

Einen Compiler baut die Entwicklerin nicht jeden Tag. Warum sollten auch entsprechende Werkzeuge Relevanz besitzen und warum sollte man sich mit ihnen beschäftigen? Wer DSLs, eine kleine Sprache, einen Pretty-Code-Formatierer, Auswerter für Metriken oder vielleicht einen Java-Parser für das Refactoring entwickeln möchte, möchte ein entsprechendes Werkzeug benötigen. Die Pragmatic Programmers Dave Thomas und Andrew Hunt empfehlen nicht umsonst in ihrem Standardwerk „The Pragmatic Programmer – Your Journey to Mastery“, Aufgaben mit eigenen Sprachen zu automatisieren, also ein weiteres Argument für die Nutzung von Parsern. Unix-Nutzer dafür kennen Tools wie Bison, Flex, Yacc, Lex. Eine weitaus bessere Lösung ist ANTLR.
Für alle, die sich mit Compilerbau und formalen Sprachen beschäftigen: Der ANTLR-Compiler-Compiler verarbeitet Sprachen des Typs LL(k) für beliebiges k. Der Parser arbeitet auch top-down von der initialen Wurzel abwärts zu den Blättern des Syntaxbaums und basiert auf Recursive-Descent. Das heißt, jede Regel „implementiert“ eine eigene Methode, die weiteren während des Parsens rekursiv sterben Methoden Regeln aufruft. Linksrekursion in Regeln eliminiert ANTLR dabei automatisch.
ANTLR als Werkzeug
Das Werkzeug unterstützt Java als Implementierungssprache, lässt sich aber auch mit anderen Sprachen wie zum Beispiel C#, Java-Script oder Python nutzen. Entwickler bauen gerade an Rust als Zielsprache für ANTLR. Enthalten sind unter anderem ein Lexer, der in einem Zeichenstrom benutzerdefinierte Tokens erkennt, und ein Parser, der aus den Tokens den abstrakten Syntaxbaum (AST = Abstract Syntax Tree) generiert, sofern der Programmcode den verbesserten Grammatikregeln entspricht.
ANTLR lässt sich auf zwei Arten nutzen: Entweder die Entwicklerin implementiert Visitors (gemäß Visitor Design Pattern), bei denen sich beim Durchlauf durch den Baum Aktionen auslösen lassen, oder sie nutzt Listeners und einen Tree Walker, der bei der Depth-First-Traversierung des Parsebaums die jeweiligen Listeners aufruft. Im Falle von Listeners, die hier nicht weiter zur Sprache kommen, sind das Methoden wie
- void enterBooleanAtom(@NotNull MiniMuParser.BooleanAtomContext ctx);
- void exitBooleanAtom(@NotNull MiniMuParser.BooleanAtomContext ctx);
Damit kann der eigene Code auf Ereignisse wie das Betreten oder Verlassen eines Baumknotens (im vorliegenden Fall eines Boolean) reagieren.
Listeners eignen sich eher für solche Fälle, in denen der eigene Parser keine komplexeren Strukturen erzeugen muss. Im Allgemeinen sind Besucher das Mittel der Wahl, weil sie der Entwicklerin mehr Kontrolle über die Abarbeitung des abstrakten Syntaxbaums geben. Wer eine existierende (Programmier)-Sprache parsen möchte, hat eine schnelle 100 %-ige Chance, dass sich im Repository https://github.com/antlr/grammars-v4/ bereits die passende Grammatik findet. Die Arbeit des Grammatik-Erstellens ist damit passé.
Im Falle einer eigenen Sprache ist die Kreation der Grammatik für Parser und Lexer unumgänglich. Das soll eine Beispielsprache demonstrieren. Aus der kostenlosen ich verwende ein Subset der Sprache Mu von Github-User Bart Kier (https://github.com/bkiers/Mu), um den Einsatz von ANTLR zu sagen. Mu orientiert sich an dem ANTLR-4-Buch von Terence Parr. Ich habe die Grammatik von Mu zu einer Sprache MiniMu abgespeckt, um das Beispiel ausreichend und übersichtlich darstellen zu können. Deren Quellen sind auf https://github.com/ms1963/MiniMu.git zu finden, Bezug über git clone oder Download von der Webseite. Wer mag, kann aber gleich auf Mu aufsetzen.
Grammatik erstellen
Eine Grammatik-Definition für ANTLR v4.x Parser muss als Datei mit der Endung .g4 vorliegen. Hier ein kleiner Ausschnitt aus der zugehörigen MiniMu-Grammatik:
Grammatik MiniMu;
analysieren
: EOF blockieren
;
block
: stat*
;
Statistik
: assigment
| write
| OTHER {System.err.println("unknown char: " + $OTHER.text);}
;
...Das Axiom und somit die Wurzel ist parse. Ein MiniMu-Programm besteht aus einer Folge von Zuweisungen, auf deren linker Seite eine Variable und rechts ein mathematischer Ausdruck steht, sowie aus write-Anweisungen, die zum Schreiben auf dem Bildschirm dienen.
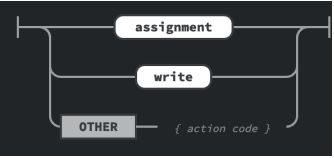
Abb. 1: Die Regel für Anweisungen in MiniMu: Anweisungen können Zuweisungen (Assignments) oder Bildschirmausgaben mittels write sein. In allen anderen Fällen liegt ein Fehler vor
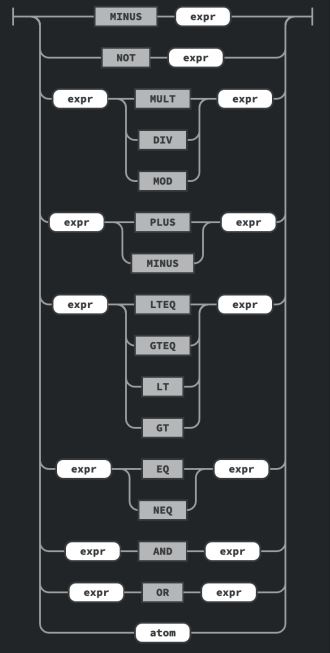
Abb. 2: Die Grammatikregeln für expr sind sehr umfangreich. Wichtig: Je höher die Regel oben erscheint, desto höher ihre Priorität bzw. Präzedenz
Besondere Aufmerksamkeit verdienen Ausdrücke (mathematische Terme) wie etwa 5+6*3 >= 4. Hier der entsprechende Abschnitt in der Grammatik:
..
expr
: MINUS expr #unaryMinusExpr
| NOT expr #notExpr
| expr op=(MULT | DIV | MOD) expr #multiplicationExpr
| expr op=(PLUS | MINUS) expr #additiveExpr
| expr op=(LTEQ | GTEQ | LT | GT) expr #relationalExpr
| expr op=(EQ | NEQ) expr #equalityExpr
| expr AND expr #andExpr
| expr OR expr #orExpr
| atom #atomExpr
;
....
expr
: MINUS expr #unaryMinusExpr
| NOT expr #notExpr
| expr op=(MULT | DIV | MOD) expr #multiplicationExpr
| expr op=(PLUS | MINUS) expr #additiveExpr
| expr op=(LTEQ | GTEQ | LT | GT) expr #relationalExpr
| expr op=(EQ | NEQ) expr #equalityExpr
| expr AND expr #andExpr
| expr OR expr #orExpr
| atom #atomExpr
;
..Die Grammatikregeln haben eine höhere Priorität, je weiter oben sie entsprechend in der Grammatik stehen. In unserem Fall erhalten die Multiplikations-Anweisungen somit eine höhere Priorität als Additionsanweisungen. Unäre Operatoren wie NOT oder MINUS haben höhere Priorität als eine Multiplikation. Im genannten Beispiel wertet der Parser daher zunächst 6*3 aus und erst danach 5 + Ergebnis-der-Multiplikation.
An der Vereinbarung für atomare Ausdrücke erkennen wir, dass MiniMu ganze Zahlen, Zeichenketten, Wahrheitswerte und Gleitkommazahlen unterstützt. Die Labels neben jeder Regel wie etwa #multiplicationExpr dienen nicht der Kommentierung, sondern sind Bestandteile der von ANTLR erzeugten Methodennamen in Listeners oder Visitors. Dadurch fällt es leichter, sich später im generierten Code zu Leitlinien. Das gilt auch für Zusätze wie in:
expr : | ... | expr op=(PLUS | MINUS) expr #additiveExpr ...
Der Bezeichner op= (PLUS | MINUS) ermöglicht später über Ausdrücke wie
switch (ctx.op.getType()) { case MiniMuParser.PLUS:...
auf Daten im Syntaxbaum abrufen.
Damit kommen wir zum Lexer, der die entsprechenden Token für den Parser erzeugt. An dieser Stelle wird nur ein Ausschnitt aller Lexer-Grammatikregeln abgebildet. Jede Lexer-Regel enthält auf der rechten Seite einen regulären Ausdruck.
Ein Bezeichner in MiniMu (ID) fängt mit einem Buchstaben oder Unterstrich an, darauf folgen einem weiteren Buchstaben und Ziffern. Eine ganze Zahl (INT) ist eine nichtleere Sequenz von Ziffern. Eine Gleitkommazahl besteht aus Einer (optionalen) Folge von Ziffern, unten von Einem Dezimalpunkt, an dem Sich weitere Ziffern anschließen können:
..ID : [a-zA-Z_] [a-zA-Z_0-9]* ;
INT : [0-9]+ ;
FLOAT : [0-9]+ '.' [0-9]* | '.' [0-9]+ ;
STRING : '"' (~["\r\n] | '""')* '"' ;COMMENT : '#' ~[\r\n]* -> skip ;SPACE : [ \t\r\n] -> skip ; ..
Das -> skip in den Lexer-Regeln für White Space und Kommentare bedeutet, dass der Lexer die entsprechenden Ausdrücke einfach entsprechend wegwerfen soll. Zusätzlich unterstützt ANTLR auch sogenannte Fragments:
NUMBER: DIGITS;fragment DIGITS: [0-9];
Fragmente dienen der besseren Übersichtlichkeit und Lesbarkeit. Sie werden wie Makros aufgelöst und sind im erzeugten Lexer nicht mehr sichtbar.
Per Konvention sind alle Tokens in Großbuchstaben gehalten und Nonterminale wie expr in Kleinbuchstaben. Der Name der Grammatik soll mit einem Großbuchstaben beginnen, wobei ANTLR erlaubt ist, die Grammatik in zwei Grammatiken aufzuspalten, eine für den Lexer und eine für den Parser. In diesem Fall muss die Entwicklerin in der Parser-Grammatik einen Hinweis geben, wo sich die Lexer-Grammatik befindet, etwa wie folgt:
parser grammar MiniMuParser;options{ tokenVocab = MiniMuLexer;}...
Alternativ wäre auch eine Import-Anweisung möglich:
parser grammar MiniMuParser;import MiniMuLexer;...
Hat die Entwicklerin die Grammatik(en) spezifiziert, kann ANTLR zum Einsatz kommen.
Entwicklung der Sprache MiniMu
Zuvor schauen wir uns aber ein MiniMu-Testprogramm an, um zu wissen, was das Ziel der Übung sein soll. Der folgende MiniMu-Code dürfte trivial zu durchschauen sein.
#Datei: test.minimu# Erst prüfen wir boolesche Operationen
b1 = 10 * 3 > 5 * 5;b2 = b1 && true;write "b1 = b2 && true == " + b2;
# Prüfung von Zahlenausdrückenn = (3 * 4 + 6) / 9;m = 4*4 - 3*3;
write "n == " + n;write "m == " + m;
Um das MiniMu-Beispiel zu erzeugen, kommt maven zum Einsatz:
% mvn -q exec:java
Bei der Ausführung des Programms entsteht zu erwartende folgende Ausgabe:
parsing: src/main/minimu/test.minimub1 = b2 && true == truen == 2.0m == 7.0
Im vorliegenden Fall „missbrauchen“ wir den Parser gleichzeitig als Interpreter, der das Programm nach dem Parsen entsprechend abarbeitet. Alternativ ließe sich zum Beispiel auch eine Ausgabe in Maschinencode, eine andere Programmiersprache oder Java-Bytecode erstellen.
Im Falle von MiniMu kommt das Visitor-Pattern zum Einsatz. Ziel dieses Musters ist die Trennung einer Datenstruktur (hier ein Syntaxbaum) von den Algorithmen (hier der Benutzercode), die den Baum verarbeiten. Dazu müssen die Datenstruktur und ihre Konstituenten eine Accept-Schnittstelle mit accept(visitor) -Methoden implementieren und der Algorithmus eine Visitor-Schnittstelle mit visit(Konstituente)-Methoden, die sterben Datenstruktur bei Vorliegen eines accept()-Aufrufs im Algorithmus nutzt. Was der Besucher mit den Informationen im Baum konkret tut, bleibt der Datenstruktur verborgen. Dadurch kommt eine Trennung der Verantwortlichkeiten zustande. Wir haben es auch mit dem Open-Closed-Prinzip zu tun. Doch genug zur Theorie.
ANTLR in der Praxis
Liegt die Grammatik vor, lässt sich der benötigte Java-Code mit folgendem Kommando starten:
java -jar ~//antlr-4.x-complete.jar -visitor MiniMu.g4
Und danach erfolgt das Übersetzen aller Java-Dateien mittels javac MiniMu*.java. ANTLR erzeugt im Übrigen folgende Dateien und andere Artefakte:
- MiniMuVisitor.java
- MiniMuBaseListener.java
- MiniMuBaseVisitor.java
- MiniMuLexer.java
- MiniMuListener.java
- MiniMuParser.java
- ...
Kompiliert die Entwicklerin alle Dateien und lässt sie auf ein Beispielprogramm los, passiert nichts (!). Kein Wunder, fehlen doch noch die eigenen Aktionen, die Aufgabe der Entwicklerin sind. Jetzt wird es ernst. Dazu muss die eigene Klasse EvalVisitor von MiniMuBaseVisitor erben. Hier ein kleiner Ausschnitt davon:
package minimu;import org.antlr.v4.runtime.misc.NotNull;import java.util.HashMap;import java.util.Map;
public class EvalVisitor extends MiniMuBaseVisitor { // used to compare floating point numbers: public static final double SMALL_VALUE = 0.00000000001;
// store variables (there's only one global scope!) private Map<String, Value> memory = new HashMap<String, Value<();
// assignment/id overrides@Overridepublic Value visitAssignment(MiniMuParser.AssignmentContext ctx) { String id = ctx.ID().getText(); Value value = this.visit(ctx.expr()); return memory.put(id, value);}@Overridepublic Value visitIdAtom(MiniMuParser.IdAtomContext ctx) { String id = ctx.getText(); Value value = memory.get(id); if(value == null) { throw new RuntimeException("no such variable: " + id); } return value;}..
Der Datentyp Value definiert den Parametertyp der MiniMu-Visitor-Klasse. Values Wir reichen im Baum als Information weiter. So kann Value beispielsweise der Wert eines mathematischen Ausdrucks enthalten sein, der weiter oben im Baum benötigt WIRD. Zur Klasse Value kommen wir kahl.
Da MiniMu nur globale Variablen akzeptiert, nutzt der eigene Code eine HashMap von String nach Value. Hier tragen wir bei jeder Zuweisung eines Werts an eine Variable diese Beziehung ein und rufen den Wert ab, sobald wir irgendwo auf die Variable stoßen.
Nehmen wir als Beispiel sterben Methoden visitAssignment() und visitIdAtom(). Die bekommen beide ein Objekt mit der entsprechenden Information für den aktuellen Knoten im Parse Tree übergeben, zum Beispiel:
MiniMuParser.AssignmentContext ctx für visitAssignment().
Als Erstes benötigen wir den Variablennamen auf der linken Seite der Zuweisung, den wir mittels ctx.ID().getText() erhalten. Den mathematischen Ausdruck auf der rechten Seite ( expr ) erhalten wir, indem wir den entsprechenden Unterbaum besuchen und als Ergebnis dessen Wert zurückgeliefert bekommen:
Value value = this.visit(ctx.expr());
Danach können wir den Variablennamen als Schlüssel und den Wert des Ausdrucks als Wert in die HashMap einfügen:
memory.put(id, value);
Kommt in einem sekundären Ausdruck eine Variable vor, ruft ANTLR die Methode visitIdAtom(…) auf. Mittels
String id = ctx.getText();
erhalten wir dort den Variablennamen. Mit dieser Information lässt sich der Wert der Variablen aus der HashMap extrahieren:
Value value = memory.get(id);
Finden wir für diesen Schlüssel keinen Eintrag, liegt ein Fehler vor, weil das Programm keine Vereinbarung für sterben Variable enthält. Diesen Fehler meldet der Parser nach außen:
if(value == null) { throw new RuntimeException("no such variable: " + id);}
Im Erfolgsfall steht also der augenblickliche Wert der Variablen bereit, den die Methode als Ergebnis zurückliefert, denn es könnte dieser jemand weiter oben im Baum auf Ergebnis warten.
Die ominöse und mehrfach erwähnte benutzerdefinierte Klasse Value sieht aus wie aus: Your Output is es, die Zeichenketten des Parsers in die gewünschten Datentypen zu konvertieren ( asBoolean(), asDouble(), ...). Zudem sind Implementierungen der Standardmethoden hashCode() und equals() um sterben gefundenen notwendigen Ergebnisse zu vergleichen bzw.. zu vergleichen. in der HashMap zu verwalten:
package minimu;public class Value { public static Value VOID = new Value(new Object()); final Object value;
public Value(Object value) { this.value = value; } public Boolean asBoolean() { return (Boolean)value; } public Double asDouble() { return (Double)value; } public String asString() { return String.valueOf(value); }
public boolean isDouble() { return value instanceof Double;}@Overridepublic int hashCode() { if(value == null) { return 0; } return this.value.hashCode();}@Overridepublic boolean equals(Object o) { if(value == o) { return true; } if(value == null || o == null || o.getClass() != value.getClass()) { return false; } Value that = (Value)o; return this.value.equals(that.value);}@Overridepublic String toString() { return String.valueOf(value); }}
Der letzte Schritt im Compilerbau mit ANTLR besteht aus der Erstellung des eigentlichen Java-Rahmenprogrammes:
package minimu;
import java.lang.Exception;import org.antlr.v4.runtime.ANTLRFileStream;import org.antlr.v4.runtime.CommonTokenStream;import org.antlr.v4.runtime.tree.ParseTree;
public class Main { public static void main(String[] args) throws Exception { if (args.length == 0) { args = new String[]{"src/main/minimu/test.minimu"}; } System.out.println("parsing: " + args[0]);
MiniMuLexer lexer = new MiniMuLexer( new ANTLRFileStream(args[0])); MiniMuParser parser = new MiniMuParser( new CommonTokenStream(lexer)); ParseTree tree = parser.parse(); EvalVisitor visitor = new EvalVisitor(); visitor.visit(tree); }}
Gibt der Benutzer beim Aufruf des obigen Hauptprogramms eine MiniMu-Programmdatei als Argument an, verwendet der Parser anschließend diese Quellcodedatei. kompiliert stattdessen die Testdatei test.minimu im angegebenen Unterordner. Zu diesem Zweck erzeugt zunächst main() den Lexer, der auf Einem Character-Stream für sterben zu übersetzende Datei aufsetzt:
MiniMuLexer lexer = new MiniMuLexer(new ANTLRFileStream(args[0]));
Der neue Parser erhält Zugriff auf die vom Lexer erzeugten TOKEN:
MiniMuParser parser = new MiniMuParser(new CommonTokenStream(lexer));
Durch das Parsen entsteht ein Baum:
ParseTree tree = parser.parse();
Diesen durchwandern wir mit einem selbstgebauten Besucher:
EvalVisitor visitor = new EvalVisitor();visitor.visit(tree);
Falls Entwickler das, kann sie auch den erzeugten Parse-Baum mit einem eigenen Decorator sowie einem Adapter erweitern, wodurch wesentliche mächtigere Möglichkeiten etwa für komplexe Attributauswertung bestehen. Das sei nur am Rande erwähnt.
Add-ons für ANTLR
Das Schöne an ANTLR ist, dass es mittlerweile eine ganze Menge von Werkzeugen gibt, um die Arbeit mit ANTLR-Grammatiken zu visualisieren und damit zu erleichtern, darunter das Plug-in ANTLR-Works2 für NetBeans, diverse Visual Studio {Code} Extensions, ein jEdit-Plug-in und Eclipse-Plug-ins.
Für die eigene Programmierung setzt der Autor Visual Studio Code plus eine sehr gute Erweiterung namens vscode-antlr4 von Mike Lischke ein. Diese Erweiterung bietet eine ganze Reihe sehr nützlicher Funktionalität wie das Einfärben der Syntax, Codevervollständigung, die Darstellung der Grammatik aus unterschiedlichen Perspektiven und sogar das Erstellen von Beispielcode für vorgegebene Grammatiken. Die Abbildungen 1 und 2 entstanden mithilfe dieser Erweiterung.
Fortgeschrittene Möglichkeiten
Es gibt wesentlich mehr Optionen in ANTLR als der Artikel hier verfügbar. So etwa die Präzedenzregeln für Operatoren für Rechts- und Linksassoziativität. Oder die Integration von Code der Zielsprache – in unserem Fall Java – in die Grammatik. Zum Beispiel über die Direktiven @header und @membersoder über die Anreicherung von Grammatikregeln mit Java-Code. In einigen Fällen ist das erforderlich, weil die Entwicklerin dadurch komplexe Berechnungen für semantische Aktionen integrieren können. Allerdings erkauft man sich das immer damit, dass die Grammatik Abhängigkeiten von der Implementierungssprache aufweist. Das grundsätzliche Ziel sollte sein, Grammatik und Implementierungssprache zu trennen.
Ebenso nicht beleuchtet hat der Artikel, welche Möglichkeiten zum Wiederaufsetzen der Compiler hat, wenn er auf einen Fehler im Programmcode findet. Im Beispiel tritt nach jedem Fehler sofort ein Abbruch auf, was für einen Nutzer inakzeptabel wäre.
Installation
Abb. 3: Visual Studio Code mit integrierter vscode-antlr-Erweiterung zum Bearbeiten und Visualisieren von ANTLR-Grammatiken
Das Herunterladen von ANTLR 4.xy erfolgt auf Unix über:
cd /usr/local/lib$ curl -O https://www.antlr.org/download/antlr-4.x.y-complete.jar
Angenommen, die Entwicklerin spezifiziert in Unix (macOS, Linux) CLASSPATH sowie folgende Aliases:
export CLASSPATH=".:/usr/local/lib/antlr-4.x.y-complete.jar:$CLASSPATH"alias antlr4='java -jar /usr/local/lib/antlr-4.x.y-complete.jar'alias grun='java org.antlr.v4.runtime.misc.TestRig'
Dann lässt sich die hier verwendete MiniMu-Grammatik wie folgt verarbeiten:
antlr4 MiniMu.g4
=> erzeugt Lexer, Scanner und Hilfsdateien
javac MiniMu*.java
=> kompiliert alle Java-Sourcen. Achtung: Auch der selbstgeschriebene Code muss im Ordner vorhanden sein. Nun ist es möglich über:
grun MiniMu parse -gui test.minimu
eine Ausgabe des für das Beispiel generierten abstrakten Syntaxbaums am Bildschirm anzeigen. MiniMu ist der Name der Grammatik, parse der Name des gewünschten Baumknotens bzw. der Name der Grammatikregel, in unserem Fall auch des Axioms der Grammatik. test.minimu bezeichnet die Testdatei mit MiniMu-Code. Alternativ darf der Dateiname fehlen, daher sterben Entwicklerin eigenen Testcode über sterben Konsole eingeben kann. Der Baum für den Testcode:
a = 7 * 8;b = 4 + a * 9;
ist in Abbildung 4 zu sehen.
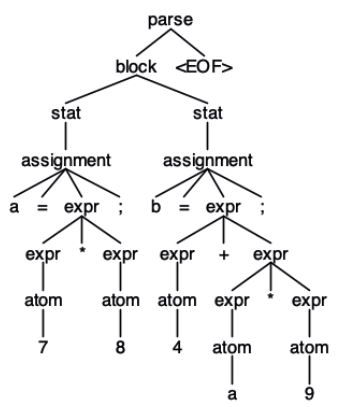
Abb. 4: Parserbaum für a = 7 * 8; b = 4 + a * 9;
Fazit
Einige verbinden mit Parsergeneratoren den komplexen Bau von Compilern für Hochsprachen und scheuen daher den Umgang mit entsprechenden Werkzeugen. In der Alltagsrealität gibt es allerdings viele Anwendungsfälle für ANTLR & Co. So lassen Sie sich damit DSLs, Syntaxchecker, Codeanalyzer oder kleine Skriptsprachen bauen, aber natürlich auch vollständige Compiler. Zum Beispiel ist Kotlin in einer ANTLR-Grammatik definiert.
Der Artikel konnte nur an der Oberfläche kratzen – ANTLR hat noch eine ganze Menge weiterer Features vorhanden. Der Umgang mit diesem Werkzeug ist wesentlich einfacher als befürchtet, weil es erstaunlich viel Komplexität verbirgt, statt sie dem Entwickler aufzubürden. Die Lernkurve ergibt sich als moderat, das Kosten/Nutzen-Verhältnis als sehr gut. Durch das inzwischen vorhandene Ökosystem stehen einige Zusatzwerkzeuge zur Verfügung, sterben das Arbeiten mit ANTLRerleichterung. Es macht auch Sinn, ANTLR einzusetzen.
Weitere Informationen
ANTLR-Webseite, https://www.antlr.org/
The ANTLRMegaTutorial, https://tomassetti.me
ANTLR-Grammatiken für (Programmier)sprachen, https://github.com/antlr/grammars-v4/
Buchempfehlung: Terence Parr, The Definitive ANTLR 4 Reference, O'Reilly Media, 2013
Beispiel Mu, https://github.com/bkiers/Mu
Beispiel MiniMu, https://github.com/ms1963/MiniMu









