

Hier bietet sich die Chance, KI-Initiativen wieder stärker mit dem DWH zu konsolidieren, um von den Maßnahmen zum Umgang mit der DSGVO zu profitieren. Dieses Vorgehen wird an einem Beispiel erläutert. Zusätzlich werden weitere Empfehlungen gegeben, wie die Modellqualität im Zeitverlauf sichergestellt werden kann.
Die statistische Analyse von Daten und maschinelles Lernen sind schon immer ein Teil von Business Intelligence (BI), doch mit neuer Software, mehr Rechenleistung und vor allem einem größeren Datenschatz hat das Thema unter dem Begriff der Künstlichen Intelligenz stark an Bedeutung gewonnen. Oft ist nicht die IT der Treiber hinter KI-Projekten, sondern es wird unabhängig in den Fachbereichen nach Anwendungsgebieten gesucht, die nötigen Daten aus diversen Quellen gesammelt und in KI-Modelle überführt. Das klassische DWH spielt oft nur eine untergeordnete Rolle in diesen schnelllebigen Experimenten, da Data Scientists lieber auf Rohdaten zurückgreifen und nicht auf Entwicklungen im DWH warten möchten. In BI-SPEKTRUM Ausgabe 2/2019, unter anderem [Baa19], werden einerseits viele gute Argumente genannt, die für verteilte Initiativen und fachspezifische Projekte sprechen, und andererseits organisatorische Vereinheitlichungen und die Nutzung gemeinsamer Ressourcen motiviert, damit klassische BI und KI-Projekte besser verzahnt werden. Dieser Artikel vertieft das Thema mit einem Fokus auf Daten und der Veränderung aufgrund von Zeit und Regulatorik.
Beispiel Handelskonzern
Als Beispiel für diesen Artikel dient ein fiktiver Handelskonzern (Abbildung 1), in dem sich verschiedene KI-Initiativen innerhalb der Fachbereiche gebildet haben. Für die Initiativen werden sowohl Daten aus dem DWH als auch direkt aus den Quellsystemen herangezogen, da nicht alle für relevant befundenen Daten im DWH zur Verfügung stehen. In den folgenden Bereichen haben sich KI-Initiativen gebildet:
- Personalisierte Werbung und Produktempfehlungen im Marketing
- Betrugserkennung im Rechnungswesen anhand des Kaufverhaltens und der Zahlungsmittel
- Versandoptimierung und Einsatzplanung in der Logistik, basierend auf dem erwarteten Bestellvolumen
- Automatisierte Bewerberauswahl im Personalwesen
- Daneben gibt es noch eine KI-Initiative aus dem DWH/BI, welche die bestehenden Analytics-Applikationen und neue Anwendungsfälle, die über die IT beauftragt sind, bündelt und sich rein aus den Daten des DWH speist.
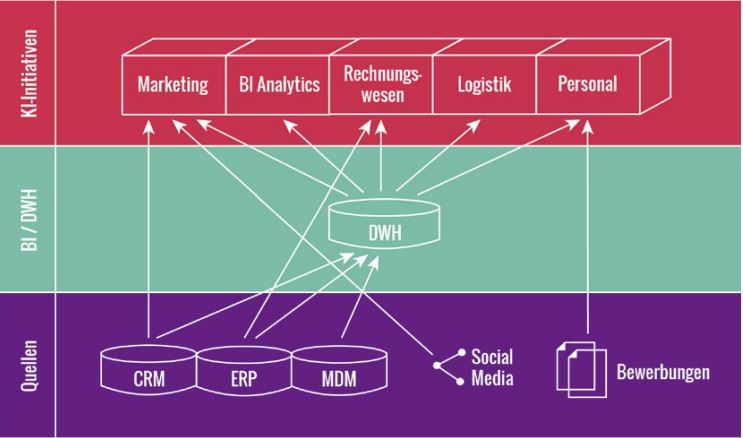
Abb. 1: KI-Initiativen und Datennutzung in einem beispielhaften Handelskonzern
Um im Weiteren die Herausforderungen und Lösungsansätze an einem konkreten Fall zu erläutern, wird die KI-Initiative des Marketings genauer betrachtet. Damit den Kunden personalisierte Produktvorschläge gesendet werden können, werden folgende Daten einbezogen:
- Vergangene Bestellungen aus dem DWH
- Kundendaten und Korrespondenz aus dem CRM-System (Alter, Geschlecht, Wohnort, Einkommen)
- Interessen und weitere Kundendaten aus verknüpften Social-Media-Konten (Beziehungsstatus, Herkunft, Beruf)
Diese Daten werden transformiert, um abgeleitete Features ergänzt und in einer CSV-Datei gespeichert. Auf dieser Basis werden dann verschiedene Modelle gelernt und verglichen. Das Modell soll für jeden Kunden relevante Produktgruppen identifizieren und konkrete Produktvorschläge zum Kauf machen.
Herausforderung DSGVO
Die DSGVO stellt eine Herausforderung für alle Systeme dar, die personenbezogene Daten nutzen. Die Verwendung ist so lange in Ordnung, wie eine entsprechende Einwilligung zur Verarbeitung der Daten vorliegt, zum Beispiel über AGB, und die Nutzung im gesetzlichen Rahmen erfolgt. Doch wenn der Nutzung widersprochen wird oder die Geschäftsbeziehung beendet ist, dürfen diese Daten nicht mehr verwendet werden und müssen entsprechend gelöscht oder so anonymisiert werden, dass auch indirekt kein Rückschluss auf Personen mehr möglich ist.
Jedoch gelingt die Einhaltung nicht immer. So wurde kürzlich Delivery Hero bzw. der neue Eigentümer Takeaway mit dem bisher höchsten in Deutschland verhängten Bußgeld aufgrund der DSGVO belegt [Gol19]. Zwar ist nicht bekannt, ob und wie viel KI zur Erstellung der geahndeten Werbe-Mails an ehemalige Kunden genutzt wurde, aber personalisierte Werbung ist ein wichtiges Anwendungsgebiet für KI. Die Vermutung liegt nahe, dass es hier kein zentrales Vorgehen zur Einhaltung der DSGVO gab oder dieses nur unzureichend war. Außerhalb Deutschlands wurden sogar deutlich höhere Strafen verhängt, zum Beispiel gegen Google [Net19].
Wie die DSGVO eingehalten werden kann und wie sich dies auf die Vorhersagequalität auswirkt, wird im Folgenden genauer betrachtet.
Der steinige Weg in die Produktion
Wichtig für die Einhaltung und die Auswirkungen der DSGVO ist die Frage, wie die Daten in den verteilten KI-Initiativen gespeichert und den Modellen zur Verfügung gestellt werden, sobald diese produktiv genutzt werden.
Der Start verteilter KI-Initiativen und die Abschätzung, ob die identifizierten Use-Cases einen Nutzen bringen können, sind in relativ kurzer Zeit möglich. Dies gilt es auch beizubehalten, damit viele Möglichkeiten ausprobiert und verworfen werden können, sodass nur die besten Modelle in einen produktiven Betrieb überführt werden. In der Phase des Experimentierens befinden sich momentan noch viele KI-Initiativen. Das bedeutet aber nicht, dass man sich erst mit der Überführung in die Produktion beschäftigen sollte, sobald ein gutes Modell gefunden ist. Der Fehler, den Schritt von der Evaluation zum Deployment im CRISP-DM-Modell (Abbildung 2) als blinde Übergabe an die IT durchzuführen, wird häufig gemacht und führt dazu, dass auch gute Use-Cases nie wirklich produktiv genutzt werden und so viel Potenzial verloren geht [KDD17].
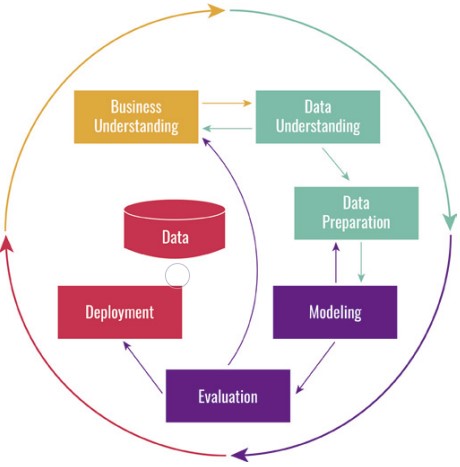
Abb. 2: CRISP-DM
Einbruch der Vorhersagequalität durch Löschung
Eine Variante, die Produktempfehlungen in die Produktion zu bringen, ist der Bau eines kleinen Service ohne langfristige Datenhaltung. Mittels dieses Service werden zuerst die Daten aus den Quellen extrahiert, so wie es zum Training des Modells manuell gemacht wurde. Anschließend wird der Service in eine bestehende Anwendung für Werbe-Mails integriert. Dies funktioniert kurzfristig gut, solange sich die Daten in den Quellen nicht stark verändern.
Die Änderung der Daten über die Zeit führt gewöhnlich zu einer Verschlechterung der Vorhersagequalität, weshalb das Modell regelmäßig auf Basis neuer Daten aufgefrischt werden muss. Für die feingranulare Empfehlung geeigneter Produkte in Unterkategorien ist auch eine große Menge an Bestellungen von Kunden mit ähnlichen Interessen nötig, denn je mehr Daten vorliegen, desto genauer wird die Vorhersage. Abbildung 3 zeigt, wie ein Modell veraltet, aber mit jeder Iteration eine bessere Vorhersagequalität erhält.
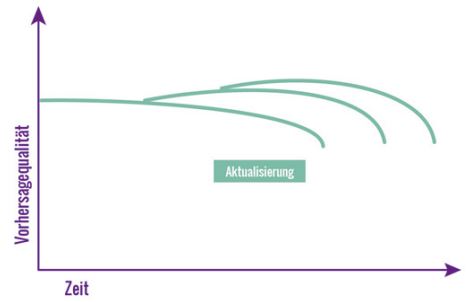
Abb. 3: Aktualisierung von KI-Modellen
In Quellsystemen, die auf Standardsoftware basieren, ist in der Regel keine Anonymisierung vorgesehen, sondern Daten werden gelöscht, wenn sie nicht mehr verwendet werden dürfen. Für das Beispielmodell bedeutet das Fehlen der Kunden- und aller damit verbundenen Daten einen Einbruch der Qualität, da es nur noch unzureichend trainiert werden kann (Abbildung 4).
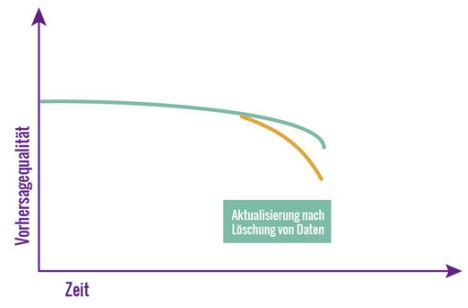
Abb. 4: Einbruch der Vorhersagequalität durch Löschung
Eigene historische Datenhaltung je KI-Projekt
Betrachtet man das Beispiel des Handelskonzerns in Abbildung 1, so erinnert dieses Bild an alte DWH-Strukturen mit vielen unabhängigen Data Marts. Im DWH hat man gelernt, dass in diesen verteilten Strukturen keine konsistente Historie und keine gemeinsamen Definitionen von Kennzahlen sichergestellt werden können. Dieses Problem trifft auch auf verteilte KI-Initiativen zu. Oft besteht der Wunsch, alle Daten unverändert zu speichern, um sich jede denkbare Analyse offen zu halten. Für personenbezogene Daten ist das jedoch unzulässig. Neben dem DWH müsste auch separat für jedes KI-Projekt, das kopierte Datenbestände nutzt, dafür Sorge getragen werden, dass eine Löschung/ Anonymisierung der Daten sowie ein passender Auslösemechanismus korrekt umgesetzt werden.
Konsolidierung mit dem DWH
Die dritte Option besteht darin, die verteilten KI-Projekte wieder mit dem DWH zu konsolidieren. Dies ist analog zu Self-Service-BI zu sehen.
Wie kann das DWH helfen, die zuvor beschriebenen Herausforderungen zu lösen?
Über die Auswirkungen der DSGVO im DWH und mögliche Lösungen wurde in BI-SPEKTRUM bereits mehrfach geschrieben. So wurde in [Eul18] gezeigt, wie eine Löschung vermieden und die technischen Beziehungen im DWH erhalten bleiben können, während schützenswerte Attribute anonymisiert werden. Dazu können Schwellenwerte definiert werden, sodass keine Kombination von Attributen aufgrund zu geringer Kardinalität eine indirekte Identifizierbarkeit ermöglicht. Tabelle 1 zeigt die Faktentabelle Bestellungen. Diese enthält nur Fremdschlüssel und Fakten – keine personenbezogenen Daten. Tabelle 2 zeigt die Dimensionstabelle Kunden. In dieser existieren personenbezogene Daten, aber zusätzlich Gruppen, die zwar immer noch interessante Analysen erlauben, jedoch keine Rückschlüsse auf die Person zulassen. Eine intelligente Bildung von Gruppen hilft auch, eine Überanpassung der Modelle an die Trainingsdaten zu vermeiden.

Tab. 1: Faktentabelle Bestellungen

Tab. 2: Dimension Kunden
In den Metadaten wird zudem hinterlegt, welche Attribute anonymisiert werden. So ist für die KI-Projekte direkt transparent, bei welchen Spalten eine dauerhafte Historie zu erwarten ist und bei welchen nicht.
Durch Anonymisierung statt Löschung bleibt die Historie erhalten. Dies ist ein großer Vorteil für KI-Projekte:
- Modelle sind reproduzierbar, wenn nur auf die nicht anonymisierten Attribute zugegriffen wird.
- Wenn weitere interessante Attribute für eine Verbesserung der Modelle identifiziert werden, die bereits im DWH vorliegen, dann sind diese auch rückwirkend verknüpft und nutzbar.
- Die Historie wächst stetig und erlaubt so bessere Modelle.
- Neben der Verbesserung der Vorhersagequalität kann es auch wichtig sein, gegenüber Prüfern nachzuweisen, auf welcher Datengrundlage ein Modell trainiert wurde. Im oben beschriebenen Beispiel ist die automatische Personalauswahl sicher ein Thema, bei dem nachzuweisen ist, dass keine unzulässige Diskriminierung stattfindet.
Neben der DSGVO ist auch die Wiederverwendbarkeit der Datenaufbereitung ein wichtiges Argument, diese im DWH zu vereinheitlichen. Die anonymisierten Bestellungen sind sowohl für die Produktempfehlungen als auch für eine Vorhersage des Versandaufkommens in der Logistik relevant. Es macht daher Sinn, diese einheitlich aus dem DWH zu beziehen.
Überwachung der Modellqualität
Die Integration mit dem DWH schützt KI-Modelle vor Auswirkungen gelöschter Daten in den Quellsystemen. Trotzdem kann es passieren, dass die Qualität von Modellen plötzlich einbricht. Um dies zu erkennen und entsprechend zu reagieren, kann das DWH ebenfalls helfen. Durch Statistiken und Datenqualitätsberichte über Attribute, die in KI-Modelle eingehen, können Schwellenwerte definiert und Probleme früh erkannt werden.
Darüber hinaus sollten natürlich auch die Modelle selbst überwacht werden. Die Ergebnisse verschiedener Modelle können zusammen mit anderen KPIs in einem Dashboard gesammelt werden, um Analysten einen schnellen Überblick zu ermöglichen.
Gerade im Beispielfall Marketing besteht ein schmaler Grat zwischen willkommenen Produktempfehlungen und als störend empfundener Werbung, die sich jeweils stark auf die Kundenbindung auswirken kann.
Notwendige Weiterentwicklung des DWH
In diesem Artikel wird begründet, warum sich KI-Projekte auf das DWH besinnen sollten. Das klassische DWH bietet den Single Point of Truth mit integrierten, qualitativ hochwertigen Daten mit zeitlichem Bezug. Jedoch gibt es auch viele Anwendungsfälle, deren Anforderungen darüber hinausgehen.
Bezogen auf das Beispiel der Produktempfehlungen, könnten diese abhängig vom Standort des Nutzers per App angezeigt werden. Um diese Live-Daten zu integrieren, reicht das klassische DWH nicht mehr aus. Selbst in einem Near Real Time DWH wird die Latenz oft zu groß sein.
In diesem Fall darf das DWH bzw. die BI-Umgebung kein Showstopper sein, sondern ist in der Bringschuld, die Daten in der benötigten Latenz leicht verfügbar zu machen, damit diese von vielen Anwendungen genutzt werden können. Um Bypässe an der BI vorbei zu vermeiden, empfiehlt sich eine moderne BI-Architektur (Abbildung 5) mit einem Data Lake neben dem DWH und einer Virtualisierungsschicht, die eine einheitliche Sicht auf die Datenplattform des Unternehmens bietet.
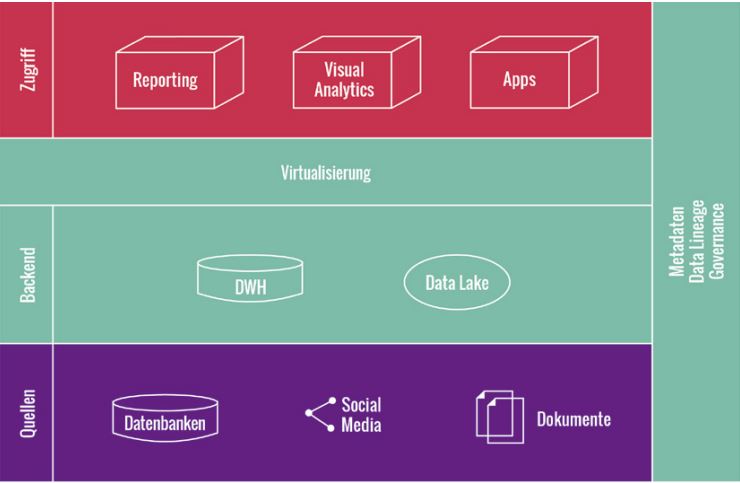
Abb. 5: Moderne BI-Architektur
Fazit
Die aktuelle Sturm-und-Drang-Phase von KI-Initiativen zeigt viele Parallelen zu früheren Schattenlösungen. Bei diesen war Anwendern der Weg über das DWH zu langwierig und sie bauten infolgedessen ihre eigenen Lösungen mittels Excel-Exporten aus verschiedenen Systemen. Die Lösung war und ist weiterhin, ein Miteinander zu etablieren, in dem einerseits ein Verständnis für die notwendige Integration der Daten im DWH geschaffen wird und andererseits Sandboxes und Self-Service-Möglichkeiten geboten werden, die es Anwendern erlauben, die Daten des DWH möglichst einfach zu nutzen und auch mit eigenen Daten zu kombinieren.
Das DWH ist immer noch der richtige Ort, Daten zu integrieren und diese mit beständiger Historie verfügbar zu machen. Mit den Anforderungen der DSGVO kann es gut umgehen. KI-Projekte sollten daher das DWH beziehungsweise die BI-Plattform sofort einbinden, sobald neue Datenquellen als aussichtsreich für KI identifiziert werden, damit die Daten integriert werden können, während Modelle erprobt und optimiert werden. So fällt nicht nur die Compliance mit der DSGVO leichter, sondern ebenso die Überführung von KI-Anwendungen in die Produktion generell.
Literatur
[Baa19]
Baars, H.: Die Bändigung des Feuers. In: BI-SPEKTRUM 2/2019
[Eul18]
Euler, T.: Historisierung versus Recht auf Vergessen. In: BI-SPEKTRUM 5/2018
[Gol19]
https://www.golem.de/news/datenschutzverstoesse-lieferdienst-muss-195-000-euro-dsgvo-bussgeldbezahlen-1909-143973.html, abgerufen am 26.9.2019
[KDD17]
https://www.kdnuggets.com/2017/01/four-problems-crisp-dm-fix.html, abgerufen am 26.9.2019
[Net19]
https://netzpolitik.org/2019/die-dsgvo-zeigt-erste-zaehne-50-millionen-strafe-gegen-google-verhaengt/, abgerufen am 26.9.2019









