

1. Anaconda sammelt Kapital für neue KI-Plattform ein
Der Anbieter von Python-Distributionen für KI und Data Science, hat eine Finanzierungsrunde von über 150 Millionen Dollar unter Führung von Insight Partners und mit Beteiligung von Mubadala Capital abgeschlossen.
Die Finanzierung erfolgt kurz nach der Einführung der neuen Anaconda AI Platform und einer strategischen Partnerschaft mit Databricks. Seit seiner Gründung im Jahr 2012 hat sich Anaconda zu einer der meistgenutzten Python-Distributionsplattformen entwickelt – mit über 21 Milliarden Downloads und 50 Millionen Nutzern.
"Da Agenten und komplexe KI-Systeme an Bedeutung gewinnen, benötigen Unternehmen eine grundlegende Plattform, um wichtige Open-Source-Komponenten effektiv zu verwalten", erklärt George Mathew, Managing Director bei Insight Partners. Die Kapitalspritze soll in neue KI-Funktionen, strategische Übernahmen und die globale Expansion in neue Märkte investiert werden.

George Mathew von Insight Partners begründet die Investition in Anaconda damit, dass der entscheidende Wettbewerbsvorteil von Enterprise-AI nicht in einzelnen Modellfähigkeiten liegt, sondern wie diese „systemisch“ in Softwarearchitekturen eingebettet werden.
2. Databricks unterstützt weitere Sprachmodelle
Der Hersteller aus San Francisco integriert die Open-Weight-Sprachmodelle "gpt-oss 120B" von OpenAI und „Gemma 3 12B“ von Google direkt in seine Plattform. Beide Modelle haben einen vergleichbaren Kontextumfang von rund 130.000 Tokens, womit sie sich auch für umfangreiche Dokumente und Datensätze eignen. Die vollständige Integration beider neuer Modelle gewährleistet sichere Datenverarbeitung unter Einhaltung wichtiger Compliance-Standards wie HIPAA und PCI. Durch APIs, SQL-Integration und Low-Code-Lösungen lassen sich die KI-Funktionen mit minimalem Aufwand in bestehende Business-Intelligence-Workflows einbinden. Die Modelle eignen sich besonders für intelligente Agenten, Datenanalyse und komplexe Entscheidungsprozesse unter Einhaltung von Compliance-Standards. Die Besonderheit bei Gemma liegt in seiner Multimodalität: Es kann nicht nur Text verarbeiten, sondern auch Bild und Video und eignet sich damit beispielsweise für die Beantwortung von Fragen zu visuellem Input.
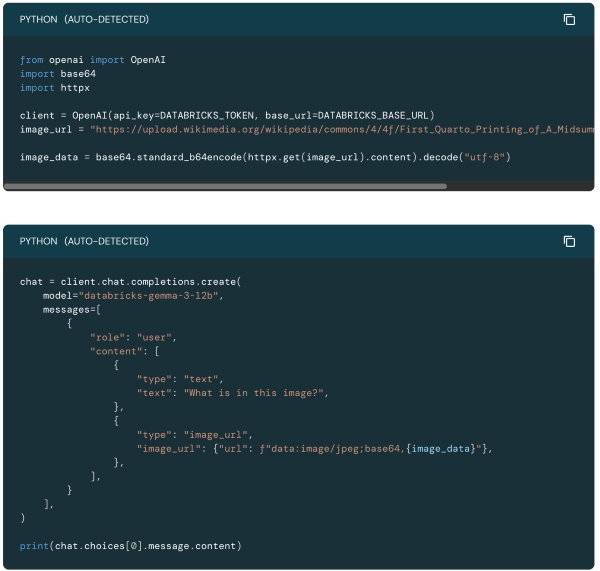
Dieses kleine Beispielskript in Databricks´ AI-Playground zeigt, wie Gemma ein Bild aus Wikipedia lädt und eine Beschreibung des seines Inhalts liefert.
2.1. Erweiterter Knowledge Store für AI/BI Genie
Diese Verbesserung bildet die Grundlage für verlässlichere KI-gestützte Analysen. Der Knowledge Store ermöglicht es Fachexperten, das Verständnis der KI für Unternehmensdaten zu verfeinern, ohne die zugrundeliegende Datenstruktur ändern zu müssen. Die Möglichkeit, lokale Metadaten zu pflegen, Synonyme zu definieren und Datenwörterbücher zu erstellen, zielt auf ein Kernproblem von KI-Systemen ab: die korrekte Interpretation von Geschäftsbegriffen und Datenwerten. Dies ist besonders für Unternehmen relevant, die KI-gestützte Analysen in regulierten Umgebungen einsetzen möchten.
2.2 Forecasting für Dashboard-Liniendiagramme
Die Integration der ai_forecast-Funktion direkt in Dashboards hilft bei der Demokratisierung von Predictive Analytics. Statt komplexe Modellierungen durchlaufen zu müssen, können Analysten so mit einem Klick Prognosen erstellen, die auf historischen Daten basieren. Diese Funktion überbrückt die Lücke zwischen deskriptiver und prädiktiver Analyse und macht zukunftsgerichtete Erkenntnisse für einen breiteren Nutzerkreis zugänglich.
2.3 Dashboard Drill Through
Diese Funktion transformiert die Art, wie Nutzer mit Daten interagieren, indem sie eine kontextbezogene Navigation zwischen Dashboard-Seiten ermöglicht. Der nahtlose Übergang von Übersichts-KPIs zu detaillierten Insights, bei denen Selektionen automatisch als Filter übernommen werden, beschleunigt die Analysezyklen erheblich. Das ist eine deutliche Effizienzsteigerung für alle Unternehmen, die komplexe Dashboards mit mehreren Ebenen benötigten.
3. Was Open-Weight-Sprachmodelle ausmacht
Open-weight-Sprachmodelle sind KI-Modelle, bei denen die trainierten Gewichte („Weights“) öffentlich zugänglich gemacht werden. Das bedeutet: Man erhält den entscheidenden Teil des Modells – die Parameter, die nach dem Training für alle Aufgaben und Antworten verantwortlich sind. Diese Modelle kann man herunterladen, direkt ausführen und auch für eigene Zwecke weiterentwickeln oder feinjustieren (Finetuning).
Im Gegensatz dazu bleiben bei Open-weight-Modellen oft andere Komponenten wie Trainingsdaten, Trainingscode und teilweise die Modellarchitektur geheim oder eingeschränkt zugänglich. Sie sind also nicht vollständig „Open Source“, sondern stellen einen Mittelweg zwischen offenen und kommerziell geschlossenen Modellen dar. Die Offenlegung der Gewichte ermöglicht dennoch große Flexibilität: Unternehmen und Entwickler können die Modelle lizenzkonform nutzen, anpassen und lokal betreiben, ohne auf Cloud-APIs angewiesen zu sein.
4. Snowflake: Container Services jetzt allgemein verfügbar
Mit Snowpark Connect für Apache Spark eine neue Lösung vorgestellt, die BI- und Dateningenieuren erlaubt, Apache Spark-Code direkt in Snowflake-Warehouses auszuführe, also ohne separate Spark-Cluster. Auf diese Weise lässt sich die Komplexität der Infrastruktur-Umgebungen reduzieren. Entwickler nutzen dabei ihren bestehenden Spark-Code einfach weiter – die Plattform kümmert sich automatisch um Performance, Skalierung und Governance. Damit entfällt nicht nur die aufwendige Verwaltung von Abhängigkeiten und Updates, sondern auch der Transfer von Daten zwischen Spark und Snowflake. Die Lösung unterstützt bereits Spark 3.5.x und erlaubt die Ausführung von DataFrame-, SQL- und UDF-Code in gängigen Umgebungen wie Jupyter, VSCode oder Airflow – mit direktem Zugriff auf Snowflake, Iceberg und Cloud-Speicher.
Eine weitere Neuerung sind die Snowpark Container Services für AWS, Azure und Google Cloud. Der neue Dienst ermöglicht die Bereitstellung benutzerdefinierter Anwendungen und KI-Modelle direkt in der Snowflake-Umgebung, ohne dass Daten zwischen den Diensten verschoben werden müssen. Dies reduziert Sicherheits- und Governance-Risiken erheblich. Entwickler können so containerisierte Workloads wie ReactJS-Frontends oder LLMs zu ihren bereits in Snowflake gespeicherten Daten bringen.
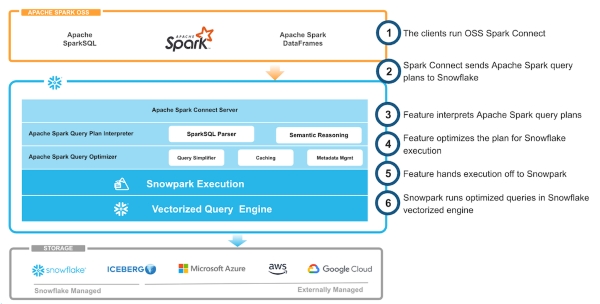
Die Architektur von Snowpark Connect für Apache Spark ermöglicht es Unternehmen, Spark-Code ohne eigene Spark-Instanzen einsetzen zu können.
5. Qlik startet mit Knowledge Marts
Mit der Einführung von Knowledge Marts in Talend Cloud integriert Qlik generative KI tiefer in die Datenanalyse-Workflows und bietet so neue Möglichkeiten für datengestützte Entscheidungen, die über herkömmliche Dashboards und Berichte hinausgehen. Knowledge Marts automatisieren den komplexen Prozess der Transformation, Vektorisierung und des Ladens von Daten in Vektordatenbanken. Diese Datenspeicher liefern innerhalb von RAG-Anwendungen der KI zu jeder Abfrage die passenden Eingabedaten für die Auswertung. So helfen sie dabei, Dokumente einzubeziehen, die nicht Teil der LLM-Trainingsdaten sind.
Knowledge Marts ermöglichen es Unternehmen, sowohl unstrukturierte als auch strukturierte Daten in einen einheitlichen Vektorkontext zu bringen. Dabei werden Vektorspeicher wie Snowflake Cortex, ElasticSearch, OpenSearch oder PineCone sowie einige Embedding-Dienste unterstützt. Unternehmen erhalten so große Flexibilität bei der Auswahl der Infrastruktur. Bei der Übernahme von Daten in die Vektordatenbank hilft der Test Assistant mit natürlichsprachlicher semantischer Suche dabei, die Validität der Daten abzusichern.
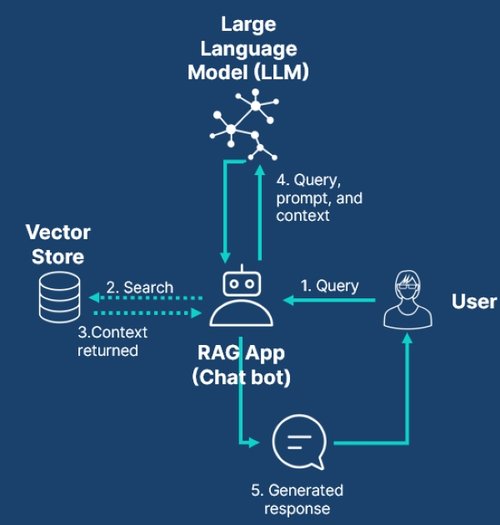
Knowledge Marts von Qlik hilft dabei, strukturierte, kuratierte und kontextspezifische Daten innerhalb von RAG-Anwendungen bereitzustellen.
6. Tableau 2025.2 bringt neue KI-Funktionen
Die neue Tableau-Version bringt mit Concierge und Semantischem Lernen zwei KI-Funktionen, die den Alltag für Viele vereinfachen werden. Concierge ermöglicht es Anwendern, Fragen in natürlicher Sprache zu stellen, worauf sie Antworten mit automatisch generierten Visualisierungen, Ursachenanalysen und konkreten Handlungsempfehlungen bekommen. Das System fragt proaktiv nach, wenn Anfragen unklar sind, und integriert sich nahtlos in bestehende Analytics-Prozesse.
Das Semantische Lernen ergänzt diese Funktionalität, indem es die Wissensbasis der Analytics-Agenten kontinuierlich erweitert. Bei jeder Interaktion mit "Fragen und Antworten" lernt das System in Echtzeit dazu und verbessert so die Präzision seiner Antworten. Unternehmensspezifisches Wissen wird in einem zentralen Repository verwaltet, wodurch die Konsistenz der Antworten erhöht und Mehrdeutigkeiten reduziert werden. Diese Kombination aus dialogorientierter Analyse und kontinuierlichem Lernen verbessert die Verwendung für datengetriebene Entscheidungen in Unternehmen.
7 . Microsoft erweitert Power BI und Fabric
Die Produkte von Microsoft haben einige Neuerungen erhalten:
7.1. Copilot-Funktion standardmäßig aktiviert
Copilot ist seit September 2025 in Power BI standardmäßig aktiviert. Die "Chat with your data"-Funktion bietet dabei eine vollständige Dialog-basierte KI-Oberfläche. Nutzer können Fragen zu Berichten, semantischen Modellen oder Fabric-Datenagenten stellen und erhalten direkt Antworten in Form von Visualisierungen oder Berichten.
7.2 Microsoft 365-Integration: Datensuche erhält Schub
Power BI erweitert seine Integration mit Microsoft 365. Die Metadaten-Freigabe umfasst jetzt mehr Kontext wie Diagrammtitel und Beschreibungstexte aus Dashboards. Dies verbessert die Auffindbarkeit von Power BI-Inhalten in M365-Copilot und Office-Suche erheblich. Auch in der anderen Richtung fließen mehr Informationen: Copilot bezieht jetzt mehr Kontext aus Microsoft 365-Datenquellen wie Teams, SharePoint und Outlook ein. So liefert Copilot intelligentere Antworten und Insights, die einer verbreiterten Informationsbasis aufbauen.
7.3 Neue Datenanbindungen und verbesserte Konnektoren
Power BI Desktop unterstützt jetzt Direct Lake-Semantikmodelle aus SQL-Datenbanken und gespiegelten Datenbanken in Microsoft Fabric. Nutzer können einfach den OneLake-Katalog öffnen, die Datenquelle auswählen und verbinden. Außerdem ist der Snowflake-Connector 2.0 jetzt allgemein verfügbar und bietet deutlich verbesserte Ladezeiten. Neue Connector-Implementierungen für Google BigQuery und Databricks befinden sich in der Vorschau-Phase.
Autor: Markus Schraudolph









