

Mittlerweile gibt es (auch in JavaSPEKTRUM oder auf www.sigs.de) Artikel, die sich damit beschäftigen, wie man LLMs aus Java anspricht. Oft will man aber gar nicht sofort eine eigene Anbindung erstellen und diese in seiner eigenen Anwendung verwenden. Vielmehr möchte man vorher einfach einmal mit einem LLM „herumspielen“, um ein „Gefühl“ für dieses zu bekommen.
Sei es, um zu prüfen, wie gut dieses für den eigenen Zweck verwendet werden kann. Oder sei es, um erst einmal zu testen, wie die eigene Hardware von diesem LLM „unter Dampf“ gesetzt wird. Spätestens, wenn man das LLM mit eigenen Daten weiter trainieren möchte, sucht man eine Oberfläche, mit dem diese Dinge leicht erledigt werden können.
In dieser Folge von Tool Talk stelle ich zwei verschiedene grafische Oberflächen vor. Dabei steigert sich die Funktionalität. Einsteiger in diese Thematik können hierzu am besten die GUIs nacheinander testen, um sich so langsam an das Thema heranzutasten. Wer aber schon Erfahrungen hat, kann auch direkt tiefer einsteigen.
LLMs – Large Language Models
Zunächst möchte ich eine kleine Einführung in das Thema „lokal gehostete LLMs“ geben. Daher werde ich zunächst ein paar Grundlagen erklären.
Unter LLMs versteht man ein Sprachmodell, das Texte generieren kann. Hierzu wird das Modell mit Trainingsdaten (bestehende Texte) mit aufwendigen Berechnungen trainiert. Heraus kommt dann ein Modell, das auf wesentlich schwächerer Hardware „ausgeführt“, also abgefragt werden kann.
Sicherlich denken viele gleich an Platzhirsche wie ChatGPT oder DeepSeek. Allerdings ist es für viele Anwendungsfälle ausreichend, kleinere und somit Ressourcen sparende Modelle zu verwenden. Hinzu kommt, dass diese leicht lokal gehostet werden können. Die Abfragen an diese Modelle werden auch nicht an Dritte weitergegeben und verbleiben im „eigenen Netz“. Das bedeutet aber auch, dass es erst so möglich ist, bei beispielsweise Anfragen mit Kundendaten die DSGVO relativ einfach einzuhalten.
Möchte man dann auch noch das Netz mit seinen, vielleicht nicht für jedermann öffentlichen Daten, weiter trainieren, bietet sich das lokale Betreiben an.
Ohne Python läuft nichts
Mittlerweile ist hinreichend bekannt, dass ohne Python hier nichts läuft. Der erste Schritt ist also (falls nicht schon geschehen), Python wie zum Beispiel hier beschrieben zu installieren.https://www.sigs.de/b7nq3x1z8v/admin/pages/5437/edit/#block-15e7a65e-f46f-47e4-bd0a-9e3f12b95a4c-section
Ollama – der Quasi-Standard
Hierbei handelt es sich um ein Softwarepaket, das es dir erlaubt, auf der Kommandozeile Modelle zum Beispiel herunterzuladen oder mit diesen zu chatten. Dabei stellen mittlerweile alle möglichen Anbieter ihre Modelle in einem Format zur Verfügung, das es erlaubt, diese mit Ollama zu managen.
Da die später vorgestellten GUIs auf Ollama aufsetzen, ist der nächste Schritt nach der Python-Installation dieses zu installieren. Für Microsoft Windows und Mac OS findest du hier Installationspakete.
Unter Linux genügt ein Befehl in der Shell:
curl -fsSL https://ollama.com/install.sh | sh
Dabei wird man nach dem root-Passwort gefragt, da es sich systemweit (also nicht nur für den angemeldeten User) installiert. Vorsichtige Admins sollten daher vielleicht einmal vorher einen Blick in das Installationsskript unter https://ollama.com/install.sh werfen, um sicherzustellen, dass dieses keine Probleme macht.
Nun kann Ollama mittels:
ollama start
gestartet werden. Standardmäßig startet dieses dann einen lokalen Webserver, der auf Port 11434 lauscht (siehe Abb. 1).
Abb. 1: Ollama lokal gestartet
Nun kann mittels der Kommandozeile mit verschiedenen LLMs gearbeitet werden. Da wir aber diesmal eine GUI bevorzugen, müssen wir erst einmal eine installieren.
Alpaca – nicht immer ein Kamel aus den Anden
Bei Alpaca handelt es sich um eine GUI, die vor allem durch ihre Einfachheit besticht. Das soll nicht heißen, dass sie nur für einfache Arbeiten geeignet ist, sondern eher, dass sie Einsteiger nicht mit allen möglichen Optionen verwirrt, sondern sich auf die Arbeit mit einem LLM beschränkt.
Auch hier haben es Linux-User einfacher bei der Installation. Es genügt ein Aufruf von:
flatpak install flathub com.jeffser.Alpaca
Aber auch mit Windows-Usern haben die Entwickler ein Einsehen und stellen hier eine ausführliche Anleitung für die Installation bereit.
Nach der erfolgreichen Installation kann die Anwendung dann am einfachsten durch Klick auf das Icon gestartet werden, das auf der Kommandozeile:
/usr/bin/flatpak run --branch=stable --arch=x86_64 --command=alpaca com.jeffser.Alpaca
doch etwas sperrig ist. Danach öffnet sich der Startbildschirm (siehe Abb. 2).
Abb. 2: Der Startbildschirm von Alpaca
Der Import des ersten LLM
Als Nächstes solltest du ein bestehendes LLM importieren. Am einfachsten geschieht dies durch Auswahl des Menüpunkts „Modelle verwalten“. Es öffnet sich nun ein Bildschirm mit allen vortrainierten LLMs, die du direkt verwenden kannst (siehe Abb. 3).
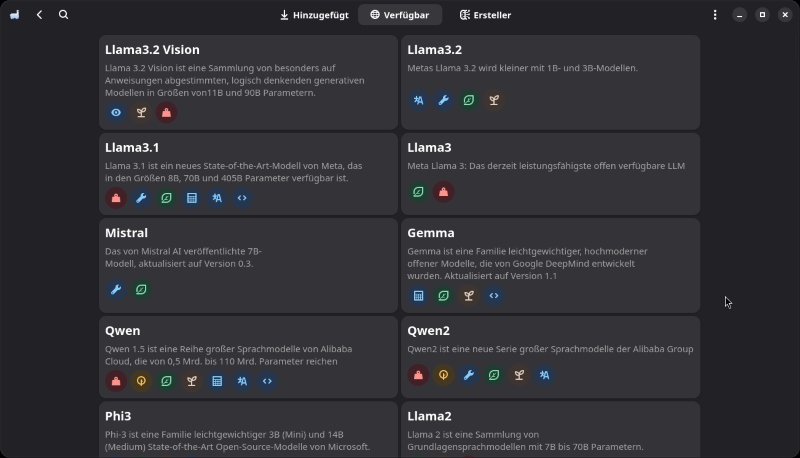
Abb. 3: Die Modelle in Alpaca
Bei mir stehen gerade direkt 138!!! Modelle zur Verfügung. Dabei haben die Modelle unterschiedlichste Eigenschaften. Welche dies sind, verraten am schnellsten die kleinen Icons unterhalb des Modellnamens. Hier findest du nicht nur Angaben über die Größe (und damit den Ressourcenbedarf), sondern auch, für welche Aufgaben und Sprachen dieses Modell trainiert wurde. Weitere Infos erhältst du auf Klick auf ein Modell.
Für die ersten Tests habe ich mich für ein Llama3.2-Modell entschieden, da es relativ klein ist und außerdem verschiedene Sprachen unterstützt.
Der erste Chat
Wechsle wieder zur Startseite. Wir wollen nun unseren ersten Chat starten. Wer mich kennt, weiß, dass ich ein alter Amiga-Freund bin (1987, Amiga 500 Kickstart 1.2). Da ich aber nicht sicher sein kann, dass alle Leser überhaupt wissen, was das ist, habe ich mal nachgefragt (siehe Abb. 4).
Beachte, alle Anfragen erfolgen lokal! Nichts geht ins Internet!
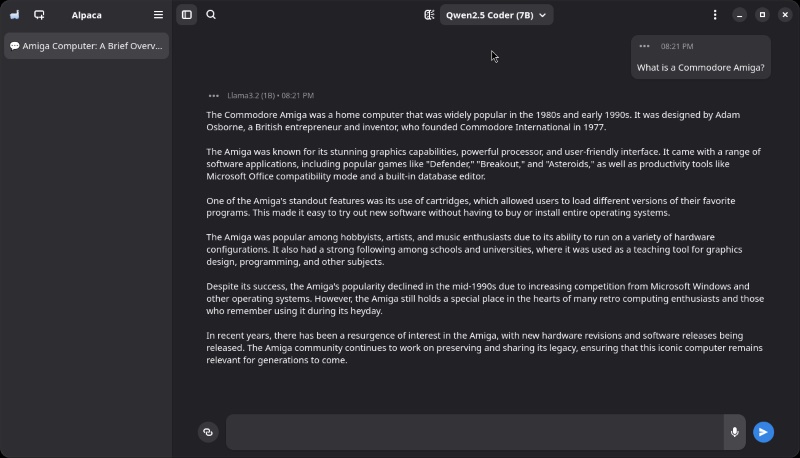
Abb. 4: Der erste Chat – Was ist ein Commodore Amiga?
One for you – one for me – GPT4All
Wie wir mit Alpaca gesehen haben, ist der Einstieg in lokale LLMs gar nicht so schwer. Ein schönes Tool für etwas fortgeschrittene User ist GPT4All. Hier möchte ich neben der Installation und den ersten Schritten auch einmal auf das Thema „Trainieren mit eigenen Daten“ eingehen.
Die Installation
Geht man auf die Startseite von GPT4All unter (https://www.nomic.ai/gpt4all), bekommt man sofort die verschiedensten Installationspakete angeboten.
Tipp: Obwohl ich kein Ubuntu-Linux mag beziehungsweise nutze, stand nur ein Installationspaket für diese Version zur Verfügung. Dieses führt einen grafischen Installer aus, welcher sich beklagte, dass er das Verzeichnis ~/Desktop nicht finde. Das manuelle Anlegen des Verzeichnisses beseitigte die Meldung und der Installer lief sauber durch. Alles, was ich tun musste, ist das Programm durch Aufruf von:
gpt4all/bin/chat
zu starten, da kein Icon auf den Desktop gelegt wurde.
Die Oberfläche
Die Oberfläche von GPT4All zeigt sich erwartungsgemäß anders als die von Alpaca (siehe Abb. 5).
Abb. 5: Der Startbildschirm von GPT4All
Aber auch hier kann zunächst durch einen Klick auf „Find Models“ ein Modell ausgewählt werden (siehe Abb. 6).
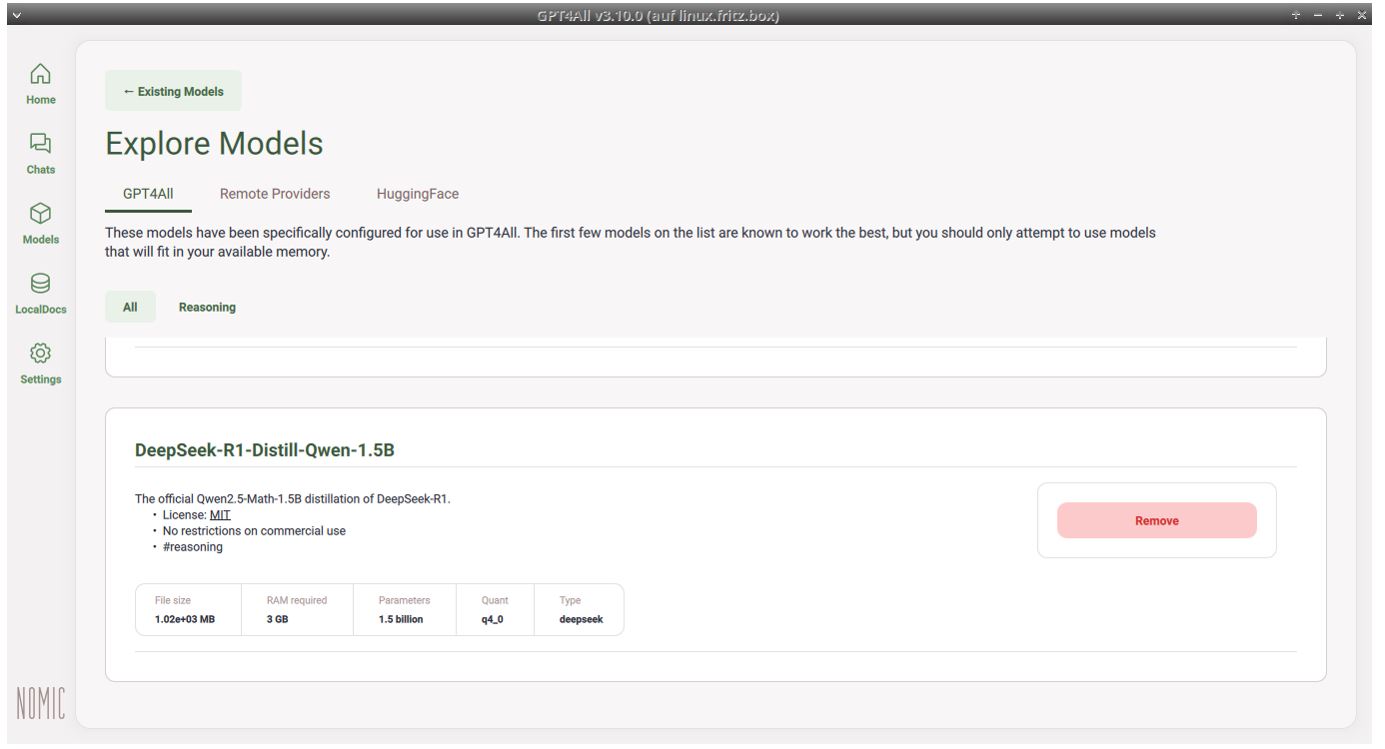
Abb. 6: Das Modell in GPT4All wählen
Der erste Chat mit GPT4All
Durch Klick auf „Chat“ ist es nun möglich, sich mit dem vorher installierten beziehungsweise ausgewählten Modell zu unterhalten. Da wir ja oben schon nach dem Commodore Amiga gefragt haben, fragen wir jetzt mal nach einem Commodore C16.
Fun Fact: Der Commodore C16 wurde nach dem Commodore 64 auf den Markt gebracht. Und obwohl er nur ein Viertel des Speichers des C64 hatte, waren seine Grafikfähigkeiten besser als die des C64. Aber nicht immer gewinnt der Bessere (siehe Video 2000 und VHS). So kam es, dass der C16 irgendwann für 150 DM bei Aldi verramscht wurde.
Aber schauen wir mal, was unser LLM dazu sagt (siehe Abb. 7).
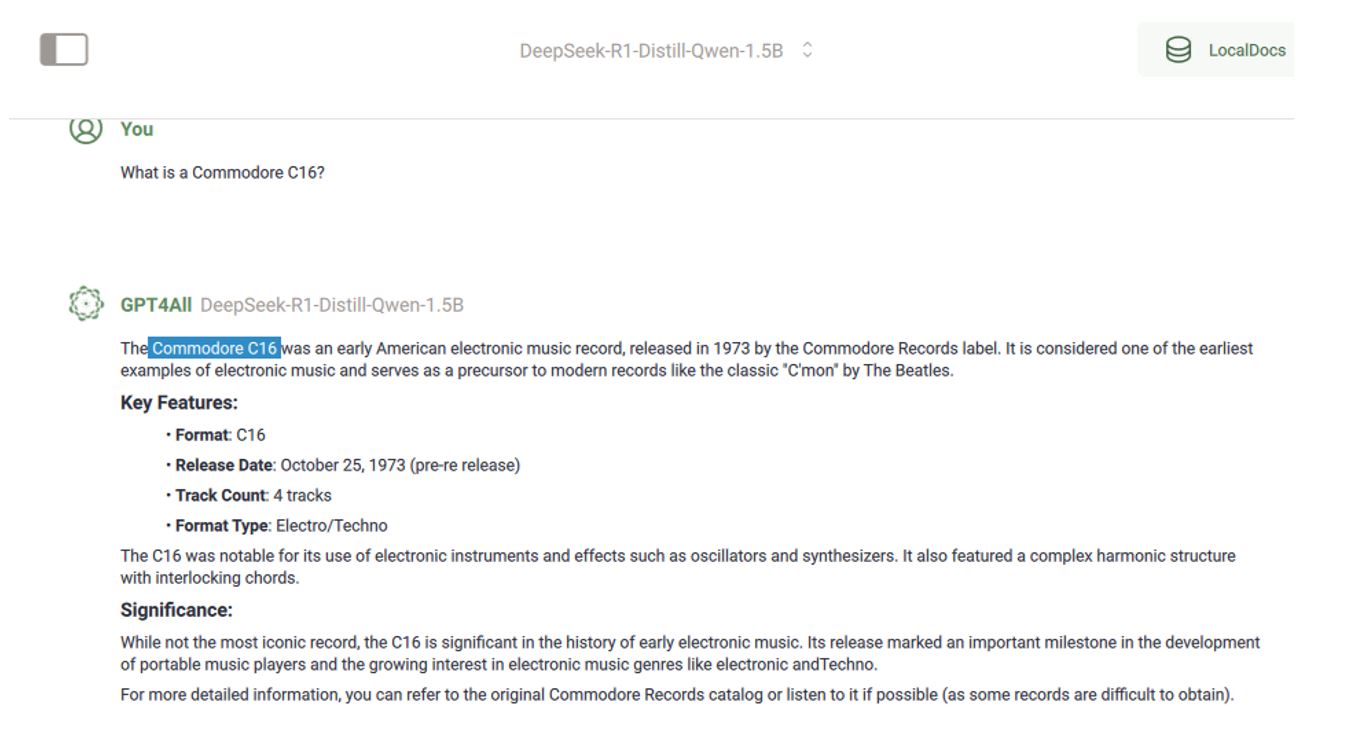
Abb. 7: Der Commodore C16 soll ein Musikalbum sein?
Hier hat die KI aber mächtig halluziniert! Ich habe einmal versucht, dieses Album zu finden – mir ist es nicht gelungen! Passt also gut auf, welches Modell ihr für welchen Zweck einsetzt!
Das Modell mit eigenen Daten trainieren
Jeder von uns hat seinen eigenen Stil, Dinge zu schreiben, beziehungsweise seine eigenen fachlichen Domänen, von denen fertig trainierte LLMs nichts wissen. Dies liegt daran, dass sie ohne Zugriff auf die persönlichen Dokumente trainiert wurden. Stell dir vor, ein Autobauer würde mit seinen Dokumenten ein LLM trainieren. Schon könnte jeder User etwas Informationen über den neusten Prototypen finden, da ja das Modell mit diesen Daten trainiert wurde. Aber auch Kundeninformationen haben nicht erst seit der DSGVO nichts in Netzen verloren, die für alle zugreifbar sind.
Ein oft beschrittener Weg ist hier, ein vortrainiertes Netz zu nehmen, das dann mit den eigenen Dokumenten feingetunt wird. Und genau dies machen wir jetzt auch!
Wähle den Punkt „LocalDocs“, damit du Dokumente, die bei dir lokal gespeichert sind, trainieren kannst. Beachte aber, dass diese als reine Texte oder PDFs vorliegen sollten. Sollte dies nicht der Fall sein, so musst du diese vorher konvertieren (siehe Abb. 8).
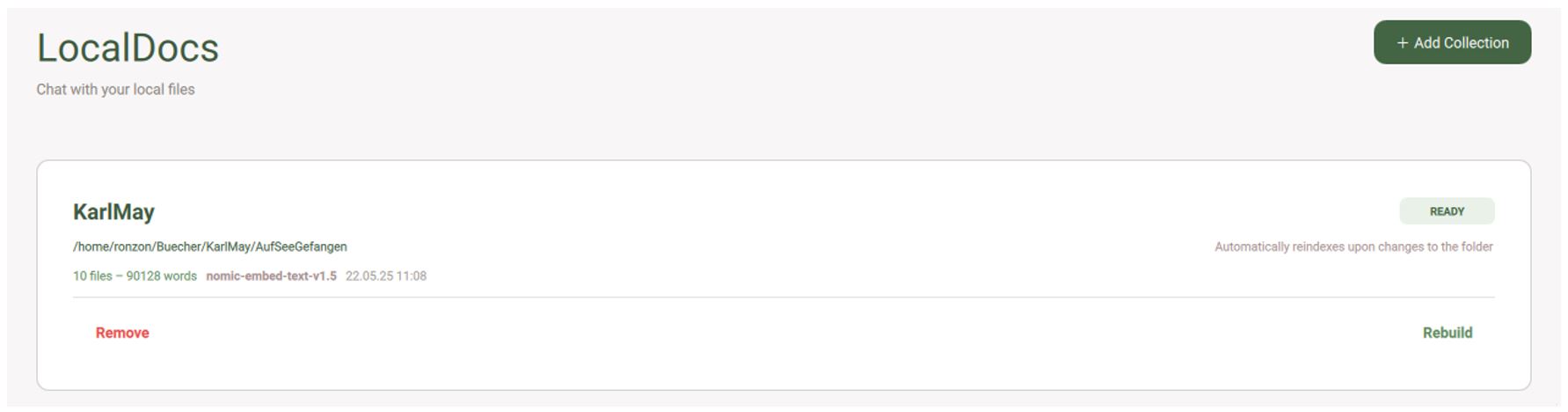
Abb. 8: Das Trainieren mit eigenen Daten
Beim Chat mit dem LLM kannst du nun auswählen, welche deiner Datenquellen mit einbezogen werden (siehe Abb. 9). Wie du siehst, habe ich einfach ein paar E-Books trainieren lassen. Da es sich bei epub um ein reines Textformat handelt, musste ich diese noch nicht einmal konvertieren.
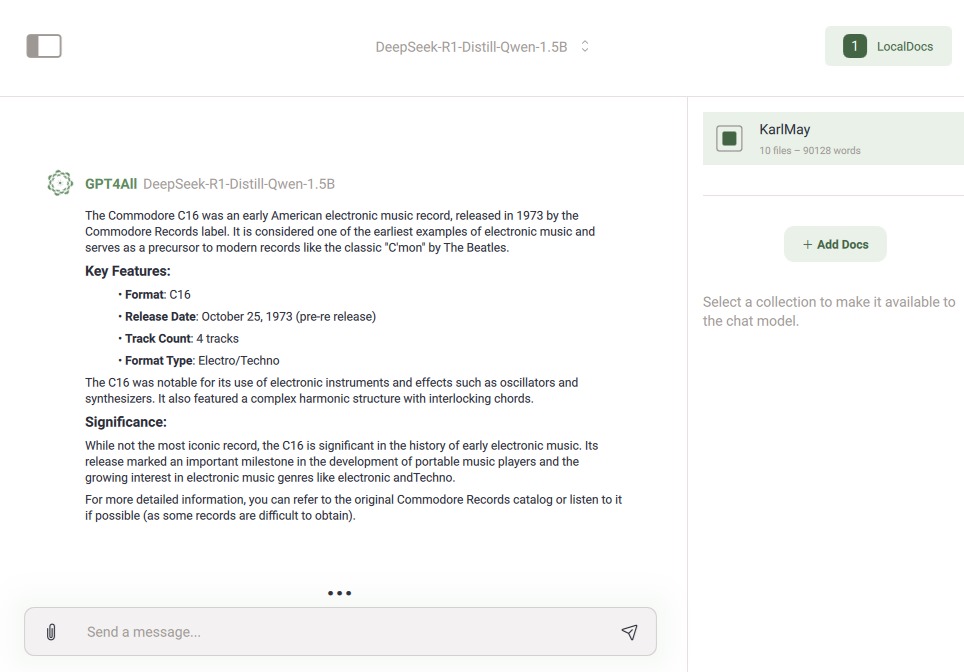
Abb. 9: Der Chat unter Einbeziehung eigener Datenquellen
Fazit
Das Betreiben von lokalen Modellen ist kein Hexenwerk! Beachte aber, dass die Auswahl eines Modells sowie das Nachtrainieren mit deinen Daten einiges an Arbeit erfordert. Wie so oft gilt auch bei der Auswahl von Modellen nicht „Viel hilft viel!“. Habe keine Angst, auch mal bewusst ein kleines Modell zu nehmen und an deine Bedürfnisse anzupassen.
Nicht immer braucht es dann einen Superrechner mit maximaler GPU-Leistung!
|
Von Data Poisoning spricht man, wenn die Daten, mit denen in unserem Fall das LLM nachtrainiert werden soll, „verschmutzt“ sind. Dies bedeutet, dass dabei zum Beispiel Dokumente sind, die ein eher schlechtes Beispiel für deine Texte sind oder aber veraltete Informationen haben. Oder aber Dokumente, die extra „verunreinigt“ wurden, um das LLM in eine andere (falsche) Richtung zu trainieren. Beispiel: Wenn ich ein Netz mit vegetarischen Gerichten trainieren soll – ich selbst aber Fleisch essen möchte, so könnte ich in die bestehenden Dokumente zum Beispiel Fleischrezepte „einschmuggeln“, indem ich hinter das vegetarische Rezept noch Fleischrezepte hänge, die in kleiner weißer Schrift auf weißem Grund sind. Ein menschlicher Leser wird dies womöglich gar nicht bemerken – eine Maschine trainiert aber einfach! Und sind diese Infos einmal im Netz, werden auch sie in der Ergebnismenge verwendet! Der redaktionelle Aufwand beim Trainieren von eigenen Daten ist hier nicht zu unterschätzen. In diesem Podcast geht es genau um dieses Thema. Mehr dazu unter: https://media.ccc.de/v/fsck-2025-133-llms-das-firmen-wiki-und-data-poisoning |









