

Dieser Artikel stellt Ergebnisse vor, die im Rahmen eines industrienahen Forschungsprojekts namens PHILAE erzielt wurden. Das Projekt startete Ende 2018, läuft bis Mitte 2022 und umfasst drei Forschungslabore (FEMTO-ST – Besançon, LIG – Grenoble, SIMULA – Oslo) sowie zwei Unternehmen (Orange, Smartesting) [Philae].
Spuren der Nutzung
Das Projekt hat sich zum Ziel gesetzt, selbstlernende Regressionstests auf der Grundlage von „Spuren der Nutzung“ – den sogenannten „Traces“ – mittels KI automatisiert zu erstellen beziehungsweise zu verbessern. Dabei werden zwei Schmerzpunkte adressiert, mit denen sich Softwareteams aktuell konfrontiert sehen:
- die Relevanz von Regressionstests in Bezug auf die Abdeckung der Softwarenutzung sowie
- der sehr hohe Aufwand, der für die Erstellung und Pflege automatisierter Regressionstests erforderlich ist.
Im Rahmen des Forschungsprojekts wurde ein Tool-gestützter Prozess entwickelt, der sich in drei Schritte gliedert (siehe Abbildung 1), die wir an einem konkreten Beispiel erläutern, welches auf der API der E-Commerce-Software Spree [Spree] basiert.
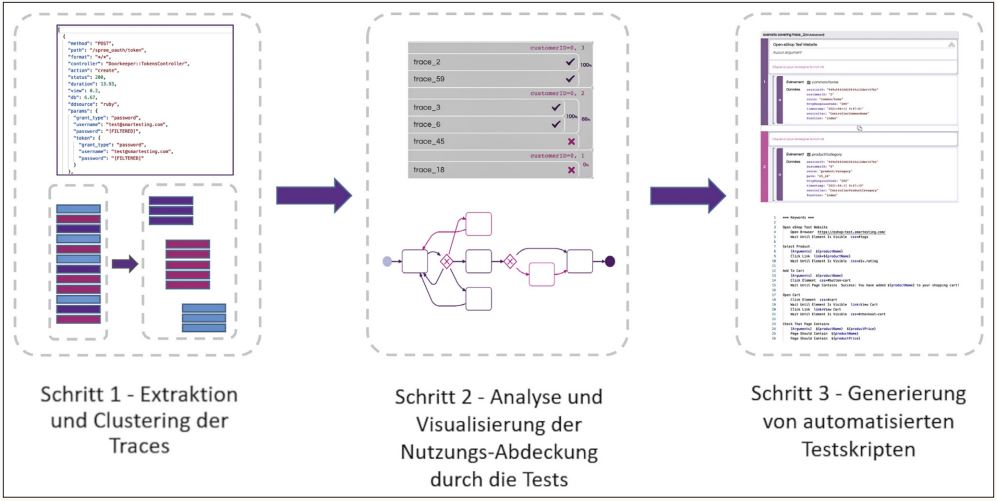
Abb. 1: Die drei Schritte des Prozesses: vom Log zu automatisierten Regressionstests
Schritt 1 – Extraktion und Clustering der Traces
Im ersten Schritt werden während der Nutzung der Software die protokollierten Ereignisse analysiert und nach fachlichen Kriterien zusammengefasst. Zur Erläuterung ist es hilfreich, einige Begriffe zu definieren:
- Eine Log-Datei ist eine Sammlung von Ausführungsereignissen, die normalerweise in einer Datenbank wie Elasticsearch gespeichert oder mit einem Monitoring-Tool wie Splunk, Dynatrace, Datadog oder Application Insight verwaltet werden.
- Ein Log-Ereignis ist das grundlegende Item in einer Log-Datei. Es handelt sich um ein aufgezeichnetes Ereignis mit einem Zeitstempel und einer Reihe von Merkmalen.
Im konkreten Beispiel entsprechen diese Log-Ereignisse Aufrufen der Spree-API im REST-Format.
- Einer „Spur“, auch Trace genannt, ist eine Sequenz von Log-Ereignissen, die einer Nutzungssitzung entsprechen. Dies ist zum Beispiel ein Nutzungsszenario in einem mit Spree betriebenen Online-Shop.
Im Detail werden drei Verarbeitungen durchgeführt:
- Erfassung von Log-Ereignissen über einen definierten Zeitbereich, eventuell gefiltert nach Ereignis-Typen;
- Interpretation der Log-Ereignisse und Bildung der Traces;
- Hierarchisches Clustering der Traces, um sie nach fachlicher Nähe zu gruppieren und in Form von Workflows zu visualisieren.
Jedes farbig gekennzeichnete Item links in Abbildung 1 entspricht einer Zeile in der Log-Datei. Diese Log-Ereignisse werden so sortiert, dass sie zusammenhängende Traces bilden, das heißt, der Abfolge von Ereignissen einer Benutzer-Session entsprechen. Die Berechnung der Traces aus den Log-Ereignissen stützt sich auf eine automatische Erkennung der Verkettung zwischen Ereignissen. In einfachen Fällen kann dies durch eine Sitzungs-ID erreicht werden. In komplexeren Fällen muss die Konfiguration der Verkettung von Log-Ereignissen manuell vorgenommen werden.
Nach der Berechnung der Traces werden diese mithilfe des hierarchischen Clustering nach dem Grad ihrer semantischen Nähe organisiert. Traces, die ähnlichen Ereignisfolgen entsprechen, werden vom hierarchischen Clustering-Algorithmus im hierarchischen Cluster nah zueinander positioniert (Abbildung 2, links). Dadurch wird es möglich, ähnliche Nutzungsszenarios als solche zu identifizieren.
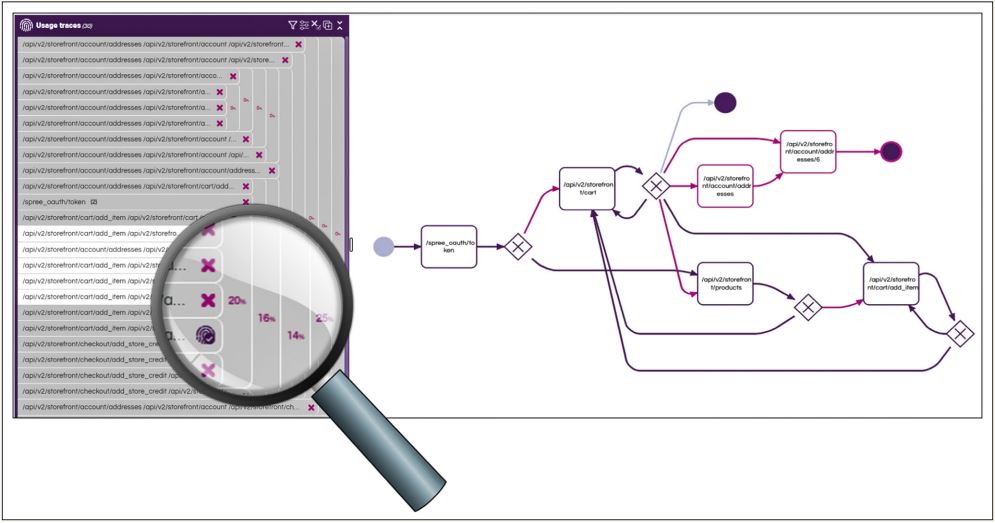
Abb. 2: Visualisierung der Traces und deren Abdeckung
Das Ergebnis wird in Form eines Workflows visualisiert (Abbildung 2, rechts). Die Darstellung wird automatisch mittels eines Abstraktionsalgorithmus aus dem modellbasierten Testen konstruiert.
Schritt 2 – Analyse und Visualisierung der Nutzungsabdeckung durch die Tests
Analog zur Berechnung der Traces aus den operativen Nutzungsprotokollen lassen sich auch Traces aus den Logs der Testdurchführung ermitteln. Die dazu erforderlichen Log-Dateien können aus einer automatisierten Testausführung (typischerweise Regressionstests), aber auch aus einer manuellen Ausführung (z. B. aus explorativen Testsitzungen) stammen.
Die so erhaltenen Testdurchführungs-Traces werden nun mit den Nutzungs-Traces verglichen, um die Abdeckung der Nutzung durch die Tests zu ermitteln. Abbildung 2 zeigt Ergebnisse und Visualisierung des Vergleichs der Traces aus der operativen Nutzung und denen der Testausführung. Violette Pfade sind Nutzungs-Traces, die durch mindestens eine Test-Spur abgedeckt werden. In Rosa dargestellt sind Traces, die von keiner Test-Spur abgedeckt werden.
Schritt 3 – Generierung von automatisierten Testskripten
Basierend auf der Abdeckungsanalyse können nun im dritten und letzten Schritt die Traces, die der Test bislang nicht abdeckt, für eine automatische Generierung von Testskripten in der Ziel-Automatisierungsumgebung extrahiert werden. In unserem konkreten Beispiel, dem Test der Spree API, werden die Tests mit Postman automatisiert.
Je nach gewünschtem Abdeckungsgrad können alle fehlenden Traces oder nur besonders repräsentative Traces generiert werden. Technisch gesehen erfolgt die Berechnung der zu automatisierenden Traces durch einfache Auswahl der nicht abgedeckten Traces.
Wir untersuchen auch Techniken zur automatischen Generierung aus einem Machine-Learning-Modell vom Typ „Transformer” [Wiki], die es ermöglichen, für eine Menge von Traces automatisch eine repräsentative Menge von Tests zu berechnen. Diese Deep-Learning-Techniken sind jedoch recht rechenintensiv, speziell hinsichtlich der Rechenzeit für das Erlernen des Modells. Daher ziehen wir derzeit eine halbautomatische, durch den Anwender gesteuerte Auswahl vor.
Bei den Log-Ereignissen in unserem Beispiel handelt es sich um REST-API-Aufrufe. Da die automatisierten Testsequenzen API-Aufrufen im gleichen Format entsprechen, wird der Übergang von den Log-Ereignissen zu den Testskripten durch die Zusammenstellung von REST-Anfragen erreicht. Diese werden schließlich in Postman veröffentlicht. In unserem Spree-Beispiel werden über 80 Prozent der Automatisierungsartefakte automatisch erzeugt. Nur einige Testdaten müssen manuell übernommen werden.
Erste Erfahrungen aus realen Projekten
Der beschriebene Prozess ist in einem Tool namens Gravity implementiert, das von Smartesting entwickelt wurde. Gravity wird zurzeit in realen Projekten mit API-basierten Testkontext erprobt. Dabei wurden folgende Punkte festgestellt:
- In den verschiedenen Projekten waren die erforderlichen Logs in einem Format verfügbar, welches es ermöglichte, sie direkt und ohne Nachbearbeitung zu verwenden. In allen Fällen werden diese Logs in einem geeigneten Tool verwaltet. Konkret sind uns folgende Tools begegnet: Dynatrace, Datadog, Splunk, Application Insight und Elasticsearch.
- Die Berechnung von Nutzungs-Traces, ihre Clusterbildung und Visualisierung in Form von Workflows erleichtert es dem Produktteam, die tatsächliche Nutzung durch die Nutzer/Kunden besser zu verstehen. In einigen Fällen wurden Nutzungen entdeckt, die dem Produktteam bis dahin unbekannt waren.
- Die Teams bewerten die Messung der Abdeckung und die Visualisierung dieser Abdeckung im Workflow als sehr nützlich, da sie ermöglicht, sich auf die wichtigsten Nutzungsszenarien zu konzentrieren und deren Test zu vervollständigen.
In dem am weitesten fortgeschrittenen Projekt lassen sich die Vorteile des Ansatzes bereits quantifizieren. Wir konnten:
- 4 Fälle aufdecken, in denen die API in einer Reihenfolge aufgerufen wurde, die so nicht vorgesehen war;
- 27 neue, automatisierte Tests hinzufügen und dadurch die Abdeckung der wichtigsten Benutzerpfade von 55 auf 80 Prozent erhöhen;
- den Aufwand für die Automatisierung der API-Tests in Postman um 50 Prozent reduzieren.
Die verbleibenden 20 Prozent der Pfade wurden vom Product Owner als selten und risikoarm eingestuft, weshalb ihre Überdeckung durch automatisierte Regressionstests für unnötig erachtet wurde.
Auch konkrete, methodische Aspekte der Umsetzung wurden im Rahmen der Erprobung identifiziert. Unter anderem hat es sich bewährt, die Erfassung der Logs zu Beginn des Prozesses auf repräsentative Ausschnitte der Nutzung auszurichten (z. B. einen Teil des Arbeitstages oder einen bestimmten Nutzertyp). Die Wahl der Ausrichtung hängt vom gewünschten Ziel ab, also davon, welcher Teil der Nutzung durch die Tests optimal abgedeckt sein soll.
Zusammenfassung und Ausblick
Zusammenfassend lässt sich sagen, dass sich funktionale Regressionstests im API-Kontext als Anwendungsfall für den PHILAE-Prozess bewährt haben. Es ist uns gelungen, dank dieses Prozesses eine gute Abdeckung der Nutzung zu erreichen und den Aufwand für die Testautomatisierung zu reduzieren. Damit erfüllt der Prozess die genannten Anforderungen an die Optimierung automatisierter Regressionstests für relevante Nutzungsszenarien.
Das Ergebnis der Analyse der Testabdeckung von Nutzungs-Traces wird visualisiert und kann jederzeit aktualisiert werden, wenn sich das Produkt weiterentwickelt und sich dadurch das Nutzerverhalten ändert.
Die Ergebnisse des Forschungsprojekts PHI-LAE sind in mehrfacher Hinsicht zukunftsweisend. Zum einen stärkt der erarbeitete Ansatz die Zusammenarbeit von operativen Ingenieuren (die die Logs verwalten) und Testern (die die Tests erstellen). Damit ist der PHILAE-Prozess Teil einer Entwicklung in Richtung DevOps.
Zum anderen wurde untersucht, inwieweit KI einen Beitrag zur Generierung von automatisierten Tests aus Logs leisten kann. Tatsächlich unterstützt die KI, genauer gesagt das Machine Learning, die Datenverarbeitung in allen drei Phasen des Prozesses:
- Clustering der Traces zwecks besseren Verständnisses, indem die Traces nach einer vom Modell berechneten semantischen Nähe gruppiert werden;
- Auswahl der Testdaten basierend auf einer Berechnung, die Nutzungs- und Testdurchführungs-Traces kombiniert, mit Clustering-Algorithmen, um Äquivalenzklassen aus den Testdaten zu extrahieren;
- Generierung repräsentativer Tests innerhalb eines Clusters unter Verwendung von Deep-Learning-Modellen des Typs „Transformer” aus dem Natural Language Processing (NLP).
Wir werden unsere Arbeit über das PHILAE-Projekt hinaus fortsetzen, um die Unterstützung für die automatische Erstellung und Pflege von Skripten für Regressionstests aus dem produktiven Einsatz zu erhöhen, mit dem langfristigen Ziel, einen autonomen Roboter für diese Regressionstests zu schaffen.
Referenzen
[Philae]
https://projects.femto-st.fr/philae/
[Spree]
Headless E-Commerce Plattform, Open Source, siehe:
https://spreecommerce.org/
[Wiki]
https://de.wikipedia.org/wiki/Transformer_(Maschinelles_Lernen)









