

Temperaturmessungen, Stromverbrauch und Druck in der industriellen Fertigung, Leistungsdaten von Motoren, Log-Dateien von Fertigungskomponenten zu anderen Maschinen in der Prozesskette oder Umgebungsdaten von Maschinen wie Luftfeuchtigkeit und Raumtemperatur. Der Artikel zeigt, wie der Einstieg in das Thema Internet of Things in der Produktionsumgebung und die darauf aufbauenden Datenanalysen gelingen kann und wie Analytics-Komponenten schnell und kostengünstig bereitgestellt werden können, um die Basis für ein Echtzeit-Monitoring von Maschinendaten zu schaffen.
IoT-Anwendungen in der Produktion sorgen dafür, dass Daten- und Sensorströme von Maschinen und Anlagen in Echtzeit erfasst werden können. Durch intelligente Technologien lässt sich anhand von Zeitreihendaten exakt berechnen, wann beispielsweise der Verschleiß einer Maschine so hoch ist, dass bestimmte Komponenten ausgetauscht werden müssen.
Damit können Vorhersagen zu Ausfällen oder Problemen von Maschinen- und Anlagenteilen getroffen und „Predictive Maintenance“ betrieben werden. Predictive Maintenance bedeutet die vorausschauende Wartung von Maschinen, Motoren, Anlagen, Geräten oder Komponenten [Sch18].
Mithilfe von Predictive Maintenance können Hersteller, Betreiber oder Techniker frühzeitig Wartungsmaßnahmen einleiten oder rechtzeitig Ersatzteile bestellen, um ungeplante Stillstände oder Ausfälle von Maschinen oder Anlagen zu vermeiden. Dies reduziert die Kosten in der Instandhaltung und verbessert gleichzeitig den Service nachhaltig.
Neben Predictive Maintenance kann durch die Verarbeitung und Analyse von Echtzeitdaten aus „intelligenten Maschinen“ oder Sensoren aber auch die Effektivität von Produktionsprozessen beurteilt oder die Identifizierung von Fehlerquellen entschieden optimiert werden. Auch im Qualitätsmanagement lassen sich durch die Analyse von Produktionsdaten oder durch größere Intervalle bei der Prüfschärfensteuerung Vorteile erzielen. So können Echtzeit-Analysen, auch bekannt als Realtime-Analytics, qualitätsrelevante Faktoren wie zum Beispiel thermische Parameter bei Fügeverfahren, Toleranzen bei Kraft- und Druckprozessen oder optische Faktoren in der Oberflächentechnik im laufenden Produktionsprozess überwachen. Die Reaktionszeit lässt sich dadurch bei Abweichungen wesentlich verkürzen, bevor etwaige Fehlteile einen weiteren Verarbeitungsschritt durchlaufen.
Weitere Anwendungsbereiche für Umgebungsdaten finden sich im Energiemanagement. In Abhängigkeit von Umgebungstemperaturen können energieintensive Verarbeitungsprozesse besser gesteuert oder ungenutzte Energie sogar für andere Bereiche verfügbar gemacht werden. Der Energieverbrauch lässt sich durch die Analyse von Daten deutlich optimieren, indem für Verarbeitungsschritte nur die Energiemenge bereitgestellt wird, die auch tatsächlich benötigt wird [TDWI1]. Wenn ein Antrieb in Zuführsystemen im Produktionsprozess längere Zeit nicht in Benutzung ist, beispielsweise aufgrund eines Reinigungsprozesses in der Maschine, kann dieser automatisch ab- und zugeschaltet werden.
Für den erfolgreichen Einsatz des Internet of Things und von Realtime-Analytics sind vor allem die richtigen Fragen entscheidend: Was gilt es herauszufinden? Was ist die Ursache eines Problems? Wie dringend muss es beseitigt werden? Hierzu müssen in einem prozessorientierten Vorgehen die richtigen Ideen generiert werden [Sch12].
Realtime-Analytics von Produktionsdaten
Die richtigen Ideen und Fragen sind von größerer Bedeutung als perfekte Algorithmen. Hierzu bedarf es eines weitläufigen Verständnisses der Zusammenhänge zwischen den zu untersuchenden Maschinen, Geräten und Komponenten sowie den flankierenden Prozessen und Alltagssituationen. Eine Orientierung, wie erfolgreiche Realtime-Analytics-Projekte durchgeführt werden können, bietet das in Abbildung 1 dargestellte Vorgehensmodell.
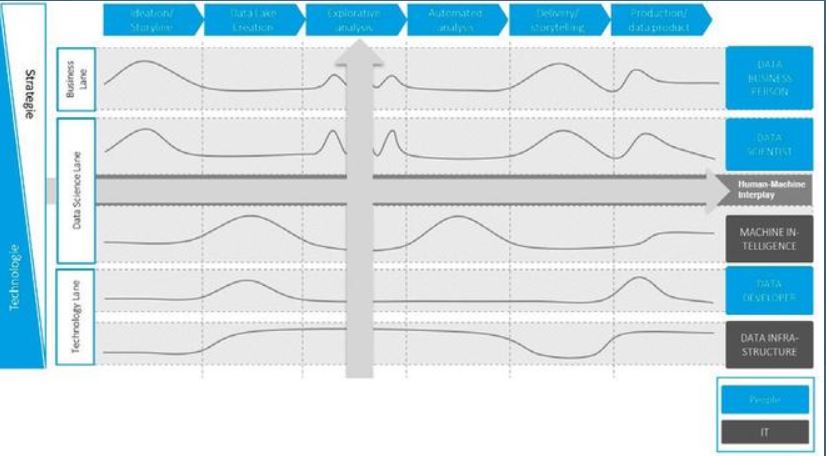
Abb. 1: Vorgehensmodell für Realtime-Analytics-Projekte
Ähnlich wie im Prozess-Management werden den jeweiligen Aufgaben Rollen zugeordnet. Die Kurven beschreiben dabei die Aktivitätsdichte der einzelnen Rollen. Der Pfeil nach rechts beschreibt
das prozessuale Vorgehen in einzelnen Phasen. Die „Data Business Person“ verantwortet im ersten Prozessschritt „Ideation“ das „Storyboard“ und definiert gemeinsam mit dem „Data Scientist“, welche Daten aus welchen Quellen zur Realisierung der Idee in den zweiten Schritt zum Aufbau eines „Data Lake“ überführt werden müssen [TDWI2].
Das Storyboard beschreibt hierbei die Ziele, die durch Data Analytics erreicht werden sollen. In dieser Phase geht es darum, möglichst viele Ideen zu generieren und Problemstellungen zu identifizieren, die mit Realtime-Analytics gelöst werden können. Deshalb sollten in Workshops verschiedene Rollen und Sichtweisen eingenommen werden, um den realen Bedingungen und Problemstellungen möglichst nahe zu kommen.
Ideal hierzu ist ein interdisziplinäres Team mit Teilnehmern aus verschiedenen Fachbereichen, zum Beispiel Mitarbeiter aus der Instandhaltung und dem Betriebsmittelbau gemeinsam mit Mitarbeitern aus der Produktionsplanung und der IT. In einem methodisch geführten Brainstorming gilt es die Ideen und Problemstellungen so weit zu präzisieren, dass die dazu notwendigen Daten zur Analyse definiert und bereitgestellt werden können. Dabei wird entschieden, ob zusätzliche Sensorik oder weitere Erfassungsgeräte nötig und inwieweit zusätzliche Investitionen und Ressourcen erforderlich sind.
Im zweiten Prozessschritt ist die „Technology Lane“ gemeinsam mit der „Data Science Lane“ für die Auswahl und Bereitstellung der erforderlichen Infrastruktur sowie für die Bereitstellung und Aufbereitung der erforderlichen Daten zur Realisierung der „Storyline“ aktiv. In dieser Phase der „Data Lake Creation“ wird auch die Infrastruktur zur Datenakquise definiert und aufgebaut. Dabei sind nicht nur Maschinen- und Echtzeitdaten zu betrachten, sondern auch historische Daten und Daten aus den Geschäftsprozessen.
Der dritte Prozessschritt beschreibt die „Explorative Analyse“. Dieser Schritt bildet auch anhand des Bottom-up-Pfeils die entscheidende Grundlage für eine zukünftige Applikations- oder Produktentwicklung ab, da hier in der Regel die infrastrukturelle Basis für Datenanalysen bereits vorhanden sein sollte. Denn: Um eine verlässliche Analyse von Ausreißern und Mustern auf Basis von Machine-Learning-Algorithmen abzubilden, ist in der Regel die analytische Verarbeitung von großen Datenmengen über einen längeren Zeitraum erforderlich. Die Ergebnisse werden in dieser Phase durch eine agile Prototypisierung immer wieder an der Storyline gespiegelt. Daraus geht hervor, in welchem Grad die definierten Erwartungen bereits erfüllt wurden beziehungsweise welche Analyse-Schritte und gegebenenfalls zusätzlichen Daten noch erforderlich sind. Deshalb ist in dieser Phase eine Art „Ping-Pong-Aktivität“ zwischen dem „Data Scientist“ und der „Business Person“ erforderlich.
Erfüllen die explorativen Analysen die Erwartungen und bilden verlässliche Erkenntnisse ab, kann der Prototyp im vierten Prozessschritt in eine Applikation überführt werden. Dafür werden die prozessualen und fachlichen Schritte in der letzten Phase innerhalb einer „Delivery Story“ zur finalen Applikationsprogrammierung beziehungsweise Implementierung einer Produktlösung definiert.
Der Erfolg eines mit diesem Vorgehensmodell umgesetzten IoT-Projekts wird nicht durch hohe Investitionen, sondern vielmehr durch eine iterative Prototypisierung der Ziellösung gewährleistet. Dabei eignen sich neben einer agil ausgestalteten Vorgehensweise insbesondere Cloud-Plattformen und -Dienste.
Analytics in der Cloud
Gründe für die Umsetzung eines IoT-Projekts mit Cloud-Technologie sind die hohe Skalierbarkeit von Cloud-Diensten in Form von Hardware und Software, die Möglichkeit der echtzeitbasierten Datenabfrage sowie eine endgeräteunabhängige Technologiebereitstellung. Diese Faktoren spielen vor allem in der Phase der „Explorativen Analyse“ eine Rolle, wo man sich iterativ durch zyklische Überprüfung der Annahmen beziehungsweise der gewünschten Ergebnisse einer produktiven, endgültigen Applikationsumsetzung beziehungsweise einem Produkt nähert. Durch die Nutzung von Infrastructure as a Service können die im Laufe der Zeit zunehmenden Datenmengen beispielsweise durch eine Erhöhung der verwendeten Hardware-Kapazität abgefangen werden.
Dabei ist es gleichzeitig von Bedeutung, ob Daten außerhalb oder innerhalb der jeweils eigenen Unternehmensgrenzen gespeichert und verarbeitet werden. In einigen Fällen bieten Hersteller ihre Cloud-Dienste deshalb sowohl in einer Public Cloud als auch in einer Private Cloud an. Bei einer Public Cloud liegt die genutzte IT-Infrastruktur und damit die entsprechende IT-Sicherheit vollständig beim Anbieter. Private Clouds werden dagegen innerhalb der unternehmensinternen Infrastruktur bereitgestellt und sind meist mit einem höheren Kostenaufwand verbunden.
Die Frage nach der geeigneten Cloud-Variante sollte jedoch nicht ausschließlich mit dem Fokus des Kostenmanagements beantwortet werden. Insbesondere durch das Inkrafttreten der neuen Datenschutz-Grundverordnung (DSGVO) ist es notwendig, dass Unternehmen ein Bewusstsein dafür schaffen, welche Art von Daten aufgrund ihrer erhöhten Sensibilität gesondert verarbeitet werden müssen. Neben finanziellen Daten sollten beispielsweise auch personenbezogene Daten vorrangig innerhalb der eigenen Unternehmensgrenzen gehalten und analysiert werden.
Eine weitere Problematik, die sich in Zusammenhang mit Cloud-Technologien ergeben kann, ist das Performance-Verhalten bei der Verarbeitung besonders großer Datenmengen. Das Laden eines großen Datenraums zum Zeitpunkt der Ausführung führt schnell zu signifikanten Performance-Verlusten. Dies kann sich gleichzeitig negativ in der Akzeptanz des Tools beim Anwender widerspiegeln. Bei der Technologieauswahl sollte deshalb auf unterschiedliche Verbindungsarten zu Backend-Systemen sowie die Möglichkeit der persistenten Datenhaltung geachtet werden.
Aufgrund der individuellen Gewichtung der einzelnen genannten Aspekte kann ebenfalls eine hybride Cloud-Lösung sinnvoll sein. Die hybride Lösung vereint die Eigenschaften der Cloud-Varianten und prägt sie unterschiedlich stark aus. So kann beispielsweise die Datenhaltung innerhalb der eigenen Unternehmensgrenzen stattfinden, während die Verarbeitung außerhalb der internen Infrastruktur durchgeführt wird. In diesem Fall werden die Vorteile einer internen Datenhaltung bedingt durch die Nachteile einer komplexeren Skalierbarkeit.
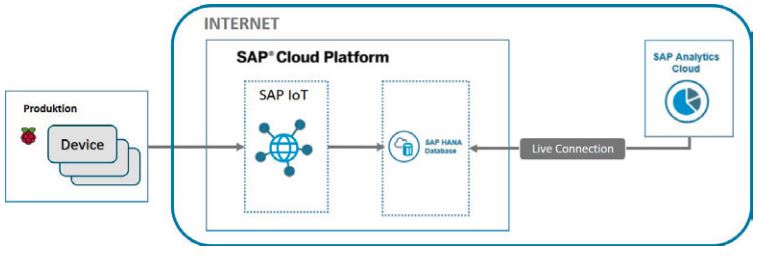
Abb. 2: Architektur der Lösung (Quelle: Braincourt)
Prototyp mit SAP-Technologie
Eine geeignete und in der Cloud bereitgestellte Plattform kann auf Basis einer adäquaten bedarfsgerechten Technologieanalyse gewählt werden. Diese sollte sich an der bereits vorhandenen Infrastruktur orientieren, um die Kompatibilität der Technologien untereinander zu gewährleisten. Die Architektur, die dem nachfolgenden Kundenbeispiel zugrunde liegt, beinhaltet die Technologien Raspberry PI (inklusive relevanter Sensoren), SAP Cloud Platform, SAP HANA und SAP Analytics Cloud. Neben SAP gibt es auf dem Markt für Cloud-Plattformen viele weitere Anbieter [Red18]. Die technologische Fokussierung des Prototyps hinsichtlich SAP ist der Tatsache geschuldet, dass die IT-Architektur des Kunden ebenfalls auf SAP-Produkten basiert und dadurch eine einfache Anbindung der Vorsysteme für den potenziellen Ausbau des Szenarios gewährleistet ist.
In der SAP Cloud Platform werden Services für unterschiedlichste Anwendungsfälle bereitgestellt. Je nach Bedarf können diese Services unabhängig voneinander aktiviert und konfiguriert werden. SAP HANA ist eine In-Memory-Datenbank, die Daten in Echtzeit spaltenorientiert speichert [TDWI1]. Die SAP Analytics Cloud stellt ein vollständig in der Cloud gehostetes Frontend-Tool dar, mit dem Daten in Dashboards visualisiert und analysiert werden können.
In Zusammenarbeit mit Metabo, einem Hersteller von Elektrowerkzeugen und Anbieter von Zubehör für professionelle Anwender [Met19], wurde ein Beispielszenario zur Veranschaulichung der Vorteile durch den Einsatz von IoT-Technologie in der Produktion geschaffen und ein Prototyp für die Analyse von Umgebungsdaten in der Produktionsstätte entwickelt. Damit konnte Metabo aufgezeigt werden, welche Schritte für den Aufbau einer IoT-Architektur notwendig wären, um die eigene Produktion in Zukunft mit Hilfe von Realtime-Analytics steuern zu können. Dadurch sollte ein erster Eindruck sowohl hinsichtlich des entstehenden Aufwands als auch in Bezug auf das Potenzial des geschaffenen Mehrwerts einer digitalisierten Produktionsumgebung gewonnen werden. Zentrale Bestandteile des Prototyps sind Minicomputer (Raspberry PIs), die Maschinen- und Umgebungsdaten mit Hilfe von Sensoren in der Produktion erfassen und an die SAP Cloud Platform übertragen. Im Prototyp wurden für das Monitoring der Produktionsumgebung folgende Werte in Echtzeit erfasst:
- Lautstärke
- Luftqualität
- Temperatur
- Luftfeuchtigkeit
- Vibration Die Raspberry PIs
sind in diesem Aufbau die einzigen physisch beim Kunden vorhandenen Komponenten. Sie senden die sensorisch erfassten Daten mit Hilfe eines Python-Codes im Sekundentakt an die SAP Cloud Platform. Sie ist die zentrale Verwaltungsplattform, auf der nicht nur die jeweiligen Sensoren über den IoT-Service registriert werden, sondern auch die zentrale SAP-HANA-Datenbank für die Speicherung der gesendeten Sensordaten aufgesetzt ist. Diese kann sowohl als Online-Datenbank von der SAP Cloud Platform bezogen werden als auch in der unternehmensinternen Infrastruktur integriert sein. Mit Hilfe verschiedener Entwicklungswerkzeuge wie beispielsweise dem SAP HA-NA Studio können in der Datenbanktechnologie Data-Cleansing-Prozesse konfiguriert werden, um die Sensordaten für die weitere Verwendung automatisiert aufzubereiten.
Die Visualisierung der in der SAP-HANA-Datenbank gespeicherten und aufbereiteten Sensordaten wird in der aufgezeigten Lösung mit der SAP Analytics Cloud durchgeführt. Hier ist insbesondere die Live-Datenabfrage in Echtzeit von Bedeutung, da auf diese Art keinerlei Daten in der SAP Analytics Cloud gespeichert werden, was für einen wesentlichen Teil der Anwender von Cloud-Technologien ein essenzielles Kriterium darstellt.
Fazit
Eine erfolgreiche Prototypisierung von IoT-Realtime-Analytics-Projekten in der Produktion zeichnet sich durch die Verwendung von Cloud-Diensten auf Basis agiler Vorgehensmodelle aus. Bei der Umsetzung des beschriebenen Prototyps stellte sich die Integration der Raspberry PIs in das Firmennetzwerk von Metabo zunächst als Herausforderung dar. Aus Gründen der IT-Sicherheit mussten die Sensoren deshalb in ein separates Netzwerk aufgenommen werden. Darüber hinaus kam es zu Beginn der Datenauswertung zu Komplikationen hinsichtlich der Kalibrierung der Sensoren in Bezug auf die Messqualität.
Die Analytics Cloud ist im Vergleich zu anderen Frontend-Produkten erst seit kürzerer Zeit auf dem Markt. Dies hat zur Folge, dass bestimmte Funktionen in Abhängigkeit von der verwendeten Verbindungsart, insbesondere Live-Connections, bisher nur eingeschränkt verfügbar sind. Aufgrund dessen musste beispielsweise die Skalierung und Aggregation der Messwerte für eine analysefähige Darstellung im Backend angepasst werden. Die Auswahl der geeigneten Sensorik steht innerhalb dieses Architekturaufbaus daher in einem direkten Zusammenhang mit dem Aufwand der Datenaufbereitung und der damit einhergehenden Datenqualität. Als Cloud-Anwendung besitzt die Analytics Cloud den Vorteil, dass sie von stetiger Weiterentwicklung geprägt ist und Releases automatisch in kurzen Intervallen von ca. zwei Wochen ausgerollt werden. Damit ist zu erwarten, dass Limitierungen durch Live-Connections in der Zukunft behoben werden.
Innerhalb des beispielhaften Szenarios war Metabo mit Hilfe des Prototyps in der Lage, die Umgebungsdaten in der Produktionsstätte in Echtzeit zu analysieren. Damit konnten neue Erkenntnisse über die Produktionsabläufe gewonnen werden. Über die Nutzung der gesammelten Informationen zu Temperatur, Lautstärke, Vibration, Luftqualität sowie Luftfeuchtigkeit wurden Muster erkennbar, die den Produktionsprozessen zugeordnet werden konnten. In einer Verlaufskurve können Ausschläge erkannt werden, die einen Rückschluss auf den Arbeitsvorgang einer Maschine zulassen. So kann durch die Analyse von Verlaufskurven der Vibration einer Maschine geprüft werden, ob ein Teilschritt im Prozess korrekt ausgeführt wurde. Ein weiteres Beispiel, das allerdings kein Bestandteil des Szenarios war, ist die Berechnung der Korrelation von Qualitätsmerkmalen zu gemessenen Sensorwerten. Ist ein bestimmtes Spaltmaß zu groß, könnte dies auf einen Unterschied der Temperatur zum Normalwert zurückgeführt werden. So können Probleme behoben werden, um Qualitätsstandards einzuhalten.
Gleichzeitig können im Kontext von „Predictive Maintenance“ durch die Analyse solcher Sensordaten Rückschlüsse auf potenzielle Ausfallzeiten oder erhöhte Ausschussquoten gezogen werden. Eine methodische Auswertung dieser Analysen ermöglicht es, relevante Einflussfaktoren zu identifizieren, um frühzeitig auf deren Veränderung reagieren zu können.
Literatur
[Met19]
Metabo-Homepage,
https://www.metabo.com/de/de/,
abgerufen am 30.1.2019
[Red18]
[INET] Reder, B.: Anbieterübersicht: Smarte Plattformen für IoT-Projekte. 3.8.2018,
https://www.internetworld.de/technik/internet-dinge/anbieteruebersichtsmarte-plattformen-iot-projekte-1569420.html?ganzseitig=1,
abgerufen am 30.1.2019
[Sch12]
[CIO] Schneider, R.: Allianz-CIO: Radikaler Business-Wandel kommt. 15.11.2012,
https://www.cio.de/a/allianz-cio-radikaler-business-wandel-kommt,2898504,
abgerufen am 30.1.2019
[Sch18]
Schreiner, J.: IoT-Basics: Was ist Predictive Maintenance? 12.11.2018,
https:// www.industry-of-things.de/iot-basics-was-ist-predictive-maintenance-a-693842/, abgerufen am 30.1.2019
[TDWI1]
eBook Real Time Analytics,
https://www.tdwi.eu/wissen/studien-buecher/ebooks/wissen-titel/tdwi-ebook-real-time-analytics.html
[TDWI2]
E-Book Data Science,
https://www.tdwi.eu/wissen/studien-buecher/e-books/wissen-titel/tdwi-e-book-data-science.html









