

Die Nutzung von Cloud-Lösungen bietet nicht nur Kosteneinsparungen für bestehende Systeme. Tatsächlich sind einige Geschäftsmodelle erst durch die Eigenschaften von Cloud-Lösungen möglich geworden. Gerade analytische Lösungen, die mit ihren Kunden wachsen, sind ohne Cloud schwierig umzusetzen oder nur den großen Anbietern vorbehalten. Möchte zum Beispiel ein neuer Anbieter eines Analysedienstes für Händler ein Data Warehouse aufbauen, ist traditionell ein hohes Vor-ab-Investment in Infrastruktur und Lizenzen sowie Konfiguration und Tuning nötig, während dem zunächst kaum Einnahmen gegenüberstehen. Moderne Cloud-DWH-Lösungen bieten Flexibilität und minimieren das Risiko durch verbrauchsbasierte Kosten und Skalierung. Zudem werden viele Wartungsaufgaben von den Anbietern übernommen. So können neue Geschäftsmodelle mit ihren Kunden wachsen. Doch welche Cloud-DWH-Lösung ist die richtige für die eigenen Anforderungen?
Verschiedene Branchenstudien, zum Beispiel von Talend [Tal22] und Qlik [Qli22] nennen Amazon Redshift, Azure Synapse, Google BigQuery und Snowflake als die vier wesentlichen Anbieter in der noch jungen Kategorie der Cloud-DWHs. Basierend auf einer Evaluation für einen Kunden, bei dem Azure als Cloud-Lösung eingesetzt war, werden im Folgenden die zwei dort verfügbaren Cloud-DWH-Lösungen Azure Synapse und Snowflake im Hinblick auf verschiedene Varianten der Mandantentrennung diskutiert. Zur Veranschaulichung dienen drei fiktive Beispielunternehmen, die in Tabelle 1 dargestellt werden.
Varianten der Mandantentrennung
Für die Trennung von Mandanten in Datenbanken gibt es drei wesentliche Optionen, die sich darin unterscheiden, wie stark Mandanten voneinander isoliert sind [Mic22-2]. Diese sind in Abbildung 1 dargestellt und werden im Folgenden erläutert, um anschließend die Auswirkungen der gewählten Methode auf den Betrieb in Synapse beziehungsweise Snowflake zu analysieren. Welche Methode zu wählen ist, hängt von den individuellen Anforderungen bezüglich Kritikalität der Daten, regulatorischen Anforderungen etc. ab. Es sind auch hybride Szenarien möglich, die unterschiedliche Aspekte der Varianten kombinieren.
Variante 1: Mandantenspalte
In jede für Kundendaten relevante Tabelle wird eine Mandantenspalte eingefügt, um die Daten zu trennen (siehe Abbildung 1 links). Diese Methode ist in der Regel die einfachste, am besten skalierbare und kosteneffizienteste Option. Durch die gemeinsame Datenhaltung können Speicher und Rechenressourcen über die Mandanten geteilt und optimal ausgelastet werden. Gleichzeitig ist keine besondere Verwaltung der Mandanten nötig, sodass diese Lösung im Extremfall für Millionen von Mandanten skalieren kann. Transformationen werden auf allen Mandanten gleich ausgeführt. Mittels Row Level Security kann der Zugriff so gesteuert werden, dass jeder Mandant nur seine eigenen Daten sehen und bearbeiten kann.
Damit das funktioniert, muss allerdings auch das Datenmodell für alle Mandanten einheitlich sein. Kleine Unterschiede lassen sich effizient umsetzen, aber bei größeren individuellen Anforderungen der Mandanten kommt diese Methode an ihre Grenzen.
Diese Variante eignet sich für den Beispielfall Reiselust, da sie für sehr viele Tourguides skaliert.
Variante 2: Ein Objekt pro Mandant
Bei dieser Methode werden die Daten jedes Mandanten in unterschiedlichen Objekten gespeichert (siehe Abbildung 1 Mitte). So sind die Daten stärker isoliert. Die Trennung kann durch Tabellen, Schemata oder Datenbanken erfolgen. Mit dieser Methode lassen sich Unterschiede zwischen Mandanten gut abbilden. Als Nachteil ist zu bedenken, dass dabei mehr Objekte zu verwalten sind, als dies bei der Mandantenspalte der Fall ist. Bei der Trennung von Datenbanken kann eine rollenbasierte Zugriffskontrolle (RBAC) genutzt werden, um eine erweiterte Sicherheit zu bieten und die Datenzugriffsrechte je Mandant zu steuern.
Diese Variante eignet sich für den Beispielfall Capitol Versicherung. Durch Schemata können die Sparten voneinander getrennt und unterschiedliche Anforderungen berücksichtigt werden. Trotzdem sind übergreifende Abfragen über mehrere Schemata möglich.
Variante 3: Ein Account pro Mandant
Die stärkste Isolation wird durch einen eigenen Account beziehungsweise eine Bereitstellung pro Mandant erreicht (siehe Abbildung 1 rechts). Durch die Trennung nach Accounts sind automatisch auch die Objekte je Mandant separiert. Zusätzlich ist der Zugriff von einem Account auf einen anderen schwieriger als bei Datenbanken innerhalb eines Accounts. Darüber hinaus sind auf Account-Ebene Netzwerkeinschränkungen möglich, um noch mehr Sicherheit zu bieten.
Unter der stärkeren Trennung leidet jedoch die gemeinsame Nutzung von Ressourcen. Die Grundkosten je Account multiplizieren sich daher mit der Anzahl an Mandanten.
Diese Variante eignet sich für den Beispielfall RetailAnalytics, um mit den heterogenen Daten umzugehen und den Kunden die Sicherheit der maximalen Isolation zu bieten.
In Tabelle 2 werden die drei Varianten in einem übersichtlichen Vergleich einander gegenübergestellt.
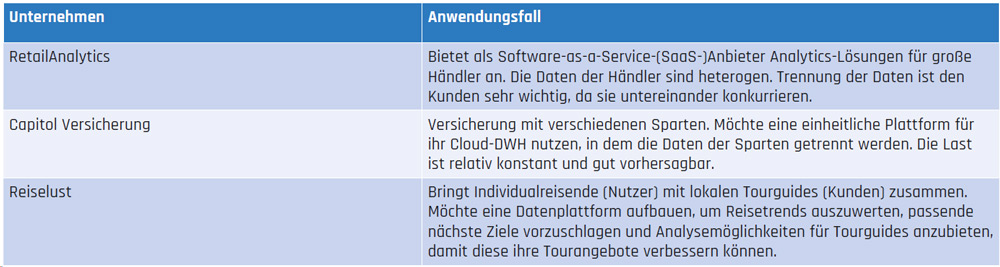
Tab. 1: Beispielunternehmen
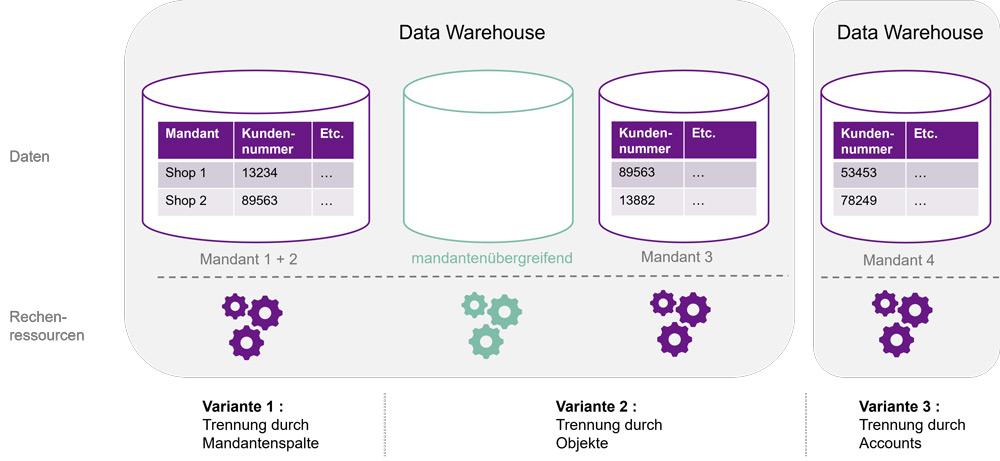
Abb. 1: Varianten der Mandantentrennung
Wie wirkt sich die Architektur des Cloud-DWH auf die Mandantentrennung aus?
Um die Auswirkungen der verschiedenen Varianten zur Mandantentrennung in der Zusammenwirkung mit dem gewählten Cloud-DWH zu verstehen, ist es wichtig, die Abrechnungsmodelle der Lösungen zu kennen. Im Folgenden werden die beiden betrachteten Lösungen Snowflake und Synapse jeweils kurz vorgestellt, um dann die Besonderheiten zu beurteilen.
Synapse
Azure Synapse ist der Enterprise Analytics Service von Microsoft, in dem verschiedene Dienste gebündelt werden. Zur Datenverarbeitung können drei verschiedene Arten von „Pools“ genutzt werden [Mic22].
- Serverless Pool: Geeignet für Ad-hoc-Abfragen auf dem Data Lake, Abrechnung nach TB verarbeiteter Daten
- Dedicated SQL Pool (zuvor SQL DW): Geeignet für typische Data-Warehouse-Lasten, schnelle Antwortzeiten und parallele Zugriffe. Abrechnung nach Data Warehouse Units (DWU) / Stunde
- Spark-Pool: Geeignet für komplexe Verarbeitungen. Weniger optimal für viele kleine Anfragen. Abrechnung nach Nodes / Minute
Da in diesem Artikel typische DWH-Lasten mit parallelen Zugriffen im Fokus liegen, wird hier der Dedicated SQL Pool näher betrachtet. Speicherkosten im SQL-Pool werden gerundet auf das nächste TB berechnet. Die Abrechnung der dedizierten DWUs erfolgt auf stündlicher Basis. Dabei sind auch angefangene Stunden zu bezahlen.
Diese ist jedoch bisher nicht vollautomatisch möglich und kann mehrere Minuten dauern, in denen es für Nutzer zu einer Einschränkung der Verfügbarkeit kommt. Eine regelmäßige geskriptete Skalierung ist daher nur für Szenarien zu empfehlen, bei denen es große Unterschiede zwischen den Lasten einer nächtlichen Batch-Verarbeitung und täglichen Zugriffen gibt. Gleiches gilt für das Starten und Stoppen eines Pools. Daher ist es nötig, für Lastspitzen etwas mehr Ressourcen bereitzustellen, als im Schnitt nötig sind, und diese im produktiven Einsatz dauerhaft angeschaltet zu lassen. Möchte man die Kosten im Produkt an die Kunden weiterverrechnen, bietet sich aufgrund dieser Eigenschaften ein pauschaler Ansatz an.
Bei der Speicherung der Mandanten-Daten in verschiedenen Datenbankschemata (Variante 2) kann der RBAC-Ansatz zur besseren Absicherung verwendet werden, während sich die Mandanten die Speicher und die Rechenleistung weiter effizient teilen können. Bewegt man sich ohnehin im Azure-Ökosystem, ist die tiefe Integration ins Azure Active Directory von Vorteil, da die vorhandene Rechteverwaltung einfach um die Elemente des Synapse DWH erweitert werden kann. Ein SQL-Pool entspricht einer Datenbank. Eine Trennung nach Pools/Datenbanken führt daher neben einer noch stärkeren Abgrenzung der Daten auch zu einer Isolation der Rechenoperationen der Mandanten (Abbildung 2 Mitte). Da, wie bereits im vorigen Absatz beschrieben, die SQL-Pools im produktiven Einsatz dauerhaft aktiv sein müssen, wachsen die Kosten linear mit der Anzahl der Mandanten. Ein lineares Wachstum ergibt sich unter der Annahme, dass alle Mandanten einen ähnlichen Ressourcenbedarf haben. Durch die Trennung der SQL-Pools ist es aber auch möglich, einigen Mandanten Rechenressourcen mit mehr oder weniger DWUs zuzuweisen.
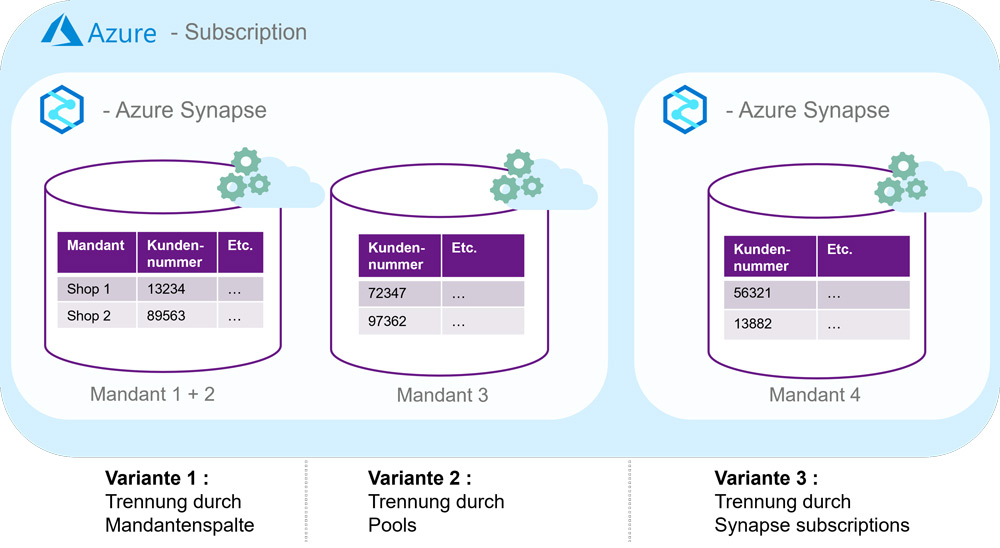
Abb. 2: Mandantentrennung in Azure Synapse
Eine noch stärkere Trennung der Mandanten wird erreicht, indem eine Synapse Subscription (Abbildung 2 rechts) und darin ein SQL-Pool je Mandant eingerichtet werden (Variante 3). Auf dieser Ebene können zusätzlich Netzwerkverbindungen eingeschränkt werden. Die Kosten sind vergleichbar mit der zuvor beschriebenen Trennung nach Pools/Datenbanken. Jedoch lassen sich in Azure viele Features zur Netzwerkisolierung und punktuellen Öffnung (zum Beispiel VNETs und Private Links) ohne große Zusatzkosten nutzen. Bei Snowflake ist für die Nutzung dieser Sicherheitsfunktionen eine höhere Edition (Business-Critical) nötig, die sich auf die gesamten Rechenkosten auswirkt.
Durch die langfristige Reservierung von Kapazität sind deutliche Rabatte möglich. Die Rabatte wirken auch über mehrere Subscriptions innerhalb eines Microsoft-Kontos hinweg, sodass sie auch bei einer Mandantentrennung mit höchster Isolation wirken.
Snowflake
Snowflake wurde von Anfang an für die Cloud konstruiert und kann damit als Cloud-nativ bezeichnet werden. Es läuft auf allen drei großen Public-Cloud-Providern und setzt auf den unterliegenden Services für Blob Storage (zum Beispiel Azure Data Lake Storage) sowie der flexiblen Bereitstellung von Rechenressourcen auf. Die Abrechnung erfolgt vollständig verbrauchsabhängig [Sno22]:
- Speicherkosten werden je TB berechnet, im Gegensatz zu Synapse aber nicht auf das nächste TB gerundet. Ein DWH mit wenigen GB verursacht nur einige Cent pro Monat an Speicherkosten.
- Rechenleistung kann ad hoc skaliert werden und wird sekündlich abgerechnet, wobei mindestens eine Minute anfällt. Der genaue Preis hängt neben der Größe der Rechenleistung auch von der gewählten Edition ab.
Bei der einfachsten Variante der Mandantentrennung (Abbildung 3 links) durch eine Mandantenspalte punktet Snowflake mit der Flexibilität virtueller Warehouses. So können Multi-Cluster Warehouses automatisch weitere Ressourcen bereitstellen, wenn Lastspitzen auftreten, und diese wieder zurückfahren, sobald die Last geringer wird, um Kosten zu sparen. Dieses Feature eignet sich zum Beispiel gut für den Beispielfall von Reiselust, bei dem stark variierende Lasten zu erwarten sind. Da virtuelle Warehouses in deutlich unter einer Sekunde starten, kann man sogar auf 0 herunterskalieren und trotzdem gute Antwortzeiten bieten. Möchte man die Kosten verursachungsgerecht weitergeben, lassen sich diese bei gemeinsam genutzten virtuellen Warehouses zwar nicht genau, aber näherungsweise anhand der Query-Historie ermitteln.
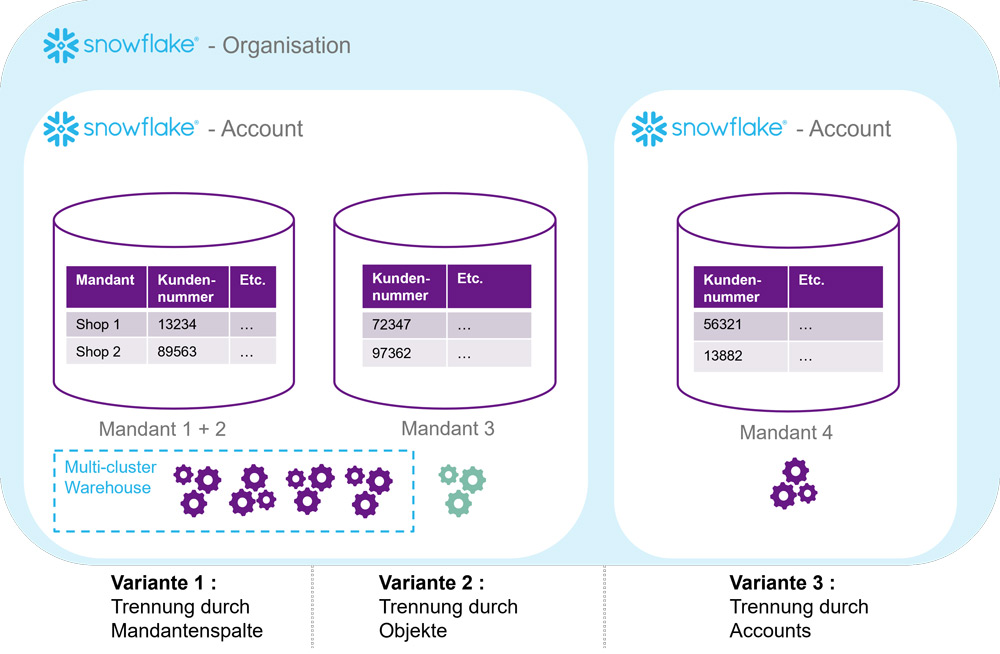
Abb. 3: Mandantentrennung in Snowflake
Aufgrund der genauen Abrechnung der Speicherkosten führt eine Trennung nach Objekten pro Mandant (Variante 2) nicht zu signifikanten Mehrkosten (Abbildung 2 Mitte). Rechenleistung in Form virtueller Warehouses kann auch in dieser Variante noch über Mandanten geteilt werden, wahlweise können auch dedizierte Ressourcen pro Mandant bereitgestellt werden. So wird eine höhere Isolation erreicht und die Kosten sind leicht zurechenbar. Durch die geringere Ressourcenteilung entstehen Mehrkosten, die durch die Elastizität aber eher geringer ausfallen als bei Synapse. Je weniger kontinuierlich die tatsächlichen Lasten sind (zum Beispiel Peaks am Morgen und am frühen Nachmittag mit ruhigen Phasen dazwischen), desto positiver wirkt sich das Abrechnungsmodell von Snowflake gegenüber Synapse aus
In Snowflake können auf der obersten Hierarchieebene der „Organisation“ verschiedene Mandanten-„Accounts“ angelegt werden, die in sich geschlossene Datenbanksysteme mit eigenen Datenbanken darstellen und eine einfache Verwaltung der maximal getrennten Mandanten (im Sinne von Variante 3) ermöglichen (Abbildung 3 rechts). Da die Rechenleistung keine Grundkosten verursacht, sind die Kosten für diese höchste Variante der Isolation nicht höher als eine Trennung von Objekten pro Mandant mit zusätzlicher Trennung der Rechenleistung durch individuelle virtuelle Warehouses.
Auch bei Snowflake sind durch Vorabzahlung Rabatte möglich. Diese sind individuell zu verhandeln.
Mandantenübergreifende Abfragen
Neben der Isolation von Verarbeitungen von Mandanten kann eine Dienstleistung auch die Bereitstellung von übergreifenden Abfragen sein. Im Beispielfall RetailAnalytics könnten den Händlern auf Basis aggregierter Daten Benchmarks zur Verfügung gestellt werden, anhand derer ein Vergleich mit dem Marktschnitt ermöglicht wird.
Je nach gewähltem Ansatz sind dazu zusätzliche Objekte beziehungsweise ein zusätzlicher Account für diese mandantenübergreifenden Daten(-verarbeitungen) nötig. Da im Beispielfall RetailAnalytics die Trennung durch einen Account pro Mandant zu empfehlen ist, wird für die übergreifenden Benchmarks ein weiterer Mandant benötigt.
Bei Synapse fallen für den übergreifenden Mandanten zusätzliche Kosten für den Speicher und die relativ hohen Grundkosten für die festen Laufzeiten des SQL-Pools an.
Snowflake bietet mit Secure Data Sharing (Abbildung 4) die Möglichkeit, Daten selektiv und gesichert zwischen Accounts zu teilen. Die Daten werden dabei nicht erneut gespeichert, sodass keine zusätzlichen Kosten anfallen, sofern sich die Accounts in derselben Region befinden.
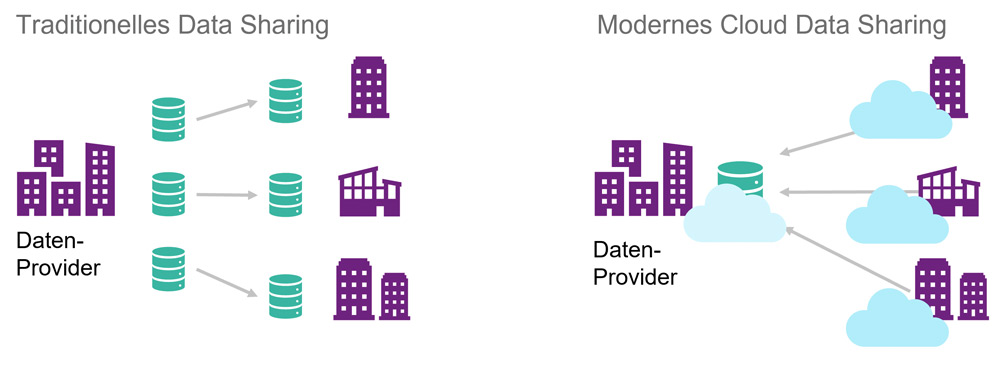
Abb. 4: Data Sharing in Snowflake
Microsoft bietet mit Azure Data Share ebenfalls einen Dienst an, mit dem ein Datenaustausch leicht konfiguriert werden kann. Für Synapse werden aktuell nur Snapshots unterstützt [Mic22-3], für deren Ausführung zusätzliche Kosten anfallen. Ein In-Place Data Sharing, wie es von Snowflake angeboten wird, wird bisher nur für den Azure Data Explorer unterstützt. Möglicherweise kann es zukünftig auf weitere Dienste ausgeweitet werden.
Sollen Daten über Cloud-Regionen hinweg repliziert werden, fallen dafür sowohl bei Synapse als auch bei Snowflake zusätzliche Kosten an. Wie im vorigen Kapitel beschrieben, hängt es vom Abfrageprofil ab, ob durch die elastischere Abrechnung bei Snowflake auch tatsächlich weniger Kosten anfallen.
Fazit
Der Betrieb von Multi-Mandantenanwendungen zeigt, wie wichtig es ist, die Elastizität und das Kostenmodell der Cloud-Plattform sowie das eigene Geschäftsmodell im Blick zu behalten. Ist das Wachstum eher kontinuierlich und gut planbar? Oder ist es volatil und die Lasten schwer einzuschätzen? Vor allem bei hohen Anforderungen an die Isolation von Mandanten können sich die Grundkosten stark multiplizieren. Besonders Cloud-native Lösungen wie Snowflake spielen hier ihre Stärken aus und helfen so, bei hoher Isolation und Sicherheit kosteneffizient zu bleiben.
Bezogen auf die Beispielfälle ist bei der Capitol Versicherung mit ihren vorhersehbaren Lasten kein großer Vorteil durch Elastizität zu erwarten. In den Fällen Reiselust und RetailAnalytics hingegen können die elastische Skalierung und die Vermeidung weiterer Grundkosten durch Data Sharing deutliche Vorteile bieten.
In diesem Artikel liegt der Fokus auf dem Kostenmodell von Synapse und Snowflake im Hinblick auf Mandantentrennung. Neben den Kosten können für die individuelle Entscheidung, welche Plattform für den eigenen Anwendungsfall die richtige ist, aber auch andere Aspekte ausschlaggebend sein, wie zum Beispiel die enge Integration von Synapse in das Azure-Ökosystem. Da ein Cloud Data Warehouse das Herzstück moderner Datenarchitekturen darstellt, sollte die Auswahl wohlüberlegt getroffen werden.
Weitere Informationen
[Mic22]
Microsoft: Azure Synapse SQL architecture. 25.5.2022,
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/overview-architecture, abgerufen am 30.5.2022
[Mic22-2]
Microsoft: Multi-tenant SaaS database tenancy patterns. 26.4.2022,
https://docs.microsoft.com/en-us/azure/data-share/supported-data-stores, abgerufen am 30.5.2022
[Mic22-3]
Microsoft: Supported data stores in Azure Data Share. 16.12.2021,
https://docs.microsoft.com/en-us/azure/data-share/supported-data-stores, abgerufen am 30.5.2022
[Qli22]
Qlik: Cloud Date Warehouse Guide. 2022,
https://www.qlik.com/us/cloud-data-migration/cloud-data-warehouse#:~:text=A%20cloud%20data%20warehouse%20is,analytics%20and%20reporting%20for%20decades, abgerufen am 30.5.2022
[Sno22]
Snowflake: Key Concepts & Architecture. 2022,
https://docs.snowflake.com/en/user-guide/intro-key-concepts.html, abgerufen am 30.5.2022
[Tal22]
Talend: Der ultimative Leitfaden zu Cloud-Data-Warehouses und Cloud-Data-Lakes. 2022,
https://www.talend.com/de/resources/definitive-guide-cloud-data-warehouses/, abgerufen am 30.5.2022









