

Dieser Artikel unterstützt Data Scientists, Data Engineers, Entwickler und DevOps-Kollegen, ihr Machine-Learning-Projekt zum Erfolg zu bringen. Dabei stehen einmal nicht die Auswahl und Erklärung von Algorithmen im Fokus, sondern all die Themen, die bei einem Machine-Learning-Projekt darüber hinaus wichtig sind. Als Softwarearchitekt oder Data Scientist beschäftigen wir uns seit Längerem mit Themen rund um Machine-Learning und stoßen dabei immer wieder auf ähnliche Herausforderungen.
Diese Sammlung von Herausforderungen lässt sich hernehmen, um den Produktiveinsatz von Machine-Learning-Lösungen vorzubereiten oder die eigene Modellentwicklung im Unternehmen weiter zu strukturieren. Neben einer Erläuterung findet sich zu jedem Bereich eine Checkliste, in der die wichtigsten Punkte festgehalten sind und „abgehakt“ werden können. Aber nun zu den vielfältigen Herausforderungen außerhalb der Analytik (siehe Abbildung 1).
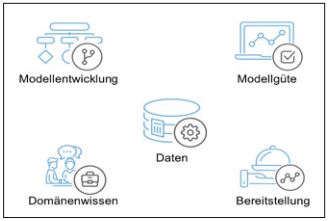
Abb. 1: Die fünf Disziplinen des MachineLearnings
Kontinuierliche Datenarbeit und ganzheitliches Datenmanagement
Das Naheliegendste ist sicher die Datengrundlage als Herzstück des Modells und seiner Entwicklung. Eine kontinuierliche Datenarbeit umfasst das Arbeiten auf drei Dimensionen:
Um ein gutes Modell zu bauen, muss zunächst klar sein, was in den Daten steckt. Exploration ist angesagt. Wie ist die Signal-to-Noise-Ratio, sprich: Wie viel Erklärung oder Prädiktionskraft kann auf Basis dieser Input-Daten überhaupt erwartet werden? Nachhaltigkeit entsteht, wenn diese Exploration nicht nur einmal, sondern kontinuierlich stattfindet. Dies ist vor allem wichtig, wenn kein automatisiertes Retraining der Modelle stattfindet, da die Güte des Modells im Zeitverlauf nachlässt.
Eine der Hauptaufgaben eines Data Scientists und vor allem Engineers ist die Aufbereitung der Daten zum Training von Modellen. Die Faustregel, dass darauf 70 Prozent der Projektzeit entfällt, ist nach wie vor korrekt. Gerade weil es sich um eine zeitintensive Aufgabe handelt, profitiert man maßgeblich davon, dass Redundanzen vermieden und Synergien zwischen verschiedenen Modellen ähnlicher Domänen genutzt werden. Frühzeitige Überlegungen zum Feature Data Management, einer zentralen Datenhaltung für die Modellinputs, können sich schnell bezahlt machen.
Soll das Modell Vorhersagen liefern, sind häufig Live- oder Near-Realtime-Daten nötig. Neben der technischen Anbindung dieser Daten besteht die Herausforderung hier vor allem in der Verarbeitung von neuen Daten durch das trainierte Modell. Wie geht das Modell mit fremden Daten um, wenn die neuen Daten nicht zu den Trainingsdaten passen? Fehlende Kongruenz kann sich hier auf die fachliche Bedeutung, das Format, den Wertebereich oder auch auf das Fehlen von Werten beziehen. Dies führt zur ersten Checkliste.

Checkliste 1: Datenarbeit
Strukturierte und nachvollziehbare Modellentwicklung
Modellentwicklung ist Softwareentwicklung. Das mag offensichtlich klingen, dennoch finden in der Praxis etablierte Vorgehen und Best Practices aus der Softwareentwicklung nicht immer Anwendung. Dabei ist es empfehlenswert, frühzeitig auf einen strukturierten und nachvollziehbaren Aufbau zu setzen, denn Machine-Learning-Projekte sind langfristig ausgelegt. Erweiterbarkeit, Wartbarkeit sowie Testbarkeit sind, genau wie in der Softwareentwicklung, von zentraler Bedeutung.
Wichtige Bestandteile des Entwicklungsprozesses wie Versionskontrolle, Tests, Dokumentation und Qualität (vgl. Abbildung 2) sind Aspekte, die in allen Softwareprojekten zu beachten sind.
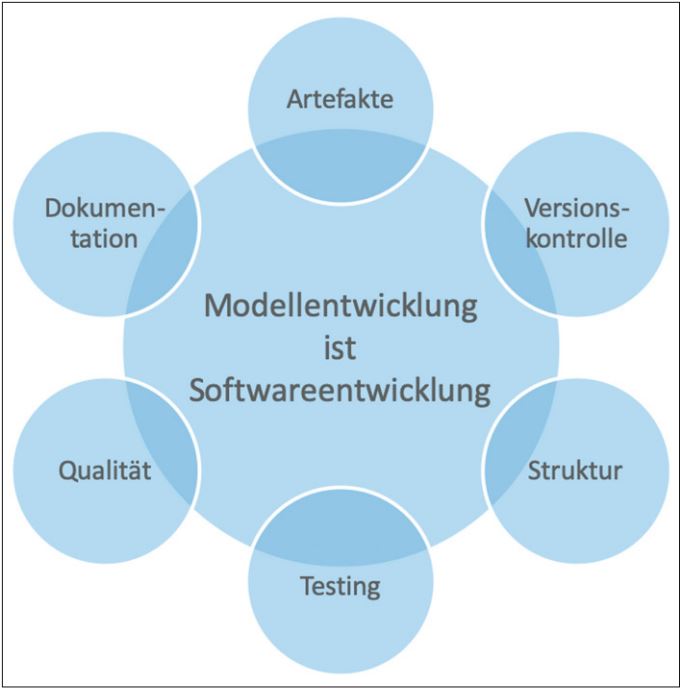
Abb. 2: Wichtige Bestandteile der Softwareentwicklung
Unterschiede beziehungsweise Feinheiten stecken im Detail: Bei der Versionskontrolle ist beispielsweise zu beachten, dass in Machine-Learning-Projekten neben Quellcode auch Trainingsdaten versioniert werden sollten. Abhilfe schaffen hier Lösungen wie DVC oder GIT-LFS (siehe [Dvc] bzw. [Git]).
Der Begriff Qualität bezieht sich nicht nur auf die Abdeckung des Modell- und Datentransformationscodes mit Tests, sondern explizit auch auf die Modellgüte (wie z. B. Sensitivität, Spezifität oder die Quote der falschpositiven Vorhersagen) und die Veränderung dieser während der Entwicklung: Welcher Code hat mit welchen Daten zu welchem Ergebnis geführt? Da bei der Modellentwicklung das Optimieren einer Metrik im Fokus steht, führen Experimente und Hyperparametertuning zu einer Vielzahl unterschiedlich konfigurierter Modelle. Um unterschiedliche Konfigurationen und Testläufe sinnvoll vergleichen zu können, ist die Aufzeichnung der Ergebnisse notwendig. Zum Tracking von Modellparametern und Güteergebnissen können Werkzeuge wie mlflow eingesetzt werden (siehe [Mlfl]). Dies führt zur zweiten Checkliste.
Verlässliche Bereitstellung und Beantwortung der Frage: make or buy?
Kommt ein Machine-Learning-Modell nicht zum Einsatz, hat seine Entwicklung nur sehr begrenzten Nutzen gestiftet. In der Regel muss es einem Benutzer oder einer Benutzergruppe zur Verfügung gestellt und in eine Systemlandschaft eingebettet werden. Gerade in Unternehmen, in denen es eine Vielzahl unterschiedlicher ML-Anwendungsfälle und Modelle gibt, lohnt sich ein einheitliches Vorgehen bei der Bereitstellung. Das kann „onpremises“, also auf eigener Hardware, und mittels zentraler Plattform passieren. Unterschätzt wird dabei jedoch oft der administrative Aufwand zur Pflege von Inhouse-Lösungen. Die Nutzung von Cloud-Diensten mag zunächst kostenintensiv erscheinen, kann sich aber mittelfristig rechnen und ermöglicht den Modellentwicklern ein breites (und häufig aktuelleres) Spektrum an Werkzeugen. Neben dem Kostenaspekt sollten es also auch die (zukünftigen) Anforderungen sein, die die Entscheidung „Cloud oder on-premises“ beeinflussen.
Orientiert man sich bei der Erstellung der Deployment-Artefakte an etablierten Herangehensweisen, profitiert man von erhöhter Flexibilität. Ein Deployment unter dem Einsatz von Containervirtualisierung, zum Beispiel mittels Docker (vgl. [Dock]), kann den zukünftigen Cloud-Einstieg oder Ausstieg erleichtern sowie den Wechsel zwischen Providern ermöglichen.
Neben dem Betriebsaspekt sei an dieser Stelle noch auf andere Dienste aus dem Portfolio von Cloud-Providern hingewiesen. Interaktive, webbasierte Notebooks à la Jupyter (vgl. [Jupy]) sind im Data-Science-Bereich längst etabliert. Sie werden in der Cloud nicht nur vollständig verwaltet, sondern profitieren auch direkt von skalierbarer Infrastruktur. Andere Dienste gehen über die Bereitstellung von Hard- oder Software hinaus: Vortrainierte Modelle lösen gängige Probleme wie Bilderkennung, Textklassifizierung oder Vorhersagen und können Eigenentwicklungen überflüssig machen. Mit AutoML-Diensten lässt sich zum Teil vollständig auf Code verzichten. Ob diese Optionen für den speziellen Anwendungsfall ausreichen, gilt es anhand der Anforderungen zu entscheiden.

Checkliste 2: Modellentwicklung

Checkliste 3: Bereitstellung
Einbeziehen von Domänen- experten und Anwendern
Abstrahiert lässt sich ein Machine-Learning-Projekt anhand des häufig bemühten „Cross-industry standard process for data mining“-Zyklus nach [Cha00] darstellen. Laut CRISP-DM folgt auf die Phase Business Understanding die Datenexploration, dann die Datenaufbereitung, die Modellierung wird gefolgt von der Evaluation und einem Deployment-Part. Neben der fast schon sträflichen Nicht-Spezifierung des Bereichs Deployment, die sich nur durch den alleinigen Fokus „Datenprodukt = Analyse“ erklären lässt, suggeriert dieser Prozess, dass man die Domänenexperten nur kurz zu Projektstart einbeziehen müsse. Um ein nutzbares Modell zu entwickeln, entspricht dies nicht der Realität.
Nicht nur in der Initialisierungsphase beim Entwickeln des Business-Cases, wo Fragen nach dem Datenprodukt, aber auch nach der Nachvollziehbarkeit beantwortet werden sollen, ist die Integration von Domänenexperten essenziell. Das finale Modell und ganz besonders die Exploration profitieren qualitativ und aus Effizienzgesichtspunkten von einer engen Begleitung und Abstimmung. In diesen Phasen (in Abbildung 3 rot gekennzeichnet) lohnt die enge Zusammenarbeit besonders.
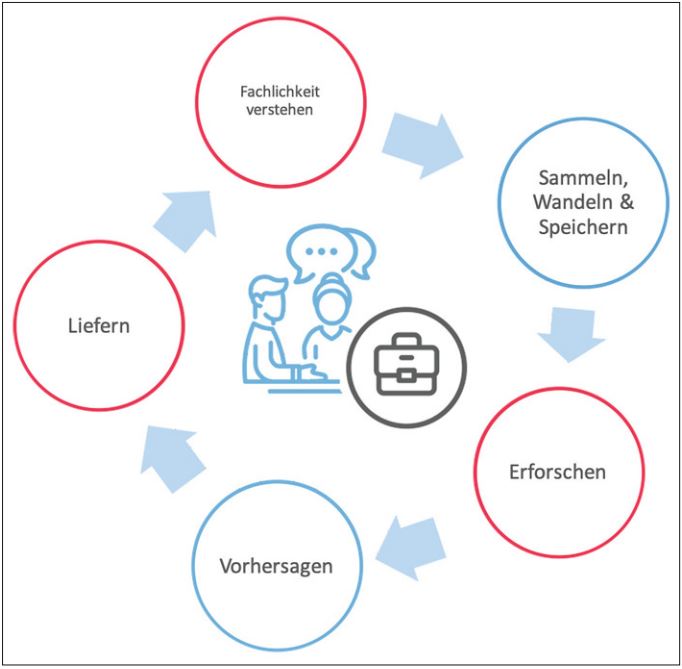
Abb. 3: Einbeziehen der Domänenexperten in den CRISP-DM-Prozess
Sicherstellen hoher Modellgüte
Ist das Modell erst einmal in die freie Wildbahn (also den Unternehmenskontext) entlassen, dient es der Entscheidungsunterstützung und ist häufig unternehmenskritisch. Es muss das Ziel sein, eine gleichbleibend hohe Modellgüte sicherzustellen. Da sich der Unternehmenskontext meist schleichend weiterentwickelt, muss man hierfür aktiv werden.
Dass ein Modell nicht mehr so gut ist wie kurz nach dem Training, kann verschiedene technische und nicht-technische Gründe haben: Datenquellen ändern ihre Strukturen, aber vielleicht ändert sich auch das Kundenverhalten systematisch, welches das Modell eigentlich vorhersagen soll. Um diese Veränderungen zu beobachten, gibt es verschiedene Anknüpfungspunkte.
Der erste ist das Aufzeichnen (Logging) der gemachten Prognosen und die retrospektive Untersuchung, ob sich die Verteilung dieser verändert. Hat man die abgegebenen Prognosen gespeichert, ist der nächste Schritt der Vergleich mit der Verteilung der Prognosen aus dem Modelltraining. Schlussendlich sollte bei neuen Iterationen oder Neueinführungen eines Modells kontrollgruppenbasiert getestet werden, ob das Modell wirklich besser ist als das vorherige.

Checkliste 4: Domänenwissen

Checkliste 5: Modellgüte
Zunehmende Unterstützung durch Dienste und Werkzeuge
Durch Nutzung der Checklisten lassen sich die zentralen Herausforderungen beim Entwickeln von Machine-Learning-Modellen identifizieren und meistern. Sie umfassen sowohl fachliche als auch verschiedene technische Dimensionen. Je nach Projektkonstellation sind manche Punkte sicher relevanter als andere, alle sollten jedoch zumindest bedacht und gegebenenfalls kontinuierlich betrachtet werden.
Die Entwicklung von Machine-Learning-Anwendungen wird zudem zunehmend komfortabler: Zum einen ermöglichen viele Cloud-Anbieter die Abdeckung signifikanter Teile unserer Checkliste. Zum anderen unterstützen Werkzeuge wie mlflow konkret das Meistern gewisser Herausforderungen, wie hier die Protokollierung von Modelliterationen. Dennoch ist die Prüfung der aufgelisteten Punkte unabdinglich, um sicherzustellen, dass das eigene Vorgehen alle relevanten Schritte berücksichtigt und abdeckt.
Beinhaltet das eigene Vorgehen alle relevanten Schritte? Falls ja: Viel Spaß beim Entdecken der Geheimnisse des Machine-Learnings!
Literatur & Links
[Cha00] P. Chapman et al., CRISP-DM 1.0: Step-by-step data mining guide, SPSS, 2000, s. a.: https://www.the-modeling-agency.com/crisp-dm.pdf
[Dock] Docker, siehe: https://docker.com
[Dvc] Data Version Control, siehe: https://dvc.org
[Git] Git Large File Storage, siehe: https://git-lfs.github.com
[Jupy] Project Jupyter, siehe: https://jupyter.org
[Mlfl] Mlflow, siehe: https://mlflow.org









