

Hierbei ist vor allem Wissen über den Kunden und seine Bedürfnisse gefragt, um mit individueller persönlicher Beratung den höchsten Verkaufsabsatz zu generieren. Dabei wird gerne auf die Verkaufshistorie des Kunden zurückgegriffen, die digitalisiert bereits zur Verfügung steht. Wenn diese jedoch fehlt – zum Beispiel bei Neukunden – oder neuen Mitarbeitern der Einstieg ins Gespräch nicht so leichtfällt, kann eine datengetriebene Lösung dabei zielgerichtet unterstützen. Hierzu wird aus dem Wissen des Kaufverhaltens aller Kunden profitiert, um ein „analoges“ Verkaufsgespräch mit individuellen, datengetriebenen Produktvorschlägen anzureichern. Per Knopfdruck erhält der Außendienstmitarbeiter Produktvorschläge, die aus Datensicht am besten zum Kunden passen. Ausschlaggebend sind hierfür die Branche sowie die Unternehmensgröße des Kunden. Die Besonderheit: Der Kunde hat diese Produkte noch nie zuvor gekauft. Somit profitieren auch erfahrene Mitarbeiter von den mit Machine Learning erzeugten Produktvorschlägen.
„Kunden, die gekauft haben, kauften auch …“ – jeder kennt heutzutage die Vorschlagsreihe an Produkten aus diversen Online-Shops. Sie helfen den Kunden, den Überfluss an Informationen zu filtern, und dienen gleichzeitig dem Händler dazu, Mehrumsatz zu generieren und Kunden langfristig an das Unternehmen zu binden. Im Online-Vertrieb sind Empfehlungen zahlreich vertreten, doch wie sieht es im Direktvertrieb aus?
Bei langjähriger Erfahrung weiß der Außendienstmitarbeiter, welche Produktpalette seine Kunden benötigen. Die Verkaufshistorie dient zudem als oft genutzte Einstiegshilfe ins Verkaufsgespräch. Wenn diese fehlt, die Nachfrage der zuletzt gekauften Produkte beim Kunden ausbleibt oder auch Prospekte kein Interesse beim Kunden wecken, sind datengetriebene Produktvorschläge die Lösung für ein schnelles, neues und individuelles Verkaufsangebot.
Dabei liegt der Fokus nicht auf ähnlichen Produkten im Portfolio des Unternehmens (Wer Schrauben kauft, benötigt einen Schraubendreher), sondern auf der Verkaufshistorie jedes einzelnen Bestandskunden. Abhängig davon, was Kunden mit ähnlicher Größe und gleicher Fachrichtung kaufen und was noch nie im Warenkorb des Kunden lag, entsteht eine jeweils individuelle Menge an Produkten als Basis der Produktempfehlungen. Anhand eines datengetriebenen Rankings werden schlussendlich zehn Produkte pro Kunde ausgewählt, die am besten zum Kunden passen.
Bei den täglichen Kundenbesuchen bekommen die Vertriebsmitarbeiter somit für jeden Kunden ein neues Angebot. Da der Kunde die Produkte bisher noch nie gekauft hat, bieten diese Vorschläge auch für erfahrene Außendienstmitarbeiter eine zeitsparende Möglichkeit, das Kaufsortiment ihrer Kunden zu erweitern. Um auch Neukunden von Anfang an passend zu betreuen, werden Produktvorschläge basierend auf ihrer jeweiligen Branche generiert und dem Außendienstmitarbeiter angezeigt.
Die Kombination von menschlichem und datengetriebenem Wissen ermöglicht eine individuelle Betreuung jedes einzelnen Kunden.
Der Algorithmus im Detail
Das Kaufverhalten aller Kunden liefert dem Algorithmus die Datenbasis. Da das Produktportfolio stark von der jeweiligen Branche des Kunden abhängt (der Dachdecker verwendet die Stichsäge eher als der Automechaniker), sind neben den gekauften Produkten auch die Unternehmensgröße sowie die dazugehörige Branche des jeweiligen Kunden zentraler Bestandteil der Datengrundlage. Jedoch gibt es, abgesehen von der Verkaufshistorie, nur wenig zusätzliche Informationen über die Käufer. So gibt es zum Beispiel kein direktes Kundenfeedback in Form von Produktbewertungen wie bei Amazon oder Netflix oder Interessensbekundung durch „Page Visits“ wie in einem Online-Shop. Demnach arbeitet der Empfehlungsalgorithmus nur mit implizitem Feedback, er bewertet also nur die Kundeninteraktion mit den Artikeln gemäß dem Kaufverhalten [Hah16]. Als Algorithmus wird dazu eine Matrix-Faktorisierung mit Alternating Least Squares verwendet [Ras19].
Matrix-Faktorisierung einfach erklärt
Kunden und Artikel können bei der Matrix-Faktorisierung gleichwertig gewichtet und eingebunden werden. Was bedeutet das im Detail? Angenommen, ein Produkt kann durch eine Reihe von Anwendungsgebieten beschrieben werden. Zum Beispiel wird die Säge A für Metall, Kunststoff und Holz verwendet. „Firma Mustermann“ ist ein Kunde, der Metall, Kunststoff und Holz verarbeitet. Den drei Kategorien können nun Werte zwischen 0 und 1 zugewiesen werden, wobei 0 bedeutet, dass die Kategorie nicht zutrifft und 1 voll zutrifft. Beispielsweise hätte Säge A einen Wert von 0,8 auf Metall (also bestens geeignet für Metall), 0,35 auf Kunststoff (nicht gut geeignet für Kunststoff) und 0,6 auf Holz (geeignet für Holz, wenn auch nicht perfekt). Weiterhin spielen die Werte der Firma Mustermann zu den drei Kategorien eine Rolle. Firma Mustermann verarbeitet besonders viel Metall (0,9); Kunststoff (0,45) und Holz (0,7) werden zwar verarbeitet, aber es herrscht deutlich weniger Bedarf. Ein Vergleich der Werte des Produkts und der des Kunden mit Hilfe des Skalarprodukts ergibt letztendlich einen Wert, der aussagt, wie gut die Säge A zur Firma Mustermann passt. Hier ergibt sich ein Wert von
(0,9 0,45 0,7) • (0,80 0,35 0,6) = 1,29
Je höher dieser Wert, desto besser passt das Produkt zum Kunden. Die analoge Berechnung für andere Produkte ergibt schlussendlich eine Kundenpräferenz je Produkt.
Matrix-Faktorisierung mit Alternating Least Squares
Aufgrund der vorhandenen Datenlage ist dieser Ansatz hier nicht direkt möglich, da nicht für jeden Kunden und jedes Produkt die Werte aller Kategorien zur Verfügung stehen. Daher weist man allen Kunden und Produkten eine Anzahl von (latenten) Kategorien zu. Dies wird durch Matrix-Faktorisierung mit „Alternating Least Squares“ erreicht [Res15]. Hierbei wird eine Datenmatrix (R) erstellt (vgl. Abbildung 1), deren Einträge ausschließlich aus Nullen und Einsen bestehen, wobei jedes Produkt, das von einem Kunden gekauft wurde, eine Eins und bei Nicht-Kauf eine Null erhält. Das bedeutet jedoch nicht, dass bei Nichtkauf der Kunde das Produkt nicht „mag“, sondern lediglich, dass der Kunde für das Produkt noch kein Interesse geäußert hat. Desinteresse, Indifferenz oder Unkenntnis gegenüber dem Produkt sind beispielhafte Gründe hierfür [Hah16].

Abb. 1: Prozess einer Matrix-Faktorisierung (Screenshot)
Die Datenmatrix R ist sparse (spärlich gefüllt), da jeder Kunde nur mit vergleichsweise wenigen Produkten interagiert. Diese Matrix (R) kann in zwei Matrizen (U und V) aufgeteilt werden: Sie werden faktorisiert (vgl. Abbildung 1). Die Matrix U beinhaltet die Kunden mit den latenten Faktoren, die Matrix V die Produkte mit denselben latenten Kategorien. Die Matrizen U und V werden nun mit Hilfe von „Alternating Least Squares“ (ALS) gelöst. ALS startet mit zufälligen Einträgen in der Kundenmatrix U, um die Produktmatrix V zu generieren. Anschließend wird V konstant gehalten, um die Kundenmatrix U zu lösen. Dies wird so lange wiederholt, bis eine beste Annäherung an die Ursprungsmatrix R erreicht ist [Res15].
Durch Multiplikation der Matrizen U und V wird annähernd die Originalmatrix R erhalten, zusätzlich ist nun jedoch jede Kunde-Produkt-Kombination mit einem Wert gefüllt (vgl. Abbildung 2). So entsteht eine Vorhersage für jede Kunde-Produkt-Interaktion, auch wenn es vorher noch keine Interaktion gegeben hat. Dieser Prozess kann gut parallelisiert werden, da immer nur ein Vektor gelöst wird [Ras19]. Zusätzlich sind die Kunde-Produkt-Interaktionen voneinander unabhängig, somit können Delta-Prozesse klein gehalten werden, ohne die kompletten Kategoriematrizen neu aufzubauen. In diesem Fall werden nur die betroffenen Kunden und Produkte aktualisiert.

Abb. 2: Beispiel einer Matrix-Faktorisierung (Screenshot)
Damit können die am besten zum Kunden passenden Produkte generiert und schlussendlich ausgespielt werden (vgl. Abbildung 3), auch wenn der Kunde sie zuvor noch nie gekauft hat.

Abb. 3: Anzeige der Produktempfehlungen im Berner Customer Connect (Screenshot)
Gezeigt wurde das Beispiel einer Kunde-Artikel-Interaktion. Mit der Methodik ist es aber auch vorstellbar, ähnliche Produkte zu finden, indem man die Produktmatrix V mit sich selbst multipliziert. Auch Kundenähnlichkeiten sind durch die Multiplikation der Kundenmatrix U mit sich selbst möglich. Um die Datenlage der Interaktionen zu verbessern, sind zukünftig auch „weiche“ Faktoren geplant. Hierbei werden den latenten Faktoren Gewichte zugewiesen. Merklisten oder abgebrochene Warenkörbe können hier zum Beispiel als Basis verwendet werden. Dadurch erhöht sich die Qualität der Empfehlungen.
Für Neukunden ohne Verkaufshistorie generiert ein separater Algorithmus Empfehlungen anhand der meistverkauften Produkte pro Branche. Der gesamte Prozess von der Generierung bis hin zur Ausspielung der Produktvorschläge im Berner Customer Connect, dem CRM-System des Außendienstmitarbeiters (Abbildung 3), läuft vollkommen automatisiert.
Um ein Produkt nicht mehrfach in verschiedenen Normen und Abmessungen anzuzeigen, wie zum Beispiel eine größere Anzahl an Ausgleichsgewichten unterschiedlicher Gewichte/Abmessungen, wird nur auf der Kategorie des Produkts gerechnet und dieses auch nur in einer Abmessung ausgespielt. Bei Bedarf lässt sich diese Anzeige jederzeit individuell an den Kunden anpassen und zum Beispiel das Ausgleichsgewicht in der jeweiligen Gewichtsklasse einfach auswählen (Abbildung 4).
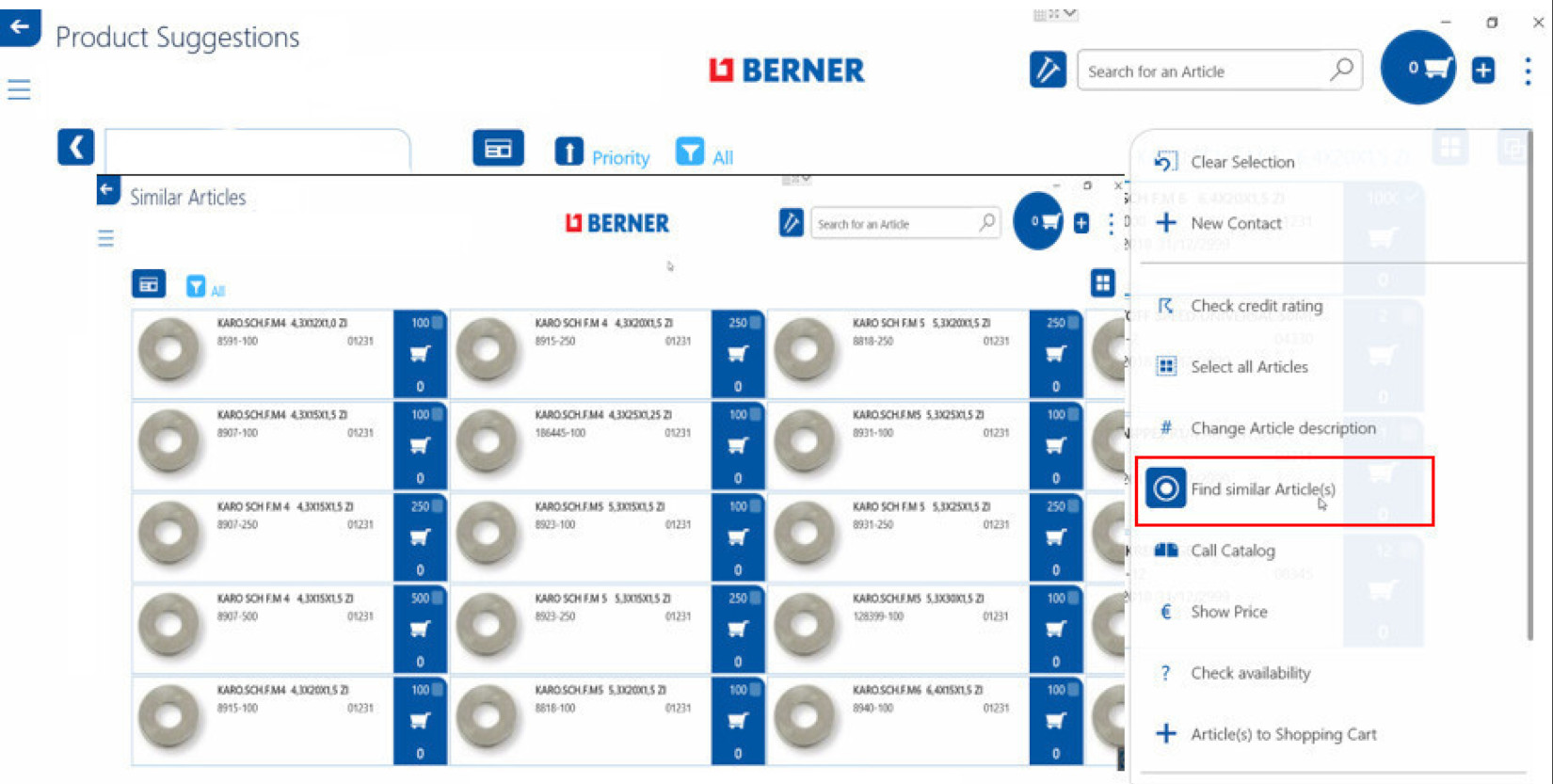
Abb. 4: Anzeige ähnlicher Produkte eines Vorschlags im Berner Customer Connect (Screenshot)
Bewusste manuelle Steuerung
Die Verkaufshistorie bietet zwar eine immense Datengrundlage für den Algorithmus, individuelles Kundenwissen oder Strategien des Unternehmens bleiben hierbei jedoch komplett außen vor. Bewusst gibt es somit verschiedene Möglichkeiten, Produkte aus den Empfehlungen auszuschließen, auch wenn diese vom Ranking her gut zum Kunden passen.
Zum einen können die Sales Manager jährlich Produkte mit Hilfe einer Blacklist komplett ausschließen sowie eine untere Grenze für die Marge des Produkts festlegen. Ist ein Produkt nicht margenstark genug oder fällt es unter die Blacklist, wird es nach der Berechnung herausgefiltert und dem Kunden das nächstbeste Produkt angezeigt. Die Qualität der Empfehlungen verschlechtert sich somit zwangsläufig bis zu einem gewissen Grad.
Ein individuell berechnetes Gütemaß verhindert hierbei jedoch explizite Produktplatzierungen. Hierfür werden die höchsten zehn ungefilterten Werte der Kunde-Produkt-Interaktionen aus dem Ergebnis der Matrix-Faktorisierung für jeden Kunden ausgelesen. Jedem Kunden werden somit zehn Produkte mit dazugehörigen Werten zugewiesen, die am besten zu ihm passen. Werden anschließend Produkte herausgefiltert, rücken die nächstbesten Produkte mit niedrigeren Werten nach. Die höchsten zehn Werte der gefilterten Produkte werden mit den ungefilterten Werten verglichen.
Weichen diese Werte zu stark voneinander ab, verschlechtert sich die Empfehlung deutlich. Um dies zu verhindern, muss der Filter somit nachträglich angepasst werden. Auf diese Weise wird das manuelle Eingreifen in den datengetriebenen Prozess begrenzt.
Ein weiterer Schwerpunkt liegt auf der Saisonalität der Produkte. Je nach Jahreszeit gibt es einen unterschiedlichen Bedarf beim Kunden, der entsprechend berücksichtigt wird: Die Nachfrage nach Eiskratzern hat ihren Höhepunkt natürlich im Winter, während Insektenspray vermehrt im Sommer genutzt wird.
Der Fokus liegt hierbei jedoch weniger auf den offensichtlich von den Jahreszeiten abhängigen Produkten, die sowohl den Kunden als auch den Mitarbeitern bekannt sind. Das Hauptinteresse gilt den auf den ersten Blick nicht erkennbaren Saisonalitäten. Diese lassen sich ebenfalls mit Hilfe von maschinellem Lernen bestimmen: Eine Clusteranalyse über alle Produktverkäufe in den letzten Jahren zeigt, ob die jeweilige Nachfrage in einigen Monaten überdurchschnittlich war, und ordnet im jeweiligen Fall dem Produkt eine oder mehrere Saisonalitäten zu.
Generiert der Algorithmus einen Produktvorschlag, für den eine Saison aus datengetriebener Sicht erkennbar ist, wird das Produkt ausschließlich in der jeweiligen Saison als Vorschlag angezeigt. Produkte außerhalb ihrer Saison werden gleichermaßen nach der Berechnung herausgefiltert.
Aktualisierung der Vorschläge
Grundlegend beinhalten die auf Länderebene individuell durchgeführten Aktualisierungen der Vorschläge eine initiale Berechnung für alle Kunden, die im vergangenen Jahr mindestens fünf unterschiedliche Produkte kauften. Für Neukunden liegt der Fokus auf den meistverkauften Produkten der Branche.
Wöchentlich erneuert der Algorithmus Produktvorschläge für alle Kunden, die innerhalb der letzten sieben Tage etwas kauften. Da Kunden mit ihrem Kaufverhalten die Empfehlungen ihrer Branche beeinflussen, erhalten inaktive Kunden ohne Produktkäufe und Aufträge quartalsweise neue Produktvorschläge. Im analogen Rhythmus erfolgt die Neuberechnung der Vorschläge aller Neukunden.
In der Praxis
Die Produktempfehlungen gelten in der gesamten Berner Group als hilfreiches und gerne genutztes Feature. Dennoch bleibt die Vertrauensgewinnung in die datengetriebene Lösung mitunter eine große Herausforderung bei der Nutzung, gerade in Hinsicht auf erfahrene Mitarbeiter. Hierbei spielt es unter anderem eine Rolle, dass auch im maschinellen Lernen Ungenauigkeiten auftreten und zu fehlerhaften Ergebnissen führen können. Daher ist regelmäßiges Feedback sowie eine Bewertung von eventuell nicht optimal zum Kunden passenden Produktvorschlägen gerade bei erfahrenen Außendienstmitarbeitern beim Verkaufsgespräch essenziell, um letztendlich mit der Kombination aus menschlichem und datengetriebenem Wissen die beste Verkaufsstrategie zu erzielen. Auf diese Weise generiert die Berner Group seit Beginn der Ausspielungen einen Anteil ihres Umsatzes mit datengetriebenen Empfehlungen.
Fazit
Neben der Verbesserung der Empfehlungsqualität liegt der Fokus auch in Zukunft auf dem verstärkten Einsatz von Produktempfehlungen im täglichen Verkaufsgespräch. Jedoch kann die datengetriebene Lösung keinesfalls die menschliche Erfahrung ersetzen. Ziel der maschinell erstellten Produktvorschläge ist es also nicht, auf das Wissen des Außendienstmitarbeiters zukünftig komplett verzichten zu können. Der Mehrwert des datengetriebenen Wissens dient somit ausschließlich zur Unterstützung für jeden Außendienstmitarbeiter im täglichen Verkaufsgespräch und ist eine gute Möglichkeit, um von der Digitalisierung auch im Direktvertrieb zu profitieren.
Weitere Informationen
[Hah16]
Hahsler, Michael: recommenderlab: A Framework for Developing and Testing Recommendation Algorithms. 2016,
https://cran.r-project.org/web/packages/recommenderlab/vignettes/recommenderlab.pdf, abgerufen am 10.5.2021
[Res15]
Reshef, Roi: How do you build a “People who bought this also bought that”-style recommendation engine. Dezember 2015,
https://datasciencemadesimpler.wordpress.com/tag/alternating-least-squares/, abgerufen am 10.5.2021
[Ras19]
Rasp, David: How To Implement Alternating Least Squares In R. Februar 2019,
https://raspository.com/alternating-least-squares, abgerufen am 10.5.2021









