

Ablauf der Anomalieerkennung
Die Anomalieerkennung ist ein eigenes Modul in Python und läuft in drei großen Schritten ab. Grundlage dafür ist einerseits das Regelset und andererseits eine Klasseneinteilung, die sich aus dem Regelset ergibt. Die Klassen stellen Wertebereiche für den zu visualisierenden Wert dar. Ein Beispiel: Unsere Daten enthalten die Anzahl an täglichen Transaktionen. Wir nehmen an, dass alles zwischen 0 und 250 Elementen der Klasse „Normal” (N) zugeordnet werden kann. Die Klasse Large 1 (L1) betrifft alles zwischen 251 und 2500. So können beliebig viele Klassen erzeugt werden. Die Grenzwerte ergeben sich aus Domänenwissen, dem Regelset oder den Daten. Tabellenartige Daten werden in Python meist in der Pandas-Klasse DataFrame verwaltet. Wir fügen einem solchen DataFrame, der den Datensatz beinhaltet, Spalten für die Vorhersage aus dem Datum, dem Wert und den Anomaliestatus hinzu.
Im ersten Schritt erzeugen wir eine Klassen-Vorhersage aus dem Wert. Das entspricht einem einfachen Einsortieren nach den Grenzwerten. Anschließend wird im zweiten Schritt basierend auf unserem Regelset und dem Datum des Datenpunkts ebenfalls eine Klasse vorhergesagt. Wenn eine Regel beispielsweise besagt, dass die Klasse L1 einmal innerhalb der ersten drei Monatstage auftritt, setzen wir bei jedem Monat für die ersten drei Tage die Vorhersage auf L1.
Schließlich können wir im dritten Schritt den Anomaliestatus entscheiden. Dieser könnte beispielsweise als „Alles okay” (0), „Beobachten” (1) und „Fehler vermutet” (2) codiert sein. Im einfachsten Fall reicht es, die beiden Vorhersagen aus Datum und Messwert zu vergleichen. Stimmen diese überein, ist alles wie erwartet und der Anomaliestatus = 0. Stimmen sie nicht überein, ist der Status 1 beziehungsweise 2. Diese Unterscheidung könnte beispielsweise anhand der Differenz zwischen der Obergrenze der erwarteten Klasse und dem tatsächlichen Messwert getroffen werden. In anderen Worten: daran, wie viele Klassen zwischen der Erwartung und der Messung liegen.
Sobald die Regeln aber Zeiträume für das Auftreten einer Klasse zulassen, muss immer auch die Umgebung des jeweiligen Messwerts berücksichtigt werden. In unserem Beispiel die ersten drei Tage des Monats. Da wir wissen, dass L1 nur einmal innerhalb dieser drei Tage auftreten soll, können wir genau darauf prüfen. Dafür nutzen wir die Vorhersagen aus den Messwerten innerhalb dieser drei Tage. Tritt L1 genau einmal auf, können wir alle drei Tage mit dem Anomaliestatus „Alles okay” bewerten. Falls nicht, kann, je nach Geschmack, der Status „Beobachten” oder „Fehler vermutet” vergeben werden. Dieser Status wird dann für die Visualisierung auf Farben gemappt.
JavaScript, Angular und Plotly
Die besten und „smartesten” Daten nutzen wenig, wenn sie dem Menschen nicht durch eine geeignete Visualisierung zugänglich gemacht werden. Zur Darstellung wird eine Single-Page-Applikation basierend auf Angular verwendet. Vorteile von Angular sind unter anderem die Unabhängigkeit zum Client-Betriebssystem und auch eine einfache Aktualisierung. Es wird lediglich ein aktueller Browser benötigt. Für die Darstellung der in Python verarbeiteten Daten nutzen wir die weitverbreitete High-Level-Bibliothek Plotly. Diese kann sowohl in Python als auch in JavaScript verwendet werden. Wir nutzen die JavaScript-Version, um damit interaktive Plots zu zeichnen.
Die Eingabe für Plotly besteht aus dem JSON-Objekt, das vom Python-Skript erzeugt wurde. Dieses wird in Einzelteilen vom Backend in Redis (Teil 1, Abb. 1, Nummer 3) zwischengespeichert und bedarfsgerecht an das Frontend gesendet. Das Objekt muss lediglich an die Plotly-Bibliothek übergeben werden, die das Zeichnen der Charts übernimmt. Der Anomaliestatus, der als Farbe codiert ist, wird dabei als Balkenfarbe festgelegt.
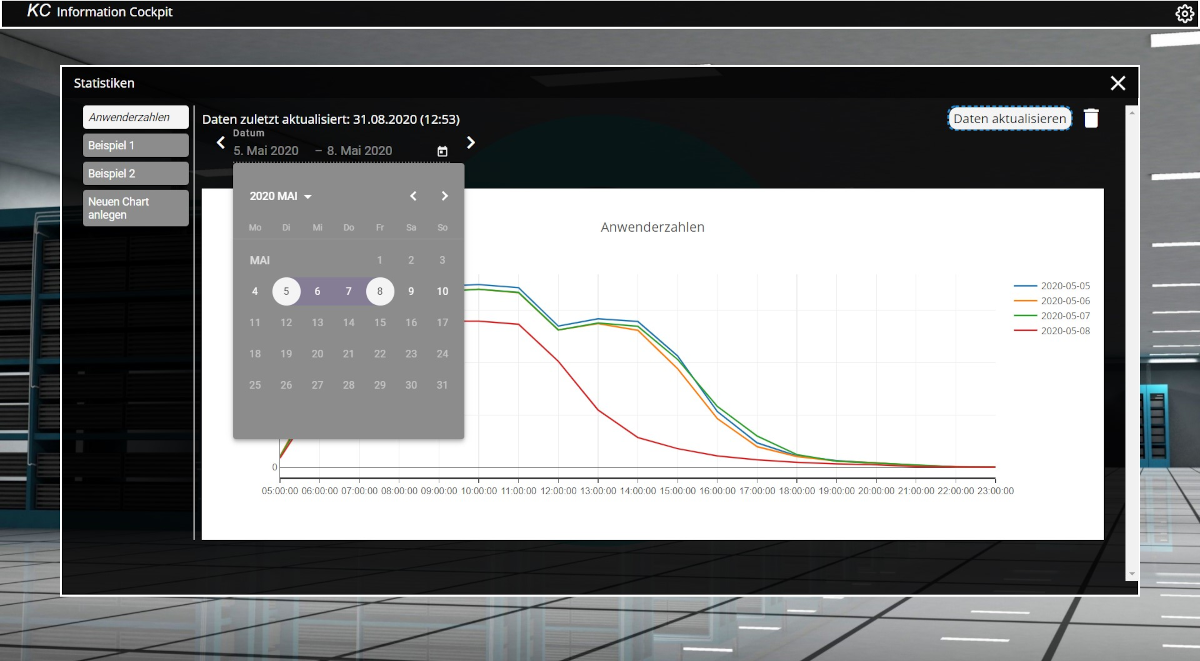
Abb. 1: Beispiel Anwenderzahlen
Im Architekturbild aus Teil 1 [Sch20] werden unter Punkt 2 Chart-Daten angefragt, dies entspricht dem „Use Case 1”. Die Antwort auf diese Anfrage ist im JSON-Objekt in Listing 1 zu sehen. Hier werden die Daten als „traces” und die Layout-Informationen als „layout” direkt vom Backend an das Frontend geschickt. Die Einzelinformationen, welche für einen Graphen gespeichert sind, werden hierbei aus Redis entnommen und in das JSON-Format zusammengesetzt. Zusätzliche Informationen für die Angular-Applikation sind der Titel und die letzte Aktualisierungszeit als „updateTime”. Die Informationen zu den Daten und Layout-Informationen werden ohne Nachbearbeitung im Frontend an die Plotly-Bibliothek weitergegeben und gezeichnet. Abbildung 1 zeigt die Oberfläche des Frontends und den Graphen, welcher aus dem Code in Listing 1 erzeugt wurde.
{
"title": "Anwenderzahlen",
"traces": [
{
"x": [ "05:00:00", "06:00:00", [...], "23:00:00"],
"y": [399.0, 9091.0, [...], 22.0 ],
"mode": "lines",
"type": "scatter",
"name": "2020-03-16",
"line": { "width": 2 }, "connectgaps": true,
"hoverinfo": "x+y+text"
},
[...]
],
"layout": {
"xaxis": { [... (Layout Information) ...] },
"yaxis": { [... (Layout Information) ...] },
"autosize": true,
"showlegend": true,
"title": "Anwenderzahlen",
"separators": ".,"
},
"updateTime": "31.08.2020 (15:00)"
}Angular Best Practices
Web-Development hat sich in den letzten Jahren durch das Entwickeln neuer Designparadigmen und Technologien grundlegend verändert. Um diese zu berücksichtigen und möglichst effektiv nutzen zu können, haben wir uns auf einige Best Practices für unser Projekt festgelegt, die wir nun näher erläutern wollen. Beginnen wir mit der Modularisierung ([Ste17], S. 103 ff.).
Modularisierung Core-Modul: In dem Kernmodul unserer Anwendung finden allgemeine Services Platz, die nur eine Instanz pro Anwendung besitzen. Beispiele hierfür sind in unserer Anwendung etwa ein Authentication-Service, mittels dem sich User anmelden können, sowie ein Information-Service, der Daten aus verschiedenen Schnittstellen einsammelt und für die weitere Verarbeitung bereitstellt. Das Core-Modul wird ausschließlich von dem App-Modul geladen, da sich hier Singleton-Instanzen von Services finden, die von jedem Teil der Anwendung genutzt werden können.
Shared-Modul: In diesem Modul werden alle „simplen” Komponenten und Pipes platziert. Diese Komponenten importieren/injizieren weder Services aus dem Core-Modul noch andere Feature-Komponenten in ihre eigenen Konstruktoren. Alle Daten, die sie benötigen, sollten sie durch das Template des übergeordneten Component erhalte, welches diese nutzt. Dies ist außerdem der perfekte Ort, um beispielsweise Angular-Material-Komponenten zu importieren und diese anschließend für die restlichen Anwendungsmodule zu reexportieren.
Feature-Modul: Feature-Module sollten für jedes unabhängige Feature der Anwendung erstellt werden. Wenn Feature-Modul A einen Service von Feature-Modul B benötigt, sollte man erwägen, diesen Service in das Core-Modul zu ziehen. Eine gute Faustregel ist es, Features, die keine Abhängigkeit zu anderen Features besitzen, nur aus Services aus dem Core-Modul und Components, die im Shared-Modul enthalten sind, zusammenzusetzen.
Lazy Loading
Durch die Modularisierung der Anwendung kann nicht nur die Entwicklung vereinfacht werden, da so das Projekt eine klare Struktur bekommt; weiterhin ermöglicht diese Trennung ein effektives Nutzen von Lazy Loading, was die Page-Load-Time der Anwendung erheblich reduzieren kann. Standardmäßig lädt eine Angular-Anwendung nämlich alle Module „eager”, das heißt, sie werden geladen, auch wenn sie noch gar nicht benötigt werden. Durch das Lazy Loading werden die Module jedoch nur bei Bedarf geladen – das hilft, sowohl die Bundle-Size zu reduzieren als auch die Ladezeiten niedrig zu halten (s. [Woi18] S. 319 ff.).
Dependency-Checking
Eine weitere Best Practice ist es, regelmäßig das Projekt auf nicht mehr benötigte Dependencies zu überprüfen. Hierdurch kann die Bundle-Size (und somit auch die Ladezeiten) weiter reduziert werden. Oftmals wird beim Überarbeiten von Code nicht berücksichtigt, dass bestimmte Abhängigkeiten nicht mehr benötigt werden. So kann man auch vermeiden, dass es durch etwaige Konflikte zu Fehlern kommt. Hier bieten sich statische Code-Analysetools an, wie beispielsweise das npm-package dep-check. Bei größeren Projekten sollten diese direkt in die CI-Pipeline integriert werden. Bei der Entwicklung unseres Cockpits kam dieses Vorgehen ebenfalls zum Einsatz. So konnten im Laufe der Entwicklung mehrere redundante Abhängigkeiten automatisiert identifiziert und entfernt werden, um die Page-Load-Time gering zu halten und die allgemeine Sicherheit zu verbessern. Weniger Abhängigkeiten bedeuten schließlich auch weniger potenzielle Fehlerquellen und Sicherheitslücken.
Code-Scanning
Jedoch hat es sich im modernen Web-Development bewährt, eine Vielzahl an unterschiedlichen Abhängigkeiten zu nutzen. Dies führt dazu, dass Entwickler kaum noch einen Überblick behalten können, welche externen Dependencies sie tatsächlich verwenden, entweder direkt in ihrer Anwendung oder indirekt durch das Nutzen von Bibliotheken.
Oftmals finden sich eklatante Sicherheitslücken nicht nur im eigentlichen Code der Anwendung, sondern sie werden auch über importierte Dependencies eingeschleust. Besonders wenn eine öffentlich zugängliche Anwendung entwickelt und gewartet wird, sollte man auf Code-Scanning des Repository setzen. Ein gutes Beispiel ist an dieser Stelle GitHub, welches für Projekte in unterschiedlichen Programmiersprachen Code-Scanning anbietet, um auf bekannte Sicherheitslücken zu testen. An dieser Stelle werden auch die von einem Projekt genutzten Abhängigkeiten geprüft. So können Security-Risiken automatisiert aufgedeckt werden und es ist Entwicklern möglich, je nach Dringlichkeit die nötigen Fehlerbehebungen zu priorisieren. Diese Technik haben auch wir angewendet. So wurden wir unter anderem auf eine Sicherheitslücke aufmerksam, bei der es möglich gewesen wäre, den Server zum Absturz zu bringen, und konnten diese durch das Aktualisieren der Bibliothek schließen.
Fazit
Durch die Verwendung des vorgestellten Stacks und der darin enthaltenen Technologien ist es für den Anwender möglich, Visualisierungen auf Basis von Plotly zu erstellen. Für diese Umsetzung wird lediglich die Implementierung des Stacks als Clone von GitHub sowie Docker benötigt. Sobald der Stack einsatzbereit ist, benötigt der Anwender nur noch Kenntnisse in Python für das Erstellen der Skripte zur Datenanalyse beziehungsweise -verarbeitung und in Plotly zur Visualisierung.
Die verwendeten Technologien werden alle aktiv weiterentwickelt. Diese sind durch die Docker-Plattform auf verschiedenen Systemen nutzbar und können über den DockerHub bezogen werden.
Durch die Verwendung von Payara als Applikationsserver können Java-Applikationen ohne Weiteres als Webservice bereitgestellt werden. Das gilt natürlich auch für andere Applikationsserver – einen kompletten Überblick liefert das Poster in Abbildung 2. Über das Docker-Netzwerk können die Services untereinander kommunizieren. Sofern keine explizite Portfreigabe für innen liegende Services besteht, können diese nicht direkt mit der Außenwelt kommunizieren. Somit ist ein Zugriff von außen auf die Datenbank oder den Python-Service nicht möglich. Weiterhin bietet die Docker-Plattform die Möglichkeit, mehrere Instanzen eines Containers zu starten. In Verbindung mit der Lastenverteilung können damit mehrere vom Nutzer angestoßene Python-Aktionen in mehreren Container-Instanzen parallel ausgeführt werden. Redis als In-Memory Key-Value-Storage bietet den Vorteil einer flexiblen Struktur der Datenhaltung durch die Nutzung von Keys. In Verbindung mit der Java-Bibliothek Jedis können die Daten in einfacher Weise gespeichert werden.
Die Daten können mit individuellen Python-Skripten vor deren Visualisierung beliebig verarbeitet werden. Python mit Gunicorn und Flask bieten eine Webservice-Schnittstelle zum Ausführen von Python-Skripten. Durch die Ablage von Python-Skripten des Benutzers zur Laufzeit ist kein Neustart des Systems notwendig, um Benutzeränderungen anzuwenden. Die Visualisierung in Angular mittels Plotly lässt zahlreiche verschiedene Darstellungen zu.

Abb. 2: Poster Applikationsserver-Vergleich
Weitere Informationen
[Sch20] Ch. Schnappinger, M. Keller, S. Steindl, E. Sultanow, Ein Architekturstack für Data Science mit Java, Python und JavaScript – Teil 1: Architekturkomponenten, in: JavaSPEKTRUM, 6/2020
[Ste17] M. Steyer, D. Schwab, Angular: Das Praxisbuch zu Grundlagen und Best Practices, O’Reilly, 2. Aufl., 2017
[Woi18] G. Woiwode, F. Malcher, D. Koppenhagen, J. Hoppe, Angular: Grundlagen, fortgeschrittene Techniken und Best Practices mit TypeScript – ab Angular 4, inklusive NativeScript und Redux, dpunkt. verlag, 1. korrigierter Nachdruck, 2018









