

Softwaretests stehen häufig unter großem Druck: Die Zeit ist zu knapp, das Geld sowieso, gutes Personal ist schwer zu finden. Gleichzeitig ist es praktisch unmöglich, alle möglichen Szenarien zu testen. Allein ein simples Login-Formular könnte theoretisch eine enorme Zahl an Kombinationen liefern, doch in der Praxis reicht es, eine begrenzte Anzahl von Variationen zu testen – etwa durch Überprüfung gängiger Eingaben oder realistischer Passwortlängen. Schon deswegen werden im Testing Techniken wie Äquivalenzklassenbildung oder Grenzwertanalyse angewandt, um sich auf die wirklich wichtigen Datensätze zu konzentrieren. Doch was, wenn auch mit diesen Techniken die Anzahl der Testfälle unüberschaubar hoch wird? Besonders in langlebigen Enterprise-Projekten stellt diese Tatsache Tester und Testmanager vor Probleme, wie sie ihre Tests priorisieren und auswählen sollen.
Eine Lösung für dieses Problem heißt risikobasiertes Testen (RBT). Dabei werden Testfälle anhand des Risikos bewertet, das sie für ein Projekt abdecken. Risiken sind im Kontext der Softwareentwicklung Möglichkeiten für Ereignisse, die ein Projekt – positiv oder negativ – in Hinsicht auf Erfolg, Zeitrahmen, Budget, Qualität, Reputation und vieles mehr beeinflussen können. Diese Risiken können verschiedene Ursprünge haben: Sie können vom Produkt und seinen Funktionen selbst stammen, aus dem Entwicklungsprozess kommen oder auf externe Quellen wie gesetzliche und regulatorische Anforderungen zurückgehen.
Eine Bewertung dieser verschiedenen Risikoquellen und Zusammenfassung in ein quantifizierbares Risiko ist in RBT essenziell, um eine zufriedenstellende Priorisierung der Testaktivitäten vorzunehmen. Durch diese Bewertung lässt sich das Testing gezielt steuern, um Ressourcen so effizient wie möglich einzusetzen. Das bringt verschiedene Vorteile mit sich: Die kritischsten Fehler werden schnellstmöglich identifiziert („Shift left“), was zu weniger kritischen Fehlern im Produktivsystem führt und damit die Kundenzufriedenheit und letztendlich auch Kosteneffizienz erhöht.
Der klassische RBT-Prozess
Klassischerweise wird RBT meist durchgeführt, indem die Parameter Eintrittswahrscheinlichkeit und Auswirkung eines potenziellen Fehlers eines Testfalls bewertet werden. Diese Parameter werden von verschiedenen Stakeholdern bewertet und dann in einer Matrix zusammengeführt, um das Risiko zu ermitteln – häufig eingeteilt in gering, mittel und hoch oder anhand der Multiplikation beider Faktoren. Anschließend können Testfälle entsprechend diesem Risiko priorisiert werden.
Um Risikobewertungen aktuell zu halten, ist allerdings eine konstante Re-Evaluierung notwendig. Das kann insbesondere im agilen Kontext zu häufigen, zeitfressenden Meetings oder im schlimmsten Fall zu veralteten Risikobewertungen führen. Auch ist eine solch grobe Einschätzung bei großen Projekten oft ungenügend und unterliegt starken subjektiven Schwankungen. Neue RBT-Ansätze versuchen daher, die Komplexität von Software und die zugrunde liegenden Daten stärker zu berücksichtigen.
Wissenschaftliche Herangehensweise an RBT
Eine Möglichkeit, diesen Herausforderungen gerecht zu werden, wurde 2015 mit einer wissenschaftlichen Studie zu einem Bayesschen Vorhersagemodell zu RBT unternommen [1]. Dieses Modell wurde bei einem langjährigen, komplexen Projekt mit verschiedenen Entwicklungs- und Testphasen in jedem Releasezyklus untersucht, für das bereits viele Daten vergangener Fehler vorlagen und die Testexperten ein gutes Gespür für neue Risiken entwickelten.
Grundlage für die Auswahl von Testfällen für einen Testlauf bildeten dort neben der Einschätzung der Experten auch die Kosten- und Wahrscheinlichkeitsfaktoren (siehe Formel 1).
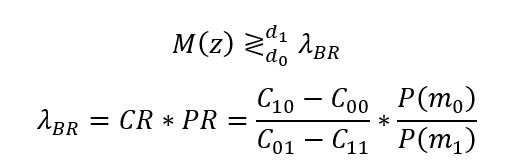
Formel 1: Entscheidungskriterium des Bayesschen Vorhersagemodells und Berechnung des Bayes-Risiko-Schwellenwerts.
M(z): Mittel der Experteneinschätzungen zur Anzahl der Fehler.
d1: Entscheidung zum Ausführen des Testfalls.
d0: Entscheidung zum Auslassen des Testfalls.
λBR: Bayes-Risiko-Schwellenwert.
C00: Kostenfaktor für korrektes Auslassen des Testfalls.
C01: Kostenfaktor für inkorrektes Auslassen des Testfalls.
C10: Kostenfaktor für inkorrektes Ausführen des Testfalls.
C11: Kostenfaktor für korrektes Ausführen des Testfalls.
P(m0): Vorherige Wahrscheinlichkeit keines Fehlers.
P(m1): Vorherige Wahrscheinlichkeit eines Fehlers.
War die Einschätzung der Experten zum Auffinden eines Fehlers größer als der Schwellwert, wurde der Testfall ausgeführt. Zusätzlich wurde auch die Risikodifferenz zwischen Auslassen und Ausführen der Testfälle bestimmt, die zur Anordnung der Testfälle im Testlauf genutzt wurde.
Mithilfe dieses Prozesses flossen sowohl objektive Daten über vorangegangene Fehlschläge und damit verbundene Kosten als auch die subjektiven Expertenmeinungen in das Modell ein. Dieses Vorgehen erwies sich als erfolgreich; nicht nur wurden risikobehaftete Testfälle verlässlich identifiziert und konnten sinnvoll priorisiert werden, sondern das Modell erwies sich auch als anpassbar an verschiedene Projektphasen und konnte die Expertenmeinungen durch Gewichtung normalisieren (siehe Abb. 1).
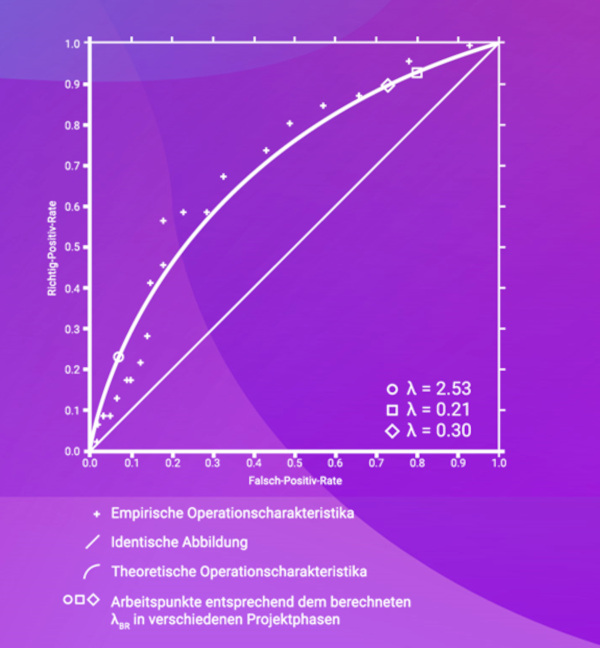
Abb. 1: Operationscharakteristika des Bayesschen Vorhersagemodells
Dennoch ist diese Methode der Risikobewertung mit gewissen Nachteilen verbunden: Die Risikoeinschätzung der Experten erfolgte manuell in jeder Releasephase, und trotz Gewichtung ist eine der Hauptsäulen der Risikobewertung die Schätzung der Experten. Zudem sind viele Daten zur Erstellung des Modells nötig, und die zugrunde liegende Mathematik ist nicht sofort eingängig.
Das RBT-Ebenenmodell
Statt mehrere Daten zu einer einzigen Risikobewertung heranzuziehen, geht das Ebenenmodell (siehe Abb. 2) einen Schritt zurück und ordnet sie dedizierten Risikoebenen zu.
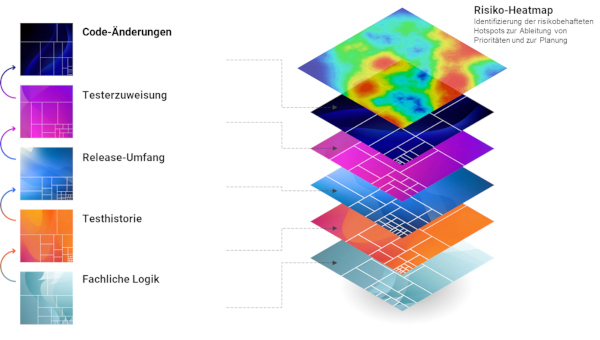
Abb. 2: RBT-Ebenenmodell
Diese Ebenen sind:
- die Fachliche Logik, wo Testfallkomplexität und Schlüsselwörtern zur Risikoermittlung herangezogen werden,
- die Testfallhistorie, bei der Fehlerfrequenz und durchschnittlicher Schweregrad eines Fehlers analysiert werden,
- der Release-Umfang, in dem Testfälle nach Relevanz für ein vorliegendes Release bewertet werden,
- die Testerzuweisung, in der Testbarkeit und Know-how des Testers beziehungsweise Testautomatisierers eine Rolle spielen, und
- die Code-Änderungen, die Testfälle nach ihrer Beziehung zu neuem und geändertem Code bewertet.
In jeder Ebene werden bewusst nur die Faktoren bewertet, die dafür relevant sind, um so eine Risikoeinschätzung nur aus einer bestimmten Perspektive zu erhalten (siehe Abb. 3).
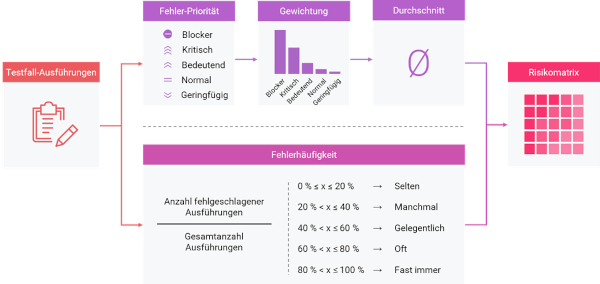
Abb. 3: Schema zur Risikoberechnung auf Ebene der Testhistorie
Jedem Testfall wird für jede Ebene automatisiert anhand der zur Verfügung stehenden Daten ein Risikowert zugeordnet. Dafür werden die Zahlen der Fibonacci-Folge verwendet. Einstellige für geringe Risiken, zweistellige für mittlere Risiken und dreistellige für hohe Risiken. Das erlaubt eine ausreichende Nuanciertheit und Vergleichbarkeit der Ebenen untereinander.
Als Gesamtrisiko werden die Risikoebenen eines Testfalls als arithmetisches Mittel aggregiert. Durch das exponentielle Wachstum der Fibonacci-Zahlen ist diese Aggregation inhärent gewichtet. So kann beispielsweise bei einer Einstufung als Hochrisikotestfall in einer Ebene trotz der Bewertung als geringes Risiko in allen anderen Ebenen das Gesamtrisiko noch immer im Hochrisikobereich liegen.
Wegen des mehrschichtigen Ansatzes wird dieses Modell auch das „Lasagne-Prinzip“ genannt. Ähnlich wie in dem beliebten Nudelgericht ist jede Ebene für sich wertvoll, doch in der Kombination entstehen emergente Eigenschaften.
Vorteile und Herausforderungen
Durch die automatisierte Risikobewertung werden Ressourcen für andere Aufgaben frei, ohne den Vorteil einer Priorisierungsmetrik zu verlieren. Ebenso sorgen Vernetzung mit anderen Testing-Tools und Feedback-Loops für automatische, konsistente und vergleichbare Risikobewertung, die nicht auf subjektive Einschätzungen vertraut.
Taucht zum Beispiel ein Fehler bei der Ausführung eines Testfalls auf, wird dieser Testfall automatisch in zukünftigen Releases mit einem höheren Risiko bewertet. Die Testhistorie reagiert auf die angestiegene Fehlerfrequenz und das entstandene Fehlerticket, im Release-Umfang wird der zukünftige Bugfix einberechnet und in der Code-Änderung sind neue oder geänderte Code-Abschnitte dieses Testfalls mit einbezogen. Das sorgt dafür, dass der Testfall zukünftig höher priorisiert wird – bis die nachfolgend hoffentlich positiven Testläufe eine geringere Einstufung vornehmen.
Diese Prinzipien machen das Ebenenmodell besonders interessant für große, langlaufende Projekte, da kritische und fehlerbehaftete Bereiche ebenso wie neu hinzugekommene Systembereiche konsistent für die Testausführung empfohlen werden. Im Zusammenspiel mit Testautomatisierung lassen sich besonders große Synergieeffekte erzielen, da so die kontinuierliche Ausführung der kritischsten Testfälle sichergestellt werden kann und die Datengrundlage verlässlicher und robuster wird.
Bedingungen für die Anwendbarkeit des Ebenenmodells sind verlässliche Dokumentation und einheitlicher Testfallstil. Quellen wie Anforderungs- oder Storytickets von Testfällen müssen ebenso wie Fehlertickets im Testlauf verlinkt werden, um die entsprechenden Daten zur Risikobewertung heranziehen zu können. Und um Komplexität und Schlagworte eines Testfalls zu bewerten, muss ein einheitlicher Standard im Projekt eingehalten werden.
Der beste RBT-Ansatz?
Letztendlich ist die Wahl des RBT-Modells von zahlreichen individuellen Faktoren abhängig (siehe Tabelle 1).
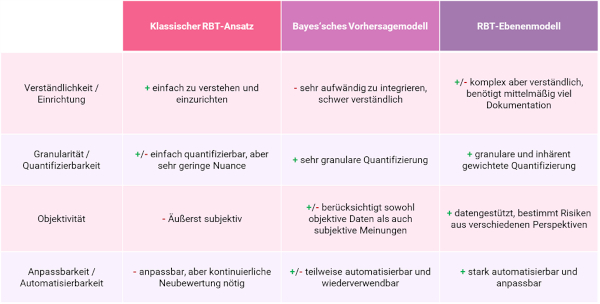
Tabelle 1: Die Wahl des RBT-Modells ist von zahlreichen individuellen Faktoren abhängig
Sicher ist jedoch: Mit zunehmender Softwarekomplexität und Entwicklungsgeschwindigkeit müssen sich auch bestehende Prozesse anpassen. Ohne Risikoeinschätzung und Priorisierung wird es schwierig, sich in dieser schnelllebigen Welt zu behaupten. Und vielleicht liegt der Schlüssel dazu in einer wohlschmeckenden Lasagne verborgen.
Quellen
[1] M. Varendorff et al., A Bayesian Prediction Model for Risk-Based Test Selection, in: SEAA (Software Engineering and Advanced Applications), 2015, siehe: https://ieeexplore.ieee.org/document/7302477









