

Das Ziel eines jeden Softwareentwicklungsprojekts ist letztlich eine fehlerfreie Applikation. Arbeitet ein Team agil, setzt es auf kontinuierliches Testen. Die Vorteile dessen gegenüber dem Wasserfall-Modell beschreibt Cohn (vgl. [Coh10]) folgendermaßen: Wird erst im Nachgang getestet, lässt sich die Qualität des fertigen Produkts nur noch schwer verbessern. Unentdeckte Fehler wiederholen sich und werden erst nach Fertigstellung des Produkts sichtbar. Daraus noch während der Entwicklung zu lernen, ist unmöglich. Meist ist nur der Stand der Feature-Umsetzung bekannt, nicht aber der Projektstatus. Das macht es schwer, die Qualität der Umsetzung und gegebenenfalls den Aufwand für die Fehlerbeseitigung einzuschätzen. Ein weiterer Nachteil: Das Team kann nicht aus Feedback-Schleifen lernen. Und zu guter Letzt: In Projekten, die nach dem klassischen Wasserfall-Modell aufgebaut sind, fallen nachgelagerte Tests aus Zeitmangel unter Umständen einfach weg.
Cohns Ausführungen verdeutlichen die Sinnhaftigkeit kontinuierlichen Testens. Dabei ist die optimale Verteilung auf Modultests, Integrationstests und Systemtests entscheidend. Seine Testpyramide aus dem Jahr 2010 beschreibt dies anschaulich (siehe Abbildung 1). Demnach wird die Zahl der zu entwickelnden Tests nach oben immer geringer, während Komplexität, Ausführungsdauer und Kosten zunehmen.
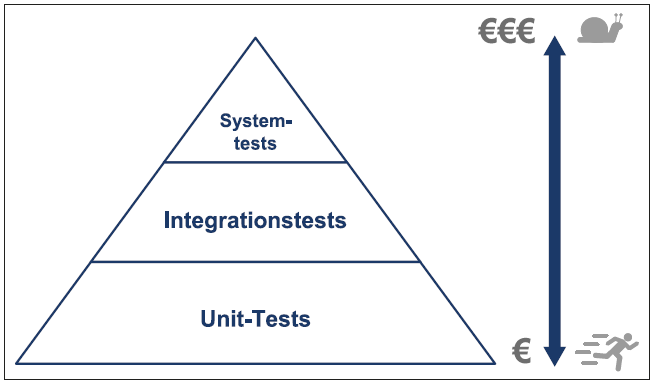
Abb. 1: Testpyramide nach Cohn [Coh10]
Testbarkeit
Die Testbarkeit von Code spielt also eine entscheidende Rolle bei der Entwicklung von Software. Aber was genau bedeutet Testbarkeit in diesem Zusammenhang? Neben der Definition und Forderung von Funktionen ist auch der Qualitätsanspruch an die Software gestiegen. Daher ist es wichtig, effizient zu testen. Neben Designprinzipien ist der Test zu einer weiteren großen Anspruchsgruppe in der Softwareentwicklung herangereift. Soll die Testbarkeit gewährleistet sein, muss der Code so implementiert sein, dass sich die fachlichen Funktionen überprüfen lassen.
Es geht also um die Möglichkeit, grundsätzlich testen zu können. Dass dies nicht immer gegeben ist, zeigen Äußerungen mancher Entwickler wie: „Das kann ich gar nicht testen“. Ein möglicher Grund dafür ist, dass zu testende Funktionen, soweit sie eng mit anderen Funktionen gekoppelt sind, nicht isoliert aufgerufen werden können. Sie müssten deshalb in Kombination ablaufen, wodurch die Komplexität und der Aufwand des Tests schnell steigen würden. „Nicht testbar“ heißt dann letztendlich auch, dass die Funktion nicht mit vertretbarem Aufwand testbar ist.
Muster und Prinzipien für ein gutes Testdesign
Vor diesem Hintergrund werden im Folgenden Entwurfsmuster und Designprinzipien vorgestellt, die eine gute Testbarkeit ermöglichen. In Abbildung 2 sind die verschiedenen Muster und Prinzipien und ihr Einfluss auf die Teststufen (Modul-, Integrations- und Systemtest) dargestellt.
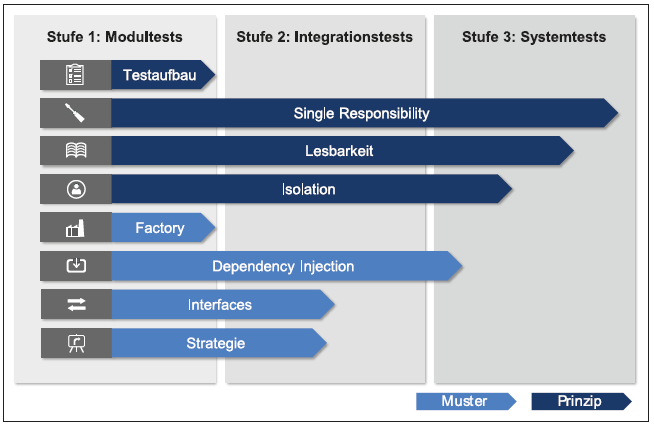
Abb. 2: Acht Muster und Prinzipien für ein gutes Testdesign
Single Responsibility
Ein wichtiges Prinzip in der Softwareentwicklung ist, die Komplexität durch Modularisierung beherrschbar zu machen. Bereits 1972 hat David Parnas den Ansatz des „Information Hiding“ beschrieben (vgl. [Par72]). Hierbei wird eine Problemstellung in Module mit abgrenzbarem Funktionsumfang zerlegt. Implementierungsdetails bleiben dem Nutzer des Moduls verborgen, da es nur über seine Schnittstellen angesprochen wird. Doch wie lässt sich der Funktionsumfang sinnvoll in Module aufteilen? Was gehört in ein Modul und was nicht? Welche Größe sollte ein Modul haben?
Etabliert hat sich hierfür das Vorgehen nach dem Single-Responsibility-Prinzip (vgl. [Mar18]). Die Idee hinter Single Responsibility (SRP) ist einfach: Jedes Modul hat eine klare Verantwortlichkeit und genau einen Grund zur Änderung. Erreicht wird dies dadurch, dass ein Modul nur genau einen Nutzer (Akteur) hat (vgl. [Mar18]):
„A module should be responsible to one, and only one, actor.“
Somit stellt das SRP ein wichtiges Prinzip für effizientes Testen dar. Nur durch kleine Module mit klarer Aufgabe und wenigen Abhängigkeiten (und Akteuren) lässt sich wartbarer und erweiterbarer Test-Code erstellen. Das SRP gilt hierbei auch für die Tests: Ein Test sollte für die Absicherung eines einzelnen Verhaltens zuständig sein. Darüber hinaus unterstützt eine Architektur auf Basis vieler kleiner Module mit klarer Verantwortung die effiziente Verteilung gemäß der Testpyramide. Außerdem fördert das SRP die Verständlichkeit und Nachvollziehbarkeit des Codes und sorgt somit für eine gute Lesbarkeit.
Lesbarkeit von Tests
Etwa 80 bis 90 Prozent der anfallenden Arbeit in der Softwareentwicklung besteht aus dem Lesen von Code – und nur 10 bis 20 Prozent aus dem Schreiben. Für eine effektive Softwareentwicklung ist gut lesbarer Code somit ein entscheidender Aspekt. Martin Fowler schreibt hierzu [Fow99]:
“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.”
Verschiedene Maßnahmen unterstützen dabei, den Code hinsichtlich Verständlichkeit und Nachvollziehbarkeit zu verbessern. So sollte beispielsweise die zyklomatische Komplexität, also die Verschachtelungstiefe von Verzweigungen und Schleifen im Code, möglichst gering gehalten werden. Guter Code hat deshalb maximal einen Wert von 3. Auch das KISS-Prinzip ist hier eine gute Leitlinie: „Keep it simple, stupid“. Es ist erfüllt, wenn Entwickler eine möglichst einfache Lösung für ein Problem verwenden und dabei nur das implementieren, was explizit in der Anforderung steht. Dabei sollten sie Verallgemeinerungen und generischen Code vermeiden.
Auch sprechende, aussagekräftige Namen für Module, Klassen, Methoden und Variablen tragen zur Verständlichkeit bei. Das SRP verbessert die Lesbarkeit, da Methoden und Klassen eine eindeutige Aufgabe haben. Von Vorteil ist es, wenn das Team gemeinsam eine einheitliche Namenskonvention festlegt. Eine Möglichkeit ist es, sich an dem System nach Osherove (vgl. [Osh15]) zu orientieren. Demnach besteht der Testname immer aus den folgenden drei Elementen:
- Name der zu testenden Methode,
- Szenario, in dem getestet wird, und
- zu erwartendes Verhalten.
Die Verwendung einer einheitlichen Teststruktur verbessert ebenfalls die Lesbarkeit der Tests. Ein Beispiel ist die AAA-Regel. Sie besagt, dass ein Test immer aus den Schritten Arrange, Act und Assert bestehen muss (vgl. [Osh15]). Eine weitere Maßnahme zur Optimierung der Verständlichkeit ist das Auslagern wiederkehrender Initialisierungen in separate Methoden, wobei Modultest-Frameworks diese zur Verfügung stellen. Nicht zuletzt sollten Entwickler auskommentierte Codeblöcke im Test- und Produktivcode vermeiden.
Testaufbau
Um einen Test zu gestalten, sollte zunächst der „Code Under Test“ – kurz CUT – abgegrenzt werden. Roy Osherove schreibt [Osh15]:
„… manche Leute verwenden auch den Begriff CUT (‚Class Under Test‘ oder ‚Code Under Test‘).“
Im Modultest schreiben die Entwickler feingranulare, atomare Tests. Diese sollen eine bestimmte Funktionalität singulär ausführen und disjunkt von anderen Funktionalitäten ablaufen lassen. Daher ist es wichtig, sich zunächst darüber klar zu werden, was hier der Code Under Test ist. Welche Teile der Software zählen also explizit nicht dazu und somit zu einem anderen CUT, und welche bilden einen eigenen CUT? An dieser Stelle zeigt sich, wie testbar eine Software ist. Etwa wenn sich herausstellt, dass der eigentliche CUT nicht isoliert gerufen werden kann. Gegebenenfalls bedingt er auch weitere Softwareteile, sodass sich unfreiwillig ein größerer CUT ergibt, als zunächst für den Test vorgesehen. Damit steigt der Aufwand für die Modultests, da mehr Eingangsdaten berücksichtigt werden müssen. Der Code wird in der Regel durch die in Abbildung 3 gezeigten Schritte getestet.
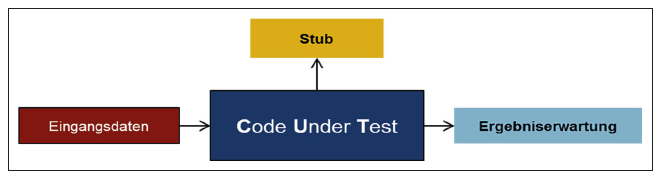
Abb. 3: Aufbau der Tests: CUT (Code Under Test)
Tests, die nach diesem Muster aufgebaut sind, haben folgende Vorteile:
- Sie lassen sich durch Eingabedaten parametrisieren.
- Schwierig erreichbare Codestellen können durch konfigurierbare Stubs durchlaufen werden.
- Es gibt einen dedizierten Soll-Ist-Abgleich. Damit wird implizit sichergestellt, dass messbare Ergebniserwartungen definiert werden.
Für die höheren Teststufen nach dem Modultest bietet dieses Muster dieselben Vorteile, nur wird die Anzahl der benötigten Daten mehr. Die Stubs sind weniger modulintern, sondern beziehen sich auf echte Systemschnittstellen. Somit kann das Softwaresystem „under test“ gelegt und angeschlossene Systeme können abstrahiert werden. Hier spricht man zum Teil auch von einer Service-Virtualisierung, sodass auch Drittanbietertools durch Stubs ersetzt werden können. Das kann immense Vorteile bieten, da nicht immer sichergestellt ist, dass sich Drittanbieter auch in die eigene Systemarchitektur sowie Verfügbarkeitszeiten und Releasezyklen integrieren. Dieses Muster versetzt die Entwickler folglich in die Lage, jederzeit zu testen – losgelöst von eventuellen Abhängigkeiten.
Insbesondere beim Stub besteht dabei allerdings häufig die Gefahr, dass Geschäftslogik nachgebaut wird. So kann schnell redundantes Coding entstehen. Im Idealfall liefert der Stub also ausschließlich Daten und implementiert keine Logik. Dazu schreibt Roy Osherove [Osh15]:
„Die Chancen auf Bugs in Ihren Tests wachsen fast exponentiell, wenn Sie mehr und mehr Logik darin einbauen.“
Benötigt man zur Testdurchführung allerdings viele Stubs, ist das sicherlich auch ein Anzeichen dafür, dass das Single-Responsibility-Prinzip (s. o.) nicht richtig angewendet wurde. Der Aufwand für die Erstellung der Stubs ist dann sehr hoch.
Isolation
Modultests entfalten ihr volles Potenzial, wenn das Testen der Module isoliert erfolgt, also mit möglichst wenigen Abhängigkeiten zu anderen Modulen. Die Tests lassen sich so relativ leicht pflegen und anpassen. Bestehen jedoch hohe Abhängigkeiten, muss bei jeder Änderung eines Moduls auch eine Vielzahl an Modultests überarbeitet werden. Zum isolierten Testen werden sogenannte Mock-Objekte verwendet, die das Verhalten von Modulen simulieren. Diese Nachbildung des echten Objekts gibt die nach außen hin sichtbaren Schnittstellen vor. Auf das Implementieren der internen Business-Logik wird für gewöhnlich verzichtet. Es reicht in der Regel aus, eine konstante Rückgabe für eine Schnittstelle zu realisieren. Abhängig vom Aufwand der Logik zur Simulation des Objektverhaltens spricht man von Mock, Fake, Stub oder Dummy (vgl. [Osh15]).
Auch Module, die nicht-deterministische Ergebnisse wie etwa die Uhrzeit liefern, bieten sich für Mocking an. Weitere Einsatzszenarien sind Module, die eine aufwendige Initialisierung voraussetzen, wie beispielsweise die Dateiablage in der Cloud oder Datenbanken, oder aber, wenn schwer reproduzierbares Verhalten getestet werden soll. Das kann etwa ein Fehler bei der Dateierstellung oder ein Übertragungsfehler im Netzwerk sein. Mocking kommt aber nicht nur für Modul-, sondern auch für Integrations- oder Systemtests in Frage. Mocks können in diesem Fall beispielsweise das Verhalten externer Anbieter nachbilden. Das macht isoliertes Testen möglich. Ein Vorteil, denn oft ist es schwer, Einfluss auf Parameter externer Anbieter wie Verfügbarkeitszeiten, die Datenqualität oder die Existenz einer Testumgebung zu nehmen. Auf Modul-Ebene lassen sich Mock-Objekte mithilfe von verschiedenen Software-Frameworks erstellen. Beispiele hierfür sind unittest.mock, Mockito oder Power Mock. Die Mock-Objekte erzeugt das Framework für gewöhnlich automatisch auf Basis der Schnittstellen der zu ersetzenden Module. Dabei implementieren die Entwickler das Verhalten der Schnittstellen innerhalb des Modul-Tests. Somit ist es in der Regel nicht notwendig, Mocks per Hand anzulegen, was die Arbeit erheblich erleichtert.
Das Mocking ermöglicht jedoch nur, einen Teil der Tests isoliert durchzuführen. Deshalb ist es essenziell, bereits vor der Auslieferung der Software einen vollständigen End-to-end-Test inklusive aller externen Services vorzunehmen.
Factory (Lookup)
Grundsätzlich gibt es mehrere Möglichkeiten, Instanzen von Klassen zu erzeugen. Der Aufruf eines Konstruktors ist einfach und kann jederzeit erfolgen. Sollte er jedoch nicht, denn die Instanziierung kann eine sensible Angelegenheit werden, wenn die Instanz zunächst initialisiert werden muss, um sie nutzen zu können. Daher muss sichergestellt werden, dass
- Instanzen gleichartig erzeugt werden können. Am besten mit denselben Übergabeparametern, im einfachsten Fall nur mit einer ID zur Identifizierung des Objekts.
- die Initialisierung getrennt von der Instanziierung abläuft. Möglich wäre hier, eine initialize()-Methode anzulegen und diese nach der Instanziierung aufzurufen.
In jedem Fall sollte das höchste Ziel sein, nicht „wild“ zu instanziieren, sondern an geeigneter Stelle. Eine mögliche Lösung ist, im System eine Factory zur Verfügung zu stellen und alle Instanziierungen von dort erfolgen zu lassen. So muss an jeder Stelle im Code, wo eine Instanz benötigt wird, auf die Factory verwiesen werden. In einer weiteren Ausbaustufe kann die Factory zu einem Lookup gewandelt werden. Dieser nimmt die Instanziierung vor und prüft, ob gegen ein Interface typisiert wurde und welche Klasse in diesem Kontext das Interface implementiert. Das zwingt Entwickler zu einer sauberen Interfaceverwendung. Für den Test nimmt der Lookup eine Art Schlüsselrolle auf allen Teststufen ein (siehe Abbildung 4). Er ermöglicht, dass Instanzen leicht ausgetauscht werden können. Das kann ausgehende Abhängigkeiten, aber auch ganze Systemschnittstellen betreffen.
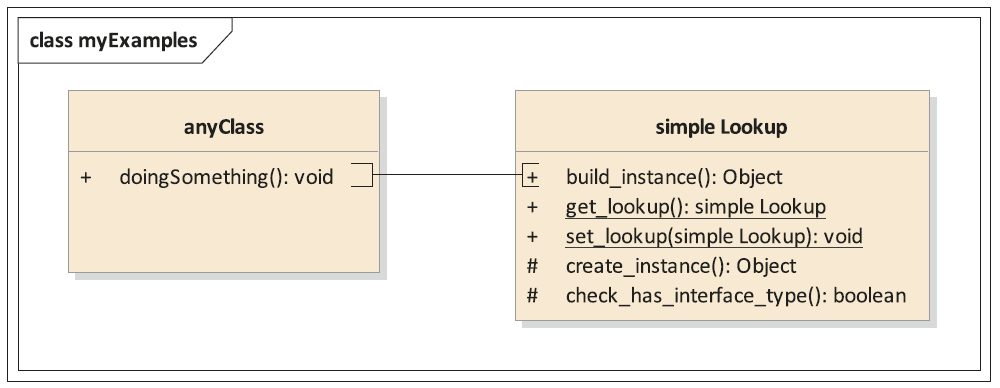
Abb. 4: Ein einfacher Lookup zur Instanzverwaltung
Dependency Injection
Mit der Factory geht die sogenannte „Dependency Injection“ einher. Dabei geht es um die Art und Weise, wie abhängige Objekte an andere Objekte übergeben werden, die diese für ihre Verarbeitungslogik benötigen. Verwendet man eine Factory, werden die Instanzen zwar zentral erzeugt, aber dennoch von Objekten selbst initiiert. Das lässt sich auflösen, indem die Abhängigkeiten durch einen sogenannten Assembler ermittelt und übergeben werden. Martin Fowler beschreibt dazu drei Verfahren (vgl. [Fow04]):
- Constructor Injection,
- Interface Injection und
- Setter Injection.
Favorit sollte die Interface Injection sein (siehe Abbildung 5).
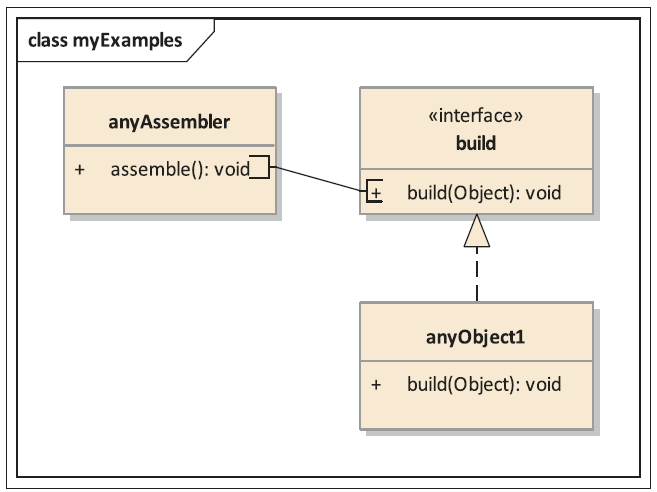
Abb. 5: Interface Injection und Assembler
Der Assembler baut hierbei eine konkrete Instanz, idealerweise unter Zuhilfenahme einer Factory, und ruft danach die build()-Methode des gleichnamigen Interface der Instanz auf. So werden alle Instanzen gleichartig aufgebaut. Einzig die verwendeten Objekte unterscheiden sich. Diese muss der Assembler ebenfalls über die Factory ermitteln. Benötigt man mehrere abhängige Objekte, wie im anyObject1 aus Abbildung 5, lässt sich die Methode zum einen mehrfach aufrufen. Zum anderen können die Entwickler etwas eleganter eine Art Sammelobjekt darüber schalten, auf dem alle benötigten Instanzen zunächst gesammelt und dann durch nur einen Aufruf an anyObject1 übergeben werden.
Die Vorteile bei dieser Lösung sind zum einen, dass über eine definierte Schnittstelle kommuniziert wird (s. u.) und dass zum anderen die Verantwortung für die Injection im Sinne des Single-Responsibility-Prinzips beim Assembler liegt. Im Test kann der Assembler durch einen Test-Assembler ersetzt werden, der Mocks injiziert. Dadurch ist sichergestellt, dass der Code Under Test präzise abgegrenzt werden kann. Dieser kann sogar beliebig groß werden, weil der Entwickler gezielt entscheidet, welche Instanzen Mocks und welche die echten Instanzen sein sollen. Das macht dieses Prinzip bis in die hohen Teststufen sehr wertvoll.
Verwendung von Interfaces
Die Verwendung von Interfaces im Sinne der Objektorientierung hat bei stark typisierten Programmiersprachen viele Vorteile:
- Öffentliche Methoden sind von Inter- faces abgeleitet: Das stellt sicher, dass keine enge Kopplung zu konkreten Klassen aufgebaut werden muss. Alle Klassen, die ein Interface implementieren, sind untereinander austauschbar.
- Referenzvariablen sind immer auf In- terfaces typisiert: Auch nachdem eine Instanz über ein Interface bezogen wurde, behält sie ihre Typisierung und wird nicht konkret gecastet. Ansonsten wäre der Aufbau einer engen Kopplung die Folge.
- Jede Klasse implementiert mindestens ein Interface: Die Klassen hätten andernfalls analog zu den anderen Festlegungen keine Daseinsberechtigung.
- Tests werden für öffentliche Methoden von Interfaces geschrieben: Wenn es die Aufteilung eines CUTs erfordert, wirken notwendige Tests auf protected Methoden von Klassen ergänzend. So lassen sich die Tests für Klassen eines Interface wiederverwenden und orientieren sich an den Anforderungen.
In schwach typisierten Programmiersprachen besteht nicht die Notwendigkeit, Interfaces einzusetzen, jedoch kann die Lesbarkeit und Verständlichkeit des Codes auch hierbei mit Interfaces erhöht werden.
Strategie
Das Strategie-Pattern (siehe Abbildung 6) wird häufig in Software verbaut.
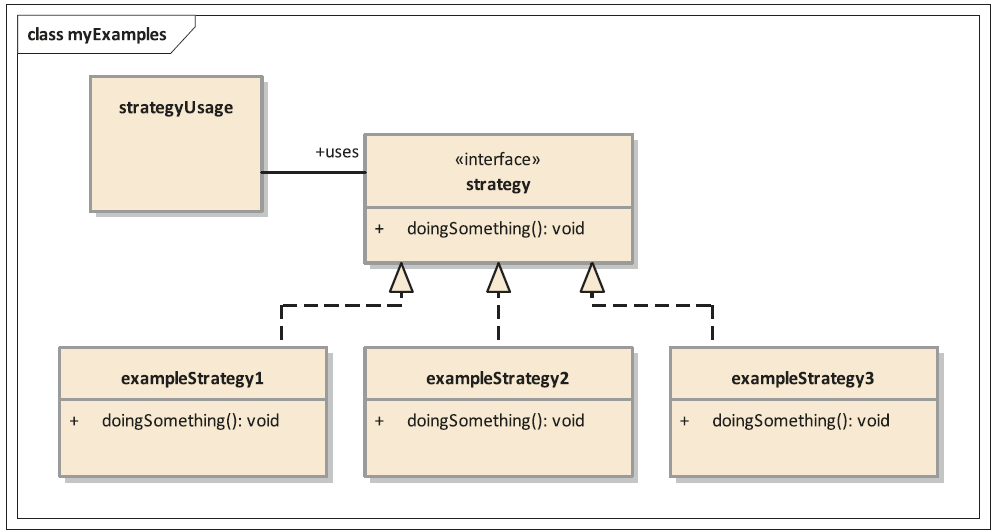
Abb. 6: Schematische Darstellung eines Strategie-Musters
Exemplarische Anwendungen sind Validierungen und Berechnungen. Dabei hilft das Entwurfsmuster, alle einzelnen Bausteine zu erkennen und zu sortieren. Dadurch erhält man viele kleine Klassen, die einen bestimmten Teilbereich abdecken – beispielsweise eine Validierung, ob ein String ein Datum oder eine Uhrzeit enthält.
Das Entwurfsmuster trägt dazu bei, dass alle Klassen gleich aufgebaut und von vergleichsweise geringer Komplexität sind. Die Methoden enthalten wenig Coding. Alle Klassen sind vergleichbar und können auf dieselbe Weise getestet werden. Die Teststrukturen sind hochgradig wiederverwendbar. Die Tests sind klein und deren Umfang kalkulierbar. Sie ergeben sich direkt aus den fachlichen und technischen Anforderungen an eine Strategie. Um die Gesamtfunktionalität zu erhalten, werden sie zusammenverschaltet und laufen in einer bestimmten Reihenfolge ab. So können auch höhere Teststufen von der Komplexitätsreduzierung profitieren, da meist nur ein Datensatz für eine Strategie übergeben werden muss und disjunkt anderer Strategien getestet werden können. Die Strategien, die nicht relevant sind, schlagen auch nicht an.
Fazit
Wie so oft ist es zunächst schwierig, die Ideen zu transportieren und als Mindset in den Entwicklungsteams zu verankern. Denn an manchen Stellen, wie etwa bei der Festlegung, Instanzen zentral über eine Factory zu beziehen, schränken Entwurfsmuster die Freiheit ein, Instanzen wahlfrei zu erzeugen und zu nutzen. Das geht zugunsten der genannten Ziele, daher ist die Einschränkung legitim. Dennoch kann jede Einschränkung für Unmut im Entwicklungsteam sorgen. Schulungen und Workshops wirken dem entgegen und bauen ein Mindset auf, das für alle Teammitglieder funktioniert.
Die genannten Patterns und Prinzipien sind deshalb immer aus Sicht der Testbarkeit zu sehen. Für Softwarearchitektur und Softwaredesign gelten sicherlich noch einige weitere.
Gut designt ist halb gewonnen – ein gutes Softwaredesign unterstützt sowohl eine hohe Softwarequalität als auch die Testbarkeit. Und das gilt nicht nur in der untersten Teststufe des Modultests, sondern hat weit darüber hinaus Auswirkungen. Verfolgt man die Ziele, sowohl ein testbares System zu bauen als auch die Komplexität des Systems und damit der Tests gering zu halten, zahlt es sich aus, die beschriebenen Designprinzipien einzusetzen.
Weitere Informationen
[Coh10] M. Cohn, Succeeding with Agile: Software Development Using Scrum, Addison-Wesley Professional, 2009
[Fow99] M. Fowler u. a., Refactoring: Improving the Design of Existing Code, Addison-Wesley, 1999
[Fow04] M. Fowler, Inversion of Control Containers and the Dependency Injection pattern, 2004, siehe:
https://martinfowler.com/articles/injection.html
[Mar18] R. C. Martin, Clean Architecture - A Craftsmans Guide to Software Structure and Design, Prentice Hall, 2018
[Osh15] R. Osherove, The Art of Unit Testing, 2. Auflage, mitp Professional, 2015
[Par72] D. L. Parnas, On the Criteria To Be Used in Decomposing Systems into Modules, in: Com. of the ACM 15 (1972), Nr. 12









