

Kubernetes wird in vielen Projekten erfolgreich für zustandslose Applikationen eingesetzt. Applikationen mit Zustand benötigen wesentlich mehr Aufwand. Um Datenverlust zu vermeiden, muss eine Backup-/Recovery-Strategie existieren. Um Hochverfügbarkeit zu garantieren, müssen Applikationen geclustert werden. Diese Aufgaben und andere werden in der Regel von Entwicklerinnen oder Administratoren (engl. Operators) automatisiert und gepflegt.
Mit Kubernetes-Operators hat CoreOS ein Konzept erschaffen, das das Arbeiten mit zustandsbehafteten Applikationen, wie zum Beispiel Datenbanken, ebenso einfach macht wie das Arbeiten mit Pods und Containern. Stabile Datenbank-Operatoren können somit als 1:1-Ersatz für Services wie beispielsweise AWS-RDS-Datenbanken dienen. Der Funktionsumfang ist ebenbürtig: Backups, Cluster-Erstellung oder das Aufsetzen einer neuen Datenbank aus einem Backup sind voll automatisiert.
Historie
Im November 2016 stellte CoreOS das Konzept der Kubernetes-Operators vor. Als Beispiele lieferten sie zwei Operatoren für etcd und Prometheus mit [Phi16]. Zusammen mit der Kubernetes-Community hatte das CoreOS-Entwicklerteam damit eine Lösung geschaffen, um zustandsbehaftete Anwendungen in Kubernetes leichter zu verpacken, bereitzustellen und zu betreiben. Von Anfang an war Kubernetes darauf ausgelegt, zustandslose Anwendungen und Services sehr einfach zu managen. Zustandsbehaftete Anwendungen brauchen jedoch einen bestimmten Kontext zur Laufzeit und spezifisches Wissen, um sie korrekt zu skalieren, auf dem neuesten Stand zu halten oder Datenverlust zu verhindern.
Die Prozesse für diese Szenarien waren in Kubernetes lange nicht auf eine standardisierte Art automatisiert. Dies konnte zu erheblichem Mehraufwand für Entwickler und Administratorinnen führen und die Fehleranfälligkeit von Systemen erhöhen, wenn beispielsweise ausgefallene Container neu gestartet werden mussten. Darüber hinaus widersprach es einem der Hauptzwecke von Kubernetes: Container leicht und vor allem automatisiert zu managen.
Nach der Übernahme von CoreOS durch Red Hat wurde das Operator-Konzept weiterentwickelt und Anfang 2018 das Operator-Framework veröffentlicht [Phi18], welches auch ein SDK bereitstellt. Außerdem wurde mit OperatorHub [OpHub] eine Plattform geschaffen, auf der Operatoren gelistet werden können.
Der Einsatzbereich von Operatoren beschränkt sich inzwischen nicht mehr auf das Betreiben zustandsbehafteter Anwendungen, sondern geht weit darüber hinaus. Manche Operatoren werden deshalb auch als native Kubernetes-Anwendungen bezeichnet.
Funktionsweise
Das Kubernetes-API sieht Erweiterbarkeit durch sogenannte Custom Resources vor. Eine Custom Resource Definition (CRD) beschreibt das Schema einer Custom Resource. Nachdem eine CRD dem Kubernetes-Cluster durch Installation des Operators bekannt gemacht wurde, kann die beschriebene Custom Resource wie jedes andere Kubernetes-Objekt benutzt werden.
Ein Kubernetes-Operator stellt CRDs bereit und verwaltet die zugehörigen Custom Resources. Dabei prüft der Operator permanent, ob der aktuelle Zustand des Systems dem gewünschten Zustand entspricht, indem er ihn mit dem in der Custom Resource beschriebenen Zustand abgleicht. Weicht der aktuelle Zustand ab, kümmert sich der Operator darum, entsprechende Schritte einzuleiten. Fällt zum Beispiel ein Pod weg, weil ein Node im Cluster ausgefallen ist, erkennt der Operator, dass die gewünschte Anzahl an Pods nicht der tatsächlichen Anzahl entspricht, und wird sich darum kümmern, dass ein neuer Pod gescheduled wird.
Das Zusammenspiel lässt sich mit einem Beispiel beschreiben. Häufig wird eine neue Instanz einer Ressource per YAML-Datei beschrieben und dann mit kubectl apply -f <datei> ausgerollt. Für eine Custom Resource einer Postgres-Datenbank kann dies zum Beispiel wie in den beiden im Folgenden beschriebenen Listings aussehen.
Das Beispiel in Listing 1 zeigt die Konfiguration einer Custom Resource des Zalando Postgres Operators [GitH-b] (apiVersion: „acid.zalan.do/v1”). Es handelt sich hierbei um eine Custom Resource vom Typ (kind) postgresql. Sie beschreibt eine Postgres-Datenbank mit zwei Instanzen. Der hier gezeigte Operator erstellt ein Master-/Replica-Setup. Die Postgres-Datenbank wird mit der Datenbank clients und dem Datenbanknutzer admin aufgesetzt.
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: client-db
spec:
enableLogicalBackup: true
volume:
size: 1Gi
numberOfInstances: 2
users:
admin: # database owner
- superuser
- createdb
databases:
clients: admin
postgresql:
version: "11"Wenn diese Konfiguration in Kubernetes ausgerollt wird, ist das beschriebene Setup nach wenigen Minuten verfügbar. Das Passwort für den Benutzer admin wird automatisch erzeugt und in einem Kubernetes-Secret gespeichert. Fällt die Master-Instanz aus, wird automatisch die Replica-Instanz den Betrieb übernehmen. Durch die Option enableLogicalBackup: true werden regelmäßig Backups erstellt.
Das Beispiel in Listing 2 zeigt eine Konfiguration, die eine Datenbank aus einem solchen Backup wiederherstellt. Auch diese Konfiguration ist vom Typ postgresql. Der Postgres-Operator, der diese Konfigurationen konsumiert, ermöglicht es also, mit wenigen Zeilen YAML ein komplexes Datenbank-Setup zu erstellen und automatisch zu betreiben. Dabei geht es nicht nur um den Aufbau des Clusters, sondern auch um typische Betriebsthemen wie Backups.
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: acid-test-cluster
spec:
clone:
uid: "efd12e58-5786-11e8-b5a7-06148230260c"
cluster: "acid-batman"
timestamp: "2017-12-19T12:40:33+01:00"Komponenten eines Operators
Um auf das Erzeugen, Aktualisieren und Löschen von Custom Resources reagieren zu können, muss eine aktive Komponente dauerhaft im Kubernetes-Cluster laufen: der Custom Controller.
Custom Controller
Wie Abbildung 1 zeigt, reagiert der Controller auf Events des Kubernetes-API und führt entsprechende Aktionen aus.
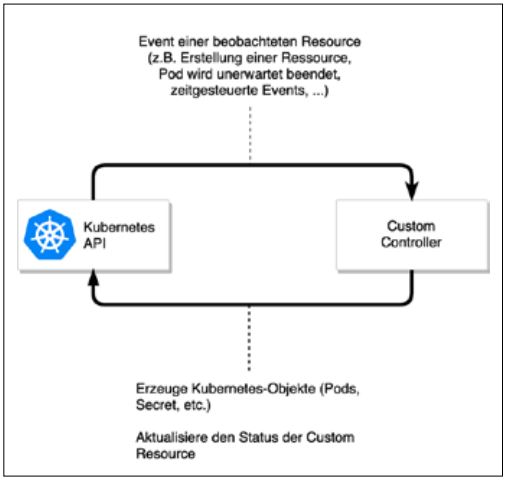
Abb. 1: Der Custom Controller reagiert auf Events des Kubernetes-API
Ein wichtiges Event ist die Erstellung oder Aktualisierung einer Custom Resource. Wenn die YAML-Datei aus Listing 1 mit kubectl apply -f <datei> in einem Kubernetes-Cluster deployed wird, erhält der entsprechende Custom Controller ein Event Create. Der Controller wird daraufhin unter Nutzung des Kubernetes-API folgende Operationen ausführen:
- Erstellung des Master-Postgres-Pods,
- Erstellung und Konfiguration eines Replica-Postgres-Pods,
- Erstellung des Postgres-Users admin in der Postgres-Datenbank,
- Erstellung eines Kubernetes-Secrets mit dem Passwort des Users admin, damit dieser in Applikationen benutzt werden kann,
- Erstellung der Datenbank clients und Zuordnung des Users admin zu dieser Datenbank,
- Aktualisierung des Status der Custom Resource (zum Beispiel: creation successful).
Der Controller lauscht nicht nur auf Ereignisse der eigenen Custom Resource (in unserem Beispiel postgresql), sondern auch auf Ereignisse der Ressourcen, die er erstellt hat. Sollte zum Beispiel der Master-Postgres-Pod terminiert werden, muss der Controller entsprechende Maßnahmen treffen und den Replica-Pod zum Master befördern.
Controller können auch ohne eigene Custom Resource auskommen. Solche Controller können sinnvoll sein, wenn der Cluster bezüglich bestimmter Regeln beobachtet werden soll. Häufig reagieren solche Controller auf Objekte, die bestimmte Annotationen besitzen. So wäre es zum Beispiel möglich, automatisch externes Monitoring aufzusetzen, sobald eine neue Ingress-Regel erzeugt wird, die die Annotation externalMonitoring: true hat.
Mutating- & Validating-Webhook
Wenn der Custom Controller ein Event über die Erstellung einer Ressource bekommt, ist diese bereits in der Kubernetes-Datenbank gespeichert. Wenn wir in Listing 1 die Postgres-Version auf „42” setzen würden, wäre dies aus Sicht des Datenschemas der Ressource korrekt, allerdings existiert diese Postgres-Version nicht. Idealerweise sollte das Deployen dieser Datei mit einer entsprechenden Fehlermeldung fehlschlagen.
Eine inhaltliche Validierung kann mit sogenannten Admission Controller Webhooks implementiert werden. Diese werden immer dann aufgerufen, wenn neue Ressourcen erstellt oder bestehende geändert oder gelöscht werden. Sie werden aufgerufen, bevor die Events von Custom Controllers gesehen werden können. Häufig sind sie deshalb auch Bestandteil von Operatoren.
Es gibt zwei verschiedene Arten von Admission Controller Webhooks: Mutating- und Validating-Webhooks. Mutating-Webhooks setzen Default-Werte bei Feldern, die nicht explizit gesetzt wurden. Validating-Webhooks überprüfen den Inhalt der Konfiguration. Wird in unserem Datenbankbeispiel eine nicht-existente Datenbankversion angegeben, könnte ein Validating-Webhook die Erstellung dieses Objektes mit einer Fehlermeldung verhindern.
Abbildung 2 zeigt, in welcher Reihenfolge welche Komponenten aufgerufen werden, wenn ein neues Objekt erzeugt werden soll. Die Mutating-Webhooks werden ganz am Anfang der Kette aufgerufen und, sofern mehrere für das Objekt existieren, nacheinander ausgeführt. Anschließend werden die Daten anhand des Datenschemas validiert und die Validating-Webhooks aufgerufen. Diese können parallel ausgeführt werden. Wenn einer der Validating-Webhooks einen Fehler meldet, wird die Erzeugung des Objektes mit einer Fehlermeldung abgebrochen. Die Custom Controller werden erst aufgerufen, nachdem das neue Objekt bereits in der Kubernetes-Datenbank etcd persistiert wurde.
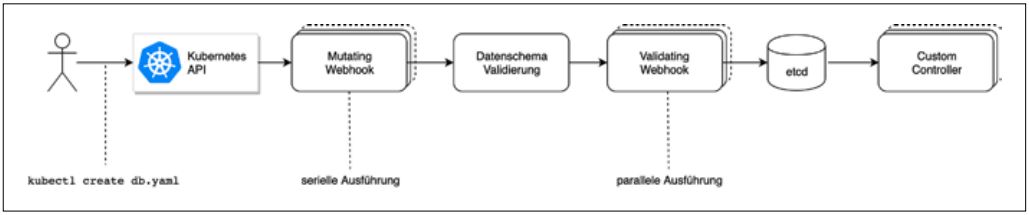
Abb. 2: Ausführungsreihenfolge, wenn ein neues Objekt angelegt wird
Admission Controller Webhooks werden als Webservice implementiert und wie jeder andere Service innerhalb des Kubernetes-Clusters ausgerollt. Sie müssen einen HTTP-Post mit einer JSON-Repräsentation des zu validierenden oder zu mutierenden Objekts entgegennehmen können und eine definierte Antwort zurückliefern.
Ist der Service ausgerollt, muss dieser als Webhook im Kubernetes-Cluster registriert werden. Die Registrierung erfolgt, wie bei Kubernetes üblich, indem eine YAML-Datei mit kubectl apply angewendet wird.
Listing 3 zeigt die Registrierung eines Validating-Webhooks, der aufgerufen wird, sobald eine Custom Resource vom Typ postgresql angelegt oder aktualisiert wird. Der Webhook-Service läuft im Namespace test und hat den Namen postgres-version-check-service. Das JSON-Objekt muss zum Pfad /validate/postgresversion per HTTP-Post geschickt werden.
apiVersion: admissionregistration.k8s.io/v1beta1
kind: ValidatingWebhookConfiguration
metadata:
name: validating-webhook
namespace: test
webhooks:
- name: postgres-version-check
failurePolicy: Fail
clientConfig:
service:
name: postgres-version-check-service
namespace: test
path: /validate/postgresversion
caBundle: ...
rules:
- apiGroups: ["acid.zalan.do/v1"]
resources: ["postgresql"]
apiVersions: ["*"]
operations: ["CREATE", "UPDATE" ]Eigene Operatoren schreiben
Um das Schreiben von Operatoren zu erleichtern, hat CoreOS das operator-sdk [GitH-c] zur Verfügung gestellt. Dieses SDK unterstützt Entwickler, mit relativ geringem Aufwand alle nötigen Komponenten eines Operators in der Sprache Go zu implementieren. Es kann aus Go-Datentypen automatisch Custom Resource Definitions erstellen. Außerdem stellt es Generatoren für Custom Controller und Webhooks zur Verfügung.
Alle aktiven Komponenten, also Custom Controller, Mutating-Webhooks und Validating-Webhooks, werden von einem ausführbaren Programm implementiert, welches in einem Docker-Container wie ein normaler Pod deployed wird.
Fazit
Operatoren erweitern die Funktionalität des Kubernetes-API und damit auch der Kubernetes-Tools, wie zum Beispiel kubectl, für neue Use-Cases. Selbstverständlich werden auch ohne Operator Datenbanksysteme im Clusterbetrieb automatisiert aufgesetzt und betrieben. Dazu ist es jedoch notwendig, eine oder mehrere andere Tool-Chains wie Terraform, Puppet oder Ansible zu benutzen. Häufig werden deshalb diese Aufgaben noch klassisch von separaten Operations-Teams umgesetzt. Ähnlich zu Services wie AWS-RDS-Datenbanken können Operatoren deshalb Wegbereiter einer echten DevOps-Kultur werden. Sie ermöglichen den Betrieb aufwendiger, zustandsbehafteter Systeme mit denselben Bordmitteln, die für alle anderen Services genutzt werden.
Durch Operatoren wird das Wissen über den Lebenszyklus einer Anwendung, das Entwicklerinnen oder Administratorinnen besitzen, systematisiert und durch Software implementiert. Wichtig ist nicht nur der höhere Automatisierungsgrad des Systems, sondern auch, dass manuelle Arbeitsschritte durch Operatoren auf skalierbare, wiederholbare, standardisierte und somit einfachere Weise umgesetzt werden.
Operatoren sind in der Regel unabhängig vom Cloud-Anbieter. Services wie Amazons-RDS-Datenbanken könnten an Bedeutung verlieren, sobald entsprechende Operatoren die nötige Stabilität und Zuverlässigkeit erreicht haben.
Kubernetes-Operators sind für zahlreiche Szenarien einsetzbar. Der Trend entwickelt sich dahin gehend, dass sowohl komplexe Softwareprojekte Operatoren als Standard-Feature anbieten werden, als auch, dass die Kubernetes Community Operatoren entwickelt. So wurde beispielsweise der AWS Service Operator von AWS entwickelt, während der Istio Operator von Banzai Cloud bereitgestellt wird.
Auch wenn Zalando den eigenen Postgres-Operator [GitH-b] schon seit zwei Jahren in Produktion nutzt, müssen Operatoren vor dem Einsatz sehr intensiv in der eigenen Umgebung evaluiert werden. Operatoren sind neu und noch nicht in vielen verschiedenen Setups erprobt. Zum Teil besteht die Gefahr von Datenverlusten [GitH-a]. Wenn zuverlässige Operatoren zur Verfügung stehen, entlasten sie mittel- bis langfristig Administratoren und Entwicklerinnen, da sie Komplexitäten des Systems abstrahieren.
Links
[GitH-a] https://github.com/kubedb/project/issues/385
[GitH-b] https://github.com/zalando/postgres-operator
[GitH-c] https://github.com/operator-framework/operator-sdk
[OpHub] https://operatorhub.io/
[Phi16] B. Philips, Introducing Operators: Putting Operational Knowledge into Software, CoreOS Blog, 3.11.2016, https://coreos.com/blog/introducing-operators.html
[Phi18] B. Philips, Introducing the Operator Framework. Building Apps on Kubernetes, Red Hat, 1.5.2018, https://www.redhat.com/en/blog/introducing-operator - framework-building-apps-kubernetes









