

Moderne IT-Infrastrukturen werden immer dynamischer und nehmen an Komplexität zu. Sie kosteneffizient und effektiv zu betreiben wird entsprechend anspruchsvoller. Eine der größten Herausforderungen, denen sich ein IT-Service-Experte bei der Störungsbehebung stellen muss, besteht darin, im Meer der Betriebsdaten (Logs, Metriken, Ereignisse, Vorfälle etc.) die relevanten Informationen zu finden, die ihm helfen, den Vorfall zu identifizieren und zu verstehen, um das Problem zu lösen. Bevor überhaupt mit der eigentlichen Störungsbehebung begonnen werden kann, besteht also ein erheblicher Aufwand bereits in der Ermittlung, Selektion und Analyse der Betriebsdaten.
Vor einigen Jahren wurde das Potenzial erkannt, das darin liegt, dieselben Technologien und Techniken, die erfolgreich für die Bereitstellung und Unterstützung von KI-Lösungen in anderen Geschäftsbereichen eingesetzt werden, für IT-Betriebszwecke zu nutzen, und so wurde Artificial Intelligence for Operations, „AIOps“, geboren. Gartner prägte den Namen AIOps als Kombination von Big Data (BD) und maschinellem Lernen (ML), das auf IT-Betriebsdaten angewendet wird, um Betriebsprozesse zu automatisieren, einschließlich Ereigniskorrelation, Anomalie-Erkennung und Kausalitätsbestimmung etc. [Pra22]. Da IT-Betriebsdaten den Zustand der IT-Infrastruktur zu einem bestimmten Zeitpunkt umfassen, bietet AIOps eine Möglichkeit, Bilder dieses Zustands (Erkenntnisse) oder auch möglicher Zustände in der Zukunft (Prognose) zu generieren, damit der IT-Service-Experte diese nicht selbst mühsam manuell erarbeiten muss und nahezu unmittelbar an der Lösung zur Behebung von Störungen arbeiten kann. Mit AIOps ist es zudem möglich, die Ursachen von Störungen zu ermitteln und bei Bedarf eine automatische Behebung zu initiieren.
Zusammengefasst geht es bei AIOps um die Vermeidung von Störfällen durch Vorhersagen, eine schnellere Ursachenanalyse und eine rasche Lösung von Störungen (siehe Abbildung 1). Damit augmentieren Service-Teams ihre Problemlösungsfähigkeiten, gestalten den IT-Betrieb ressourcenschonend sowie kosteneffizient und stabilisieren dadurch ihre IT-Services.

Abb. 1: Definition von AIOps
Do-It-Yourself AIOps
Laut Gartner muss eine qualifizierte AIOps-Lösung folgende Komponenten bieten [Pra22]:
- Domänenübergreifende Datenaufnahme und -analyse
- Topologie-Erkennung
- Erkennung der Korrelation von Ereignissen
- Mustererkennung von Vorfällen/Ursachen
- Identifizierung einer möglichen Lösungsmaßnahme Obwohl es bereits kommerzielle AIOps-Werkzeuge mit erheblichem Funktionsumfang auf dem Markt gibt und einige klassische Monitoring-Tools neue AIOps-Funktionalitäten anbieten, gibt es noch viel Raum für Do-It-Yourself-Ansätze (DIY) [Kro21]. Ein Grund dafür ist, dass KI-basierte Lösungen in jedem Fall ein gewisses Maß an Konfiguration, Training, Parametrisierung oder Tuning erfordern, und das ist auch bei kommerziellen Lösungen mit Outof-the-Box-Anwendungsfällen nicht anders.
Ein weiterer Grund für einen DIY-Ansatz besteht in der Möglichkeit, Technologien aus dem Bereich Free and Open-Source Software (FOSS) für den Zusammenbau einer offenen AIOps-Architektur zu nutzen. Dadurch lassen sich existierende Pipelines kontinuierlich integrieren, was viele Organisationen mit einer FOSS-only-Strategie begrüßen.
Organisationen, die schon andere KI-basierte Produkte erfolgreich implementiert haben, verfügen bereits über die erforderlichen Skills und Erfahrungen in den benötigten Technologien. Ebenso ist das Vorhandensein von IT-Service-Experten förderlich für das Gelingen der Implementierung einer DIY-AIOps-Plattform.
Die Nutzer der AIOps-Lösung sind die IT-Service-Teams selbst, die Anforderungen und Nutzungsfälle definieren. So spielen sie eine Schlüsselrolle für den Erfolg. Gleichzeitig durchlaufen sie aufgrund der datenwissenschaftlichen Aspekte, die mit der Implementierung von AIOps verbunden sind, einen Mindset-Change mit Blick auf ihren eigenen Alltag im IT-Service und Betrieb. Dies könnte der Beginn des IT-Service-Experten der Zukunft sein, der Wert darauf legt, Erkenntnisse aus ansonsten ungenutzten operativen Rohdaten zu gewinnen und wirksam einzusetzen.
Die Einführung von AIOps befindet sich noch in einer frühen Phase. Der Aufbau neuer Qualifikationen, die Reaktion auf neue Erkenntnisse und ein kontinuierliches und konsequentes Umdenken in den operativen und führenden Organisationseinheiten wird auf dem weiteren Weg unerlässlich sein. Um der Organisation den dafür nötigen Raum und die erforderliche Zeit zu geben, ist ein schrittweises Vorgehen notwendig. Das Team reift mit der schrittweisen Implementierung von AIOps in einem DIY-Vorgehen und öffnet sich somit immer mehr neuen Perspektiven und Möglichkeiten.
XOps ebnet den Weg zu AIOps
AIOps ist eine technische Lösung zur Effizienzsteigerung im IT-Betrieb. AIOps gibt weder die Methodik noch die Technologie für ihre Umsetzung vor.
XOps bietet die Möglichkeiten für einen zielgerichteten Einsatz (siehe Abbildung 2). Es sorgt zum Beispiel für zuverlässige und qualitativ hochwertige Prozesse im Deployment und in der Wartung von Daten- und ML-Modellen, die zur Analyse von Betriebsdaten eingesetzt werden. Einige Definitionen von XOps schließen AIOps als Teil davon ein, aber AIOps ist eher ein einzelner Anwendungsfall von XOps als eine Reihe von Methoden an sich [Tre21]. Von den spezifischen Disziplinen im Rahmen von XOps sind DevOps, DataOps und MLOps diejenigen, die am meisten zu einem DIY-AIOps-Ansatz beitragen können.
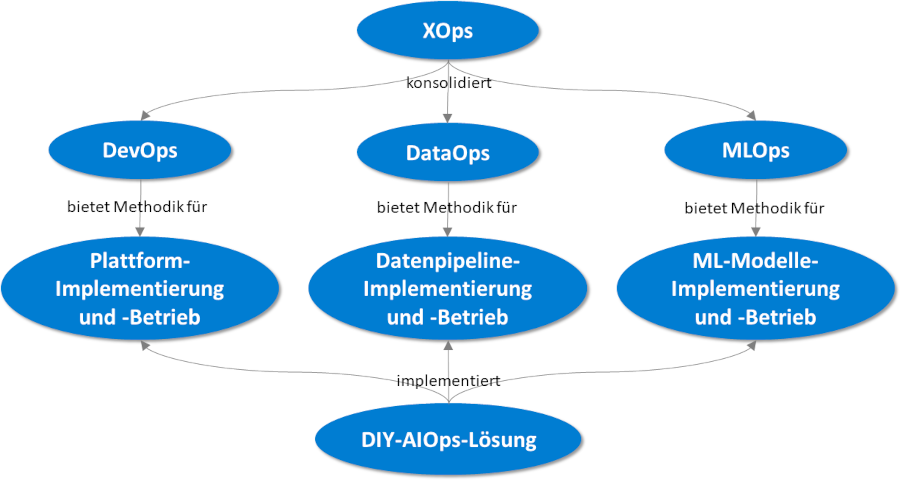
Abb. 2: Zusammenhänge zwischen einer DIY-AIOps- Lösung und XOps
DevOps befasst sich mit der Qualität der Bereitstellung des Betriebs aus Sicht der Softwareentwicklung [Kim17], während DataOps auf die Besonderheiten abzielt, die für die Produktion hochwertiger Daten erforderlich sind [Det20], und MLOps auf die Anforderungen der Erstellung neuer zuverlässiger ML-Modelle innerhalb kurzer Entwicklungszyklen [Tre21]. Einige dieser Disziplinen verwenden Aktivitäten und Technologien, die sich überschneiden.
Die DIY-AIOps-Lösung erfordert einen Prozess zur Schaffung neuer Anwendungsfälle, die implementiert, aktiv genutzt, verbessert und kontinuierlich gepflegt werden müssen. Dazu bedarf es eines AIOps-Entwicklungslebenszyklus (siehe Abbildung 3), der im Folgenden auf hoher Ebene umschrieben wird, einschließlich der Beziehung zwischen den AIOps-Aktivitäten und den von XOps übernommenen Methoden und Technologien (siehe Abbildung 4).
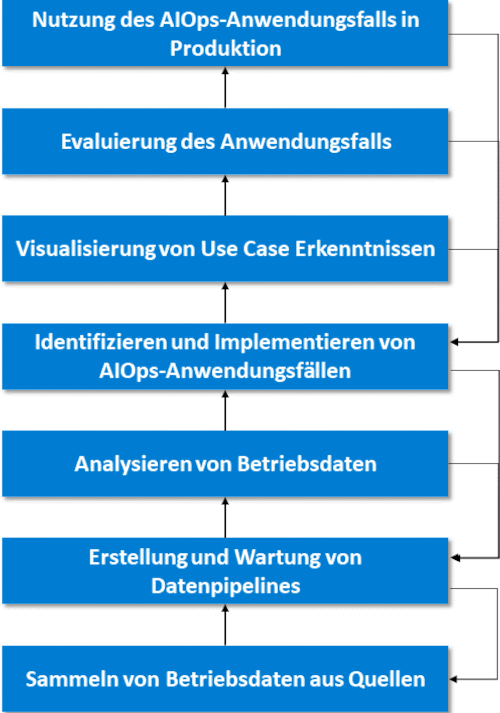
Abb. 3: Vereinfachte Darstellung des DIY-AIOps- Entwicklungslebenszyklus
Sammeln von Betriebsdaten aus Quellen
Betriebsdaten werden normalerweise über die einzelnen Komponenten generiert, die eine IT-Infrastruktur bilden, wie zum Beispiel Server, Container, Datenbanken, Firewalls, Router, Systeme, Dienste etc. Aus Sicht des IT-Service werden diese Komponenten als Configuration Items (CI) bezeichnet. Weitere Quellen für AIOps-relevante Daten sind IT-Service-Management-Tools wie zum Beispiel Monitoring-Tools oder Ticketing-Systeme. Die Daten können im Push- oder Pull-Modus mittels Data-Collection-Agents gesammelt werden, die in der Lage sind, Log-Dateien, Metriken oder Events zu lesen und an einen beliebigen Zielort zu senden oder zu empfangen. DevOps bietet Verfahren zur Automatisierung der Bereitstellung, der Konfiguration, des Betriebs und der Überwachung der Agenten für die Datenerfassung. DataOps stellt Methoden zur Definition der Anforderungen an die Datenerfassung, Datensicherheit, Data Governance und Datenqualität zur Verfügung. FluentBit und Fluentd sind Beispiele für Data-Collectoren und -Aggregatoren, die speziell für die Sammlung von Betriebsdaten entwickelt wurden.
Erstellung und Wartung vonDaten-Pipelines
Aus der Sicht von DataOps wird die Daten-Pipeline als Produkt eines Entwicklungsprozesses betrachtet [Det20]. Die Komponenten einer Daten-Pipeline können kodiert, getestet und ausgeliefert werden, und diese Prozesse lassen sich mit Hilfe von Dev-Ops-Methoden automatisiert und kontinuierlich verbessern. Dies sind die wichtigsten Komponenten, die zur Implementierung einer AIOps Data Pipeline benötigt werden:
- Sammeln von Daten: Die AIOps-Plattform erfordert eine Technologie, die in der Lage ist, große Datenströme stabil und zuverlässig zu verarbeiten. DevOps bietet Methoden, um die Bereitstellung, die Konfiguration, den Betrieb und die Überwachung des Data-Brokers zu automatisieren. DataOps stellt Methoden zur Sicherstellung der Qualität und der Verwaltung der Daten bereit. Apache Kafka ist eine solche Technologie, die ein hochleistungsfähiges Daten-Streaming ermöglicht.
- Daten verarbeiten: Die Definition der Anforderungen für die Datenverarbeitung ist eine Schlüsselaktivität von DataOps [Det20]. ETL-fähige (Extract–Transform–Load) Technologien sind die übliche Wahl zur Durchführung dieser Aufgabe. DevOps bietet Methoden zur Automatisierung von Bereitstellung, Konfiguration, Betrieb und Überwachung des ETL-Tools. Apache Nifi ist ein für diese Aufgabe geeignetes Werkzeug. Dazu verfügt es über Data-Provenance-Funktionen, das heißt, es kann die Änderungen an jedem einzelnen Datenelement verfolgen.
- Daten speichern: DevOps bietet Verfahren zur Automatisierung von Bereitstellung, Konfiguration, Betrieb und Überwachung der Datenbank. DataOps stellt Methoden für die Definition und Implementierung von Datenspeicheranforderungen bereit. PostgreSQL ist eine relationale Datenbank, OpenSearch und Prometheus sind nichtrelationale Datenbanken, die für die Speicherung von Betriebsdaten beispielsweise verwendet werden können.
Analysieren von Betriebsdaten
Die konsolidierten Daten können untersucht werden, um mögliche AIOps-Anwendungsfälle zu identifizieren. MLOps stellt hierfür die benötigen Verfahren zur Verfügung. Um die Qualität der Daten während des AIOps-Entwicklungslebenszyklus weiter zu überwachen, werden DataOps-Methodiken verwendet. Folgende Technologien können zum Einsatz kommen:
- ML-Experimentier- oder Entwicklungsum- gebung: Diese besteht in der Regel aus einer Programmiersprache nach Wahl, die mit ML-Bibliotheken erweitert wird, und einer IDE mit Datenvisualisierungsfunktionen. Jupyter Notebooks und Pycharm mit Python und ML-Bibliotheken wie Tensorflow, Keras, Pytorch sind Beispiele solcher Umgebungen.
- ML Lifecycle Management Tool: Dieses Tool implementiert die von MLOps definierten Prozesse und Pipelines zur Nachverfolgung von Experimenten und Modellen einschließlich ihres Codes, ihrer Daten, Parameter und Ergebnisse, zur ordnungsgemäßen Produktionalisierung und Speicherung von Modellen sowie zur Bereitstellung von Modellen in Zielumgebungen. MLFLow ist ein Beispielprojekt, das einige dieser Methoden abdeckt.
- Werkzeug zur Datenvisualisierung: Es ermöglicht die Visualisierung und Abfrage der eingegebenen Betriebsdaten zusammen mit den von den AIOps-Modellen generierten Erkenntnissen. Grafana ist ein Beispiel für ein leistungsfähiges Visualisierungs-Tool, das speziell für die operative Beobachtbarkeit entwickelt wurde.
Identifizieren und Implementieren von AIOps-Anwendungsfällen
Ein Anwendungsfall wird auf einem oder mehreren ML-Modellen basieren, die als Service paketiert und bereitgestellt werden können. Für die Automatisierung der Ausführung von AIOps-Services können Workflow-Automatisierungswerkzeuge eingesetzt werden. Apache Airflow ist eine Beispiellösung, die Workflow-Automatisierungsfunktionalitäten auf Basis von Code bietet.
Visualisierung von Use-Case- Erkenntnissen
Ziel dieser Aktivität ist es, die Erkenntnisse eines AIOps-Anwendungsfalls dem Endbenutzer in geeigneter Weise zu präsentieren, zum Beispiel in Form eines Dashboards.
Evaluierung des Anwendungsfalls
Das Serviceteam gibt Feedback zur Implementierung eines Anwendungsfalls. Wenn die Ergebnisse nicht zufriedenstellend sind, ist eine Verbesserungsschleife erforderlich, die auf eine der vorherigen Aktivitäten des AIOps-Entwicklungslebenszyklus zurückgeht. Kollaborations-Tools können als Kanal für Feedback und Dokumentation nützlich sein.
Nutzung des AIOps-Anwendungsfalls auf einen Live-IT-Service
Der Anwendungsfall wird in die Zielumgebung ausgerollt, und die Endbenutzer (IT-Service-Experten) nutzen die gewonnenen Erkenntnisse, um ihre Fähigkeiten effektiv zu erweitern. Ein Live-Anwendungsfall muss immer noch betrieben, überwacht und gewartet werden, was durch DevOps-, Data-Ops- und MLOps-Verfahren abgedeckt wird. Diese Methoden, die auf kontinuierliche Verbesserung setzen, ermöglichen es, die Aktivitäten des AIOps-Entwicklungslebenszyklus zu wiederholen und mit jeder Iteration effektivere Anwendungsfälle zu erzeugen.
Weitere DevOps-Technologien für allgemeine Entwicklungs-, Betriebs- und Lieferaktivitäten können ein Versionskontrollsystem (wie Git) umfassen, ein Infrastructure-as-a-Code-Tool (wie Terraform), ein Automatisierungs-Tool (wie Ansible) sowie Container-Virtualisierungs-Tools (wie Docker).
Fazit
XOps kann jede Aktivität eines beispielhaften DIY-AIOps-Entwicklungslebenszyklus prägen, der auf hochspezialisierte Anwendungsfälle abzielt. In Kombination mit einer FOSS-only-Strategie und einer inkrementellen Einführung von Änderungen können Organisationen durch die Optimierung ihrer IT-Services in kurzen Entwicklungsphasen mit minimalen Investitionen einen spürbaren Mehrwert schaffen. Darüber hinaus ermöglichen die schrittweise Einführung und der Ausbau von AIOps-Skills es der IT- und Service-Organisation, sich nachhaltig auf eine Zukunft mit sehr dynamischen, volatilen und komplexen Infrastrukturen vorzubereiten.
Weitere Informationen
[Det20] Detemple, K.: DataOps als Basis und Treiber einer erfolgreichen Data Governance. In: Gluchowski, P. (Hrsg.): Data Governance. dpunkt verlag 2020
[Kim17] Kim, G. et al.: Das DevOps-Handbuch. O’Reilly 2017
[Kro21] Kroculick, K.: Effective AIOps with Open Source Software in a Week. 6.8.2021,
https://www.youtube.com/watch?v=NuL1u_CIkQw (ab 1.35 Min.), abgerufen am 10.2.2023
[Pra22] Prasad, P. et al.: Market Guide for AIOps Platforms. 30.5.2022,
https://www.gartner.com/doc/reprints?id=1-2A6HEH3Y&ct=220531&st=sb, abgerufen am 10.2.2023
[Tre21] Treveil, M.: MLOps. Kernkonzepte im Überblick. O’Reilly 2021









