

Bei Apache Lucene handelt es sich um eine Open-Source-Software fürs Suchen. Lucene erlaubt es, vereinfacht gesagt, schnell und komfortabel in irgendwelchen Dokumenten zu suchen. Das Besondere ist dabei, dass das Core-Projekt lediglich aus einer JAR-Datei mit 3,6 MByte besteht. Dabei gibt es sogar Schnittstellen zu verschiedenen anderen Sprachen wie zum Beispiel Python.
Lucene ist so mächtig und performant, dass es zum Beispiel in Form von Elasticsearch bei Wikipedia verwendet wird [WIK]. Wer also in einer Applikation Dokumente durchsuchen möchte, sollte weiterlesen.
Der Start von Lucene
Wie immer musst du zunächst einmal Lucene hier herunterladen. Um zu testen, holt man sich in der Regel erst einmal nur das Paket mit den Binaries. Hier aber solltest du zusätzlich auch das Paket mit den Sourcen herunterladen. Warum? Zu der eigentlichen core.jar-Datei enthält das Archiv eine eigene jar-Datei mit Demos. Diese sind ein wirklich guter Einstieg in das Thema. Und da wir uns hier ja auch die Entwicklung ansehen wollen, bietet es sich an, dies mithilfe der Demos zu machen.
Das erste Indizieren von Dateien
Wie man Dateien indiziert, zeigt das Beispiel org.apache.lucene.demo.IndexFiles aus dem Demopaket sehr schön. Importiere dies einmal in die IDE deines Vertrauens und füge lucene-core zum Classpath hinzu. Um es zu testen, genügen zunächst einmal zwei Parameter. Dabei gibt -index das Verzeichnis an, in dem der Index angelegt werden soll, und -docs das Verzeichnis, in dem die Dokumente liegen, die indiziert werden soll.
Tipp: Lege für den Index ein leeres Verzeichnis an, da die Indexdateien keine sprechenden Namen haben und deshalb das Verzeichnis "zuspammen". Außerdem sollten Index und Daten nicht im gleichen Verzeichnis liegen. Machst du dies trotzdem, hast du nämlich das Problem, dass du die Index-Dateien beim Indizieren herausfiltern musst. Schließlich willst du ja nicht deinen Index in den Index aufnehmen. Weitere Tipps findest du unten unter "Tipps für den Betrieb" weiter unten.
Schauen wir uns das Programm einmal genauer an: Nach dem obligatorischen Handling der Parameter wird der Index aufgebaut.
Directory dir = FSDirectory.open(Paths.get(indexPath));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
if (create) {
// Create a new index in the directory, removing any
// previously indexed documents:
iwc.setOpenMode(OpenMode.CREATE);
} else {
// Add new documents to an existing index:
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
}
...
try (IndexWriter writer = new IndexWriter(dir, iwc);
IndexFiles indexFiles = new IndexFiles(vectorDictInstance)) {
indexFiles.indexDocs(writer, docDir);Listing 1 ist eigentlich ziemlich selbsterklärend oder? Dokumente auswählen, Analyser instanzieren, IndexWriter konfigurieren und Dokumente hinzufügen. Gut, ein wenig "Magie" passiert noch in der Methode indexDocs(). Ich habe absichtlich die Original-Kommentare in Listing 2 gelassen, da sie meines Erachtens wirklich einfach beschreiben, was hier passiert. Wie man sieht, wird nicht nur das Dokument selbst in den Index aufgenommen, sondern auch ein paar Metadaten, die später die Suche vereinfachen.
/** Indexes a single document */
void indexDoc(IndexWriter writer, Path file, long lastModified)
throws IOException {
try (InputStream stream = Files.newInputStream(file)) {
// make a new, empty document
Document doc = new Document();
// Add the path of the file as a field named "path". Use a
// field that is indexed (i.e. searchable), but don't
// tokenize the field into separate words and don't index
// term frequency or positional information:
doc.add(new KeywordField("path", file.toString(),
Field.Store.YES));
// Add the last modified date of the file a field
// named "modified".
// Use a LongField that is indexed with points and
// doc values,and is efficient
// for both filtering (LongField#newRangeQuery) and sorting
// (LongField#newSortField). This indexes to
// milli-second resolution, which
// is often too fine. You could instead create a number
// based on year/month/day/hour/minutes/seconds, down
// the resolution you require.
// For example the long value 2011021714 would mean
// February 17, 2011, 2-3 PM.
doc.add(new LongField("modified", lastModified,
Field.Store.NO));
// Add the contents of the file to a field named "contents".
// Specify a Reader, so that the text of the file is
// tokenized and indexed, but not stored.
// Note that FileReader expects the file to be in
// UTF-8 encoding.
// If that's not the case searching for special characters
// will fail.
doc.add(
new TextField( "contents",
new BufferedReader(new InputStreamReader(
stream, StandardCharsets.UTF_8))));
if (demoEmbeddings != null) {
try (InputStream in = Files.newInputStream(file)) {
float[] vector =
demoEmbeddings.computeEmbedding(
new BufferedReader(new InputStreamReader(in,
StandardCharsets.UTF_8)));
doc.add(
new KnnFloatVectorField("contents-vector",
vector, VectorSimilarityFunction.DOT_PRODUCT));
}
}
if (writer.getConfig().getOpenMode() == OpenMode.CREATE) {
// New index, so we just add the document (
// no old document can be there):
System.out.println("adding " + file);
writer.addDocument(doc);
} else {
// Existing index (an old copy of this document may
// have been indexed) so we use updateDocument instead
// to replace the old one matching the exact
// path, if present:
System.out.println("updating " + file);
writer.updateDocument(new Term("path",
file.toString()), doc);
}
}
}Eigentlich gar nicht so schwer, oder? Quasi als kleine Checkliste habe ich in Tabelle 1 eine Übersicht der Klassen erstellt, die im Beispiel verwendet werden. Genauere Informationen findest du in der javadoc-Dokumentation [JD].
| Klasse | Beschreibung |
|---|---|
| Analyser | Der Analyser zerlegt die zu indizierenden Dokumente in Token, die dann zum Index hinzugefügt werden. Je nach verwendetem Analyser kann er aber auch nicht benötigte Teile herausfiltern oder durch Synonyme ersetzen. |
| Document | Wie der Name schon sagt, ist dies die Repräsentation eines Dokuments, das in den Index aufgenommen werden soll. Dabei handelt es sich um eine Sammlung von Feldern („Fields“). |
| Field | Einzelne Felder/Attribute eines Dokuments |
| IndexWriter | Der IndexWriter kümmert sich darum, wie und wo der Index gespeichert wird. |
| IndexWriterConfig | Konfiguriert den IndexWriter |
| StandardAnalyser |
Hierbei handelt es sich um eine Implementierung eines Analysers. Der hier beschriebene StandardAnalyser verwendet für die Token die Worttrennungsregeln, die im „Unicode Standard Annex #29“ [USA] spezifiziert sind. So wandelt er zum Beispiel die Token in Kleinbuchstaben und entfernt „stopwords“. Unter „stopwords“ versteht man Wörter wie Artikel, die für eine Indizierung wenig hilfreich sind. Dabei sind die Regeln natürlich pro Sprache durchaus sehr unterschiedlich. Näheres findest du hier [ANA]. |
Das erste Suchen im Index
Wie man sich denken kann, gibt es nicht nur für das Indizieren ein Beispiel. Natürlich gibt es auch ein Beispiel für das Suchen im Index. Die entsprechende Klasse versteckt sich ebenfalls in dem Demo-Paket unter org.apache.lucene.demo.SearchFiles.
Auch hier gilt wieder: Importiere es einmal in deine IDE! Nun genügt es zum ersten Spielen, einmal dieses mit dem Parameter -index <Pfad zum Index> aufzurufen. Beim nun folgenden Prompt gib einmal einen Suchbegriff ein und schon siehst du die Treffer. Ich habe für meine Tests die Sourcen von jAMOS-Basic importiert. Hier [JAM] findest du jAMOS-Basic.
Hier ein Beispiel, ich suche Sourcen, die die Methode setARG beinhalten:
Enter query:
setARG
Searching for: setarg
6 total matching documents
1. C:\projektePriv\jAMOS\jAMOS_src\jAMOS\src\jamos\jamal\AMALCompiler.java
2. C:\projektePriv\jAMOS\jAMOS_src\jAMOS\bin\jamos\jamal\miniAMALCompiler.
javx
3. C:\projektePriv\jAMOS\jAMOS_src\jAMOS\src\jamos\jamal\miniAMALCompiler.
javx
4. C:\projektePriv\jAMOS\jAMOS_src\jAMOS\bin\jamos\resources\
miniAMALCompiler
5. C:\projektePriv\jAMOS\jAMOS_src\jAMOS\src\jamos\resources\
miniAMALCompiler
6. C:\projektePriv\jAMOS\jAMOS_src\jAMOS\bin\jamos\jamal\AMALCompiler.class
Press (q)uit or enter number to jump to a page.
Und auch hier wieder ein Blick in den Code. Nach dem üblichen Parsen der Parameter wird ein IndexSearcher instanziiert, der im angegebenen Index sucht. Dabei sieht man sofort, dass dieser als Parameter einen IndexReader übergeben bekommt. In unserem Beispiel wird der Index also aus dem Dateisystem gelesen. Dieser kann aber zum Beispiel auch woanders her gelesen werden (z. B. aus dem RAM) , wenn man einen entsprechenden anderen Index-Reader verwendet:
DirectoryReader reader =
DirectoryReader.open(FSDirectory.open(Paths.get(index)));
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer();
Nun muss nur noch die Abfrage mit dem QueryParser geparst und dem IndexSearcher übergeben werden. Auch dies ist schön kommentiert in dem Beispiel zu finden. Nutze es einfach für eigene Versuche!
Achtung vor dem ersten produktiven Einsatz
Willst du aber mehr als 100 Dokumente indizieren, bekommst du eine RuntimeException mit der Fehlermeldung Are you (ab)using the toy vector dictionary? See the package javadocs to understand why you got this exception. ?
Das liegt daran, dass IndexFiles und SearchFiles numerische Vektoren indizieren und durchsuchen können, die von diesem Text abgeleitet sind und als „Embeddings“ bezeichnet werden. In der Demo werden aber nur eine winzige Menge vorher berechnete Embeddings aus dem GloVe-Projekt [GLV] verwendet. Für einen Produktionseinsatz ist dies viel zu wenig. Genaueres hier [LJD].
Tipps für den Betrieb
Nun die versprochenen Tipps für den Betrieb eines Projekts, das Lucene nutzt.
Der Blick in den Index – Luke
Falls du einmal einen tieferen Blick in den Index wagen möchtest, so sollte der erste Anlaufpunkt das Tool Luke sein. Dieses war lange Zeit ein eigenes Projekt, bis es schließlich in das Lucene-Core-Projekt übernommen wurde. Wechsle einfach in das bin-Verzeichnis und starte je nach Betriebssystem luke.sh beziehungsweise luke.bat. Nach dem Start siehst du zunächst eine wenig modern aussehende Oberfläche. Lass dich von dieser aber nicht abschrecken – hier zählen die inneren Werte.
Am einfachsten gelingt der Start, wenn du einfach einmal den eben generierten Index öffnest. Dabei erfährst du im Reiter "Overview" schon eine Menge über diesen Index, unter anderem, dass es sich um einen Index handelt, der mit Lucene 8 oder neuer erstellt wurde. Dies ist insbesondere dann wichtig, wenn du mit deiner Applikation in einem Index suchen möchtest, der nicht mit deiner Anwendung – also der gleichen Lucene-Version – erzeugt wurde (s. Abb. 1).
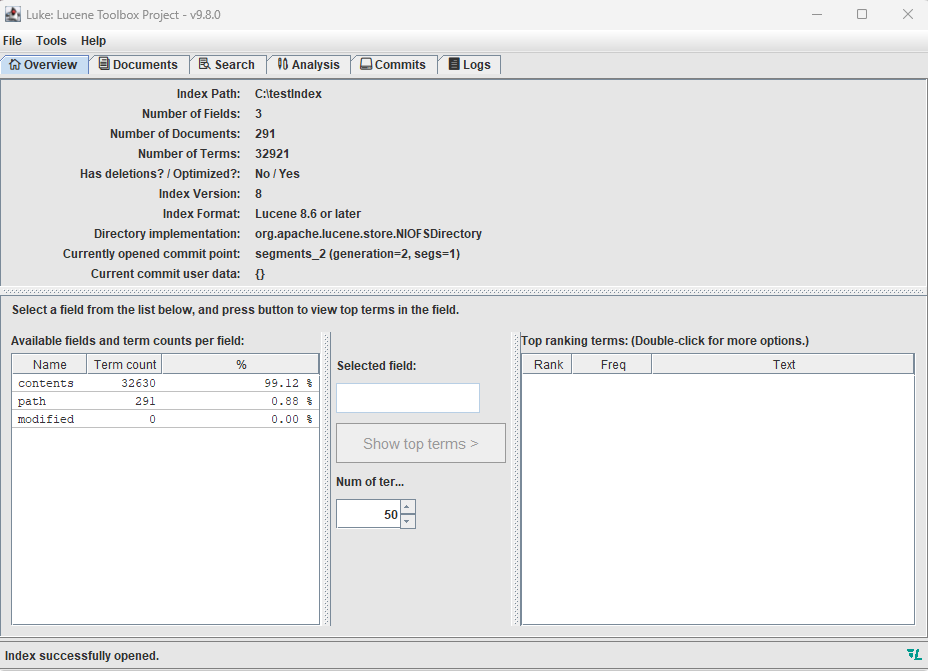
Abb. 1: Der Blick in den Index mit Luke
Du kannst aber auch zum Beispiel in Luke direkt im Index suchen. Nutze hierzu, wie in Abbildung 2, gezeigt den "Search"-Tab.
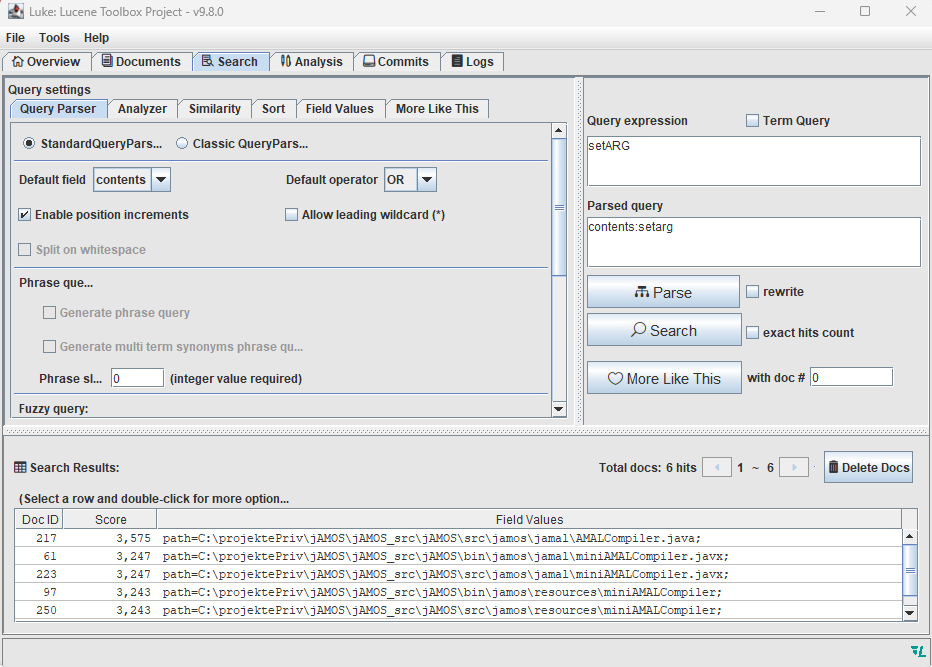
Abb. 2: Suchen im Index mit Luke
Den Index optimieren
Wie man sich vorstellen kann, wird ein aktiver Index, also ein Index, zu dem viele Dokumente hinzugefügt oder gelöscht werden, mit der Zeit immer langsamer. Genaueres findest du hier [LI]. Eine einfache Optimierungsmethode besteht darin, den Index in Luke zu öffnen (siehe oben) und dann im Menü "Tools" den Punkt "Optimize Index" zu wählen.
Geschwindigkeit und Backup
Der Geschwindigkeit des Suchens wird maßgeblich dadurch bestimmt, wie schnell auf den Index zugegriffen werden kann. Das Lesen des eigentlichen Dokuments dagegen ist in der Regel nebensächlich. Das bedeutet aber auch, dass der Index auf einem schnellen Datenträger liegen sollte. Bei vielen Daten kann es deshalb kaufmännisch sinnvoll sein, den Index auf eine SSD auszulagern und die Dokumente auf einer klassischen Harddisk beziehungsweise auf einem Netzlaufwerk liegen zu haben. Beachte aber bei einem Backup unbedingt, dass beides zusammenpassen muss! Solltest du dir nicht sicher sein, so baue den Index bei einem Recovery lieber noch einmal auf – du hast sonst den Effekt, dass Dokumente entweder nicht gefunden werden oder aber nicht mehr existierende Dokumente gefunden werden.
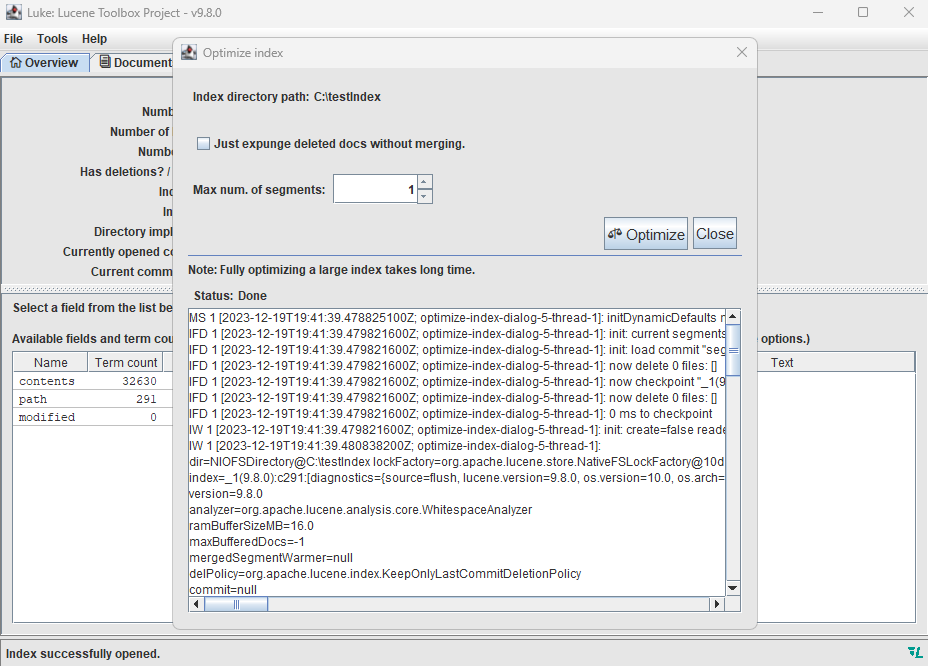
Abb. 3: Optimierung des Index
Sicherheit
Pass auf, welche Dokumente du indizierst – es kann sonst schnell passieren, dass du durch deine Suche Dokumente zur Verfügung stellst, von denen du gar nicht willst, dass sie für alle sichtbar sind. Oft reicht es ja auch, wenn man Zugriff auf die Metadaten hat. Pass deshalb auch auf, wer Zugriff auf den Index hat – denn auch dieser enthält ja schützenswerte Informationen.
Mangelnde Ressourcen
Die zentrale Klasse von Lucene ist IndexWrtiter. Diese hat weitreichende Möglichkeiten, das Indizieren von Dokumenten zu konfigurieren. Nicht vergessen allerdings sollte man, dass dies in der Regel direkten Einfluss auf die Ablaufumgebung hat. Wird der Heap-Space zu klein, so kann dies mit der JVM-Option -Xmx hochgesetzt werden. Ob dies nötig ist, kannst du am einfachsten überprüfen, indem du einmal die Anwendung mit der JConsole beobachtest (s. Abb. 4).
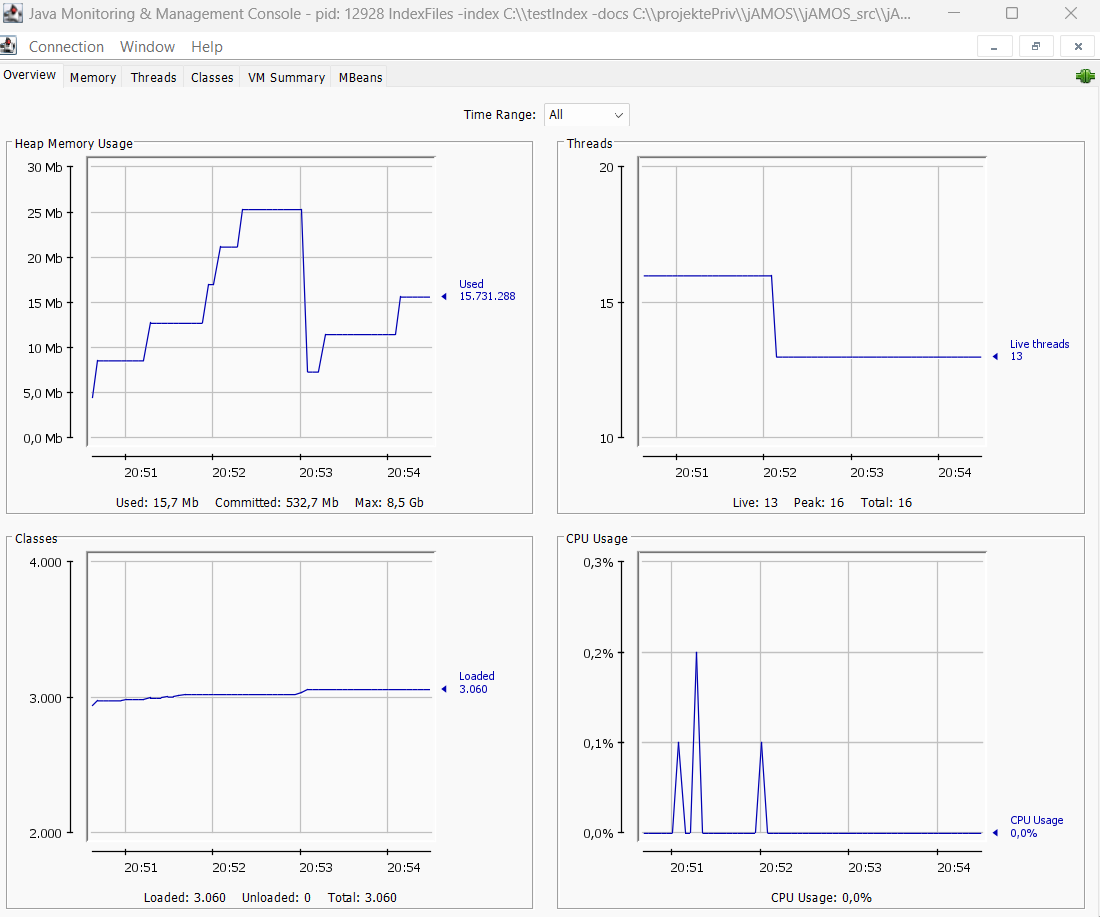
Abb. 4: Blick in IndexFiles.java mit der JConsole
Oft vernachlässigt wird allerdings, dass Lucene sehr viele File-Handles benötigt. Sollte das Betriebssystem zu wenig haben, so kannst du sehr seltsame Effekte beobachten. Warum? Nun, für Unix System V [USV], an dessen Spezifikation sich auch Windows NT orientierte, sind File-Handles nicht nur geöffnete Dateien, sondern auch Handles auf Sockets. Somit kannst du zum Beispiel plötzlich keine Socket-Verbindung öffnen.
Solltest du also eine "Too many open files"-Fehlermeldung bekommen, so schau zunächst einmal nach, ob dein Index-Verzeichnis sehr viele Segmente enthält. Ist dies der Fall, so versuche, den Index zu optimieren. Unter Linux zum Beispiel genügt ein:
ulimit -n
und schon sehe ich, wie viele File-Handles ich verwenden kann. Möchte ich diese hochsetzen, so reicht:
ulimit -n 2048
und schon habe ich 2048 File-Handles.
Ablegen von vielen Dokumenten im Dateisystem
Oft hat man das Problem, dass man viele Dateien in einem Verzeichnis ablegen möchte, um diese später mittels Lucene zu indizieren. Dabei solltest du aber nicht vergessen, dass die unterschiedlichen Dateisysteme hier unterschiedliche Grenzen haben, wie viele Dateien maximal in einem Verzeichnis liegen können.
Auch wenn FAT32 natürlich ein schon etwas angestaubtes Format ist, so wird es doch immer noch häufig auf zum Beispiel Wechseldatenträgern verwendet. Vielen ist dabei nicht bewusst, dass hier aber nur 65534 Dateien in einem Verzeichnis erlaubt sind. Am Anfang gibt es hier sicherlich wenig Probleme, aber Fehler wie der, dass keine 65.535te Datei geschrieben werden kann, kann man vermeiden.
Möchtest du in einem Verzeichnis viele Dateien ablegen, so bietet sich folgender Trick an: Ermittle die MD5-Summe der Datei und baue so eine Baumstruktur auf, in der du die Datei ablegen kannst. Unter Linux genügt hier einfach md5sum <file> – unter Windows hilft uns das Utility Certutil in der Shell:
C:\Users\ronzon>certutil -hashfile 1_RBG.JPG
MD5 MD5-Hash von 1_RBG.JPG:3bd7c0a3bb2d4ebff476535b96766895
CertUtil: -hashfile-Befehl wurde erfolgreich ausgeführt.
Nun kannst du dies verwenden, um die Verzeichnis-Baumstruktur aufzubauen. Hast du also ein Verzeichnis data, so speichere die Datei nicht direkt in diesem Verzeichnis, sondern in:
data/3b/d7/c0/a3/bb/2d/4e/bf/f4/76/53/5b/96/76/68/95
Natürlich musst du nicht 2er-Pärchen bilden, sondern kannst die Tiefe beliebig wählen.
Der große Vorteil ist nicht nur, dass du mehr Dateien in einem Verzeichnis speichern kannst, sondern sogar eine gewisse „Ausgewogenheit“ in den Verzeichnissen hast. Das macht den Zugriff deutlich komfortabler, da das Lesen eines Verzeichnisses deutlich weniger Dateien anzeigt.
Als netter Nebeneffekt ist es so auch möglich, die Verzeichnisse auf verschiedenen Datenträgern abzulegen und entsprechend zu mounten, sodass der physikalische Plattenplatz im Projekt skalieren kann.
Indizieren von nichttextuellen Dokumenten
Wie du oben gesehen hast, ist das Indizieren von Texten mit Lucene sehr leicht möglich. Wie aber ist es, wenn du andere Dateien indizieren möchtest.
Schlagwortsuche
Der klassische Weg ist, Bilder mit Wörtern zu beschreiben und so anhand dieser Wörter die Bilder wiederzufinden. Hierzu ist es aber auf jeden Fall notwendig, schon vorher zu wissen, nach was man später einmal suchen wird. Schau mal auf Abbildung 5.

Abb. 5: Die Winkekatze
Was ist hier zu sehen? Geht es bei diesem Bild eher um eine Winkekatze (Grüße an Klaus Becker) oder um den Raspberry Pi in der Mitte? Oder zeigt es einfach den Schreibtisch eines Makers? Gar nicht so einfach, oder?
Nutzung von Metadaten
Neben der Nutzung von Schlagworten hilft es häufig auch, die Metadaten einer Datei in die Suche einzubeziehen. Möchtest du auf die Metadaten eines speziellen Formats zurückgreifen, so schau bitte in der jeweiligen Formatspezifikation nach, ob beziehungsweise welche Metadaten das Format unterstützt.
Tipp: Für die Metadaten von Bildern gibt es ein eigenes Package: javax.imageio.metadata.
Metadaten in der Musik
Auch wenn für viele das Hören von mp3-Dateien durch Streamingdienste abgelöst wurde, haben viele von uns eine mehr oder weniger große Sammlung dieser Dateien. Nehmen wir einmal an, du hast eine Sammlung und möchtest darin suchen. So kannst du einfach die Metadaten auslesen und mit Lucene indizieren.
Um nicht alles selbst zu implementieren, nutze ich mp3agic [MP3A], mit dem das Auslesen wirklich einfach geht. Ein paar Zeilen Code genügen, um die relevanten Informationen aus einem mp3 zu extrahieren (s. Listing 3).
Mp3File mp3file = new Mp3File(
"37c3-12142-eng-Breaking_DRM_in_Polish_trains_mp3.mp3");
System.out.println("Titel >" + mp3file.getId3v2Tag().
getTitle()+"<\n");
System.out.println("Artist >" + mp3file.getId3v2Tag().
getArtist()+"<\n");
System.out.println("Albumtitel >" +
mp3file.getId3v2Tag().getAlbum()+"<\n");
System.out.println("Genre >" +
mp3file.getId3v2Tag().getGenreDescription()+"<\n");
System.out.println("Laenge >" + mp3file.getLengthInSeconds() +
" seconds<\n");
System.out.println("Bitrate: >" + mp3file.getBitrate() +
" kbps " + (mp3file.isVbr() ? "(VBR)" : "(CBR)")+ "<\n");
System.out.println("Sample rate: >" + mp3file.getSampleRate() +
" Hz<\n");Wie erwartet, erfahren wir hier ein wenig mehr über den Inhalt dieser Audio-Datei:
Titel >Breaking "DRM" in Polish trains<
Artist >Redford, q3k, MrTick<
Albumtitel >37C3 <
Genre >lecture<
Laenge >3706 seconds<
Bitrate: >128 kbps (CBR)<
Sample rate: >48000 Hz<
Tipp: Schau dir die Metadaten der "Bitrate" an – auch so etwas kann dir passieren. Die Bitrate einer mp3-Datei kann nämlich konstant sein (CBR) oder aber variabel (VBR). Dann wird diese dynamisch angepasst. Bedeutet also, dass die Bitrate nicht an allen Stellen innerhalb des Musikstücks konstant ist.
Metadaten in den Lucene-Index aufnehmen
Da du nun die Metadaten, wie oben beschrieben, extrahiert hast, kannst du sie natürlich wie bereits am Anfang beschrieben in den Lucene-Index aufnehmen. So ist es dann möglich, auch zum Beispiel nach mp3s aus bestimmten Jahren zu suchen.
Fazit
Lucene ist supermächtig – dabei ist der Einstieg erstaunlich einfach. Versuche doch mal, Lucene in ein Projekt zu integrieren, und du wirst dich wundern, wie schnell dies gelingt beziehungsweise wie schnell die Suche in den Dokumenten ist.
Weitere Informationen
[ANA] javadoc.io/doc/org.apache.lucene/lucene-analyzerscommon/latest/index.html
[GLV] nlp.stanford.edu/projects/glove/
[INFAY] The Seekers – I’ll never find another you, www.youtube.com/watch?v=wZf41UudAbI
[JAM] sourceforge.net/projects/javaamos/
[JD] lucene.apache.org/core/9_9_0/core/index.html
[LI] www.elastic.co/de/blog/lucenes-handling-of-deleteddocuments
[LJD] javadoc.io/doc/org.apache.lucene/lucene-demo/latest/index.html
[MP3A] mp3agic, github.com/mpatric/mp3agic
[USA] unicode.org/reports/tr29/
[USV] de.wikipedia.org/wiki/System_V
[WIK] de.wikipedia.org/wiki/Apache_Lucene
Du möchtest Zugriff auf alle unsere Inhalte? Dann teste jetzt 30 Tage SIGS+









