
double parkingspaceArea = parkingspacePolygon.getArea() ;
try {
double intersectionArea = detectedObjectPolygon.
intersection(parkingspacePolygon).getArea() ;
return intersectionArea / parkingspaceArea ;
} catch (TopologyException e) {
// There is no intersection...
return 0.0 ;
}Basierend auf den bisher ermittelten Informationen haben wir zwei prozentuale Werte, auf deren Basis wir die Entscheidung treffen können, ob es sich tatsächlich um einen belegten Parkplatz handelt:
- die Sicherheit, mit der YOLOv4 berechnet, dass es sich um ein Auto handelt,
- die prozentuale Überschneidung der Flächen zwischen den konfigurierten Parkplätzen und den detektierten Autos.
Für beide Werte lassen sich nun im Frontend individuelle Schwellwerte einstellen. Somit erhält der Benutzer in der Anwendung einen gewissen Spielraum für die Empfindlichkeit der Erkennung.
Allgemein gilt: Je geringer die Schwellwerte angelegt sind, desto höher ist die Wahrscheinlichkeit, dass fälschlicherweise ein Parkplatz als belegt angenommen wird. Wenn der Schwellwert für die prozentuale Überschneidung zu niedrig gewählt ist, kann es passieren, dass ein schlecht geparktes Auto den angrenzenden Parkplatz mit als belegt markiert (Anm.: In unseren Testläufen ist dieser Fall jedoch nie aufgetreten). Interessant für die Konfiguration des Schwellwerts der YOLO-Sicherheit ist, dass jede Objektklasse eine einzelne Wahrscheinlichkeit besitzt. Wenn der Algorithmus nun nicht sicher zwischen zwei Klassen (LKW vs. PKW) unterscheiden kann, wie in Abbildung 4 geschehen, sinken die einzelnen Wahrscheinlichkeiten. Im obigen Beispiel beträgt die Erkennungswahrscheinlichkeit für das weiße Auto somit nur noch knapp 16 Prozent.
Herausforderungen
Bei der Inbetriebnahme dieses ML-basierten Ansatzes sind jedoch einige Punkte zu beachten, die im Folgenden diskutiert werden.
Datenschutz
Solange die aufgenommenen Bilder nicht gespeichert werden und den Jetson Nano nicht verlassen, ergeben sich wenige Probleme mit den Anforderungen des Datenschutzes. Durch den Einsatz einer Kamera, die einen großflächigen Bereich filmt, muss sichergestellt werden, dass Datenschutzrichtlinien eingehalten werden und zum Beispiel keine öffentlichen Bereiche gefilmt werden. Will man jedoch trotzdem die Bilder speichern (z. B. zum Nachvollziehen von Entscheidungen des Netzes), benötigt man eine (automatisierte) Unkenntlichmachung von personenbezogenen Daten. In diesem Kontext lässt sich zum Beispiel eine Erweiterung von YOLO nutzen [Mon18], um Kennzeichen zu erkennen und unscharf zu markieren. Doch auch dieses Netz kann keine absolute Erfolgsgarantie geben, sodass eine automatisierte Lösung nur unterstützend zu einer manuellen Kontrolle der Bilder verwendet werden kann.
In unserem Aufbau erfolgt der Zugriff auf den Edge-Computer über das Backend im internen Netzwerk der Anwendung. Sollte dies im Produktivsystem nicht möglich sein, ist eine sehr starke Absicherung des Jetson Nano gegen Hacking-Angriffe notwendig.
Single Point of Failure
Die Reduktion auf weniger Sensoren (eine Kamera anstatt mehrerer Bodensensoren) bedeutet auch, dass bei Ausfall der Kamera viel mehr Informationen wegfallen.
Wetterbeständigkeit
Nicht jeder Ort eignet sich zum Anbringen des Jetson Nanos und der angeschlossenen Kamera. Dieses Gerät ist nicht wettergeschützt, sodass dieser Punkt bei einer Inbetriebnahme separat betrachtet werden muss.
Mehrkamerasystem
Auch wenn eine Kamera ein sehr großes Gebiet an Stellplätzen abdecken kann, wird man für einen größeren Parkplatz nicht den Einsatz von mehreren Kameras vermeiden können.
Trotz alledem funktioniert die Erkennung sehr solide und auch bei großen Entfernungen und Teilverdeckungen (z. B. durch Bäume) noch verlässlich.
Fazit und Ausblick
„Herr Müller steckt sein Smartphone zurück in die Tasche. Er ist zufrieden, dass er jederzeit einsehen kann, welche Parkplätze zur Verfügung stehen, und ahnt nicht, dass ein hochkomplexes Neuronales Netz ihm einen guten Start in den Tag beschert hat.”
Methoden des maschinellen Lernens sind, in unseren Augen, eine wertvolle Bereicherung für das Themenfeld Smart City. Zusammen mit der Stadt Ulm, die als Modellprojekt „Smart City“ ausgewählt wurde, haben wir zusammen mit deren Abteilung Digitale Agenda und unserem Beteiligungsunternehmen citysens GmbH Projekte sowohl On-Street wie auch in Parkhäusern umgesetzt. Neben der Parkplatzbelegung könnten weitere Themen der Smart City (z. B. Verkehrsleitung und Stauvermeidung) vom Einsatz intelligenter Kameraauswertungen profitieren.
Doch nicht nur Autos lassen sich mit Neuronalen Netzen mit hoher Erkennungswahrscheinlichkeit und in Echtzeit detektieren. Auch Menschen können, trotz starker Verdeckungen, erkannt werden, was eine Zählung ermöglicht. Gerade in Zeiten von Covid-19 ist eine Algorithmen gestützte Auslastungsmessung von Besucherzahlen in Städten von enormer Bedeutung. Auch die Entwicklung der Algorithmen geht voran. Im Juni 2020, nur zwei Monate nach der Publikation von YOLOv4, wurde mit YOLOv5 eine inoffizielle Weiterentwicklung veröffentlicht, die behauptet, den bisherigen Stand der Technik in puncto Geschwindigkeit und Genauigkeit zu übertreffen. Wir sind überzeugt, dass das Thema Objekterkennung mit Machine Learning noch viele weitere, spannende Anwendungsfälle im Bereich der Smart City bieten wird.
Weitere Informationen
[Boc20]
A. Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao, YOLOv4: Optimal Speed and Accuracy of Object Detection, arXiv preprint arXiv:2004.10934 (2020), s. a. https://arxiv.org/pdf/2004.10934
[Lin14]
Tsung-Yi Lin et al., Microsoft COCO: Common Objects in Context, in: European conf. on computer vision, Springer, 2014, s. a. https://arxiv.org/pdf/1405.0312
[Loc20]
LocationTech, JTS Topology Suite, https://github.com/locationtech/jts
[Nvi20]
NVIDIA, Jetson Nano, https://www.nvidia.com/de-de/autonomous-machines/embedded-systems/jetson-nano/
[Mon18]
S. Montazzolli Silva, C. R. Jung, License Plate Detection and Recognition in Unconstrained Scenarios, in: Proc. of the European Conf. on Computer Vision (ECCV), 2018, s. a. https://openaccess.thecvf.com/content_ECCV_2018/papers/Sergio_Silva_License_Plate_Detection_ECCV_2018_paper.pdf
[Red20]
J. Redmon, Darknet: Open Source Neural Networks in C, https://pjreddie.com/darknet/









