

Für die meisten Data-Vault-Systeme wird ausschließlich auf integrierte Funktionalitäten relationaler Datenbanken zurückgegriffen. Im Gegensatz dazu werden bei Real-Time-Anforderungen neben Change-Data-Capture-Ansätzen moderne Frameworks aus dem Streaming-Bereich wie Kafka, Flink und Beam eingesetzt. Dieser gleichzeitige Einsatz von Cloud-Technologien erlaubt die weitergehende Automatisierung und die Nutzung von Managed Services der etablierten Anbieter. Außerdem können über die automatisierte Bereitstellung von Infrastruktur (Infrastructure as Code) und zugehörigen CI/CD-Pipelines die Aufwände der Entwicklungsteams minimiert werden.
Business Data Model als fachliche Vorgabe
Die Integration von Daten in Echtzeit ermöglicht die Nutzung neuer Architekturmuster wie zum Beispiel den Bezug von operativen und dispositiven Daten aus einer Datenquelle. Microservices müssen somit nicht mehr all ihre Quell-Schnittstellen kennen, sondern konsumieren Ereignisse der relevanten Geschäftsobjekte im Kontext. Eine Kernvoraussetzung hierfür ist ein semantisches Datenmodell (Business Data Model).
Das Business Data Model (BDM) eines Unternehmens ist eine ganzheitliche Sicht über System- und Geschäftsbereichsgrenzen hinweg zur Schaffung eines einheitlichen Verständnisses für die Informationen eines Unternehmens. BI-Projekte/-Systeme konsolidieren sehr heterogene Daten aus verschiedenen Quellen, die im Anschluss oftmals durch komplexe Transformationen für das Reporting aufbereitet werden.
Die Erstellung eines semantischen oder konzeptionellen Modells als primäre Diskussionsgrundlage sollte gängige Praxis sein. Dieses system-agnostische BDM schafft ein gemeinsames Verständnis für die Informationen eines Unternehmens. Obwohl diese fachliche Modellierung breite Anerkennung findet, ist sie bei vielen Unternehmen nicht fester Bestandteil der Projekte beziehungsweise einer gelebten Data-Governance-Organisation. Die fachliche Zusammenfassung der kritischen Geschäftsobjekte kann als Vorgabe für verschiedene logische Datenmodelle – nicht nur für den Data Vault – verwendet werden. Ein beispielhaftes BDM ist in Abbildung 1 dargestellt.
Im weiteren Vorgehen wird das BDM durch Zuordnungen von Datenquellen zu den BDM-Objekten erweitert, um daraus das Data-Vault-Modell als logisches Datenmodell zu erstellen.
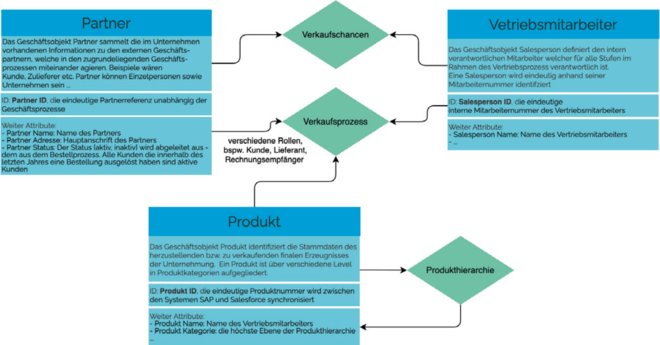
Abb. 1: Beispielhaftes Business Data Model
Code-Generierung für den Real-Time Data Vault
Ein wesentlicher Vorteil der Data-Vault-Modellierung ist die Möglichkeit zur automatisierten Code-Generierung durch die fest vorgegebene Logik zur Beladung der einzelnen Data-Vault-Entitäten. Ein Hub beispielsweise ist definiert als eindeutige Liste an Geschäftsschlüsseln. Daraus lässt sich ein einheitliches Lademuster für alle Hubs als Basis definieren. Dieses Lademuster gleicht neue mit bereits vorhandenen Datensätzen basierend auf den Schlüsseln ab und lädt nur unbekannte Datensätze in den Hub.
Diese einfachen Regeln ermöglichen es, maschinell den Code für Datenbank-Schemata (das physische Datenmodell) und die notwendigen Datentransformationen zu generieren. Gleiches gilt für die im Echtzeit-Kontext relevanten Streaming Engines. Grundsätzlich lassen sich drei Ansätze der Code-Generierung unterscheiden, die in Tabelle 1 inklusive Vor- und Nachteilen beschrieben werden.
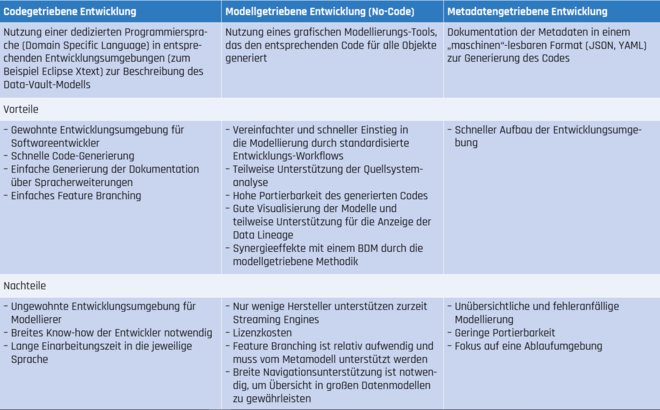
Tab. 1: Vor- und Nachteile der Automatisierungsverfahren
Architekturmuster für Echtzeitanwendungen
In den gängigen Architekturmustern kommen neben Streaming Engines sogenannte Event-Broker für die Verteilung der Daten zum Einsatz. Hierbei wird das Publish- und Subscribe-Muster zur losen Kopplung von Datenproduzent und -konsument mit Nachrichten-Warteschlangen kombiniert. Die Nachrichten haben dadurch eine Aufbewahrungsfrist und können durch mehrere Konsumenten gelesen werden. Architekturen unterscheiden sich somit hauptsächlich durch die parallele oder simultane Verarbeitung von Batch- und Streaming-Daten.
Data Vault mit Lambda-Architektur
Schon 2013 hat Nathan Marz die Lambda-Architektur vorgeschlagen (siehe Abbildung 2) [MaW13]. Die Idee hinter dem Architekturmuster ist die parallele Bearbeitung von Batch- und Stream-Daten. Es ermöglicht die Verarbeitung von Echtzeitdaten und zeitgleich die Durchführung von Initial- und Wiederholungsläufen der Datenverarbeitung im Batch-Modus.
In unserem Anwendungsfall zum Aufbau eines Real-Time Data Vault sind die Vorteile eine gute Balance von Durchsatz, Fehlerbehandlung und geringer Latenz. Nachteilig ist jedoch die höhere Komplexität und schlechtere Wartbarkeit durch Duplizierung und Ausführung des Codes auf verschiedenen Infrastrukturkomponenten. Zudem ist die Integration von Stream- und Batchdaten kompliziert, da zum Beispiel für Hubs und Links sowohl Batch- als auch Streaming-Prozesse in die Datenbankobjekte schreiben müssen.
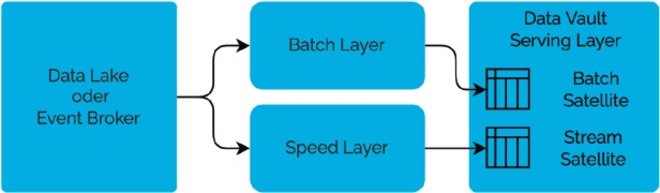
Abb. 2: Lambda-Architekturmuster
Data Vault mit Kappa-Architektur
Im Gegensatz zur Lambda-Architektur werden bei der Kappa-Architektur sowohl Batch- als auch Stream-Datenbereitstellungen über die gleichen Datenintegrationsstrecken verarbeitet (siehe Abbildung 3) [Kre14].
Der Vorteil ist, dass man nur eine Technologie und nur eine „Code Base“ zur Verarbeitung der Daten benötigt und die Datenstrecken nur einmal vorgehalten werden müssen. Datenanlieferungen im Batch-Betrieb können dadurch auch nachträglich auf Streaming umgestellt werden.
Nachteilig ist, dass Wiederholungsläufe nur dann funktionieren, wenn der Event-Broker die Eingangsdaten dauerhaft vorhält. Initialläufe dauern länger als bei der Batch-Verarbeitung und die Verarbeitung von späten Datenlieferungen, die nicht in der erwarteten Reihenfolge stehen, muss im Zielsystem abgefangen werden. Wenn man dies im Aufbau des Systems beachtet, überwiegen die Vorteile der Kappa-Architektur gegenüber der Lambda-Architektur.

Abb. 3: Kappa-Architekturmuster
Nutzung des Data Vault für die operative Datenintegration
Die oben genannten Architekturmuster haben die analytische Anwendung im Fokus. Es steigt allerdings der Bedarf, operative und analytische Anwendungen enger zu integrieren. Eines des wichtigsten Architekturprinzipien in der Softwareentwicklung ist die lose Kopplung von Systemkomponenten. Die Verwendung von Microservices ist ein gängiges Architekturmuster zur Erreichung dieses Ziels.
Ein Nachteil bei der Verwendung von Microservices besteht allerdings darin, dass jeder Konsument von Daten die Schnittstellen der notwendigen Microservices kennen muss. Wenn aber jeder Microservice seine Daten in Echtzeit in einen Event-Broker publiziert, der nach dem Muster des Data Vault aufgebaut ist, behält man den Vorteil der losen Kopplung bei, ohne den Kontext des Business Data Model zu verlieren.
Im Folgenden werden empfohlene Softwarekomponenten für die Architekturbausteine eines Real-Time Data Vault vorgestellt.

Abb. 4: Streaming von Microservice-Daten in den fachlichen Kontext
Software-Technologien
Wir greifen die Schichten der präferierten Kappa-Architektur auf und ergänzen diese um die Datenanbindung für eine applikationsorientierte Architektursicht.
Für den Aufbau eines Data Vault in Echtzeit werden die Änderungen in den Datenquellen zum Event-Broker gesendet, die Streaming Engine liest diese Eingangsdaten und generiert in Echtzeit die Ausgangs-„Topics“, die die Objekte des Data Vault repräsentieren. Diese können dann direkt konsumiert werden, zum Beispiel in einer relationalen Datenbank.
Datenanbindung
Je nach Quellsystemtyp kommen unterschiedliche Technologien für die Datenanbindung in Betracht. In der Regel werden relationale Datenquellen mit „Change Data Capture“ angebunden, sodass die an den Event-Broker gesendeten Nachrichten für relevante Tabellen die Anweisungen der Datenbank-Logs enthalten.
Software-as-a-Service-Applikationen bringen in der Regel REST- oder GraphQL-Schnittstellen mit. In manchen Fällen können Änderungen über sogenannte Webhooks via eine zu konfigurierende URL direkt an den Event-Broker oder ein vorgeschaltetes API-Gateway geschickt werden.
Kommt zum Beispiel Kafka als Event-Broker zum Einsatz, kann mit dem Kafka Connect Framework eine Vielzahl von unterschiedlichen Datenquellen angebunden werden.
Event-Broker
Apache Kafka ist einer der gängigsten Event-Broker am Markt. Für den produktiven Betrieb eines solchen Brokers ist aufgrund der Komplexität allerdings die Verwendung von verwaltenden Diensten wie Confluent oder AWS zu empfehlen.
Einen ähnlichen Event-Broker bieten auch die großen Cloud-Provider wie Microsoft mit dem Azure Event Hub oder Googles Pub/Sub-Dienst.
Der Event-Broker übernimmt die Funktion des zentralen Eingangskanals für alle Daten und löst somit die „Landing Zone“ des traditionellen Data Warehouse ab. Insbesondere wenn mehrere Konsumenten auf den Broker zugreifen, ist eine permanente Vorhaltung der Daten sinnvoll. Diese Funktion wird nicht durch alle Event-Broker unterstützt. Kafka bietet jedoch diese Möglichkeit, wobei ältere Daten aus Kostengründen zum Beispiel in ein AWS S3 ausgelagert werden können.
Streaming Engine
Für die Transformation der Daten wird eine Streaming Engine benötigt, die Eingangsdaten aus dem Event-Broker liest, verarbeitet und die transformierten Ergebnisdaten wieder an den Broker zurücksendet. Für die Auswahl der Streaming Engine sollte man beachten, dass es sich um parallele, skalierbare Plattformen handelt. So ist es für die Erzeugung eines korrekten Data Vault wichtig, dass im Rahmen der Fehlerbehandlung die Datensätze bei Konsumenten nur genau einmal ankommen.
Während viele Operationen in einem Datenfluss jeweils nur ein einzelnes Ereignis betrachten, benötigt man für manche Transformationen Informationen über mehrere zustandsbehaftete Ereignisse hinweg (zum Beispiel Window Operations).
Bei der Generierung eines Data Vault ist dies zum Beispiel die Deduplizierung von Datensätzen oder die Funktion, sich zu merken, ob ein Business Key schon in einem Hub ist.
Folgende gängige Streaming Engines bieten sich für die Implementierung unseres Architekturkonzepts an:
- Apache Flink wurde an der TU Berlin entwickelt und bietet eine verteilte Datenfluss-Engine, die es erlaubt, sowohl Datenströme als auch Stapeldaten zu verarbeiten. Mit Flink lassen sich insbesondere zustandsbehaftete Streaming-Transformationen vornehmen.
- Apache Spark Structured Streaming unterstützt eine Reihe von Programmiersprachen (Scala, Java, Python, R) und basiert auf der Spark SQL Engine. Für die Sicherstellung der Einzigartigkeit werden die Daten im Micro-Batch-Verfahren verarbeitet.
- ksqlDB baut auf Apache Kafka auf und verwendet das bereits weit etablierte SQL als Sprache. Einsteiger tun sich allerdings schwer mit den Besonderheiten einer Streaming Engine.
- Apache Beam ist ein Softwaremodell, um sowohl Batch- als auch Streaming-Applikationen zu definieren, die dann von unterschiedlichen Engines interpretiert werden können. Dazu gehören zum Beispiel Flink und Spark Structured Streaming sowie Google Dataflow.
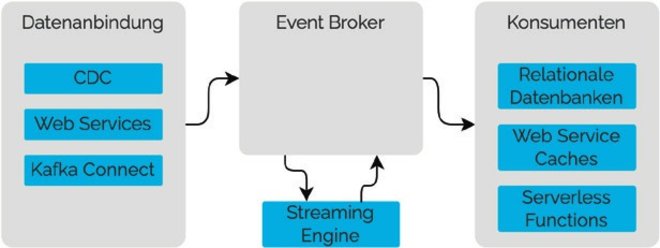
Abb. 5: Softwarekomponenten
Konsumenten
Durch die Datenintegration im Datenstrom ermöglicht das Architekturmuster eine Vielzahl gleichzeitiger Konsumenten. Der in der Datenbank gespeicherte Data Vault ist nicht mehr die Datendrehscheibe für Systemschnittstellen. Abhängigkeiten werden reduziert und zusätzliche Anwendungsfälle können einfacher umgesetzt werden.
Der Raw Data Vault kann direkt aus den Datenströmen (ohne weitere Transformation in der Zieldatenbank) konsumiert werden. Technologien sind entweder relationale Datenbanken (zum Beispiel Snowflake, Azure Synapse, Google Bigquery oder
On-Premises-Datenbanken) oder Data Lakes. Hier muss darauf geachtet werden, dass die Technologie das schnelle Schreiben von Einzeldatensätzen unterstützt. Dies kann entweder durch eine Kafka-Connect-Schnittstelle geschehen oder über zusätzliche Abstraktionsschichten (zum Beispiel Delta Lake, Iceberg, Hudi etc).
Häufig sollen die Daten im Data Vault auch anderen Abnehmern über Schnittstellen zur Verfügung gestellt werden. Damit diese APIs schnell Daten zurückliefern, sollten diese in einem Cache bzw. in einer In-Memory-Datenbank vorgehalten werden. Hier kommen Technologien wie Redis, Elastic oder Azure Cosmos zum Einsatz.
Der Komplexität der Stream-Data-Integration sind jedoch auch Grenzen gesetzt, insbesondere im No-Code-Ansatz. Um auch komplexere Transformationen in einer geringen Latenz zur Verfügung zu stellen, können Rohdaten oder auch Raw-Vault-Daten aus dem Broker durch eine Serverless Function (zum Beispiel AWS Lambda, Azure Function, GCP Cloud Function) gelesen, berechnet und in einer beliebigen Datensenke wieder zur Verfügung gestellt werden.
Referenzarchitektur Stream2Vault
Unser erstes Echtzeit-Data-Warehouse für die Allianz Versicherung [MSF15] basierte auf einer eigens entwickelten Programmiersprache zur Code-Generierung des Data Vault mittels Oracle Stored Procedures [BaT17]. Es entsprach somit noch nicht den in diesem Artikel vorgestellten präferierten Architekturentscheidungen.
Das in den letzten Jahren entwickelte Produkt Stream2Vault fußt hingegen auf dem modellgetriebenen No-Code-Ansatz nach dem Kappa-Architekturmuster und bietet dadurch einen hohen Grad der Automatisierung. Das betrifft nicht nur den Code, sondern auch den technischen Aufbau der Plattform, die Dokumentation in Form eines Datenkatalogs und den Betrieb.
Unter Verwendung des Kafka-Ökosystems (Kafka Broker, Kafka Connect, ksqlDB) und nach Vorgabe des unternehmensweiten BDM werden die Daten aus vielen heterogenen Datenquellen im Datenstrom geladen und zu einem Raw Data Vault transformiert. Dieser kann wiederum in diversen Datenbanksystemen in Echtzeit konsumiert werden. Die Infrastruktur wird durch „Infrastructure as Code“-Pipelines mit Hilfe von Terraform und Ansible automatisiert aufgebaut. Der cloudbasierte Service Vaultspeed ist als Umgebung für die Modellierung des Data Vault integriert. Der durch Stream2Vault generierte Code wird in Gitlab verwaltet, mit dessen Hilfe auch die Transporte in Abnahme- und Produktionsumgebungen vollautomatisch durchgeführt werden.
Bei Bedarf können weitere Abnehmer für andere Schnittstellen die Daten über APIs oder direkt im Datenstrom konsumieren. Der Data Vault wird Teil der operativen Datenintegration, stellt die heterogenen Datenquellen in den Kontext der jeweiligen Geschäftsobjekte und sorgt so für die Integration von dispositiven und operativen Daten in Echtzeit.
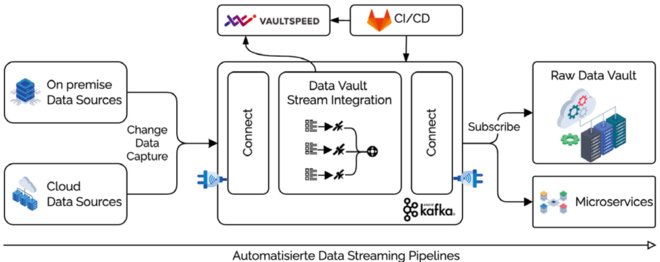
Abb. 6: Referenzarchitektur für den Real-Time Data Vault
Zusammenfassung
Die geringe Latenz eines Real-Time Data Vault ermöglicht den verstärkten Einsatz in der operativen Datenintegration. Das semantische BDM sorgt hier für die gemeinsam verstandenen Strukturen, während Cloud-Services und Infrastructure as Code den Aufbau der Plattform vereinfachen. Der Aufbau und Betrieb einer solchen Architektur ist und bleibt jedoch ein Unterfangen mit vielen Herausforderungen. Werden aber Datenarchitektur und Technologie wie hier vorgestellt optimal aufeinander abgestimmt, lässt sich die Komplexität auf ein beherrschbares Maß reduzieren und der Aufbau eines Real-Time Data Vault erfolgreich realisieren.
Weitere Informationen
[BaT17]
Baule, M. / Tanzer, W.: Unternehmensweite Datenmodellierung. TDWI Konferenz 2017, München
[Kre14]
Kreps, J.: Questioning the Lambda Architecture. 2.7.2014,
https://www.oreilly.com/radar/questioning-the-lambda-architecture/, abgerufen am 19.9.2022
[MaW13]
Marz, N. / Warren, J.: Big Data: Principles and best practices of scalable realtime data systems. Manning Publications 2013
[MSF15]
Mayer, V. / Schmid, W. / Feuring, N. / Maßing, D.: Anwender im Fokus: Transformation der Informationslandschaft – Allianz Global Corporate Speciality SE. In: BI-Spektrum 03/2015









