

In der industriellen Fertigung ist es längst selbstverständlich, Teile von spezialisierten Zulieferern zu beziehen und nicht mehr alles selbst herzustellen. Trotz ständig steigender Komplexität können so neue Produkte schnell an den Markt gebracht werden – ohne Qualitätseinbußen und ohne das Weglassen von Funktionen, die Kunden inzwischen als unverzichtbar ansehen.
Bei „Plattform as a Service“ (PaaS) handelt es sich meist um verbreitete Frameworks oder Bibliotheken, die Entwickler zusammen mit eigenen Teilen zu einer Lösung integrieren. Doch PaaS ist nicht gleich PaaS. Genau genommen gibt es im PaaS zwei Stufen der Standardisierung: Developer und Managed PaaS.
Beim Developer PaaS müssen sich Entwickler nicht mehr um die Installation einer Software kümmern. Sie erhalten ein fertig installiertes und vorkonfiguriertes „Softwarepaket“, das Image, das quasi auf Knopfdruck läuft. Möchte ein Entwickler eine neue technische Komponente oder ein neues Framework einsetzen, so spart er sich die Installation und die Zeit, um eine erste Konfiguration zum Laufen zu bringen. In der industriellen Fertigung entspricht das in etwa einem Vorprodukt, das man durch Integrieren zu etwas Neuem veredelt.
Beim Managed PaaS erhält man auf Knopfdruck einen lauffähigen Service, dessen Verfügbarkeit der Serviceanbieter über ein Service-Level-Agreement (SLA) garantiert. Die Verantwortungsteilung ist meist durch eine Variante des „Shared Responsibility“-Modells geregelt [Asr]. Trotzdem erhalten Entwickler und Administratoren genügend Zugriffsmöglichkeiten und Rechte, um die Komponenten optimal auf die individuellen Bedürfnisse einzustellen.
Dieses Prinzip erkennt man recht gut am Beispiel von PaaS-Datenbanken auf Public Clouds: Der Cloud-Anbieter stellt sicher, dass die Datenbankinstallation verfügbar bleibt. Der Datenbank-Administrator im eigenen Team konfiguriert, wann und wie oft Backups erfolgen sollen, und administriert die Tuning-Parameter der Datenbank.
Managed PaaS besitzt also eine größere Fertigungstiefe oder anders ausgedrückt: Managed PaaS nimmt einem cross-funktionalen Team auch langfristig Arbeit im Betrieb ab, Developer PaaS hauptsächlich während der Entwicklung.
Äpfel mit Äpfeln vergleichen
Mitarbeiter in Unternehmen führen Diskussionen über die Nutzung von PaaS-Services häufig über pauschale Aussagen wie:
- Zu teuer: „Der Server ABC kostet mich viel weniger, wenn ich ihn kaufe.“
- Zu gefährlich: „Da auch andere auf der Cloud sind, könnten die ja meine Daten stehlen.“
- Zu wenig Kontrolle: „Wenn bei mir etwas ausfällt, habe ich meine Leute. In der Cloud habe ich keinen Einfluss.“
Für einen objektiveren Vergleich zwischen Eigenbau und Paas-Lösung hilft zunächst die Festlegung eines gemeinsamen Mindestlieferumfangs:
- Selfservice: Teams können auf Knopfdruck eine neue Instanz des Service erhalten. Es gibt weder einen langlaufenden Bestellprozess noch einen individuellen Aufbau durch einen menschlichen Administrator.
- Nutzung bei Bedarf: Die Servicenutzung kann jederzeit beendet werden. Das spontane Anlegen neuer Instanzen oder eine dynamische Skalierung wie beim PaaS-Service muss auch bei der eigenen Plattform in der Regel ohne langfristige Kapazitätsplanung möglich sein.
- Gleiche Ansprüche: Interne Services in der Firma müssen vergleichbare Operation-Level-Agreements zum Beispiel bezüglich Verfügbarkeit und Reaktionszeiten einhalten wie der PaaS-Service.
In der Industrie ist die Wahl eines Lieferanten ein Kompromiss zwischen seinem Preis, dem versprochenen Leistungsumfang (zum erstmaligen Nutzungszeitpunkt, nicht zum Kaufzeitpunkt) und seiner Vertrauenswürdigkeit. Vertrauenswürdigkeit bezieht sich dabei nicht nur auf technische Aspekte wie Verfügbarkeit oder Qualität der Dienstleistung, sondern auch auf Themen wie Flexibilität und Liefertreue.
Dieses Bewertungsdreieck aus Preis, Vertrauenswürdigkeit und Leistungsumfang (siehe Abbildung 1) hilft auch in unserem Kontext, um interne und externe Lieferung eines Dienstes strukturierter gegenüberzustellen.
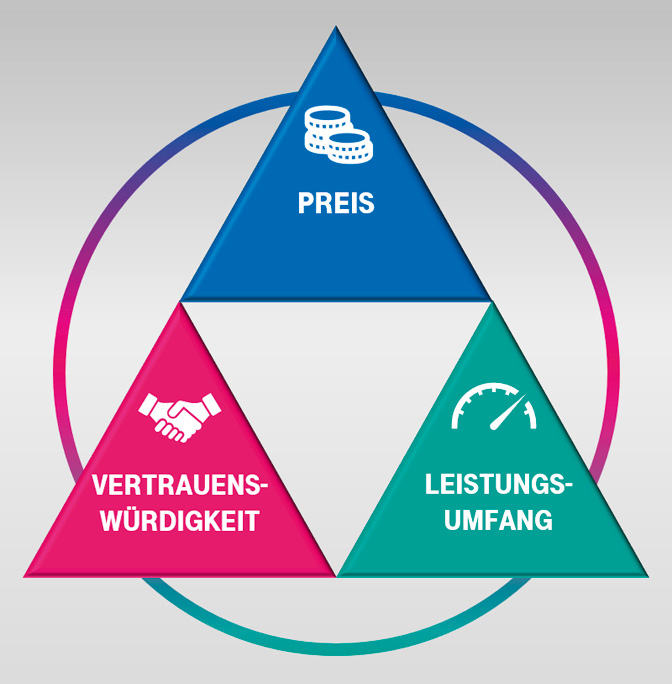
Abb. 1: Bewertungsdreieck für interne und extern zugelieferte Services
Die Sache mit dem Preis
Kostendiskussionen starten typischerweise damit, dass Experten monatliche Preise eines Cloud-Service damit vergleichen, was die Beschaffung entsprechender Hardware kosten würde. Um die Zahlen vergleichbar zu machen, teilen sie die Hardwarekosten auf den finanziellen Abschreibungszeitraum auf (typischerweise zwischen 3 und 5 Jahren). Alle anderen Kosten gelten erst mal als „neutral“, weil Miete, Strom und Administratoren ohnehin bezahlt werden müssten – also „eh da“ sind. Das Ergebnis des Vergleichs ist meist ziemlich eindeutig pro Eigenbau, aber wenig aussagekräftig und eigentlich sogar gefährlich.
Wenn man Managed PaaS in der Cloud kauft, so steht der Cloud-Betreiber für die Verfügbarkeit und Lauffähigkeit der installierten Software beziehungsweise des installierten Frameworks mit einem SLA gerade. Nicht nur diese Garantie bestimmt den monatlichen Preis des Cloud-Angebots, sondern auch die Tatsache, dass die Infrastruktur beim Provider steht. Der übernimmt damit alle „eh da“-Kosten, wie Personal oder Unterbringung der Hardware.
Ein fairer Vergleich mit einem internen Plattformbetrieb müsste also auf Basis einer Gesamtkostenaufstellung erfolgen. Leider geben in vielen Firmen die Buchhaltungssysteme die benötigten, feingranularen Kostenaufstellungen zum Beispiel für einen einzelnen Serverraum nicht her. So ist die übliche, vereinfachte Betrachtung also eher nicht Faulheit oder Ablehnung geschuldet, sondern fehlenden Daten. Doch welchen Effekt hat das?
Die großen Cloud-Anbieter bieten sogenannte „Total Cost of Ownership“-Rechner an, die auf Basis eines Modells und von aktuellen Durchschnittskosten für Hardware, Strom, Miete usw. versuchen, die tatsächlichen Kosten beim Kunden abzuleiten (z. B. [Mco]). Die Berechnungsmodelle können in extremen Setups (z. B. bei extrem viel Speicherbedarf) erstaunliche Ergebnisse liefern. Im Regelfall (ähnlich wie in Abbildung 2) sind aber typische Tendenzen feststellbar:
- Die Hardwarekosten machen weniger als ein Fünftel der Gesamtkosten aus.
- Die Personalkosten betragen ungefähr 2/3 der Gesamtkosten und sind der eigentliche Kostentreiber.
Mit den Daumenregeln ist eine alternative Kostenbetrachtung möglich: Die Gesamtkosten einer Eigeninstallation liegen bei etwa dem Fünffachen der Hardwarekosten. Das kippt meist die Kostenbetrachtung zugunsten des Paas-Service.
Zudem dürften die Kosten des bereits verfügbaren PaaS-Service eigentlich nur mit denen einer bereits fertig aufgebauten, internen Plattform verglichen werden. Während dem Aufbau eines Service fallen nämlich häufig „Leerstandskosten“ an: Denn eigene Infrastrukturen benötigen Investment-Budgets und lassen sich oft nicht kurzfristig beschaffen. Das führt zu einer großzügig-optimistischen Dimensionierung und einer Systemumgebung, die in der Aufbauphase größtenteils leer läuft. „Mieten bei Bedarf“ in einer Public Cloud vermeidet dieses Leerstands-Problem. Cloud-Natives dagegen nutzen teure PaaS-Dienste sogar produktiv geschickt nur stundenweise und verbrennen dadurch kein Geld mit Infrastruktur, die sich langweilt.
Alle Kosten-Betrachtungsvarianten haben ihre Berechtigung, sodass es überraschenderweise erst einmal keinen klaren Sieger gibt …
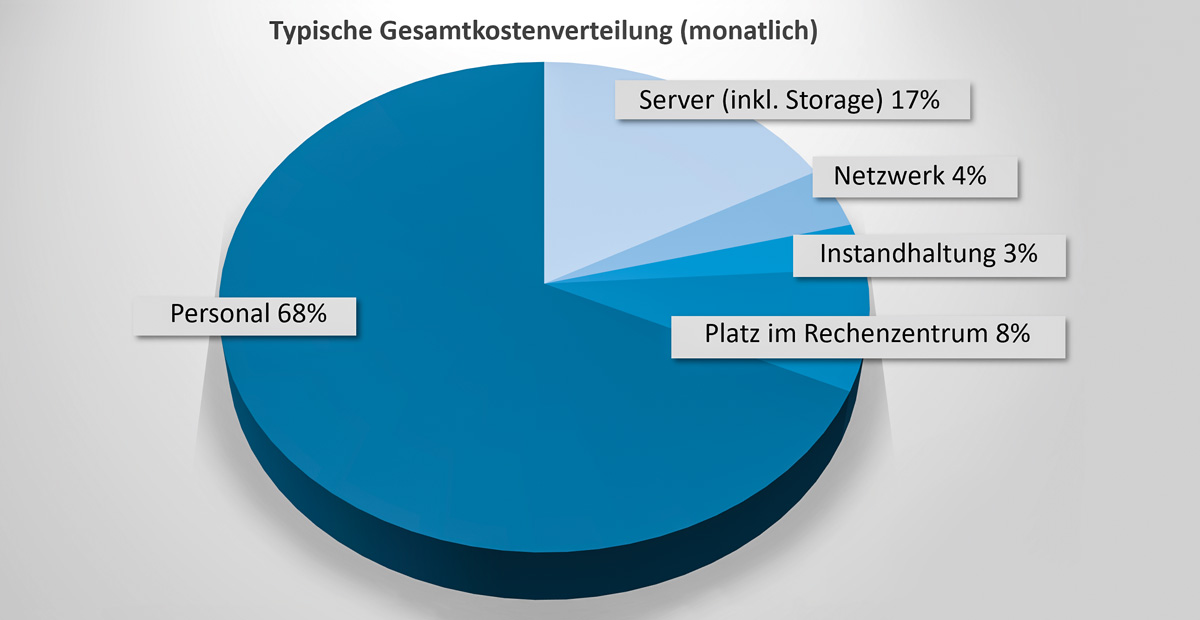
Abb. 2: Beispiel einer typischen Gesamtkostenverteilung
Die Sache mit der Vertrauenswürdigkeit
„Vertraue keinem Fremden“ – so lässt sich das Verhalten vieler Verantwortlicher in IT-Organisationen zusammenfassen. Vertrauen ist kein harter Bewertungsfaktor wie die monatlichen Kosten und basiert stark auf subjektiver Wahrnehmung. Persönlicher Kontakt schafft Vertrauen. Im Falle eines Ausfalls oder einer Krise „kenne“ ich meine Administratoren und kann darauf vertrauen, dass sie die Sache im Griff haben. Ich sehe, dass sich die Kollegen um das Problem kümmern, und muss nicht befürchten, fürs Nichtstun zu bezahlen. Also ein klarer Punkt für eine eigene Installation?
Man übersieht gerne, dass der Erfolg eines Cloud-Providers maßgeblich von der Qualität und Verfügbarkeit seiner Services abhängt. Fällt ein Service aus, so sind gleich sehr viele Kunden betroffen. Sie alle können sehr kurzfristig und einfach auf Knopfdruck die Nutzung eines Dienstes beenden, mit dem sie unzufrieden sind. Dies erzeugt einen deutlichen Druck, viele Absicherungsmaßnahmen von Anfang an umzusetzen.
Kommt es tatsächlich zu einem Ausfall, so ist die Wiederherstellung des Dienstes überlebenswichtig für den Cloud-Anbieter. Daher gibt es einen sehr strukturierten, professionellen und geübten Ablauf zur Krisenbewältigung – den Kunden aber von außen selten wahrnehmen. Ist der Service wieder da, gilt es, das Kundenvertrauen zurückzugewinnen. Hierzu gehört, den Vorfall sauber aufzuarbeiten und eine saubere Root-Cause-Analyse an die Kunden zu geben, zum Beispiel [Tot19]. Verbesserungsmaßnahmen, wie zusätzliche redundante Infrastrukturen, sind Pflicht und werden auch zeitnah umgesetzt.
Interne Plattform-Teams haben oft gar nicht die notwendigen Freiräume, um nach einem Ausfall die Ursachen sauber zu erforschen und Maßnahmen aufzusetzen. Das Tagesgeschäft drückt zu stark. Es bleibt dann manchmal bei Willensbekundungen und einem mutigen „Jetzt, wo wir das Problem kennen, können wir ja das nächste Mal schneller reagieren“.
Cloud-Skeptiker führen gerne auch Vorbehalte bezüglich des Datenschutzes an. Da man die Admins der Infrastruktur nicht kennt, entsteht ein subjektives „Feindbild“ des allmächtigen, anonymen Cloud-Admins, der frei auf kritische Daten zugreifen kann. Tatsächlich ist aber auch dieser Tatbestand bei Weitem nicht so eindeutig, wenn man berücksichtigt, dass mittlerweile nur noch ca. 27 Prozent aller Angriffe Insider involviert haben [DBIR].
Admins bei Cloud-Providern unterliegen tendenziell deutlich härteren Kontrollen, haben einen stärkeren Audit-Druck und sind deshalb stärker sensibilisiert als Corporate Admins. Bei Cloud-Diensten sind getrennte Rollen für unterschiedliche Aufgaben deutlich verbreiteter und klarer ausgeprägt als im „kleinen Serverraum nebenan“ mit wenigen Admins. Und die Cloud-Dienste bieten in der Regel alle möglichen Arten von Transport- und Data-at-Rest-Verschlüsselungen an – man muss sie nur aktiv einschalten und nutzen. Im eigenen Rechenzentrum kann demgegenüber die Einführung von verschlüsselten Festplatten eine strategische Infrastrukturmaßnahme werden, die wegen ihrer Komplexität immer noch nicht umgesetzt ist.
Ob PaaS oder eigene Plattform – das gleiche gesunde Vertrauen beziehungsweise Misstrauen gilt für beide.
Die Sache mit dem Leistungsumfang
Der Leistungsumfang könnte also die Entscheidung für oder gegen PaaS-Services bringen – wie auch schon früher beim Softwarekauf. Da ein verbreitetes Framework oder eine Bibliothek als Service angeboten werden soll, unterscheidet sich der funktionale Leistungsumfang erst mal nicht – falls man intern und extern die gleiche Version zugrunde legt. Bei PaaS-Services bekommt man aber meist nicht die aktuellste Version eines Produkts. Die Angebote sind in der Regel mindestens eine, oft mehrere Minor-Versionen hinter der aktuell stabilsten, veröffentlichten Softwareversion zurück. Das hängt damit zusammen, dass der Serviceanbieter jeden Versionswechsel absolut verlässlich für eine größere Anzahl von Kunden gestalten muss. Dies benötigt zumindest einen ausgedehnteren Zeitraum für intensive Tests nach dem Erscheinen einer neuen Version.
Installiert und betreibt mein eigenes Team die Software, so kann ich natürlich auf Zuruf eine neue Version einführen. Man sollte jedoch nicht übersehen, dass diese Einführung Arbeitsleistung des Plattform-Teams aufbraucht, die gegebenenfalls für die Stabilisierung und Verbesserung der Verlässlichkeit besser eingesetzt wäre. Die Erfahrung zeigt zudem, dass interne Plattformen spätestens im Regelbetrieb Versionswechsel auch nicht häufiger anbieten als Cloud-Provider. Beide unterliegen ja faktisch den gleichen Auslieferungs-Risiken.
Sind gemanagte PaaS bei der Aktualität vielleicht im Nachteil, so gleichen sie dieses durch die Ad-hoc-Verfügbarkeit von betrieblichen Funktionalitäten oft mehr als aus. Aufgrund des Modells der geteilten Verantwortung mit SLA ist der Provider gezwungen, alle wesentlichen Maßnahmen zur Sicherstellung eines störungsfreien Betriebs von Anfang an umzusetzen: Professionelle Log-Überwachung, Monitoring von Ressourcen und konfigurierbare Alarmierungen sowie Backup-Funktionen und redundanter Aufbau sind von Anfang an verfügbar.
Beim Aufbau eines Service durch ein eigenes Team geht die reine Installation der Software oft schnell von der Hand. Aber für einen professionellen Grad an Stabilität, Verfügbarkeit und Betriebssicherheit vergehen selten weniger als zwei Jahre. Diese Wartezeit ist inakzeptabel lang für einen ersten Produktiv-Release, und so gehen interne Services in vielen Betriebsbereichen mit Kompromissen oder „erst mal ohne live“.
Leistungsumfang: Und was ist mit dem Vendor-Lock-in?
Richtig interessant wird ein PaaS-Service durch zusätzliche, innovative Features, die im Standard nicht enthalten sind und die den Anbieter von allen anderen differenziert. Solche Erweiterungen wirken verlockend, gelten aber in Management-Kreisen als gefährliches „Vendor-Lock-in“. Die Befürchtung ist, dass man wegen der Nutzung des Features an einen Anbieter gebunden ist und nicht mehr „einfach mal so“ wechseln kann.
In manchen Organisationen gibt es daher die pauschale Vorgabe bei der Produktauswahl, dass Vendor-Lock-ins zu vermeiden sind. Andererseits, wenn man sich Investitionen in moderne Unternehmenslandschaften anschaut, scheint die strenge Auslegung ohnehin nicht für alle Anbieter und IT-Produkte zu gelten ... Und übrigens: Hat schon jemand ohne viel Aufwand durch einfaches Umschalten ein Produkt ausgewechselt?
Für eine klarere Sicht lohnt es sich, das Thema API eine Detailebene tiefer zu betrachten. Wir empfehlen Kunden, zwischen Nutzungs(Consumption)- und Bereitstellungs(Provisioning)-Schnittstellen zu unterscheiden (siehe Abbildung 3).
Consumption-Schnittstellen enthalten alle Funktionen, die die Fachlogik bei der Nutzung des Dienstes aufruft. Da PaaS-Services im Kern häufig bekannte Open-Source-Pakete sind, ist so eine gewisse Herstellerunabhängigkeit gegeben. Andere unterstützen offene API-Standards oder standardisierte Zugriffsverfahren, wie Datenbank-Treiber.
Anders sieht die Situation bei Provisioning-Schnittstellen aus: Die Bereitstellungs-Schnittstelle ist vom PaaS-Provider definiert und damit meist herstellergebunden. Bei strenger Auslegung scheidet der PaaS-Service deshalb aus. Doch andererseits: Was ist eigentlich das Gegenstück zur Provisioning-Schnittstelle bei Eigeninstallationen? Vielleicht ein interner Bestellprozess mit manueller Lieferung?
Innovativen, neuartigen Diensten fehlt anfangs (noch) eine Standardschnittstellen. Es ist jedoch selten eine gute Idee, dann darauf zu warten, dass der neuartige Dienst eine herstellerunabhängige Schnittstelle bekommt oder dass jemand eine universelle Abstraktion wie Docker erfindet. Verpasste Marktchancen sind das wahrscheinlichste Resultat des Wartens.
Domain-driven Design [Ver17] schlägt in so einem Fall den Aufbau einer sogenannten Antikorruptions-Schicht vor. Sie führt Sollbruchstellen in der eigenen Software ein, die in der Fachsprache der jeweiligen Domäne formuliert sind und die produktspezifische Methodenaufrufe kapseln. Aber Achtung: Sie sind keine einfachen „Umformulierungen“ der Consumption-Schnittstelle. Was hilft beispielsweise eine Abstraktion markiereKunde, wenn eine andere Programmierschnittstelle überhaupt keine Markierungen für ihre Arbeit benutzt?
Clevere DevOps-Automatisierer übernehmen eine ähnliche Vorgehensweise bei den Provisioning-Schnittstellen: Sie führen eine Sollbruchstelle in ihre Provisionierungsskripte ein – möglichst ohne technische Details und Abläufe der Schnittstelle zu imitieren. Ansonsten hat man später ja doch nichts gewonnen, wenn zum Beispiel bei jedem Anbieter der Weg zum Anlegen einer verschlüsselten Festplatte ganz anders ist. Auch hier hilft die Rückbesinnung auf die Fachsprache der Domäne. Was wird denn da eigentlich installiert? Tatsächlich ist ein erzeuge
KundenRepository auch beim Provisionieren viel freier implementierbar als ein Technologie-nahes erzeugeLeseKopie.
Bei einem Wechsel des Anbieters müssen die Entwickler zwar diese Antikorruptionsschicht neu implementieren und können nicht einfach umschalten. Aber es gibt jetzt eine für Änderungen vorgesehenen Stelle und Entwickler müssen nicht überall in der Anwendung eingreifen. Am Ende verpassen sie so wenigstens nicht die Gelegenheit für eine kurzfristige Innovation.
Das böse Vendor-Lock-in ist also auch kein stichhaltiger Grund, um auf gemanagte PaaS-Services zu verzichten.
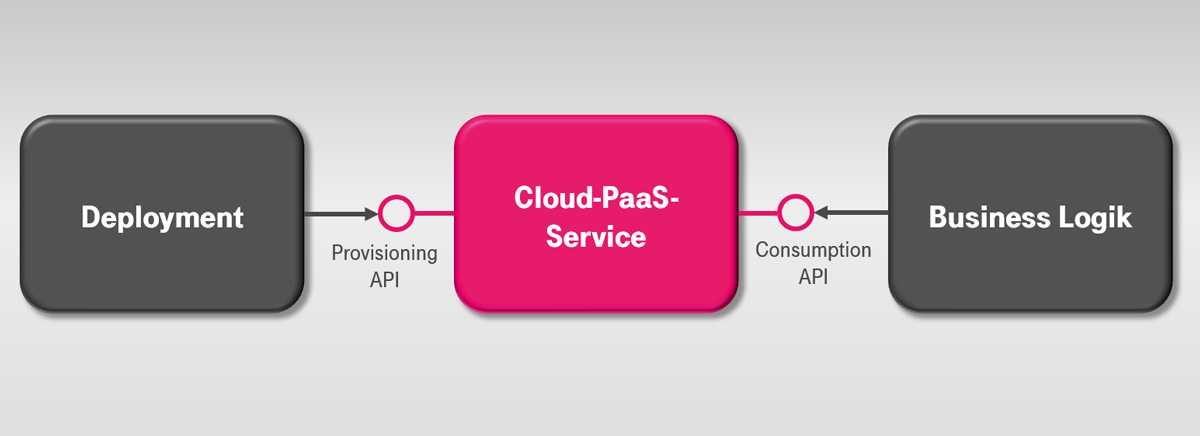
Abb. 3: Provisioning- vs. Consumption-Schnittstellen

Kasten 1
Geschäftlich langweilig
Die Betrachtung mithilfe von Zulieferer-Kriterien hat geholfen, viele verbreitete Argumentationen der PaaS-Befürworter und -Gegner zu relativieren. Eine praktikable und möglichst nicht zu komplexe Entscheidungshilfe sind sie aber anscheinend nicht. Was nun?
Die Industrie setzt Zulieferer-Teile überall dort ein, wo sie zwar unverzichtbarer Bestandteil eines Produkts sind, aber genauso wie bei der Konkurrenz funktionieren dürfen. Sie sind
geschäftlich langweilig. Die Herstellung im eigenen Haus würde wichtige Experten blockieren, die für die Verbesserung von Alleinstellungsmerkmalen gebraucht werden und unmittelbar die Kundenwahrnehmung verbessern.
Auch PaaS-Services sind standardisierte Komponenten und sollten nach demselben Prinzip zum Einsatz kommen. Ein Eigenbau empfiehlt sich nur dort, wo der Einsatz eines eigenen Mitarbeiters die Produkt-Wahrnehmung der Software beim Kunden oder Nutzer verbessert und damit einen Unterschied zu allen anderen Anbietern macht. Wahrnehmbare Verbesserungen sind vielfältig:
- Entwickler arbeiten mehr und häufiger an den Teilen eines Produkts, die besser sein sollen als die Konkurrenz.
- Administratoren sind befreit vom Betrieb der „langweiligen“ Services und können ihren Fokus auf das häufigere Liefern des Kernprodukts setzen.
- Entwickler und Administratoren können auf der grundlegenden Stabilität und Verfügbarkeit der (gemanagten) PaaS-Services aufsetzen und von Anfang an ein deutlich betriebstauglicheres Produkt ausliefern.
Am Ende sind also PaaS-Services ein flexibles Mittel, um rare IT-Ressourcen durch den Einsatz von Zulieferern effektiver einzusetzen. Die eigene IT-Abteilung skaliert gefühlt besser, wichtige Marktfunktionen werden seltener auf die lange Bank geschoben. Vor allem gemanagtes PaaS hat deutliche Personal-Skalierungsvorteile, wenn man bedenkt, dass typischerweise in Unternehmen auf 10 Entwickler 1 Administrator kommt.
Fazit: Langweiliges as a Service
Zusammengefasst empfiehlt sich das „Langweiliges as a Service“-Entscheidungsprinzip aus Kasten 1. Es reicht aus, um PaaS wohldosiert einzusetzen.
Allerdings besteht die Gefahr, dass der „fühlende Mensch“ dabei in den Hintergrund tritt. Es ist zum Beispiel blauäugig anzunehmen, dass jeder Mitarbeiter vom Kunden wahrgenommen werden will. Die Regel kann Menschen dazu zwingen, Dinge aufzugeben, die sie gerne tun. Manch ein Administrator liebt es, im Keller neue Kabel zu ziehen, statt nur noch „Infrastructure as Code“ zu schreiben. Und auch manch ein Entwickler möchte sich vielleicht gar nicht aus seiner liebgewonnenen Bastelumgebung herausbewegen. In diesem Fall ist es die Aufgabe eines Transformational Leader, echte Alternativen zu bieten oder aber frühestmöglich einen Trennungsprozess zu begleiten.
Außerdem gilt es, persönliche Vorbehalte zu hinterfragen und darauf zu vertrauen, dass nicht nur bösen Menschen für PaaS-Provider arbeiten. Ohne ein Grundvertrauen geht es am Ende nicht. Deshalb sollte es legitim sein, den richtigen Lieferanten eben nicht nur aufgrund des Preises auszusuchen. Manchmal schläft es sich mit einem deutschen Provider (z. B.
[Tso18]) halt eben doch ruhiger als mit einem US-amerikanischen …
Weitere Informationen
[Aco12] J. Varia, The Total Cost of (Non) Ownership of Web Applications in the Cloud, Amazon Web Services, 2012, Appendix A, siehe:
https://media.amazonwebservices.com/AWS_TCO_Web_Applications.pdf
[Asr] Modell der gemeinsamen Verantwortung, Amazon Web Services, siehe: https://aws.amazon.com/de/compliance/shared-responsibility-model/
[DBIR] 2019 Data Breach Investigations Report, Verizon, siehe: https://enterprise.verizon.com/de-de/resources/reports/dbir/
[Mco] Microsoft Azure, Gesamtkostenrechner (TCO), siehe: https://azure.microsoft.com/de-de/pricing/tco/
[Tso18] T-Systems, Open Telekom Cloud – die erste Wahl für Firmenkunden mit EU-Fokus, 2018, siehe: https://open-telekom-cloud.com/de
[Tot19] B. Gerlach, Root Cause Analysis and Improvements on OTC Outage 2019-03-30, T-Systems, Open Telekom Cloud, 2019, siehe:
https://imagefactory.otc.t-systems.com/home/root-cause-analysis-and-improvements-on-otc-outage-2019-03-30
[Ver17] V. Vernon, Domain-Driven Design kompakt, dpunkt.verlag, 2017









