

Möchte man den Clou beim maschinellen Lernen (ML) benennen, gibt es einige mögliche Antworten. Eine davon: Maschinelle Lernverfahren als Teilgebiet der Künstlichen Intelligenz (KI) kehren den Vorgang der klassischen Datenverarbeitung um. Bisher war es nötig, für einen Computer ein Programm zu schreiben, das mithilfe von Eingabedaten Ausgaben erzeugt. Diese Programmierung erfordert Fachwissen und ist aufwendig. Maschinelles Lernen ermöglicht dem Computer, dass er sich selbst programmiert. Hierfür erhält er Eingabedaten und abhängig von der genutzten ML-Methode auch Ausgabedaten. Darauf basierend wird das nötige Programm, wie beispielsweise ein neuronales Netz, automatisch erstellt. So weit, so genial.
Erklärbarkeit (XAI) immer entscheidender
Es kann aber je nach Anwendungskontext gewünscht oder erforderlich sein, zu wissen, wie dieses automatisch erstellte Programm genau aussieht, wie es funktioniert und aufgrund welcher Rechenschritte es zu bestimmten Ausgabedaten kommt. Das interessiert manchen Verbraucher, der sich über seltsame Empfehlungen in Onlineshops wundert. Kritischer wird es, wenn automatisch gefällte, ML-basierte Entscheidungen Einfluss auf das eigene Handeln nehmen, beispielsweise in Form des oft in diesem Kontext zitierten abgelehnten Kreditgesuchs.
Und unbedingte Nachvollziehbarkeit ist dann gefordert, wenn es um hochgenaue Prozesse und sicherheitskritische Abläufe geht, sei es im Produktionsumfeld, in der Medizin oder beim autonomen Fahren. Beispielsweise entsteht am Fraunhofer-Institut für Produktionstechnik und Automatisierung IPA ein Tool, das beim sicheren Einrichten von Arbeitsplätzen mit Mensch-Roboter-Kooperation unterstützt (s. Abb. 1). Hier muss unbedingt klar sein, warum ein ML-Verfahren welche Entscheidung trifft, damit die Lösung künftig auch zertifizierbar ist.

Abb. 1: ML-Verfahren erleichtern bspw. die Einrichtung von Arbeitsplätzen mit Mensch-Roboter-Kooperation; die ML-basierten Aktionen müssen aber erklärbar sein. (Bild: Fraunhofer IPA/Foto: Rainer Bez)
Branchenübergreifend sind mit der Nachvollziehbarkeit von ML-Verfahren auch die Fragen verbunden, inwieweit die Menschen dieser Technologie vertrauen, sie als Unterstützung akzeptieren und inwieweit es gelingt, eine menschzentrierte, ethische Umsetzung von KI zu schaffen. Dass auch die neue Datenschutzgrundverordnung einfordert, automatisch gefällte Entscheidungen der sie betreffenden Person transparent zu machen, oder die Europäische Kommission kürzlich ihre „Ethik-Leitlinien für eine vertrauenswürdige KI“ vorgelegt hat, sind in diesem Kontext zwei weitere starke Argumente für transparente ML-basierte Entscheidungen.
Die Arbeiten für mehr Transparenz laufen mittlerweile auf Hochtouren. Seitdem maschinelles Lernen und insbesondere neuronale Netze vermehrt in die Anwendung kommen, steigt die Zahl an wissenschaftlichen Veröffentlichungen zum Thema Erklärbarkeit oder auch „XAI“ (Explainable artificial intelligence, s. [SchW21, BuHu21]]) nahezu exponentiell (s. Abb. 2). Wissenschaftler möchten mithilfe verschiedener Ansätze und Methoden den „Blackbox-Charakter“ maschinellen Lernens überwinden. Aber woher rührt dieser überhaupt? Die Algorithmen sind von Menschen gemacht, wie kann es dann sein, dass selbst Experten ein tiefes, also vielschichtiges, neuronales Netz nicht mehr verstehen können? Das liegt an drei Aspekten. Der erste ist die Simulierbarkeit. Diese meint, dass ein Mensch alle Rechenschritte eines Netzes in angemessener Zeit auswerten können sollte. Da ein neuronales Netz mitunter Hunderte Schichten hat, die jeweils Rechenschritte ausführen, kann kein Mensch diese Rechnungen nachvollziehen. Der zweite Aspekt ist die Unterteilbarkeit. Hierfür müssten alle Komponenten eines neuronalen Netzes intuitiv verständlich sein, also auch jeder Parameter, der einen Rechenschritt beeinflusst. Auch das ist nicht mehr möglich. Und schließlich ist die algorithmische Transparenz der dritte Aspekt. Die Entscheidungsgrenzen eines neuronalen Netzes sind alles andere als linear, sondern hochkomplex, sodass auch die algorithmische Transparenz nicht mehr gegeben ist.
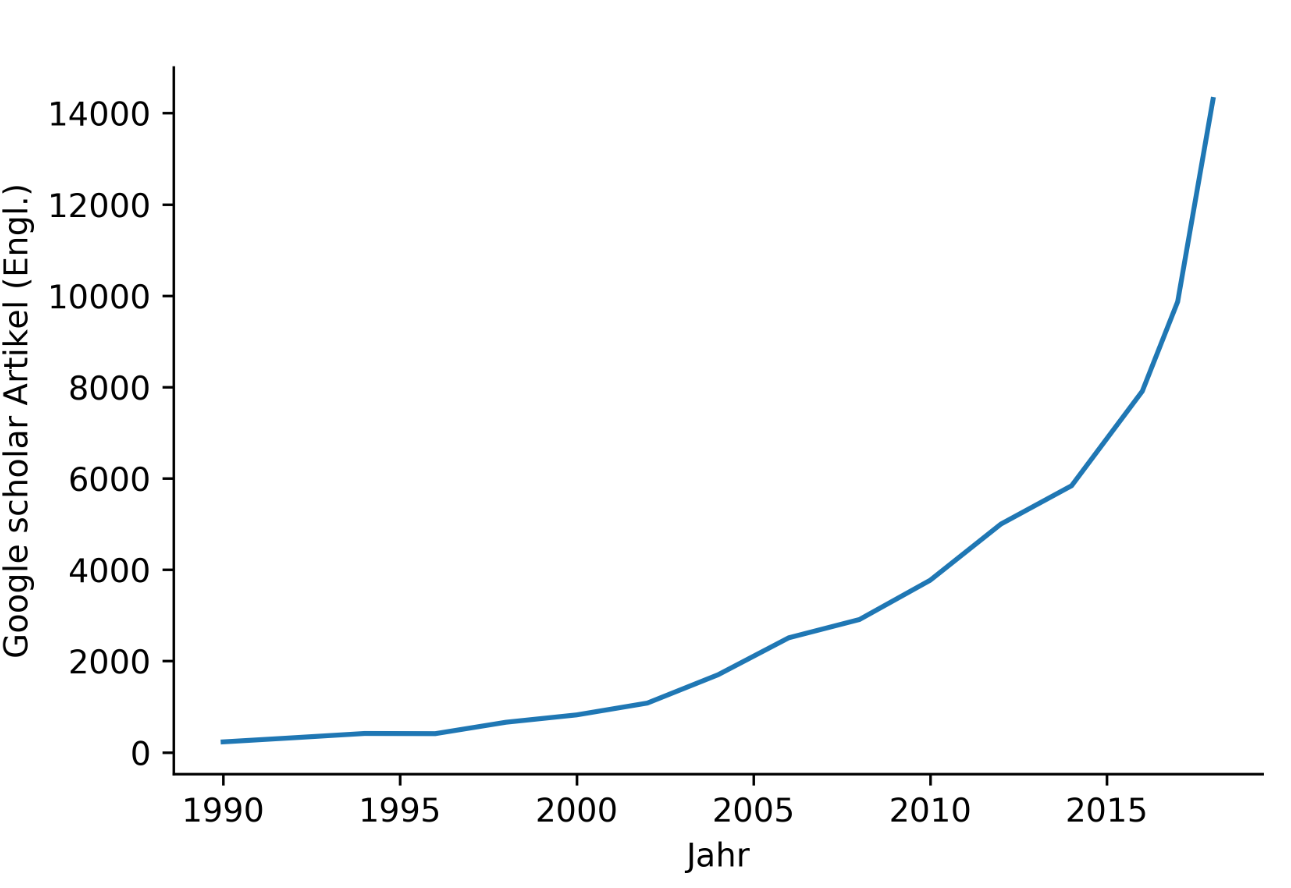
Abb. 2: Wissenschaftliche Veröffentlichungen zum Thema Erklärbarkeit bei ML werden immer zahlreicher (Daten aus Google Scholar; Grafik: Fraunhofer IPA)
Erklärbarkeit für die Praxis
Wissenschaftler am Zentrum für Cyber Cognitive Intelligence (CCI), das dem Fraunhofer IPA angehört, arbeiten an Verfahren, mit denen dieser Blackbox-Charakter von ML-Verfahren überwunden werden kann. Sie fokussieren sich auf Anwendungen im Kontext von Produktions- und Automatisierungstechnologien. Das CCI bietet insbesondere dem Mittelstand niederschwellige Angebote wie Open Lab Days und Quick Checks, also kleine Machbarkeitsstudien, um KI und ML in die Anwendung zu bringen. Nach über 80 durchgeführten Quick Checks haben die Wissenschaftler einen exzellenten Überblick über die Bedarfe und Themen, die Unternehmen zum maschinellen Lernen umtreiben. Das Thema Erklärbarkeit ist regelmäßig von Interesse.
Zwei Beispiele hierfür: Ein Engineering-Dienstleister für die Automobilindustrie arbeitet daran, Regler für Motoren mithilfe von KI zu verbessern. Für diese Geräte wurde ein neuronales Netz mithilfe von „reinforcement learning“ entwickelt. Der Lernprozess ist hierbei am Prinzip „trial and error“ ausgerichtet und der Art, wie wir Menschen lernen, sehr ähnlich. Der damit verfolgte Ansatz zur Regelung des Steuergeräts ist grundverschieden von der traditionellen Herangehensweise. Wo früher physikalisch begründbare Vorgaben Aktionen des Steuergerätes auslösten, ist jetzt nicht mehr nachvollziehbar, aufgrund welcher Rechenschritte eine Aktion erfolgt. Der Dienstleister ist nun auf der Suche nach einer Möglichkeit, den neuronalen Regler zu „übersetzen”, um die Entscheidungsgrundlagen und Aktionen transparent zu machen. Dies hilft den Ingenieuren, den Regler besser zu verstehen und den Entwicklungsprozess zu perfektionieren. Aktuell wird geklärt, ob Erklärbarkeit auch für die Abnahme beim TÜV genügen würde oder ob es dafür weiterer formaler mathematischer Verifikationen bedarf.
Bei der Bildverarbeitung – der aktuellen Paradedisziplin für den Einsatz neuronaler Netze – kann es ebenfalls einige Fallstricke geben, die die Erklärbarkeit eines Netzes unabdingbar machen. Man spricht von der „Voreingenommenheit“ eines Netzes, wenn es Bilder aufgrund von Kriterien einer Klasse von Objekten zuordnet, die nur zufällig auf einigen Bildern zu sehen sind und nicht als Kriterium dienen sollten. Beispielsweise sollen Bananen nicht nur aufgrund eines Marken-Aufklebers erkannt werden, sondern anhand der Merkmale der Frucht selbst. So wandte sich ein Kamerahersteller an das CCI mit dem Ziel, solche „Verzerrungen“ frühzeitig erkennen zu können. Um derartige Fehler aufzudecken, wird mit sogenannten Heatmaps gearbeitet: Auf den Bildern werden die Bereiche angezeigt, die für die Zuordnung des Objekts zu einer Klasse besonders relevant waren. Wird also ein Bildbereich hervorgehoben, der nicht charakteristisch für die zugeordnete Klasse ist, kann dies einen Hinweis auf die „Voreingenommenheit“ des Netzes liefern. So wird klar, dass Korrelation nicht immer auch Kausalität bedeutet.
Erklärbarkeitsansätze
Diese Heatmaps sind ein gutes Beispiel für lokale Erklärbarkeitsansätze, die nur betrachten, warum eine bestimmte Eingabe zu einer bestimmten Ausgabe führt. Ein weiteres Beispiel für lokale Erklärungen sind Kontrafakte. Diese geben an, welche Eingabemerkmale wie stark geändert werden müssten, um eine gegensätzliche Entscheidung herbeiführen zu können. Dieses Hilfsmittel macht nicht nur ML-Anwendungen verständlicher, sondern beinhaltet auch eine Handlungsempfehlung. Denn wenn ein einflussreiches Merkmal gezielt geändert wird, kann bereits ein anderes Ergebnis erzeugt werden.
Eine Möglichkeit, ein neuronales Netz global, also als Ganzes, zu erklären, ist, ein interpretierbares Stellvertretermodell aus dem Netz zu extrahieren, beispielsweise in Form eines Entscheidungsbaums (s. Abb. 3) oder von Entscheidungsregeln. Dieses Whitebox-Modell simuliert das Blackbox-Modell und trifft weitgehend gleiche Vorhersagen. Es wird nun also möglich, das Stellvertretermodell zu untersuchen, um die Entscheidungsweise des zugehörigen Netzes besser verstehen zu können. An dieser Methode arbeiten die Wissenschaftler am CCI sehr intensiv. Entscheidungsbäume [SchHuMa19] bestehen aus internen Knoten, die zu überprüfende Bedingungen definieren, und Blattknoten, die Klassen darstellen. Für ein zu klassifizierendes Datum wird der Entscheidungsbaum von oben nach unten traversiert, bis man einen Blattknoten erreicht, der die Klasse codiert.
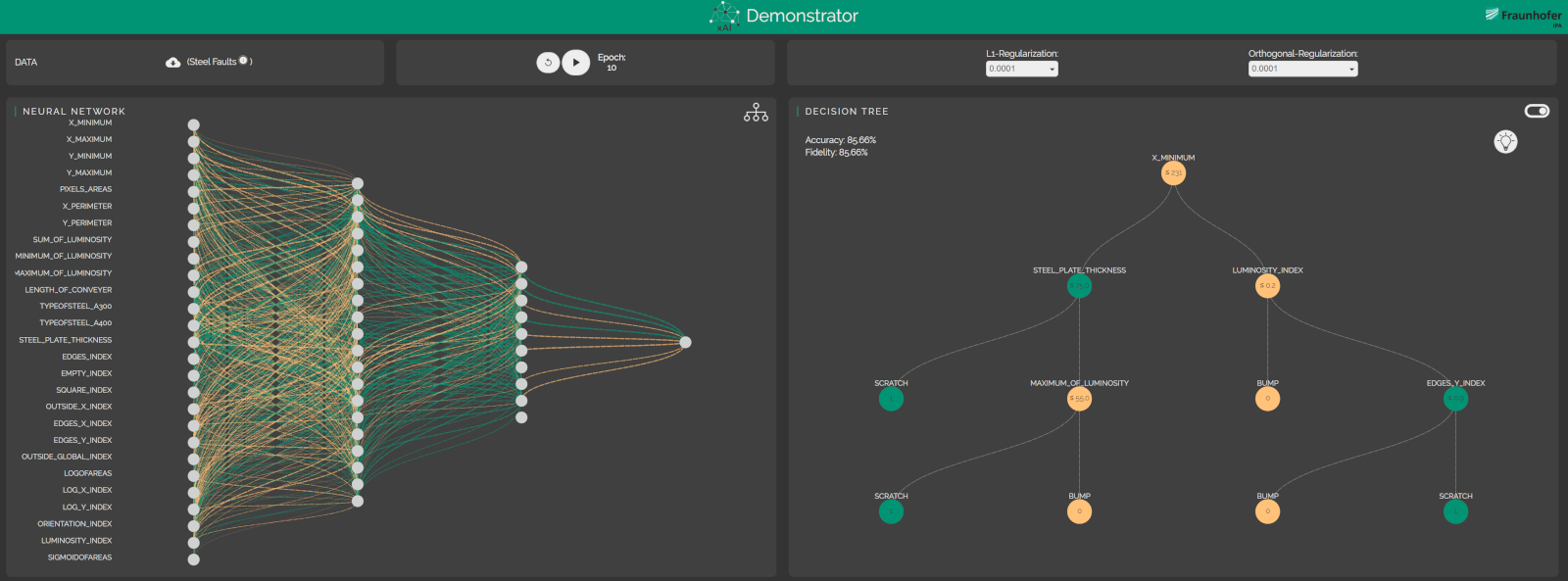
Abb. 3: Ein Entscheidungsbaum (rechts) kann ein neuronales Netz (links) vereinfacht abbilden und es so verständlicher machen. (Quelle: Fraunhofer IPA)
Konkret funktioniert die Extraktion eines Entscheidungsbaums aus einem neuronalen Netz wie folgt (s. Abb. 4): Zuerst wird unter Zuhilfenahme des Netzes für alle Eingabedaten, bestehend aus Merkmalen und einer Sollausgabe, eine Vorhersage berechnet. Im Anschluss werden die Merkmale zusammen mit der Vorhersage des neuronalen Netzes dazu verwendet, einen Entscheidungsbaum zu trainieren. Oftmals besitzen die auf diese Weise extrahierten Entscheidungsbäume eine relativ geringe Vorhersagegenauigkeit und Wiedergabetreue, das heißt, die Entscheidungen des Entscheidungsbaums stimmen oftmals nicht mit denen des neuronalen Netzes überein. Eine Möglichkeit, dieser Herausforderung zu begegnen, ist, die Struktur des neuronalen Netzes gezielt zu beeinflussen, sodass aus dem Netz extrahierte Entscheidungsbäume bestimmte Eigenschaften besitzen, zum Beispiel eine hohe Wiedergabetreue haben oder besonders klein und damit verständlicher sind.
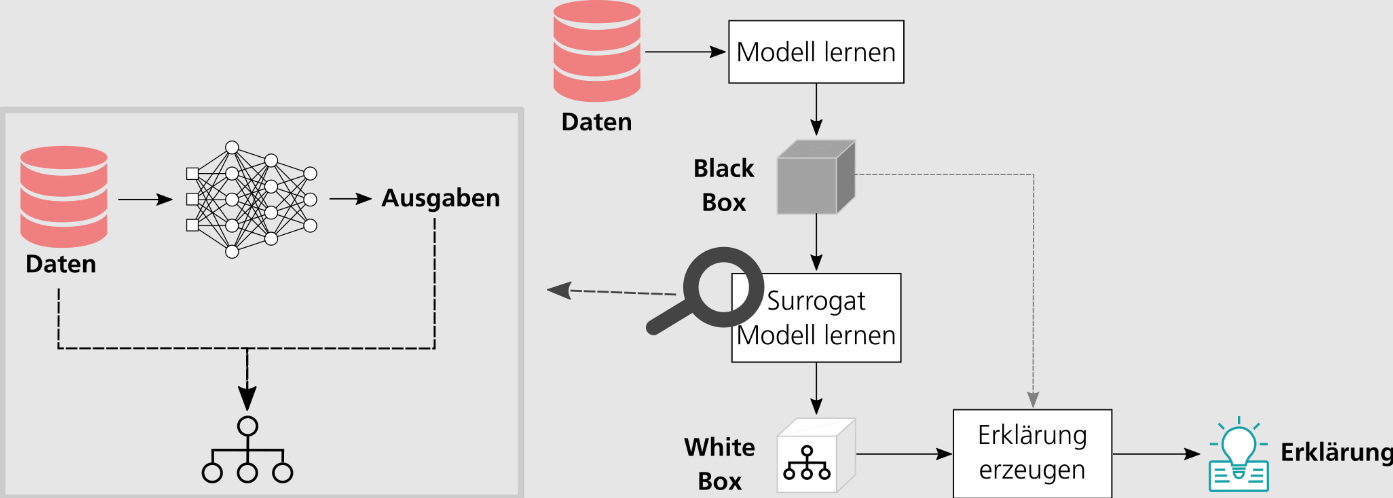
Abb. 4: Von der Blackbox zur Erklärung: Extraktion von Whitebox-Modellen aus Blackbox-Modellen
Repräsentation von Erklärungen
Neben diesem Einsatz unterschiedlichster Erklärbarkeitsmethoden wird zukünftig auch die Art und Weise, wie die erzeugten Erklärungen dem Anwender präsentiert werden, immer mehr Bedeutung zuteilwerden. Beispielsweise können Modelle visualisiert oder mithilfe von Narrativen, virtueller Realität, Animationen oder Sprachausgaben erklärt werden.
Der Vorteil: Die Repräsentation von Erklärungen kann sehr anwenderspezifisch gestaltet werden. Denn je nach Personenkreis, für den ML-Verfahren transparent gemacht werden sollen, sind Erklärungen anders zu gestalten. Ein ML-Experte möchte andere Dinge wissen als ein Fachexperte, beispielsweise aus dem Produktionsumfeld, ein Manager wiederum legt auf anderes Wissen wert als der Endnutzer. Das Fraunhofer IPA bietet maßgeschneiderte Lösungen für alle Zielgruppen.
Weitere Informationen
[BuHu21] N. Burkart, M. F. Huber, A Survey on the Explainability of Supervised Machine Learning, in: J. of Artificial Intelligence Research, 19.1.2021,
https://www.jair.org/index.php/jair/article/view/12228
[SchHuMa19] N. Schaaf, M. Huber, J. Maucher, Enhancing Decision Tree Based Interpretation of Deep Neural Networks through L1-Orthogonal Regularization, in: IROS 2019, https://ieeexplore.ieee.org/document/8999213 bzw.viaarXiv http://arxiv.org/abs/1912.12125
[SchW21] N. Schaaf, Ph. Wagner, Erklärbare KI in der Praxis. Anwendungsorientierte Evaluation von xAI-Verfahren, IPA, https://www.ki-fortschrittszentrum.de/de/studien/erklaerbare-ki-in-der-praxis.html









