

Nachvollziehbarkeit bedeutet dabei aber nicht nur, zu wissen, aus welchen Quelldaten eine bestimmte Kennzahl in einem Bericht ermittelt wurde. Durch die gewachsene Bedeutung von Machine Learning und Verfahren der Künstlichen Intelligenz ist es ebenso bedeutsam, dass nachvollzogen werden kann, wie ein bestimmtes Machine-Learning-Modell zu seinem Ergebnis gekommen ist. Die in letzter Zeit immer wichtiger werdenden Foundation Models und Large Language Models (LLMs) stellen dabei neue Herausforderungen auf.
Daher sind beim Thema Nachvollziehbarkeit verschiedene Aspekte zu berücksichtigen. Ein Aspekt ist die Erfassung der Bewegung und Transformation von Daten von ihrer Quelle bis hin zu ihrem Ziel. Dies wird häufig als Data Lineage bezeichnet. Das ist aber nicht der einzige Ansatz, um Nachvollziehbarkeit in einem analytischen System zu schaffen. Es geht auch um die Nachvollziehbarkeit von Abläufen, die man häufig unter dem Begriff Data Observability zusammenfasst. Zur Nachvollziehbarkeit gehört dabei auch das Erfassen des Zustands der Umgebung, die bei den einzelnen Schritten der Abläufe vorhanden ist. Ein Beispiel sind etwa Informationen zu den Trainingsdaten eines Machine-Learning-Modells oder auch die beim Trainieren verwendeten Parameter.
Definition und Abgrenzung der Begriffe
Ein wesentlicher Aspekt von Data Governance [Ery23] ist die Frage der Nachvollziehbarkeit, wie Daten, die als Ergebnis präsentiert werden, entstanden sind. Dabei werden meist zwei Gesichtspunkte – Data Lineage und Data Observability – unterschieden, die im Folgenden definiert werden.
Data Lineage (deutsch Datenherkunft) [MGV22; StS23] dokumentiert Datenflüsse, das heißt den Weg von einem Datenerzeuger oder – wenn die Datenerzeugung schon lange zurückliegt – einem Datenspeicher zu einem Datenverbraucher. Dabei werden Objekte wie beispielsweise relationale Tabellen, Dateien, Reports oder auch Machine-Learning-Modelle sowie Datenflüsse zwischen diesen Objekten durch Graphen repräsentiert und visualisiert. Es handelt sich also um eine eher statische Darstellung der Abhängigkeiten zwischen diesen Objekten. Abbildung 1 zeigt ein Beispiel für einen Ausschnitt aus einem Data-Lineage-Graphen.
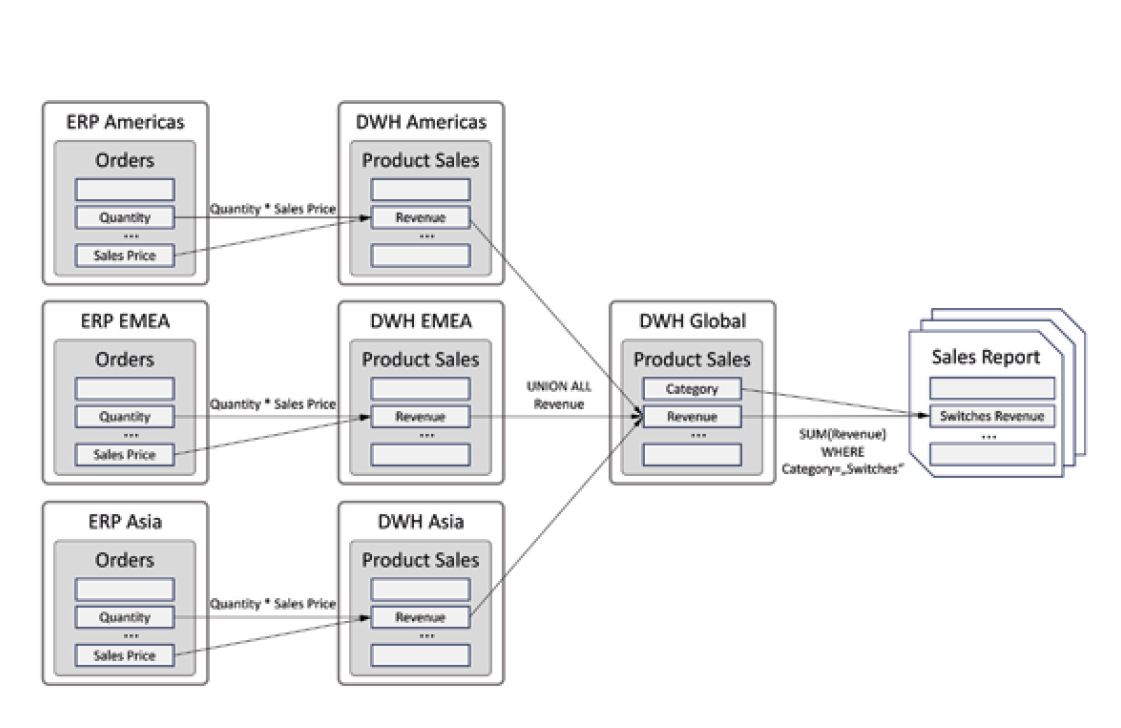
Abb. 1: Ausschnitt aus einem Lineage-Graphen
Data Observability [Pet22; Pet23] hingegen dokumentiert die Zustände und deren Änderungen von und durch Abläufe, wenn Daten verschoben werden, etwa beim Data Engineering [ReH22], und hat daher eher dynamischen Charakter. Sie dient beispielsweise dazu, den laufenden Betrieb von Datenströmen oder ETL-Pipelines zu überwachen und zu verbessern, Probleme frühzeitig zu erkennen oder Fehler schneller zu analysieren und zu beseitigen. Entsprechende Werkzeuge erlauben es auch, in Datenströme hineinzuschauen und diese genauer zu analysieren. Hierzu zählen zum Beispiel das Sammeln von Performance-Metriken oder die Prüfung auf Anomalien in den Daten.
Data-Lineage-Werkzeuge können gegebenenfalls auch im Bereich Data Observability nutzbringend eingesetzt werden. Zum Beispiel kann beim Ausfall einer ETL-Pipeline ein zugehöriger Lineage-Graph genutzt werden, um eine Impact-Analyse des Problems durchzuführen, möglicherweise um zu ermitteln, welche nachgelagerten Datenkonsumenten von diesem Problem betroffen sind. Ein Werkzeug dafür ist IBM Data Observability by Databand [IBM23].
Typische Anwendungsfälle für die Nachvollziehbarkeit von Datenflüssen
Im Folgenden werden einige Anwendungsfälle für die Nachvollziehbarkeit von Datenflüssen aufgelistet:
- Berichterstattung und Analysen: Durch die Nachvollziehbarkeit der zugrunde liegenden Daten kann das Vertrauen in Analysen und Berichte erhöht werden.
- Nachweis über das Einhalten von Gesetzen und Regularien: Damit kann dokumentiert werden, wie Daten gesammelt, verarbeitet und verwendet werden.
- Datenqualitätsmanagement: Durch Nachvollziehbarkeit lassen sich Inkonsistenzen in Daten und zugehörigen Transformationen erkennen.
- Datenschutz: Nachvollziehbarkeit ermöglicht zu erkennen, wie und wo bestimmte – beispielsweise personenbezogene – Daten verwendet werden.
- Einhaltung von Service Level Agreements (SLAs): SLAs können bezüglich der zeitnahen Datenbereitstellung und Datenqualität überprüft werden.
- Fehleranalyse und -behebung: Die verbesserte Analyse der Ursachen und Auswirkungen von Problemen führt zu einer schnelleren Behebung.
Ein häufiger Anwendungsfall für die Nachvollziehbarkeit von Datenflüssen ist die Nachverfolgung der Herkunft von Daten in Analysen (Charts) und Berichten. Hierbei möchte man zum Beispiel für Stammdaten wie Kundendaten und Bewegungsdaten wie Stückzahl oder Umsatz lückenlos nachverfolgen können, aus welchen Systemen diese Daten stammen und wie sie gegebenenfalls transformiert und aufbereitet wurden.
Ein weiterer Anwendungsfall aus dem regulatorischen Bereich ist die Umsetzung von Datenlöschanfragen von Kunden entsprechend der DSGVO-Verordnung [DSG23]. Hier gilt es unter anderem, alle Systeme zu ermitteln, in denen Daten des betreffenden Kunden gespeichert sind. Häufig stammen die Attribute in Kundendatensätzen aus mehreren Quellsystemen, werden deshalb in einem zentralen System zusammengeführt und von dort aus beispielsweise zu Auswertungszwecken in weitere Systeme übertragen.
Herausforderungen einer durchgängigen Nachvollziehbarkeit von Datenflüssen
Eine durchgängige Nachvollziehbarkeit von Datenflüssen ist insbesondere für größere Unternehmen mit komplexen Systemlandschaften eine Herausforderung. Ein Beispiel ist in Abbildung 2 dargestellt.
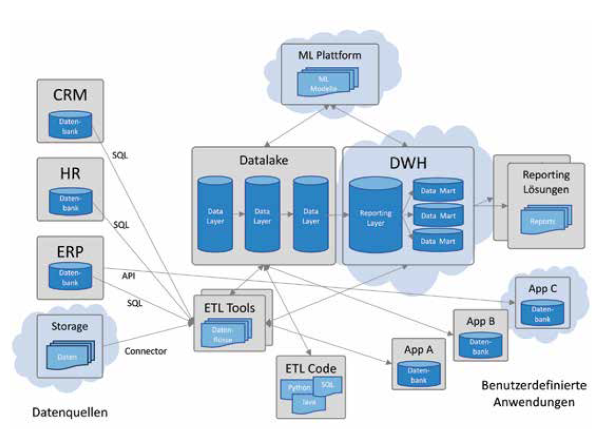
Abb. 2: Datenflüsse in einer komplexen Systemlandschaft
Häufig liegen die Daten in unterschiedlichen Typen von Datenspeichern. Die Daten werden auf unterschiedliche Weise transportiert, transformiert und aufbereitet. Neben Standardwerkzeugen und APIs (zum Beispiel für die Extraktion, Transformation und das Laden von Daten, Machine-Learning-Pipelines) kommen selbst entwickelte Programme in unterschiedlichen Programmiersprachen oder auch datenbankspezifische Stored Procedures zum Einsatz. Datenflüsse umfassen häufig mehrere Systeme wie Systems of Record, Systems of Engagement, Data Lakes, Data Warehouses, Reporting-Lösungen etc. Häufig werden Daten über viele Stufen transformiert und aufbereitet. Entsprechend hoch sind die Anforderungen an Werkzeuge zur Analyse solcher Datenflüsse.
Anforderungen an die Nachvoll- ziehbarkeit von Datenflüssen
Wenn es um die Nachvollziehbarkeit von Datenflüssen geht, sind einige wichtige Anforderungen zu beachten:
- Entsprechende Lösungen sollen die automatische Analyse eines möglichst breiten Spektrums an externen Datenquellen (Datenbanken, Dateien etc.) und Werkzeugen aus den Bereichen ETL, Reporting etc. unterstützen.
- Sofern Daten nicht durch Standardwerkzeuge, sondern durch selbst geschriebene Programme transformiert werden, sollen diese Programme automatisch analysiert werden können, um die Transformationen zu ermitteln.
- Abhängigkeiten zwischen Tabellen und Spalten sollen auch manuell modelliert werden können. Zum Beispiel sollten automatisch generierte Lineage-Graphen auch manuell ergänzt werden können.
- Abhängigkeiten zwischen Daten sollen sowohl auf Tabellenebene als auch auf Spaltenebene nachvollzogen werden können. Auch die Analyse indirekter Abhängigkeiten zwischen Daten soll unterstützt werden. Ein Beispiel für indirekte Lineage: Ein Feld wie „Geschlecht“ wird als Filterkriterium für ein anderes Feld verwendet.
- Änderungen an Datenflüssen sollen auch im zeitlichen Verlauf nachvollzogen werden können, etwa Änderungen der Transformationen, der Datenquellen oder der nachgelagerten Datenziele.
- Weitere Anforderungen betreffen die Werkzeuge zur Visualisierung von Lineage-Information. Beispielsweise soll der Detailgrad der Darstellung gewählt werden können (zum Beispiel Tabellenebene, Spaltenebene), um den unterschiedlichen Bedürfnissen verschiedener Benutzerrollen Rechnung zu tragen (zum Beispiel Business-Analyst, Data Engineer). Es sollen Möglichkeiten zur Navigation innerhalb von Lineage-Graphen verfügbar sein.
Auch in Hinsicht auf die Verbesserung des operativen Managements von Datenflüssen lassen sich einige wichtige Anforderungen formulieren:
- Performance-Metriken (zum Beispiel Laufzeit, Latenz etc.) sollen automatisch gesammelt und visualisiert werden. Aus diesen Metriken sollen automatisch KPIs abgeleitet werden. Beispiele für solche Metriken sind die durchschnittliche Laufzeit einer ETL-Strecke oder der Grenzwert, ab dem ein Alarm generiert werden soll.
- Entsprechende Werkzeuge sollen mit externen Lösungen (zum Beispiel ETL-Werkzeugen anderer Anbieter, Open-Source-Frameworks) kompatibel sein.
- Anomalien in den Daten sollen automatisch erkannt werden. Dazu müssen entsprechende Werkzeuge in die Datenströme hineinschauen können.
- Funktionalität für Alerting soll verfügbar sein für entsprechende Benachrichtigungen, falls KPIs nicht eingehalten werden oder sonstige Anomalien auftreten.
- Workflows sollen für die effektive Zusammenarbeit bei der Behebung von operativen Problemen unterstützt werden.
- Eine einfache und schnelle Ursachen- und Impact-Analyse soll beim Auftreten von Problemen unterstützt werden. Ein Beispiel hierfür ist die Möglichkeit, von einem Problemreport automatisch in die ETL-Strecke oder den entsprechenden Programmcode abspringen zu können.
Nachvollziehbarkeit von Abläufen
Wie bei der reinen Nachvollziehbarkeit der Datenflüsse hat man auch für die Nachvollziehbarkeit von Abläufen zunächst einen gerichteten Graphen, der die Abhängigkeiten der einzelnen Schritte in einem Ablauf repräsentiert. Dieser Graph kann Zyklen haben, wenn bestimmte Schritte in einem Ablauf wiederholt werden. Wenn man aber die einzelnen Instanzen der Ablaufschritte betrachtet, kommt man zu einem gerichteten azyklischen Graphen (DAG). Abbildung 3 veranschaulicht das an einem Beispiel.
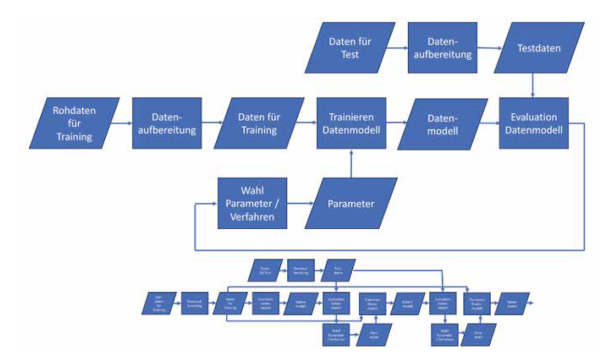
Abb . 3: Abläufe in Data Pipelines
Im oberen Teil der Abbildung sieht man einen Ablauf zum Trainieren eines Machine-Learning-Modells als Ausprägung eines Datenflusses. Im unteren Teil sieht man den azyklischen Graphen für einen zugehörigen konkreten Ablauf.
Die Nachvollziehbarkeit von Abläufen hat verschiedene Aspekte: So soll überprüft werden können, ob die Abläufe ihren Spezifikationen und Nebenbedingungen entsprechen: Werden Daten zum erwarteten Zeitpunkt geliefert? Entspricht die Anzahl der zur Verfügung gestellten Ladedateien der erwarteten Anzahl? Passt das Format der Ladedateien zum erwarteten Format (oder hat sich zum Beispiel bei einer CSV-Datei die Anzahl der Spalten geändert)? Bewegt sich die Laufzeit eines Ablaufschrittes im vorgegebenen Rahmen (auch zu schnelle Verarbeitung kann auf einen Fehler hindeuten)? Stehen alle benötigten Ressourcen zur Verfügung?
Auch bei erzeugten Objekten wie Machine-Learning-Modellen sollte überwacht werden können, ob sich deren Qualität ändert: Tritt Drift oder Bias nach einer gewissen Zeit auf? Diese Nebenbedingungen können entweder fest vorgegeben sein oder das System kann aus den Abläufen der Vergangenheit lernen, in welchen Bereichen sich bestimmte Werte bewegen sollen, und Anomalien aufzeigen. Voraussetzung ist dabei, dass alle wesentlichen Parameter für jeden konkreten Ablauf festgehalten werden. Dies ist zum einen wichtig, um Trainingsdaten zu haben, damit ermittelt werden kann, was erwartete Werte sind, aber auch um beim Erkennen eines Problems im Nachhinein noch ermitteln zu können, wann das Problem zum ersten Mal aufgetreten ist.
Um die Nachvollziehbarkeit von Abläufen zu gewährleisten, sollen unter anderem folgende Informationen gesammelt werden:
- Wann wurde ein Schritt gestartet?
- Wann wurde er beendet?
- Welche Ressourcen wurden genutzt?
- Was wurde als Input bei einem Schritt benutzt (Daten und Parameter)?
- Wie war die Umgebung während der Ausführung? • Was ist das erwartete Ergebnis eines Verarbeitungsschritts?
Man benötigt dazu ein übergreifendes Tooling, das mit allen eingesetzten Komponenten – seien es nun Datenformate oder Applikationen – zurechtkommt.
Zusammenfassung
Der Nachvollziehbarkeit von Datenflüssen und zugehörigen Abläufen kommt in einer wachsenden Zahl von Anwendungsfällen eine immer größere Bedeutung zu. Dabei geht es einerseits um mehr Transparenz bezüglich der Herkunft und Verwendung von Daten, aber auch um die Verbesserung von operativen Abläufen. Dies betrifft auch den Bereich Machine Learning und das relativ neue Thema „generative KI“. Hier wird aktuell besonders deutlich, dass die Nachvollziehbarkeit, wie generierte Daten entstanden sind und aus welchen Quellen sie stammen, eine zentrale Voraussetzung für den Einsatz in geschäftskritischen Anwendungen ist.
Weitere Informationen
[DSG23] Datenschutz-Grundverordnung, https://www.bmj.de/DE/themen/digitales/DSGVO/DSGVO_node.html, abgerufen am 31.10.2023
[Ery23] Eryurek, E. et al.: Data Governance – The Definitive Guide. O’Reilly 2021
[IBM23] IBM Data Observability by Databand.
https://www.ibm.com/docs/en/dobd?topic=overview, abgerufen am 31.10.2023
[MGV22] Moses, B. / Gavish, L. / Vorwerck, M.: Data Quality Fundamentals. O’Reilly 2022
[Pet22] Petrella, A.: What is Data Observability? O’Reilly 2022
[Pet23] Petrella, A.: Fundamentals of Data Observability. O’Reilly 2023
[ReH22]Reis, J. / Housley, M.: Fundamentals of Data Engineering. O’Reilly 2022
[StS23] Stanley, J. / Schwartz, P.: Automating Data Quality Monitoring at Scale. O’Reilly, Dezember 2023, Early Release verfügbar









