

Hinzu kommen weitere Punkte wie Testverfahren, welche die Funktionalität eines ML-Modells im Betrieb nicht abschließend bestätigen können, und Mitarbeitende, deren professioneller Hintergrund häufig stark mathematisch geprägt ist und die nun mit ganz eigenen Tools und Vorgehensweisen in die Entwicklerteams eingebunden werden müssen.
Diese neue Komplexität macht es notwendig, neue Herangehensweisen, Arbeitsprozesse, Rollenbeschreibungen und Tools zu entwickeln. Der Prozessansatz MLOps greift etablierte Prozesse aus der Softwareentwicklung auf und erweitert sie hinsichtlich Design, Entwicklung, Integration und Betrieb von ML-Lösungen.
MLOps – ein Überblick
MLOps (Machine Learning Operations) wird als Erweiterung von DevOps (Development and Operations) verstanden. Das Ziel von DevOps ist es, den Entwicklungszyklus von Software zu verkürzen und qualitativ hochwertige Softwareartefakte schnell in die Produktion zu bringen. Dabei ist ein Team sowohl für die Entwicklung als auch für den Betrieb eines Produkts verantwortlich. Arbeitsabläufe und Verfahren werden so weit als möglich automatisiert. Ausgehend vom DevOps-Zyklus integriert der MLOps-Ansatz die Arbeitsphasen von ML-Projekten, so wie sie im grundlegenden CRISP-DM-Modell (CRoss Industry Standard Process for Data Mining) systematisiert wurden.
Das ist sachgerecht. Zum einen aus konstruktiver Sicht: Im Dev-Ops-Ansatz sind die erfolgreichen Software-Engineering-Konzepte der letzten Jahrzehnte enthalten: Modularisierung, Versionierung, Test-gesicherte Konstruktion, Continuous Integration, Continuous Delivery und permanente Qualitätssicherung. Automatisierung sorgt für Verlässlichkeit, Nachvollziehbarkeit, Wiederverwendbarkeit und Effektivierung von Arbeitsabläufen. Zum Zweiten aus organisatorischer Sicht: Der DevOps-Ansatz legt Wert auf enge Zusammenarbeit von Nutzern und Entwicklern, auf agile Arbeitsweisen und gemeinsame Verantwortung für Entwicklung und Betrieb eines Produkts. Die Weiterentwicklung ist orientiert an fachlichen Anforderungen und Ideen. Technisch werden unterbrechungsfreier Betrieb sowie permanente Überwachung und Sicherung der Qualität gewährleistet.
Gegenstände der Entwicklung sind der Sourcecode der Anwendung, Testprogramme, Module und Bibliotheken. Das Team nutzt, pflegt und versioniert auch die Artefakte zur Automatisierung von Arbeitsabläufen. Das sind codierte Verfahren für Qualitätsprüfungen, Build- und Integrations-Prozesse, Virtualisierung, Bereitstellung und Aufrechterhaltung des Betriebs, Logging usw. Sie sind mit Bezug auf die Anwendung programmiert, konfiguriert und in der Arbeitsumgebung verfügbar.
ML-Entwicklung konfiguriert und parametrisiert (trainiert) Programme („Modelle” genannt), die Muster in vorhandenen Daten algorithmisch erkennen und in neuen Daten wieder-erkennen. Die Programme modellieren (sic!) Sachverhalte aus dem Anwendungsbereich, wie sie sich durch Muster in den Daten widerspiegeln. Ein Modell wird dann auf der Grundlage von Daten evaluiert, die im Optimierungsprozess des Trainings nicht eingesetzt wurden. Damit wird getestet, ob ein Modell, angewandt auf neue Daten, fachlich nützliche Ergebnisse in ausreichendem Maße liefert. Nun gilt es, diese datenorientierte Entwicklung von ML-Komponenten in den Zyklus von DevOps-Aktivitäten zu integrieren. Gegenstände der Entwicklung und des Betriebs sind nicht nur Softwarekomponenten, sondern auch Komponenten zur Datenverwaltung und der Pflege von Metadaten, welche zur Orientierung in den vielfältigen und großen Datenbeständen geeignet sind.
Monitoring und technische Sicherung des Betriebs wird ergänzt um eine fachliche Bewertung der eingehenden Daten und der Ergebnisse des Modells. Dies geschieht anhand von Statistiken und Metriken, mit denen die Betriebsbedingungen und Analysen der Modell-Anwendung geprüft werden. In der Entwicklung werden Grenzwerte oder Referenz-Statistiken ermittelt, die eine automatisierte Qualitätsprüfung und Monitoring der Anwendung im laufenden Betrieb vorbereiten. Diese Metrik-Algorithmen müssen codiert und konfiguriert werden und sind Artefakte in Entwicklung und Betrieb.
Effekte wie Data-Drift – die Änderung der Verteilung innerhalb der Daten – oder Concept-Drift – eine fundamentale Änderung der zugrunde liegenden Muster – müssen rechtzeitig erkannt, kompensiert oder behoben werden.
Abbildung 1 zeigt die Arbeits- und Automatisierungsbereiche in einem MLOps-Prozess und eine große Vielfalt von Tätigkeiten, die von unterschiedlichen Werkzeugen unterstützt werden. Die Werkzeuge müssen beherrscht werden und sind auch Elemente der Automatisierung. Sie werden in automatisierte Arbeitsabläufe integriert, welche Entwicklung, Bereitstellung und Betrieb einer ML-Anwendung effektivieren [Beck20].
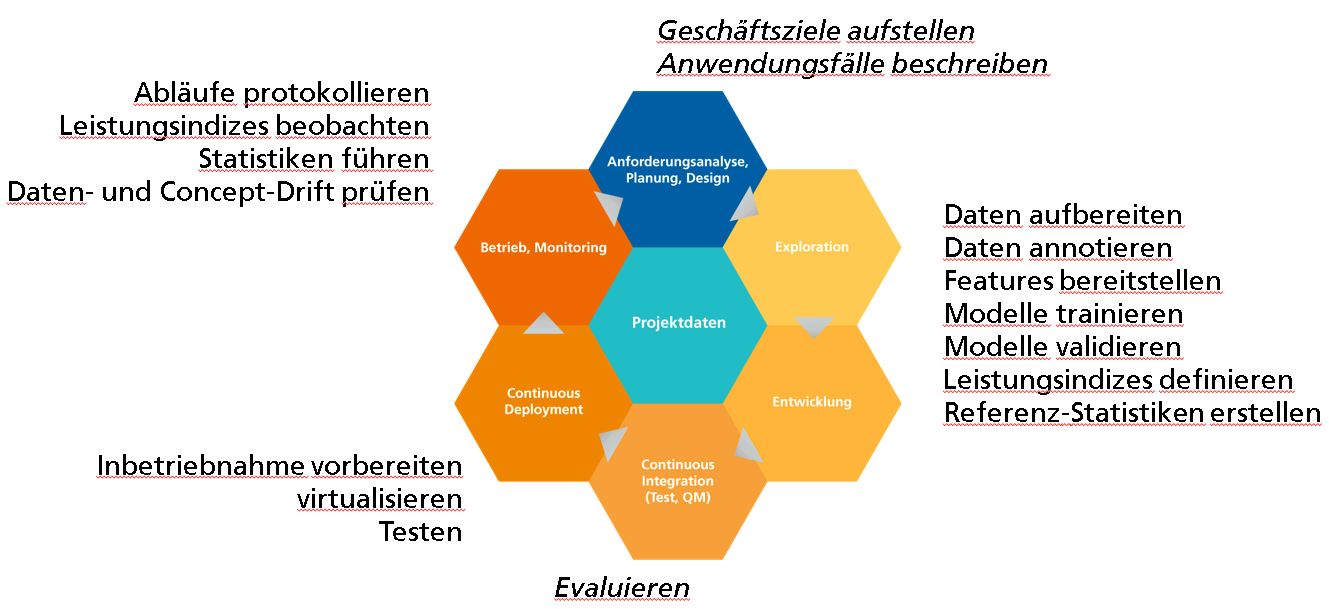
Abb. 1: Tätigkeiten im MLOps-Zyklus
Durch den ehemaligen Big-Data-Hype, die aktuellen Entwicklungen im Bereich der großen Sprachmodelle und angesichts der umfangreichen Machine Learning-Infrastrukturen der großen Cloud-Anbieter sind Unternehmen mit der Frage konfrontiert, ob und wie sie Verfahren des maschinellen Lernens (ML) in ihr Geschäftsmodell integrieren können.
Das softwaretechnische Wissen
Für den Aufbau erster Use-Cases werden in der Praxis häufig Data Scientists eingestellt, deren Hintergrund sich in der Regel auf den mathematischen und algorithmischen Hintergrund bekannter ML-Algorithmen fokussiert, sowie deren Einsatz und die vorbereitenden Schritte zur Datenaufbereitung. Das notwendige softwaretechnische Wissen in einem DevOps geprägten Projektalltag ist nur sporadisch vorhanden.
Data Science Use Cases werden an der Universität und auch in der Praxis mittels Jupyter Notebooks umgesetzt. Diese Technologie erlaubt die interaktive Ausführung von Code, das Darstellen von Inputs, Outputs, Bildern und Texten. Diese Möglichkeiten ermöglichen ein schnelles Experimentieren, die Exploration von Datensätzen und erklären die große Anziehungskraft, die sie auf Data Scientists ausüben.
Jupyter Notebooks sind jedoch nicht dazu ausgelegt, gemeinschaftlich an ihnen zu arbeiten, da Outputs überschrieben werden und Anpassungen nicht nachvollziehbar sind. Bei der gleichzeitigen Entwicklung verschiedener Notebooks durch verschiedene Mitarbeitende ergibt sich die Gefahr, dass gleiche Funktionalität auf verschiedene Arten umgesetzt wird und Ergebnisse abweichen, ohne dass dies offensichtlich wird. Vergleichbare Herausforderungen sind bekannt im DevOps-Kontext und hier haben sich Verfahrensweisen wie die Versionierung des Codes, Modularisierung der Architektur und rigides, automatisiertes Testen bewährt. Dies unterstützt die effiziente Teamarbeit und auftretende Fehler werden frühzeitig erkannt.
Jede MLOps-Strategie muss Verfahrensweisen etablieren, die es Data Scientists ermöglichen, ihre gewohnten Tools einzusetzen, und sie gleichzeitig unterstützen, sich in den Arbeitsfluss agiler Entwicklerteams einzufügen. Es gilt zu klären, wie der Übergang von Jupyter Notebooks in versionisierten und getesteten Sourcecode organisiert werden kann.
Vor diesem Hintergrund kommt dem Aufbau softwaretechnischen Wissens bei den Mitarbeitenden mit Data Science-Hintergrund eine große Bedeutung zu. Gleichzeitig ist die durch Experimente getriebene Arbeitsweise mit Jupyter Notebooks gerade in explorativen Phasen äußerst nützlich und kann einen entscheidenden Beitrag zur Beschleunigung der Modellentwicklung leisten. Daher ist es notwendig, ein Verständnis für diese Arbeitsweisen im Entwicklerteam zu verankern und umgekehrt das Wissen und bewährte Praktiken des Software-Engineerings im gesamten Team zu pflegen. Ein praktischer Weg der Motivation ist zum Beispiel, im Pair-Programming ein funktionierendes Notebook schrittweise in verständliche Module und zugehörige Test-Module umzuwandeln und in einem Code Repository zu versionieren.
Rollen, Tools und Automatisierung
Um das Ziel eines hohen Automatisierungsgrades zu erreichen, müssen Mitarbeitende in den Projekten verfügbar sein, die die Tools zur Automatisierung nicht nur anwenden, sondern auch konfigurieren können. Für das bekannte Tooling aus dem DevOps-Bereich haben sich Rollen, wie DevOps Engineer, herausgebildet, die genau diese Lücke füllen wollen. Im Bereich ML kommt jetzt eine ganze Reihe weiterer Tätigkeiten hinzu, die sich mit der versionierten Speicherung von Objekten, wie Modelle, Datensätze und Metriken, auseinandersetzen. Hier ist ein ganzer Markt neuartiger Tools entstanden, die sich optimal auf den Arbeitsfluss von Data Scientists einstellen und versuchen, diese Tätigkeiten mit möglichst wenig manuellem Anteil zu vereinfachen. Die Anwendung dieser Tools ist jedoch selten trivial, und es erfordert einen nicht unerheblichen Aufwand, um sie zu beherrschen und in automatisierten Prozessen miteinander zu verknüpfen.
Eine Vielzahl an Anbietern ist angetreten, diese Probleme zu lösen, und verspricht in ihren Angeboten Plattformen, bei denen keiner oder nur ein geringer Eingriff des Entwicklerteams notwendig ist. Das kann auch grundsätzlich richtig sein - bevor man aber ein solches Angebot berücksichtigt, sollte beurteilt werden, wohin man sich in den nächsten Jahren entwickeln möchte, wie viel Individualität bei der Entwicklung notwendig ist und ob das Risiko eines Vendor Lock-in gerechtfertigt ist.
Bevor eine solche Entscheidung getroffen wird, ist es zunächst vielversprechender, im Unternehmen grundsätzliche MLOps-Kompetenzen aufzubauen und Arbeitsprozesse zu etablieren, die die Voraussetzungen schaffen, um ML-Produkte kompetent zu entwickeln. Dadurch kann mittelfristig das Wissen und Verständnis aufgebaut werden, um für spezifische Herausforderungen auch kommerzielle Software als Lösung in Betracht zu ziehen.
Um diese Kompetenz aufzubauen, haben sich sogenannte Maturity-Modelle im MLOps-Bereich (s. Abb. 2) etabliert. Diese beschreiben den inkrementellen Aufbau immer fortschrittlicherer Kompetenzen und Tätigkeiten. Das Ziel ist es, manuelle Tätigkeiten durch automatisierte Pipelines zu ersetzen. In den höheren Maturity-Ebenen sind davon insbesondere ML-Tätigkeiten erfasst, wie Trainieren neuer Modelle, deren Testing und Monitoring.
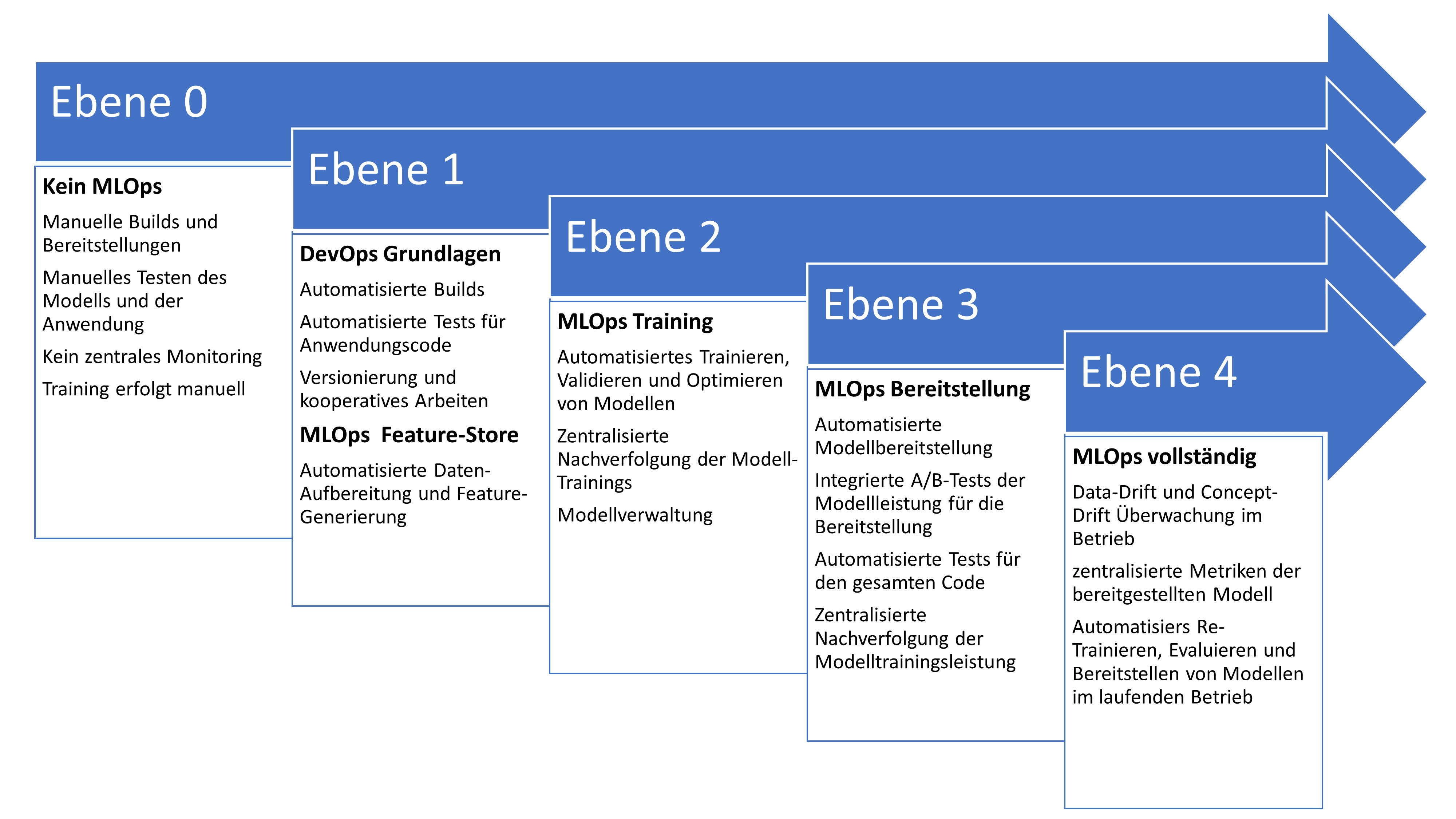
Abb. 2: MLOps Maturity Level [Microsoft23, Google23]
Die zunehmende Automatisierung von ML-Tätigkeiten zeigt die Veränderung im Berufsbild eines Data Scientist. Statt durch wissenschaftlich orientierte Data Scientists wird die Entwicklung verstärkt von Rollen wie ML-Engineer oder ML-Solution-Architekt übernommen, welche sowohl Kenntnisse im Machine Learning als auch im Software-Engineering voraussetzen, um entsprechende Pipelines entwickeln und warten können.
Fazit
MLOps bietet einen ganzheitlichen Lösungsansatz zur nachhaltigen Entwicklung und Übernahme von ML-Anwendungen in den produktiven Betrieb [Beck20]. Neben einem vielfältigen Angebot von Arbeitsumgebungen, Werkzeugen, Komponenten und automatisierten Verfahren entstehen neue Arbeitsweisen, Rollen und Managementmethoden, um dem hohen Anspruch an die Qualität der Entwicklung und dem Betrieb einer ML-Anwendung gerecht zu werden.
Die Arbeitsweise von MLOps sollte in den Entwicklungsabteilungen schrittweise erschlossen werden. Eine durchdachte MLOps-Strategie misst den Reifegrad eines Teams daran, welches Maß an Automatisierung eingesetzt und im Entwicklungsprozess technisch und organisatorisch beherrscht wird. Wir empfehlen eine mittelfristige Strategie mit geplant wachsender Projektgröße und Komplexität, zunehmender Automatisierung, verständlicher Organisation und gepflegter Kompetenz in Kommunikation und Konstruktion.
Weitere Informationen
[Beck20] N. Beck, C. Martens, K. H. Sylla, D. Wegener, A. Zimmermann, Zukunftssichere Lösungen für maschinelles Lernen, Fraunhofer IAIS, 2020,
https://publica.fraunhofer.de/entities/publication/be431a0b-ae8e-4644-9b0b-429249bcd8f0/details
[Microsoft23]
https://learn.microsoft.com/de-de/azure/architecture/example-scenario/mlops/mlops-maturity-model









