

Nach Definition des IREB (International Requirements Engineering Board) [IRE20] sind die vier Hauptaufgaben des RE:
- Anforderungserhebung,
- Anforderungsdokumentation,
- Anforderungsprüfung und -abstimmung sowie
- Anforderungsverwaltung.
Diese Aufgaben fallen grundsätzlich auch bei der Entwicklung von KI-Systemen an, wobei KI-Systeme besondere Anforderungen an das RE stellen. Unter KI-Systemen verstehen wir Systeme, die KI-Komponenten beinhalten. Diese KI-Komponenten können sowohl auf Basis spezifizierter Algorithmen regelbasiert arbeiten als auch stochastische Elemente aufweisen, deren Verhalten erst durch maschinelles Lernen (ML) festgelegt wird. Wie jedes System steht auch ein KI-System in Wechselwirkung mit seiner Umgebung (siehe Abbildung 1). Die Wechselwirkung des zu entwickelnden Systems mit der Umgebung wird durch die Festlegung der Systemgrenze und die Abgrenzung des Systems gegen den Systemkontext greifbar.
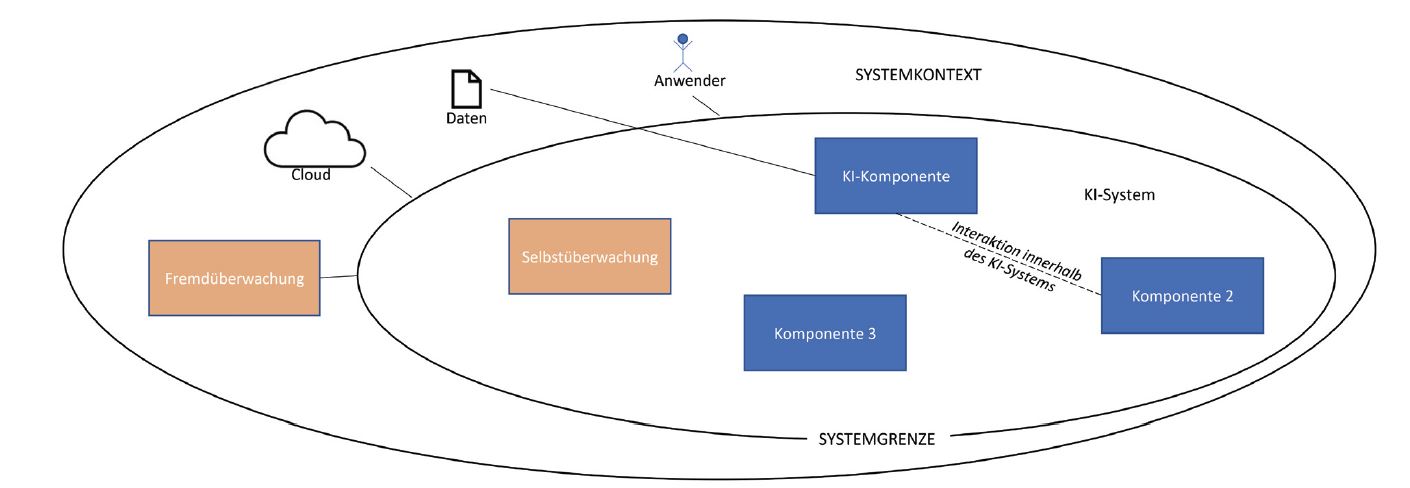
Abb. 1: KI-System, Systemgrenze und Systemkontext
Herausforderungen von KI-Systemen für das RE
Nach [Hey21] liegen die Herausforderungen von KI-Systemen mit stochastischen Elementen in der Definition des Systemverhaltens und der Sicherstellung der Systemqualität. Diese Erkenntnis führt zur Ableitung von vier Aufgabenbereichen im RE: Verstehen, Bestimmen und Spezifizieren von:
- kontextbezogenen Definitionen und Anforderungen,
- Datenattributen und -anforderungen,
- Leistungsdefinition und -überwachung und
- Auswirkungen menschlicher Faktoren auf Systemakzeptanz und Erfolg.
Ergänzt werden diese vier Aufgabenbereiche durch die Herausforderungen beim Verifizieren und Validieren von KI-Systemen [SEB21] (siehe Abbildung 2).
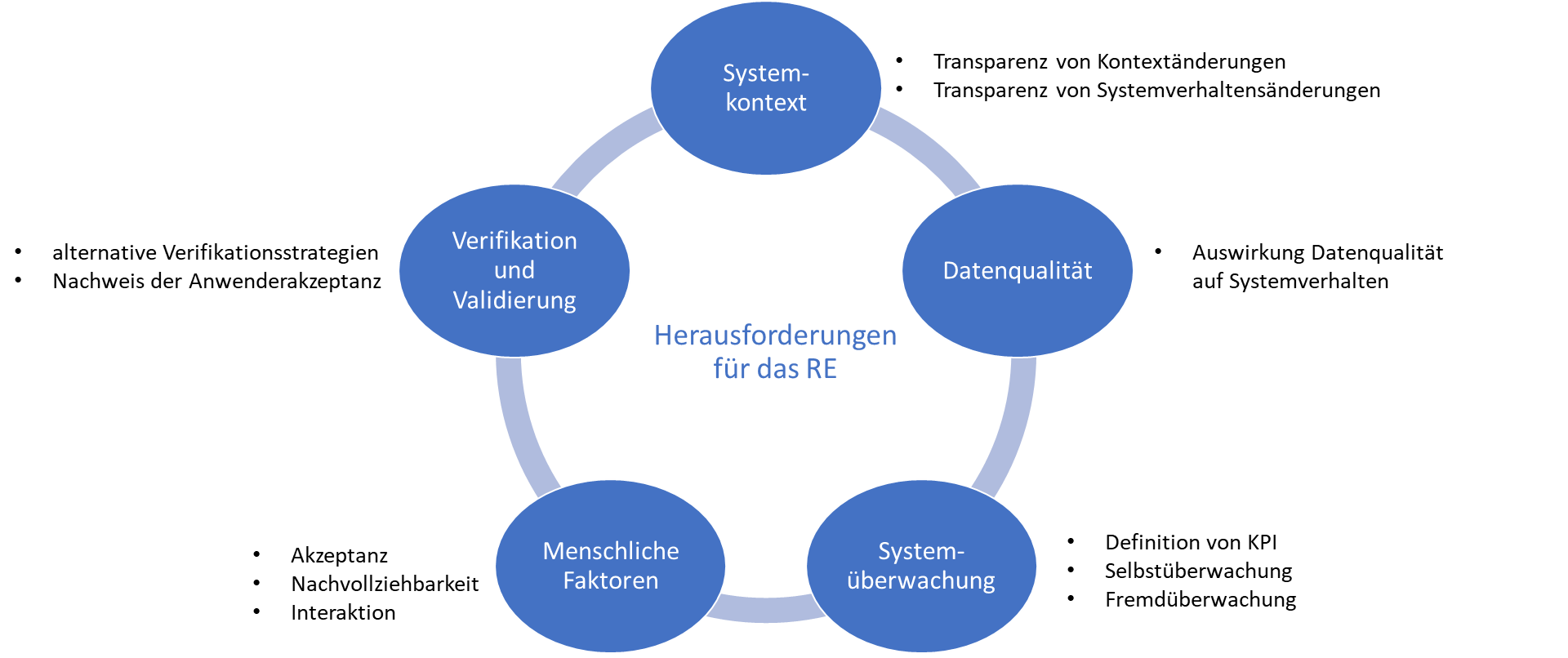
Abb. 2: Wechselwirkung der RE-Herausforderungen für KI-Systeme
Transparenz von Systemkontext und -verhalten
KI-Komponenten sollen mit anderen Systemkomponenten innerhalb des KI-Systems interagieren können. Erforderlich ist deshalb ein tiefes Verständnis der KI-Komponentengrenze und des KI-Komponentenkontexts im KI-System sowie der Einbettung und des Betriebs des KI-Systems in seiner Umgebung. Nur wenn der Kontext ausreichend verstanden ist, kann das erwünschte Systemverhalten erreicht und sichergestellt werden. (siehe auch Abbildung 1 zum Systemkontext) [Hey21] stellt fest, dass ein trainiertes KI-System nicht ohne Weiteres in einen anderen Kontext übertragen werden kann, ohne dass es erneut trainiert und validiert wird. Außerdem kann sich der Kontext über die Zeit verändern. Für das RE besteht deswegen eine der Herausforderungen darin, sowohl den Systemkontext als auch das Systemverhalten transparent zu gestalten. Dadurch können Anwender einschätzen, ob ein KI-System für ihre Bedürfnisse noch das erforderliche Verhalten aufweist. Und Entwickler können erkennen, inwieweit der reale Kontext vom geplanten abweicht, und gegebenenfalls Systemanpassungen vornehmen.
Auswirkung der Qualität der Daten für Training, Validierung und Betrieb auf die Funktion von KI-Systemen mit stochastischen Eigenschaften
Bei KI-Systemen mit stochastischen Eigenschaften wird das Systemverhalten mithilfe vorhandener Daten festgelegt. Beim Einsatz von ML werden diese Daten genutzt, um das Systemverhalten zu trainieren, das heißt sukzessive zu optimieren. Die genutzten Trainingsdaten bestimmen daher die Qualität des Systemverhaltens.
Die Erfahrung zeigt, dass der häufigste Grund für das Scheitern von KI-Projekten quantitativ oder qualitativ unzureichende Trainingsdaten sind und dass der Zeitund Kostenaufwand für das Beschaffen dieser Trainingsdaten sehr hoch sein kann. Transparenz über die Anforderungen an die Trainingsdaten hilft, zielgerichtet bei der Datengewinnung vorzugehen oder auch den Datengewinnungsaufwand durch Fokussierung auf wenige, besonders relevante Anforderungen zu reduzieren. Eine Herausforderung für das RE ist zunächst das Bestimmen der Informationsgrößen, die in den Trainingsdaten enthalten sein müssen. Diese Informationsgrößen können durch Analyse des Systemkontexts gefunden werden. Zudem muss das RE ermitteln, mit welcher Qualität die Systemfunktion gefordert ist. Dazu gehören Eigenschaften wie Genauigkeit, Aktualität und Rechtzeitigkeit, Korrektheit, Konsistenz, Benutzerfreundlichkeit, Sicherheit und Datenschutz, Zugänglichkeit, Skalierbarkeit und Unvoreingenommenheit [SEB21]. Mit diesen Informationsgrößen und Qualitätsanforderungen kann das RE spezifischere Anforderungen an die Trainingsdaten ableiten.
Anforderungen an die Überwachung des KI-Systems im laufenden Betrieb
Um Fehlentwicklungen während des laufenden Betriebs eines KI-Systems zu erkennen, müssen entsprechende Kenngrößen gemessen werden, sogenannte Key Performance Indicators (KPIs) [Hey21]. Dies ist vor allem bei selbstlernenden Systemen wichtig, da hier nicht nur der Systemkontext, sondern auch das Systemverhalten veränderlich ist. Die Messung der KPIs erfolgt im laufenden Betrieb entweder durch Selbstüberwachung oder durch Fremdüberwachung. Selbstüberwachung bezeichnet dabei die durch das System selbst übernommene kontinuierliche Validierung seines Verhaltens im Systemkontext. Im Gegensatz zur Selbstüberwachung findet die Fremdüberwachung nicht innerhalb der Systemgrenze, sondern im Systemkontext des KI-Systems statt. Die Fremdüberwachung kann zum Beispiel durch Cloud-Dienste erfolgen. Diese können Informationsquellen und zusätzliche Rechenkapazitäten nutzen, die für das KI-System nicht direkt verfügbar sind, um die KPIs für das KI-System und den Systemkontext zu messen (siehe auch Abbildung 1). Das RE hat darum die Aufgabe, KPIs zu identifizieren, geeignete Messmethoden zu spezifizieren und die Reaktion im Falle unerwünschten Systemverhaltens festzulegen.
Berücksichtigung menschlicher Faktoren im Design des KI-Systems
Die Berücksichtigung menschlicher Faktoren im Design ist eine Voraussetzung für die Akzeptanz des KI-Systems durch den Anwender. Dies beginnt bei der Ergonomie von erforderlicher Interaktion zwischen Anwender und KI-System und geht bis zur Nachvollziehbarkeit von KI-Entscheidungen durch den Anwender. Ein wesentlicher Faktor bei der Interaktion zwischen KI-System und Anwender ist das Niveau der KI-Unterstützung. Hier gibt es eine große Spannweite von leichter KI-Unterstützung wie Eingabeüberprüfungen, über automatisiert ablaufende Teilprozesse bis zu vollautomatisch autonomen Prozessen. Eine weitere Herausforderung in der Entwicklung des KI-Systems stellt die Gewinnung von Transparenz über die Charakteristik und Motivation des Anwenders dar. Dies ist für die Entwicklung besonders wichtig, weil nur so zielgerichtet KI-Lösungen ausgewählt werden können, die vom Anwender akzeptiert werden. Das RE hat in diesem Kontext die Aufgabe, mit Anwendern und Entwicklern gemeinsame Perspektiven auf den Systemkontext und das KI-System zu entwickeln und eine kontinuierliche Kommunikation zwischen den Beteiligten zu ermöglichen. Dadurch kann eine Systementwicklung für Anwender akzeptable KI-Systeme entwerfen. Die rechtzeitige Einbindung des Anwenders ist essenziell.
Verifikation und Validierung von KI-Systemen
Das System Engineering Body of Knowledge [SEB21] stellt fest, dass einige Aspekte der Verifikation und Validierung für konventionelle Systeme ohne Änderungen generell für KI-Systeme verwendet werden können. Allerdings wird ebenso erwähnt, dass bestimmte Merkmale von KI-Systemen für Verifikation und Validierung eine Herausforderung darstellen. Genannt werden dabei die folgenden Merkmale von KI-Systemen:
- Erosion des Determinismus,
- Unvorhersehbarkeit und Unerklärbarkeit der einzelnen Ergebnisse,
- unerwartetes, emergentes Verhalten und unbeabsichtigte Folgen von Algorithmen,
- komplexe Entscheidungsfindung der Algorithmen,
- Schwierigkeiten bei der Aufrechterhaltung der Konsistenz und Schwäche gegenüber geringfügigen Änderungen der Eingaben.
Die größten Herausforderungen bei der Verifikation und Validierung ergeben sich demzufolge vor allem dann, wenn KI-Systeme stochastische Komponenten enthalten. Die Verifikation von stochastischen KI-Systemen kann nicht mit den gleichen Mitteln erfolgen wie für konventionelle Systeme. Darum muss das RE bereits bei der Definition des Systemverhaltens alternative Verifikationsstrategien berücksichtigen und zum Beispiel Anforderungen an Testdaten und zulässige Ergebnistoleranzen spezifizieren. Hinsichtlich der Validierung von KI-Systemen ist außer dem üblichen Nachweis der Systemtauglichkeit für den beabsichtigen Einsatzzweck vor allem der Nachweis der Anwenderakzeptanz relevant. Das RE hat hier die Aufgabe, klar zu spezifizieren, wie Anwenderakzeptanz gemessen wird. Eine Besonderheit bei der Validierung von stochastischen KI-Systemen ist die Notwendigkeit der Validierung derjenigen Daten, die für Entwicklung oder Verifikation des Systems benutzt werden. Hierfür sind klare Anforderungen an Daten unerlässlich.
Prinzipieller Lösungsansatz des RE für KI-Systeme
Abbildung 3 zeigt die Vorgehensweise RE für KI-Systeme, die in progressivKI konzipiert worden ist.
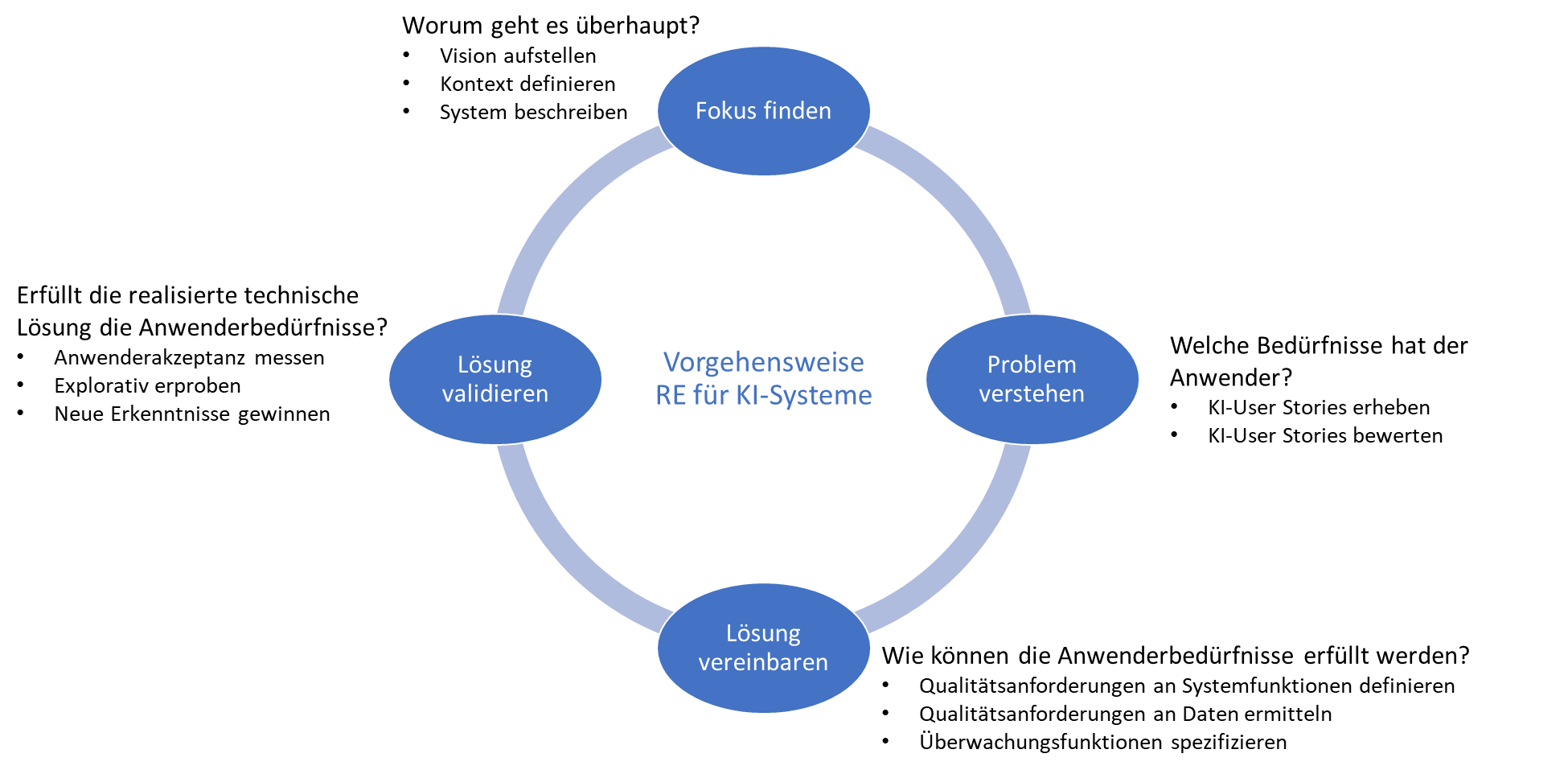
Abb. 3: Prinzipieller Lösungsansatz des RE für KI-Systeme
Fokus finden
Mit dieser Aktivität wird frühzeitig für Transparenz von Systemkontext und -verhalten unter den Entwicklungsbeteiligten gesorgt. Entwicklungsbeteiligte sind dabei Anwender, Fachexperten, KI-Experten, Entwickler und sonstige Stakeholder.
Vision aufstellen Ausgangspunkt ist eine Vision, die allen Beteiligten die Zielsetzung verdeutlicht. Diese sollte folgende Dinge benennen:
- Stakeholder, die den Hauptnutzen des Systems haben sollen, zum Beispiel spezifische Anwenderrollen,
- wichtigste Stakeholder-Bedürfnisse, die erfüllt werden sollen,
- wesentliche Systemmerkmale,
- Geschäftsmodell.
Das macht die gewählte Vision in sich konsistent. Es reicht allerdings nicht aus, um als gemeinsames Ziel in einer Entwicklung zu dienen. Dazu muss die Vision auch die Entwicklungsbeteiligten ansprechen. Dies lässt sich durch Einbinden der Stakeholder bei der Erarbeitung der Vision, den Einsatz spielerischer Kreativitätstechniken und regelmäßiges Werben für die Vision erreichen.
Kontext definieren und System beschreiben Neben der Vision sollte zusammen mit den Stakeholdern auf den Kontext eingegangen und das System beschrieben werden. Dadurch bekommen die Entwicklungsbeteiligten ein erstes gemeinsames Bild des Systems. Die Definition von Kontext und System kann beispielsweise durch gemeinsames Erarbeiten folgender RE-Artefakte erfolgen:
- System-Schnittstellenliste,
- System-Anwendungsfalldiagramm,
- Kontextdiagramm,
- Domänenmodell.
Für das Finden eines gemeinsamen Fokus ist die Erarbeitung von Details hier noch nicht erforderlich. Bei vielen Aspekten genügt zunächst eine Benennung, eine Definition kann später erfolgen. In progressivKI wurde diese Transparenz durch die Gesamtvorhabensbeschreibung [PKI2022] erreicht und der Betrachtungsrahmen auf die Entwicklung einer modularen KI-Plattform festgelegt.
Problem verstehen
Das RE muss mit dieser Aktivität frühzeitig Transparenz über menschliche Bedürfnisse erhalten, damit diese im Design des KI-Systems aufgegriffen werden können [Stö20].
KI-User-Stories erheben
Wir schlagen vor, zur Ermittlung von Bedürfnissen mit dem Format der User-Story zu starten. Denn diese hat den Vorteil, Motivation und Lösung naturgemäß zu separieren. Dieses Format zwingt die Beteiligten, bei der Erarbeitung nicht nur über die geforderte Lösung im Sinne einer KI-Unterstützung zu reden, sondern durch Nennung der Motivation automatisch auch den Anwendungskontext zu berücksichtigen (siehe Abbildung 4). Der eigentliche Nutzen der User-Story liegt nicht in ihrer Dokumentation, sondern vielmehr in der Kommunikation zwischen allen Beteiligten während ihrer Formulierung. Für KI-User-Stories muss an dieser Stelle besonders über folgende Aspekte gesprochen werden:

Abb. 4: KI-User-Story
- Nutzenkategorien, wie Sicherheit, Wirtschaftlichkeit, Innovation, Anwendungskomfort und Prestige,
- die erwünschte KI-Interaktionsstufe, von Stufe 1 (KI macht Vorschläge) über Stufe 2 (KI bearbeitet Aufgaben, Anwender gibt Resultate frei) bis Stufe 3 (KI arbeitet autonom), sowie
- technische Machbarkeit.
Diese Aspekte können als Akzeptanzkriterien für die KI-User-Stories notiert werden. In progressivKI reflektieren die KI-User-Stories die Erwartung der involvierten Parteien an die zu entwickelnde modulare KI-Plattform aus Sicht potenzieller Anwender dieser Plattform (siehe Abbildung 5).

Abb.5: Beispiel KI-User-Story in progressivKI
Diese Aspekte können als Akzeptanzkriterien für die KI-User-Stories notiert werden. In progressivKI reflektieren die KI-User-Stories die Erwartung der involvierten Parteien an die zu entwickelnde modulare KI-Plattform aus Sicht potenzieller Anwender dieser Plattform (siehe Abbildung 5).
- Verbesserungspotenzial: Ist KI-Lösung bezüglich Effizienz und Ergebnisqualität eine Verbesserung gegenüber der aktuell durchgeführten Praxis?
- Frequenz: Wird das Szenario häufig durchgeführt?
- ML-Relevanz: Kann das Szenario regelbasiert beziehungsweise mit klassischen Algorithmen nicht zufriedenstellend gelöst werden?
Die ersten zwei Fragen beantworten wir durch Angabe einer Ganzzahl von 0 bis 2, mit folgender Bedeutung: 0 – nein, 1 – indifferent, 2 – ja. Die ML-Relevanz wird nur durch Vergabe von 1 – nein und 2 – ja bewertet. Das KI-Potenzial berechnen wir abschließend, indem wir die drei Werte multiplizieren und dabei einen Wert zwischen 0 und 8 erhalten, wobei 8 das größte KI-Potenzial darstellt:
PotenzialKI = Verbesserungspotenzial ∙ Frequenz ∙ RelevanzML
Lösung vereinbaren
Das RE muss generell bei der Beschreibung der Lösung durch Ermitteln und Spezifizieren von Details mitwirken. Für KI-Lösungen muss es insbesondere Qualitätsanforderungen an Trainingsdaten und Systemfunktionen ermitteln und kommunizieren. Zudem muss RE KPIs identifizieren, geeignete Messmethoden spezifizieren und die Reaktion im Falle unerwünschten Systemverhaltens festlegen. Vor der Implementierung werden die genannten Details zwischen Entwicklung und Stakeholdern vereinbart und in Form von Akzeptanzkriterien der KI-User-Stories festgehalten.
Qualitätsanforderungen an Systemfunktionen definieren
Bei Qualitätsanforderungen an Systemfunktionen besteht die Schwierigkeit vor allem darin, dass Anwender sich schwertun, quantifizierte Anforderungen in ihren Anwendungskontext zu transferieren. Die Herausforderung für das RE ist es, mit den Stakeholdern valide Zahlen zu ermitteln. Zu diesem Zweck muss das RE den Stakeholdern vermitteln, was bestimmte Zahlen genau bedeuten. Was heißt es für den Anwender zum Beispiel, dass ein Ergebnis eine Genauigkeit von 98 Prozent hat? Wäre auch eine geringere Genauigkeit noch genau genug?
Eine Möglichkeit, dies für die Stakeholder greifbar zu machen, besteht in einer Form der erlebbaren Simulation. Dazu sind nicht unbedingt computergestützte Simulationen erforderlich. In vielen Fällen genügt es, Szenarien in einer Art Rollenspiel mit Anwendern durchzuspielen. Hierbei kann zum Beispiel ein Entwickler die Rolle des Systems übernehmen und dabei dem Anwender auch entsprechend ungenaue Ergebnisse liefern. Beide Seiten, sowohl Entwickler als auch Anwender, bekommen dadurch eine bessere Vorstellung von der jeweiligen Qualitätsanforderung.
Qualitätsanforderungen an Daten ermitteln Eine Herausforderung besteht darin, dass die Qualität der Trainingsdaten maßgeblichen Einfluss auf die Qualität des Systems und das Systemverhalten hat. Für das RE erfordert dies, zusammen mit den KI-Experten und Anwendern herauszufinden, welche Eigenschaften der Daten für die betrachtete KI-User-Story maßgeblich sind und wie die entsprechenden Informationsgrößen bestimmt werden können.
Die relevanten Informationsgrößen kann das RE aus der Systemfunktion ermitteln, denn nur Informationsgrößen, die für die Systemfunktion relevant sind, werden auch in den Daten benötigt. Allerdings kommen zusätzliche Qualitätseigenschaften hinzu, welche bei Durchsprache einer Datenqualitätscheckliste mit KI-Experten und Stakeholdern ermittelt werden. Wesentliche Qualitätseigenschaften von Daten sind zum Beispiel:
- Interpretierbarkeit,
- Nachvollziehbarkeit,
- Unvoreingenommenheit (Diskriminierungsfreiheit),
- Relevanz.
Überwachungsfunktionen spezifizieren
Das RE muss bei KI-Systemen KPIs für die System- und Kontextüberwachung identifizieren, geeignete Messmethoden spezifizieren und die Reaktion im Falle unerwünschten Systemverhaltens festlegen. Ziel ist eine Resilienz des KI-Systems auch bei sich ändernden Rahmenbedingungen. Dafür kann auf direkte Rückmeldung durch Anwender im operativen Betrieb zurückgegriffen werden. Ist dies nicht möglich oder nicht ausreichend, so müssen andere Messgrößen genutzt werden, um zu bestimmen, ob das gegenwärtige Verhalten des KI-Systems noch den Erwartungen entspricht.
Lösung validieren
Das RE muss festlegen, wie Anwenderakzeptanz gemessen wird. Dies erfolgt auf Basis der festgehaltenen Akzeptanzkriterien. Der Anwender kann durch explorative Erprobung ergänzendes qualitatives Feedback an die Entwicklung geben. Es ist vorteilhaft, die realisierte Lösung frühzeitig zu validieren, im Idealfall begleitend zur Entwicklung. Auf diese Weise können Erfahrungen aus der Validierung verwendet werden, um Anforderungen kontinuierlich zu priorisieren.
Ausblick
In diesem Artikel haben wir die Herausforderungen von KI-Systemen an das RE erläutert und aufgezeigt, wie ein Lösungsansatz dafür aussehen kann. Die weitere Konkretisierung des RE für KI-Lösungsansätze ist Gegenstand des Forschungsvorhabens progressivKI. ||
Weitere Informationen
[Hey21] H.-M. Heyn et. al., Requirement Engineering Challenges for AI-intense Systems Development, in: Contribution to the WAIN‘21 1st Workshop on AI Engineering during the 43rd International Conference on Software Engineering (ICSE21), siehe:
https://arxiv.org/abs/2103.10270
[IRE20] M. Glinz et.al., IREB Handbook for the CPRE Foundation Level according to the IREB Standard, Version 1.0.0, November 2020
[PKI20] Bundesministerium für Wirtschaft und Klimaschutz (BMWK), Verbundvorhaben progressivKI: „Unterstützung der Entwicklung von effizienten und sicheren Elektroniksystemen für zukünftige KFZ-Anwendungen mit automatisierten Fahrfunktionen mittels einer modular strukturierten KI-Plattform“, Förderkennziffer: 19A21006H, Laufzeit: 04/2021 - 03/2024, siehe:
https://www.edacentrum.de/projekte/progressivKI
[SEB21] Verification and Validation of Systems in Which AI is a Key Element (19 May 2021), System Engineering Body of Knowledges (SEBoK), siehe:
https://www.sebokwiki.org/w/index.php?title=Verification_and_Validation_of_Systems_in_Which_AI_is_a_Key_Element&oldid=65244
[Stö20] F. Stöckel, HOOD-Blog, Künstliche Intelligenz und Anforderungsmanagement, siehe:
https://blog.hood-group.com/blog/2020/10/29/kuenstliche-intelligenz-und-anforderungsmanagement/









