

Experten wie Emad Mostaque, ehemaliger CEO von Stability AI [1], gehen davon aus, dass KI künftig Softwareentwickler teilweise oder vollständig ersetzen wird. Ob diese Vorhersage zutrifft, wird sich zeigen. Zumindest unterstützen KI-Co-Piloten schon heute als persönliche Assistenz weltweit Softwareentwickler bei der Arbeit. KI wird als Werkzeug in bestehende Umgebungen eingebettet und erleichtert dort die Bedienung und erhöht die Produktivität.
Co-Piloten sind keine Randerscheinung, sondern ein Trend, der zeigt, wie KI künftig in vielen Einsatzbereichen integriert werden wird. Bereits jetzt sind zahlreiche KI-Co-Piloten im Einsatz, mit bekannten Platzhirschen wie Microsoft Copilot im Betriebssystem, GitHub Copilot in der Entwicklungsumgebung und auch mit eigens für die KI-gestützte Arbeit entwickelten Plattformen wie Codium/qodo oder dem Marketing-Tool Jasper.
KI-Co-Piloten als integriertes Werkzeug
Besonders in der Entwicklung kommt generative KI bereits jetzt an vielen Stellen zum Einsatz. Werkzeuge wie Cursor oder replit sind im Grunde Co-Piloten, deren Steuerung, Anweisung und Kontrolle weiterhin der Entwickler übernimmt, wobei bei den letztgenannten Lösungen mehr Kontrolle an die KI abgegeben wird, was Workflows vereinfachen kann. Die verschiedenen Produkte und Ansätze werfen dabei die klassische Frage auf, ob Software bedient oder beherrscht werden muss.
Ein Kerngedanke der generativen KI gilt auch für Co-Piloten: die Schnittstelle über natürliche Sprache. Nutzer können mit einfacher Sprache Probleme und Aufgaben beschreiben, für welche die generative KI des Co-Piloten Lösungen anbietet. Hier kommen auch spezielle Funktionen von Co-Piloten ins Spiel, die häufige Aufgaben, wie Commit Messages in der Entwicklungsumgebung, per Tastendruck generieren können. Auch durch Echtzeitvorschläge und bei der Fehlererkennung unterstützen die Co-Piloten den Entwickler und sollen die Arbeit so effizienter und einfacher machen. Sie übernehmen Seitenaufgaben ganz oder teilweise, vereinfachen wiederkehrende Aufgaben und das Beheben von Fehlern. Die Kontrolle bleibt dabei meist beim Nutzer, dem echten Piloten der Software, der stets den letzten Blick behalten kann und damit weiter in der Verantwortung bleibt.
Wer abseits von Enterprise-Lösungen, monatlichen Bezahlmodellen und möglicher mangelnder Kontrolle nach einem Co-Piloten sucht, kann mit Open Source bereits jetzt eigene generative KI bereitstellen, lokal auf dem eigenen Rechner oder auf dedizierten Servern. Vor allem für Entwicklungsumgebungen steht hier bereits echte Integration als Co-Pilot durch Plug-ins bereit, inklusive individualisierbarer Befehle und voller Kontrolle darüber, welche Aufgaben der Co-Pilot übernehmen kann und wohin die Daten fließen.
Der Weg zum eigenen Co-Piloten
LLM-basierte Co-Piloten unterstützen Entwickler durch automatische Code-Vervollständigung und kontextbezogene Vorschläge. Ein großes Sprachmodell (LLM) ist eine Künstliche Intelligenz (KI), die Sprache verstehen und Texte oder Bilder generieren kann. Dafür wird es mit riesigen vorgegebenen Mengen an Textdaten trainiert, um Muster und Zusammenhänge zu erkennen. Co-Piloten greifen zusätzlich auf relevante Informationen in eigenen Dokumentationen und Code-Repositories zu.
Darin liegt auch ein Teil ihrer Kraft: Retrieval-Augmented Generation (RAG, siehe Abb. 1) kann einem Co-Piloten zusätzliche externe Wissensquellen zur Verfügung stellen.
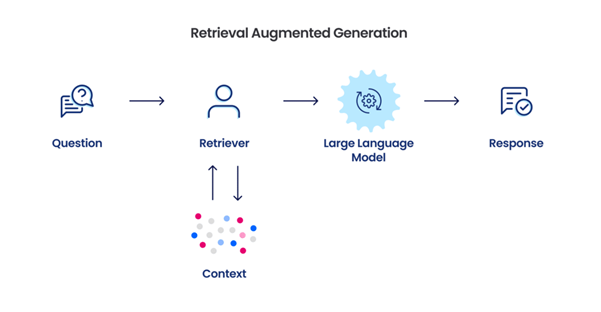
Abb. 1: Mit RAG Kontext erzeugen
So entstehen genauere und kontextbezogene Vorschläge, die sich an aktuellen Best Practices orientieren. Besonders bei komplexen Aufgaben oder neuen Technologien profitieren Entwickler von präziseren und aktuelleren Code-Empfehlungen.
Im Cockpit die Kontrolle behalten
Der Einsatz von RAG ist auch notwendig, denn KI macht Fehler oder gibt irreführende Hinweise. Um Risiken zu verringern, lohnt es sich, Best Practices im Umgang mit KI zu beachten und sich nicht blind auf die Assistenz zu verlassen, auch dann nicht, wenn sie mehrmals richtig gelegen hat.
Es ist durch Projekte wie Cline zwar mittlerweile möglich, in der Entwicklungsumgebung fast völlig auf Autopilot zu fahren, doch Kontrolle bleibt auch in diesem Falle nötig. Der erste Kontrollschritt ist die Bewertung des Use Cases für den Einsatz von KI. Die Möglichkeit zu automatischer Code-Generierung ist zum Beispiel im Java-Umfeld auch ohne KI bereits groß, ein Einsatz hier wäre gegebenenfalls überflüssig und wenig effizient.
Co-Piloten lassen sich gut einsetzen, um Fehler zu vermeiden, Alt- und Fremdcode zu analysieren und die Funktionen von Frameworks und Schnittstellen zu verstehen. Der Maschinen-Kollege ist gut darin, in kurzer Zeit essenzielle Informationen aus vielen Seiten Dokumentationen zu sammeln oder Debug Traces zu lesen, klassische Fälle, wo vielleicht sonst eine lange Internetsuche ansteht.
Mit Personalisierungen zum Ziel
Um hier gute Antworten zu erhalten, muss der eingesetzte Co-Pilot natürlich diese Informationen haben. Mit dem erwähnten RAG ist es möglich, auch große Mengen von fehlendem Kontext schnell durch den Co-Piloten filtern und verwenden zu lassen. Der Co-Pilot kann umso mehr zum alltäglichen Partner werden, je stärker er für die gewählten Anwendungsfälle personalisiert ist.
Zu diesem Zweck sollten Entwickler vordefinierte und standardisierte Prompts nutzen. Besonders bei Aufgaben, bei denen ein festes Muster als Antwort erwartet wird, zum Beispiel wenn man den Co-Piloten anweist, eine Commit-Nachricht zu erstellen, sollte die Struktur der Antwort immer dieselbe sein. Indem man diese Struktur und den Auftrag in Standardprompts vordefiniert und diese konsequent immer wieder nutzt, erzielt der Co-Pilot konsistente Ergebnisse, die in den gewählten Einsatzbereichen schnellen Mehrwert bringen.
Für besondere Anpassungsmöglichkeiten ist es möglich, Training auf bestimmte Einsatzzwecke zu nutzen, um Modelle noch besser auf eigene Use Cases anzupassen. Auch diese Art der Individualisierung ist insbesondere durch Open-Source-Modelle möglich, aber mit deutlich größerem Aufwand verbunden, als Modelle direkt zu verwenden.
In einigen Fällen dürfen Entwickler Code, Dokumentationen und zum Beispiel personenbezogene Daten nicht von einem Co-Piloten verarbeiten und speichern lassen. Diese Einschränkungen können die Individualisierung von Co-Piloten und auch deren Einsatz begrenzen oder teure, datenschutzkonforme Lizenzen erfordern. Auch hier lässt sich Kontrolle der Datenhaltung- und Speicherung durch die Verwendung von self-hosted Open-Source-Modellen erreichen.
Eine individuelle Lösung mit Open Source
Open-Source-LLMs lösen nicht nur Probleme mit Datenschutz, Kosten und Individualisierung, sondern schaffen auch neue Möglichkeiten für Entwicklung und Innovation. Sie sind durch Finetuning, ihre Modularität und Vielfalt vielseitig einsetzbar – solange man die Möglichkeiten für RAG und Prompt Engineering ausnutzt.
DeepSeek-R1 ist beispielsweise ein Open-Source-Modell, welches laut Entwicklern mit einem geringen Budget und ohne High-End-GPUs trainiert wurde. Es kann trotz dieser begrenzten Ressourcen starke Leistungen im Vergleich zu den besten OpenAI-Modellen erbringen, ist also eine echte Alternative. Es legt eine Grundlage für die Weiterentwicklung generativer KI mit MIT-Open-Source-Lizenz: Auf der KI-Plattform HuggingFace existieren bereits über 700 Modelle, die innerhalb eines Monats auf DeepSeek-R1 oder DeepSeek-V3 aufgebaut wurden [2].
Durch die Vielzahl an Weiterentwicklungen entstehen optimierte Varianten für unterschiedliche Anwendungsbereiche. Forschung und Industrie profitieren von dieser offenen Innovationskultur, die Verbesserungen rasch integrieren und Anwendungen anpassen kann. Die schnelle Verbreitung zeigt, wie dynamisch die Open-Source-Community an neuen KI-Modellen arbeitet, und führt zu einer stetigen Qualitätssteigerung. Wer Open-Source-Modelle verwendet, kann also gut mit den neuesten Entwicklungen Schritt halten.
Diese Dynamik erinnert an die Entwicklung von Linux. Open-Source-Betriebssysteme prägen heute Cloud-Infrastrukturen, Server und mobile Geräte [3]. Ein ähnlicher Wandel zeichnet sich bei KI ab: Unternehmen setzen verstärkt auf offene Modelle, die mehr Transparenz und Anpassungsfreiheit bieten. Mit fortschreitender Entwicklung werden Open-Source-LLMs in immer mehr Bereichen zum Standard. Sie können Kosten senken, Abhängigkeiten von großen Tech-Konzernen reduzieren und Innovationen breit zugänglich machen. Herausforderungen wie nachhaltige Finanzierung und Qualitätskontrolle bleiben bestehen, dennoch könnte Open-Source-KI für Künstliche Intelligenz das werden, was Linux für Betriebssysteme wurde – eine treibende Kraft für Technologie und Wirtschaft.
Vorteile des Self-Hostings
Das Self-Hosting eines LLM bietet volle Kontrolle über Datenschutz und -sicherheit. Sensible Daten bleiben auf Servern unter eigener Kontrolle und müssen nicht an externe Anbieter übertragen werden. Dadurch lassen sich Compliance-Anforderungen und branchenspezifische Sicherheitsstandards besser einhalten.
Ein lokales Modell kann gezielt angepasst und spezialisiert werden. Spezifisches Fachwissen, unternehmensinterne Dokumente oder besondere Sprachstile lassen sich in das Modell integrieren. Dabei besteht auch die Flexibilität bei der Modellwahl. Für viele Aufgaben reichen kompakte Modelle aus, die schneller und ressourcenschonender arbeiten. Verschiedene Modelle lassen sich testen und je nach Anwendungsfall optimal einsetzen. So entsteht ein maßgeschneiderter KI-Assistent.
Langfristig bietet Self-Hosting oft eine kosteneffiziente Lösung. Externe API-Zugriffe verursachen laufende Kosten, die mit steigender Nutzung erheblich wachsen können. Ein eigenes Modell erfordert zwar anfängliche Investitionen in die Infrastruktur, doch bei intensiver Nutzung oder einer Einrichtung auf dem eigenen Privatrechner sinken die Kosten im Vergleich zu kommerziellen LLM-Diensten. Auch die Latenz wird deutlich reduziert, da Anfragen nicht über externe Server laufen. Für zeitkritische Anwendungen wie Echtzeit-Analysen oder interaktive Systeme kann dies entscheidend sein. Sofortige Antworten und minimale Verzögerungen verbessern die Nutzererfahrung erheblich.
Zusätzlich entfällt die Abhängigkeit von Drittanbietern. Updates, Nutzungsbedingungen oder Verfügbarkeiten externer Dienste beeinflussen den Betrieb nicht. Volle Kontrolle über Infrastruktur und Weiterentwicklung sichert langfristige Stabilität und Planbarkeit. Ein mögliches Tool, um KI dann mit Open Source schnell lokal bereitzustellen, ist Ollama.
Demonstration mit Ollama, Continue und Open WebUI
Die Laufzeitumgebung Ollama bietet eine effiziente Möglichkeit, Open-Source-Sprachmodelle lokal oder in eigene Umgebung auszuführen. Es unterstützt eine Vielzahl an Open-Source-Modellen und erleichtert so den Wechsel zwischen verschiedenen LLMs. Außerdem lässt sich die Plattform problemlos mit Docker betreiben, was eine einfache Bereitstellung und Skalierung ermöglicht. Besonders bemerkenswert: Ollama nutzt das OpenAI-API-Format, wodurch auch Unternehmen ohne große Umstellungen von kommerziellen Diensten zu Open-Source-Alternativen wechseln können.
Die Nutzung von Ollama erfordert keine komplizierte Technik oder tiefes IT-Wissen. In wenigen Schritten lässt sich die Plattform auf einem Computer oder Server installieren und direkt nutzen. Auf ollama.com stehen Anleitungen für Windows, macOS und Linux bereit. Damit die Modelle effizient arbeiten, ist eine GPU mit ausreichend Video Random Access Memory (VRAM) erforderlich, und die Wahl des Modells sollte sich an der verfügbaren Hardware orientieren. In diesem Artikel demonstrieren wir alle Beispiele mit Qwen2.5-Coder-7B. Das lässt sich zum Chatten einfach über ein Konsolen-Kommando aufrufen, siehe Abbildung 2.

Abb. 2: Start mit Ollama
Theoretisch lassen sich jetzt bereits über die Konsole Fragen zu Entwicklungsthemen stellen. Aber für eine echte KI-Assistenz braucht es eine nahtlose Integration in die Entwicklungsumgebung. Dafür eignet sich das Plug-in Continue.dev: Dieser Open-Source-KI-Code-Assistent lässt sich einfach über den jeweiligen Marketplace in VS Code und JetBrains IDEs integrieren. Er bietet Entwicklern Funktionen wie Chat-Unterstützung, Inline-Code-Vervollständigung und die Möglichkeit, Code direkt im aktuellen Dokument zu bearbeiten.
Was Continue besonders auszeichnet, ist seine Open-Source-Natur und die hohe Anpassungsfähigkeit. Entwickler können verschiedene KI-Modelle und mehr als 25 Kontextquellen wie aktuelle Codes, Website und Jira integrieren, um den Assistenten optimal an ihre individuellen Bedürfnisse anzupassen. Die nahtlose Integration in beliebte IDEs wie VS Code und JetBrains ermöglicht KI-gestützte Entwicklung ohne Unterbrechung des bestehenden Workflows (siehe Abb. 3).
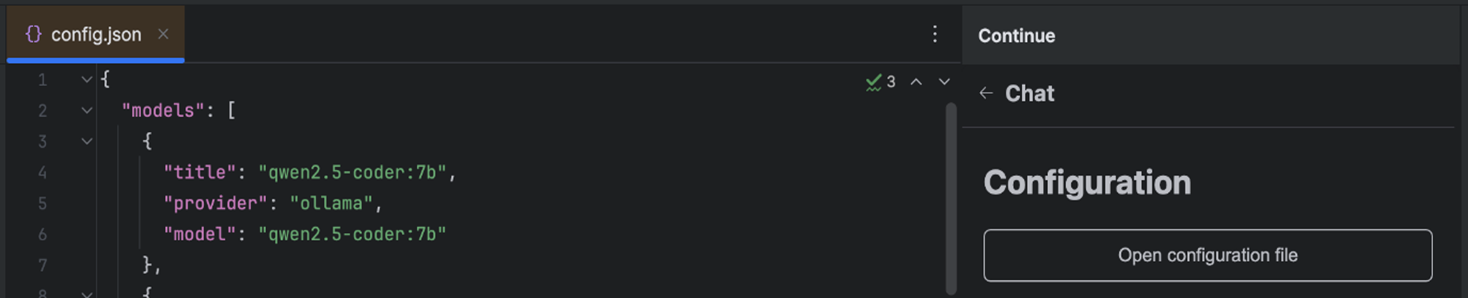
Abb. 3: Lokale und externe Modelle lassen sich in der config-Datei von Continue verbinden
Entwickler können eigene Funktionen mit speziellen Prompts vordefinieren, die sich dann immer wieder in Chats über Funktionsaufrufe ausführen lassen. Für jede Funktion lässt sich auch ein anderes Modell anbinden. Es ist also möglich, Autovervollständigungen über ein OpenAI-Modell zu erhalten und Tests von QwenCoder generieren zu lassen, wenn man Zugang zu beiden Modellen hat. Einzelne Funktionen lassen sich unabhängig voneinander modifizieren (siehe Abb. 4).
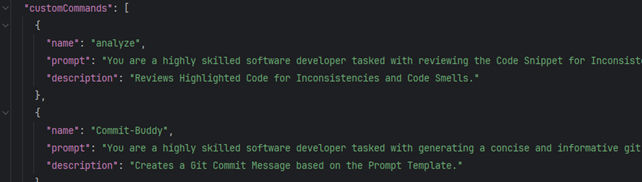
Abb. 4: Custom Commands ermöglichen standardisierte Workflows
Mit Continue lässt sich also ein Co-Pilot einrichten, modifizieren und personalisieren. Wer hierbei die Vorteile von RAG nutzt und standardisierte und erprobte Prompts benutzt, kann die KI-Assistenz schnell für verschiedene wiederkehrende Aufgaben, wie das Formulieren von Commit-Nachrichten, einsetzen. Schnell unterstützt der Assistent bei Code-Analysen, Fehlerbehandlung und Autovervollständigung und somit der eigentlichen Entwicklungsarbeit, ohne dass dabei echte Kontrolle verloren geht (siehe Abb. 5).
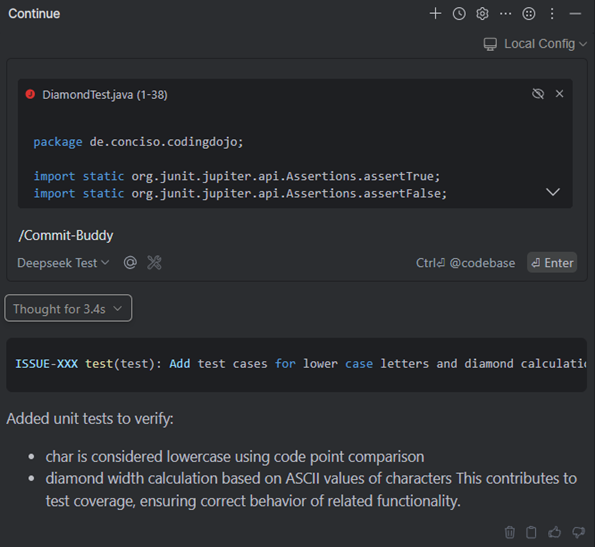
Abb. 5: Mit Custom Commands erledigt der Co-Pilot alltägliche Aufgaben
Wer noch mehr Customizing erreichen möchte, kann zwischen Continue und Ollama noch Open WebUI einsetzen. Diese Weboberfläche ermöglicht unter anderem das Erstellen eigener Modelle, die mit einem Systemprompt und eigenen Wissenskollektionen und RAG-Parametern individualisiert werden können. Die Open WebUI erlaubt auch eine einfache Erprobung oder den Einsatz der Modelle als Chatbot über ein eigenes Chatinterface. Sie bietet eine einfache Nutzerverwaltung und kann so Teams als KI-Provider dienen oder durch ihre zu OpenAI-API konforme Schnittstellen zur Automatisierung genutzt werden.
Ein Softwarestack aus Continue, Ollama und der Open WebUI erschließt also viele Möglichkeiten, konfigurierbare KI-Unterstützung auf Basis von Open Source zu verwenden.
Nicht ohne Kompromisse
Ganz kompromissfrei kommt der eigene Co-Pilot, wie jede herkömmliche KI-Assistenz, jedoch nicht daher. Continue befindet noch in der Entwicklung und war in der Vergangenheit fehleranfällig. Auch sammelt das Tool Telemetriedaten, was sich noch abschalten lässt.
Die Leistung des Co-Piloten ist stark von der lokalen Rechenleistung und der Qualität und Menge des Kontexts abhängig. Generell gilt, egal ob man nun Continue oder andere Plug-ins verwendet, um sich KI-Unterstützung in die Entwicklungsumgebung zu holen: Die tatsächliche Leistung und Qualität von Vorschlägen, Generierungen und Analysen sind zudem immer abhängig von den eingesetzten Modellen, der Eingabe und den Prompts. Wer Co-Piloten bereits jetzt nutzen will, sollte also auch das Potenzial von RAG, Prompting und vielleicht sogar Finetuning nutzen.
Der große Vorteil einer Open-Source-Lösung: Es stehen viele Modelle zur Verfügung, die bereits ihre eigenen Spezialisierungen mit sich bringen und die Personalisierung durch die genannten Funktionen unterstützen, während man gleichzeitig keine Daten an Dritte geben muss und Kontrolle über Kapazitäten, Leistung und damit auch Kosten behält.
Ein großes Problem der Open-Source-Lösung ist die Menge an eingesetzten Tools. Keine Technologie erfüllt alle Erwartungen, die eine Enterprise-Lösung sonst vielleicht bieten kann, es wird immer noch ein Open-Source-Tool mehr benötigt. Diese Modularität kann sehr praktisch sein, ist aber auch mit höherem Einrichtungs- und Wartungsaufwand verbunden.
Fazit
Bereits heute sind selbsteingerichtete KI-Assistenzen in der Entwicklungsumgebung möglich und produktiv einsetzbar. Durch die Nutzung von Open Source bleibt man unabhängig und flexibel, muss allerdings auch einen längeren Weg zum Ziel gehen, denn Personalisierung, Modellauswahl und der Einsatz verschiedener Tools erzeugen erst durch die gemeinsame Nutzung den optimalen Mehrwert.
Diesen Weg zu gehen, bietet sich für Entwickler und Unternehmen durchaus an. Unter anderem, weil es in Ollama einfach ist, Modelle wie Llama, Deepseek, Mistral oder Qwen zu tauschen und so künftige KI-Fortschritte an der eigenen Codebasis zu erproben und standardisierte Prompts zu definieren, die für die eigenen und alltäglichen Anwendungsfälle die besten Ergebnisse erzeugen. So bleibt der Einsatz mit den neuesten Modellen, Modulen und Agenten am Puls der Zeit – oder ist ihr sogar voraus.
Literaturangaben
[1] E. Mostaque, P. H. Diamandis, Why AI Matters And How To Deal With The Coming Change, Episode EP #52, 2023, siehe: https://www.youtube.com/watch?v=ciX_iFGyS0M
[2] S. Gerstl, What does DeepSeek mean for the AI model market?, 5.2.2025, siehe: https://www.all-about-industries.com/what-does-deepseek-mean-for-the-ai-model-market-a-8ab5f5b9ede5a11c13d5ae3138873c58/
[3] V. Danen, The Power Of Open Collaboration, Forbes, 1.3.2025, siehe: https://www.forbes.com/councils/forbestechcouncil/2025/01/03/the-power-of-open-collaboration-how-open-source-is-shaping-the-future-of-ai/









