

Das Cross-Business-Architecture Lab
Das Cross-Business-Architecture Lab (CBA Lab) ist ein Verband von Anwendern für Anwender. Erprobte Best Practices werden geteilt und zu belastbaren, direkt nutzbaren Ergebnissen weiterentwickelt. Das CBA Lab erarbeitet mit und für seine Mitglieder innovative „Bausteine“ für die Digitale Transformation, die die Architektur prägen und organisieren.
Weitere Informationen zum Verband finden Sie unter: cba-lab.de
Die Erwartungen an ML sind übergroß. Gleichzeitig fehlen die Experten, deren Mangel sich durch den ultraschnellen Technologiewandel noch gravierender bemerkbar macht. Vom Erfolgsdruck getrieben, verzichten die meisten Unternehmen am Anfang ihrer ML-Projekte auf den Aufbau einer geeigneten Infrastruktur. Damit könnten sie nachvollziehbar und automatisiert Experimente mit verschiedenen Methoden beziehungsweise Lernalgorithmen, Parametrisierungen und Daten durchführen. Aber sie setzen auf Prototypen, bei denen das meiste händisch erledigt werden muss. Das ist bei ML deutlich problematischer als bei klassischen Softwareprojekten, weil ML-Modelle durch ihre Abhängigkeit von Daten regelmäßig angepasst werden müssen. Anpassungen sind ohne die entsprechende Infrastruktur deutlich aufwendiger, weil nichts automatisiert werden kann. Das ist einer der wesentlichen Gründe, warum ML-Projekte so oft in der Prototypen-Sackgasse enden.
Unsicherheiten auf der Fachseite
Ein zweiter wesentlicher Grund dafür ist, dass fachliche Entscheider von ML-Lösungen das Gleiche erwarten wie von klassischen Softwarelösungen: deterministische Ergebnisse mit erklärbarem Antwortverhalten. Deshalb stellen sich schnell Unsicherheiten ein, wenn Prototypen in Fachbereichen erprobt werden. Die ML-Methode ist häufig unklar, das Zustandekommen der Ergebnisse kann nicht nachvollzogen werden, und dass die Auswahl der Trainingsdaten großen Einfluss auf die zu erlernenden Zusammenhänge hat, ist den meisten auf der Fachseite ebenfalls nicht klar.
Weitere Gründe für das Steckenbleiben von ML-Projekten in der Prototypenphase sind:
- Der Datenschutz ist in Bezug auf ML oft nicht klar. Dürfen zum Beispiel Bilder von Personen für das Training von ML-Modellen genutzt werden? Wenn Entscheidungen von einem ML-System getroffen werden, zum Beispiel bezüglich eines Kredits, ist nicht klar geregelt, wie detailliert die Entscheidung gegenüber den Betroffenen nachvollziehbar gemacht werden muss.
- Erfahrene Data-Science- und ML-Engineering- Spezialisten sind am Arbeitsmarkt eine rare Ressource. Sie werden aber für kompetente Entwicklungsteams gebraucht – genauso wie Expertise im Bereich Software-Engineering und Betrieb [Cos21]. Den eingesetzten Teams fehlt es außerdem an Kompetenzdiversität. Das kann dazu führen, dass Pilotprojekte in kleinem Rahmen funktionieren, dann aber technisch und organisatorisch nicht skalieren (cross-funktionale Teams können hier eine Lösung darstellen.)
- Die Kosten werden häufig unterschätzt, weil mehr Aufwand als in einem klassischen Softwareprojekt berücksichtigt werden muss (zum Beispiel höhere Personalkosten oder Kosten für Datenaufbereitung, Spezialhardware, Modelltraining, Wartezeiten der Fachseite, Überführung in die Produktion).
- Fehlende Nachvollziehbarkeit der Entscheidungen
- Unbekannte Abhängigkeiten der Daten, die für das Trainieren der Modelle verwendet werden
- Fehlende oder nicht verlässliche Daten
ML ist keine Allzweckwaffe
Gerade weil die Erwartungen groß sind und die Hürden hoch, ist es wichtig zu fragen, welche Aufgaben sich mit ML-Methoden tatsächlich lösen lassen. Um diese Frage positiv beantworten zu können, muss eine Aufgabe folgende Eigenschaften aufweisen: Es existiert ein Muster (in den Daten), sie ist mathematisch nicht zu beschreiben und es gibt umfangreiche Trainings- & Testdaten.
Selbst wenn die Voraussetzungen für ML erfüllt sind, ist ML nicht immer der beste Lösungsansatz. Zuerst muss die Frage gestellt werden, ob sich das Problem nicht bereits mit traditionellen Methoden lösen lässt, zum Beispiel durch Berechnung der zugrunde liegenden physikalischen Prozesse. Diese Methoden bieten oft den Vorteil, dass die Vorhersagen weitaus präziser sind als die Vorhersagen mittels ML.
Übersteigt die gestellte Aufgabe eine bestimmte Komplexität und lässt sie sich nicht mehr oder nur mit erheblichem Aufwand durch mathematische Gleichungen oder andere klassische Verfahren beschreiben, dann ist es sinnvoll, ML als Lösungsansatz in Betracht zu ziehen.
MLOps ist angelehnt an DevOps
ML-Lösungen lassen sich am besten als MLOps entwickeln und betreiben. Der Begriff MLOps ist angelehnt an DevOps, aber um ML-Spezifika erweitert. Der MLOps-Prozess ist grob in vier Phasen untergliedert (siehe Abbildung 1):
- In der Vorbereitungs-Phase wird betrachtet, ob alle Voraussetzungen für ein ML-Vorhaben gegeben sind, sowohl aus einer ökonomischen, einer Governance- als auch aus einer Datensicht.
- Die Proof-of-Concept-Phase lässt sich grob in eine Exploration- und eine Vertiefungsphase unterteilen. In der Exploration-Phase wird die prinzipielle Machbarkeit des Use-Case auf schnelle Art und Weise überprüft. Ist diese gegeben und aussichtsreich, wird der Proof of Concept in der Vertiefungsphase tiefergelegt und bereits betriebliche Aspekte mitbetrachtet.
- In der Entwicklungs- und Transitions-Phase wird der Use-Case in eine betriebliche Umgebung eingebettet, die auch die notwendigen Prozesse für Betrieb und Weiterentwicklung umfasst.
- Schließlich wird in der Betriebs-Phase die erarbeitete Lösung betrieben, überwacht und kontinuierlich weiterentwickelt.
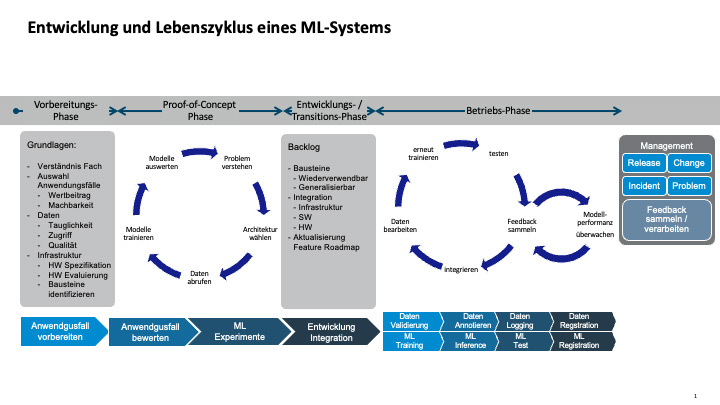
Abb. 1: Im hier abgebildeten Lebenszyklus eines ML-Systems wird auch der MLOps-Ablauf deutlich
Die Einführung von MLOps ermöglicht eine Automatisierung, Versionierung und Reproduzierbarkeit von ML-Systemen und unterstreicht gleichzeitig die erfolgreiche Zusammenarbeit der erforderlichen Fähigkeiten von Data Engineers, Data Scientists, ML-Ingenieuren und Softwareentwicklern.
Die richtigen Capabilities entscheiden
Um ML-Lösungen aus der Pilotphase in die Produktion zu überführen, braucht es neben der entsprechenden Expertise noch weitere Capabilities. Das CBA Lab hat insgesamt sechs definiert (siehe Abbildung 2):
- Mensch & Kompetenz: Der Mensch und die benötigten Fertigkeiten sind eine Grundvoraussetzung für ein erfolgreiches MLOps. Es braucht nicht nur den Data Scientist, den ML Engineer, sondern eine Vielzahl unterschiedlichster Fähigkeiten. Diese müssen rekrutiert, ausgebildet und an die Organisation gebunden werden, um für eine funktionierende ML-Umgebung bereit zu sein.
- Kultur: Die Organisation muss sich auf die neuen Technologien auch kulturell vorbereiten. Es braucht bei den einzelnen Teilnehmern einer MLOps-Initiative, aber auch in der gesamten Organisation die Bereitschaft, sich auf ML-unterstützte Prozesse einzulassen und diese ständig weiterzuentwickeln. Eine Grundvoraussetzung dafür ist die Unterstützung des Top-Managements: Die Organisation kann sich erst dann zur Einführung von MLOps verpflichten, wenn das Top-Management klare, unterstützende Signale sendet. Dazu dienen beispielsweise eine AI-Vision sowie eine entsprechende Strategie, aber auch die Förderung des Know-how-Aufbaus im Bereich von ML. Grundlegende Elemente sind:
– Transdisziplinäre Zusammenarbeit: MLOps basiert auf dem Zusammenführen unterschiedlicher Perspektiven und Fähigkeiten wie Fachwissen, Datenanalyse, ITC etc.
– Innovationsbereitschaft: Fördert die Bereitschaft, bestehende Prozesse durch den Einsatz von ML zu verändern.
– Veränderungsmanagement: Durch die gezielte Begleitung der Mitarbeitenden und konkrete Unterstützungsangebote werden Verständnis und Änderungsbereitschaft gefördert. - Prozesse: Änderungen, die mit der Adaption von ML einhergehen, beeinflussen immer die Prozesse einer Organisation. Die Prozesse werden aufgrund des systematischen Einbezugs von Datenströmen verändert. Qualität und Pflege der Daten für ML bedeuten auch neue Herausforderungen: Die Kontrolle der Prozesse und der generierten Resultate muss kontinuierlich verbessert werden, damit das ML-System nicht außer Kontrolle gerät und möglicherweise beträchtlichen Schaden anrichtet.
- Daten: Daten sind der Treibstoff für eine ML-Organisation. Ohne qualitativ hochwertige, vollständige und korrekte Daten gibt es kein ML. Unternehmen haben häufig Probleme mit der Qualität historischer Daten. Deshalb müssen grundlegende Fähigkeiten wie Datenaufbereitung, Datenverarbeitung und Datenqualitätssicherung verbessert werden, um die Bereitschaft für ML zu erhöhen. Folgende Elemente sind dabei von besonderer Bedeutung:
– Datenverfügbarkeit: ML-basierte Systeme lernen auf der Grundlage großer Datenmengen.
– Datenqualität: Je höher sie ist, umso bessere Resultate liefern die ML-basierten Systeme.
– Datenzugriff: Data Scientists und ML-Engineers benötigen Zugriff auf die relevanten Datenquellen, um Analysen durchzuführen sowie die Bereitstellung und den laufenden Betrieb sicherzustellen. - Technologie und Infrastruktur: ML basiert auf einem komplexen Technologie-Stack und benötigt eine hochperformante Infrastruktur, gleichwohl in einem sehr dynamischen Umfeld. Die stetige technologische Innovation und Pflege sind Grundvoraussetzung für ML. Dafür müssen die notwendigen Ressourcen sowohl finanziell als auch personell bereitgestellt werden.
- Risiko, Compliance & Ethik: Der Einsatz von Systemen, die potenziell selbstständig Entscheidungen treffen, birgt Gefahren. So können unausgewogene Daten zu tendenziösen Resultaten und unethischen Entscheidungen führen, die im schlimmsten Fall Menschen gefährden und eine ganze Organisation bedrohen können. Die Beherrschung der Risiken und die Sicherstellung der Compliance werden damit vor neue Herausforderungen gestellt.
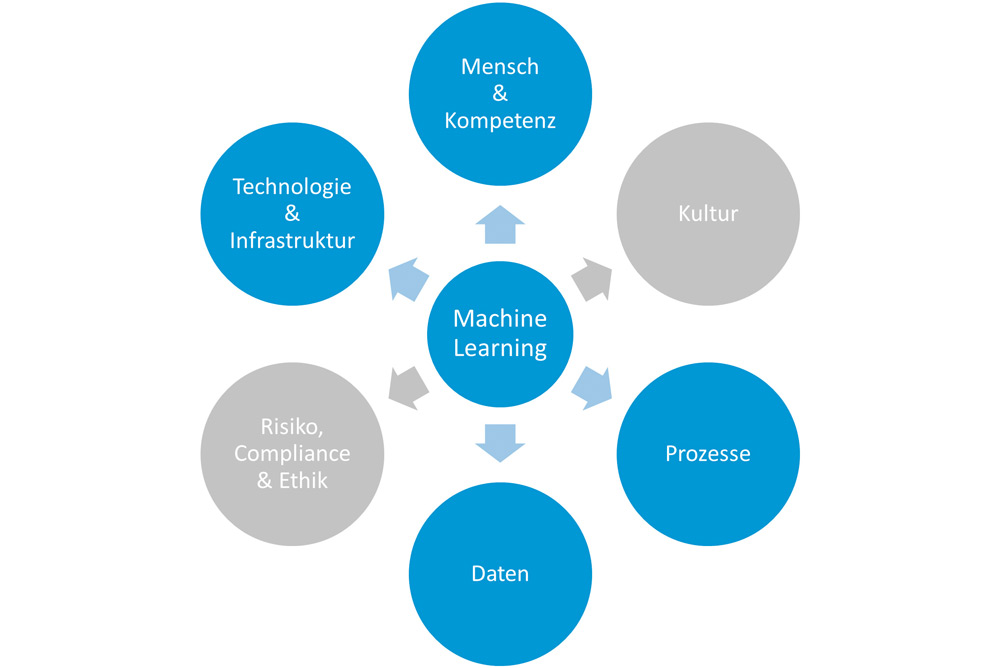
Abb. 2: Die wichtigsten Capabilities, die ein Unternehmen braucht, um ML erfolgreich produktiv einzusetzen
Daten, Daten, immer wieder Daten
Weil hinlänglich bekannt ist, dass Daten von herausragender Bedeutung für ML sind, widmen wir ihnen in dieser kleinen Handreichung für die Produktionalisierung von ML-Lösungen noch eine genauere Erklärung. ML-Systeme bestehen grob gesehen aus zwei Komponenten: einer Modellarchitektur und den Daten. Die Entwicklung eines solchen Systems kann deshalb mit einem modellzentrierten oder einem datenzentrierten Ansatz geschehen [Jo21]. Hier wird besonderes Augenmerk auf den datenzentrierten Ansatz gelegt. Deshalb betrachten wir die Aspekte Datenqualität, Metadaten oder die Daten-Governance sowie den Daten-Lifecycle hier genauer.
Datenqualität: Mit schlechten Daten entsteht kein gutes Modell. Deshalb fokussiert sich der datenzentrierte Ansatz auf die Daten und deren Qualität. Bei dieser Vorgehensweise wird die Modellarchitektur festgelegt und das Modell durch eine iterative Datenqualitätssteigerung verbessert, indem beispielsweise Labels korrigiert, die Konsistenz des Labeling erhöht oder die Ausgewogenheit der Daten optimiert werden.
Bei strukturierten Daten haben sich einige etablierte Messgrößen entlang mehr oder weniger etablierter Qualitätsdimensionen entwickelt, wie Vollständigkeit, Rechtzeitigkeit oder Richtigkeit. Diese Dimensionen sind ebenfalls bei unstrukturierten Daten sinnvoll, jedoch ist deren Messung nicht in gleicher Weise etabliert und vielfach auch viel schwieriger umzusetzen. Deshalb hilft die Beschränkung auf drei Qualitätsdimensionen:
- Interpretierbarkeit – Hilft der Datenpunkt den Inhalt zu verstehen?
- Relevanz – Welchen Wert hat der Datenpunkt für das zu lernende Modell?
- Genauigkeit – Sind die Daten präzise genug für das Lernen?
Daten-Governance: Ihr oberstes Ziel ist, die Integrität und Qualität der Daten zu gewährleisten, eine Grundvoraussetzung, um das ganze Potenzial der Daten abschöpfen zu können. Ein weiterer Punkt tritt zunehmend in den Fokus der Datenverarbeitung: Einzelne Unternehmen sind nicht mehr in der Lage, alle anfallenden Daten so zu veredeln, dass sie als Grundlage für ML-Trainings dienen können. Aus diesem Grund haben sie begonnen, ihre Kräfte zu bündeln und die Daten gemeinsam zu nutzen. Das verlangt nach einer gestiegenen Verantwortung, was die Sicherheit der Daten betrifft oder den Ansatz von komplexen Lernumgebungen, wie zum Beispiel Federated Learning. Standards und Richtlinien sind erforderlich, um sicherzustellen, dass solche gemeinsam genutzten Daten nur innerhalb definierter Grenzen verwendet werden können und kein Missbrauch damit getrieben wird.
Daten-Lifecycle: N. Polyzotis beschreibt den Daten-Lifecycle [Pol18]: Daten werden von einer Primärquelle, zum Beispiel einem Sensor, erhoben und für das ML vorbereitet, zum Beispiel durch den Labeling-Prozess. Parallel dazu muss die „Ground Truth“ sorgfältig erstellt werden. Mit den Trainingsdaten wird anschließend ein Modell erstellt und evaluiert. Schließlich muss die Genauigkeit des Modells anhand der „Ground Truth“-Daten überprüft werden. Diese Validierung muss jedoch nicht nur für ein neu trainiertes Modell erfolgen, sondern kontinuierlich auch für bestehende, produktive Modelle. Gibt es Abweichungen zwischen diesen Datensets, wird das auf Basis der Trainingsdaten erstellte Modell keine konsistenten Resultate zeigen. Deshalb müssen erkannte Abweichungen, zum Beispiel Unterschiede oder Änderungen der Input-Daten, zu den Trainingsdaten zurückgemeldet werden, um die Trainingsdaten zu verbessern. Schließlich sind die Trainings- und eventuell auch die verwendeten „Ground Truth“-Daten an die neuen Verhältnisse anzupassen: Die Daten müssen bereinigt, nicht mehr valide Datenpunkte aus den Trainings- und Validierungsdaten entfernt und schließlich betroffene Modelle optimiert werden. Um dies gewährleisten zu können, ist es unumgänglich, dass alle notwendigen Informationen dazu in den ML-Metadaten festgehalten werden.
Metadaten: Damit Nachvollziehbarkeit und Interpretierbarkeit von ML-Modellen gewährleistet werden können, muss eine durchgehende Kette existieren, angefangen bei den Trainings- und Testdaten über die Parameter und Konfiguration der Lernalgorithmen bis hin zu den einsetzbaren Modellen. Das wird mit ML-Metadaten erreicht.
Was eine ML-Architektur können muss
Beim DevOps- beziehungsweise MLOps-Ansatz wird Continuous Delivery immer mitgedacht. Im Fall von Machine Learning hat Continuous Delivery das Ziel, einen einheitlichen Tooling-Ansatz für den Lebenszyklus des maschinellen Lernens bereitzustellen. Besonderer Fokus liegt hierbei auf der automatisierten, skalierbaren Herstellung von KI-Modellen und deren Betrieb. In Data-Science-Projekten liegen Auswahl und Anwendung geeigneter analytischer Methoden häufig im Kern der Betrachtung. Die meisten Data-Science-Projekte verfolgen das Ziel, durch ein Modell Entscheidungen oder Vorhersagen zu treffen, die schließlich in die Wertschöpfungskette einfließen.
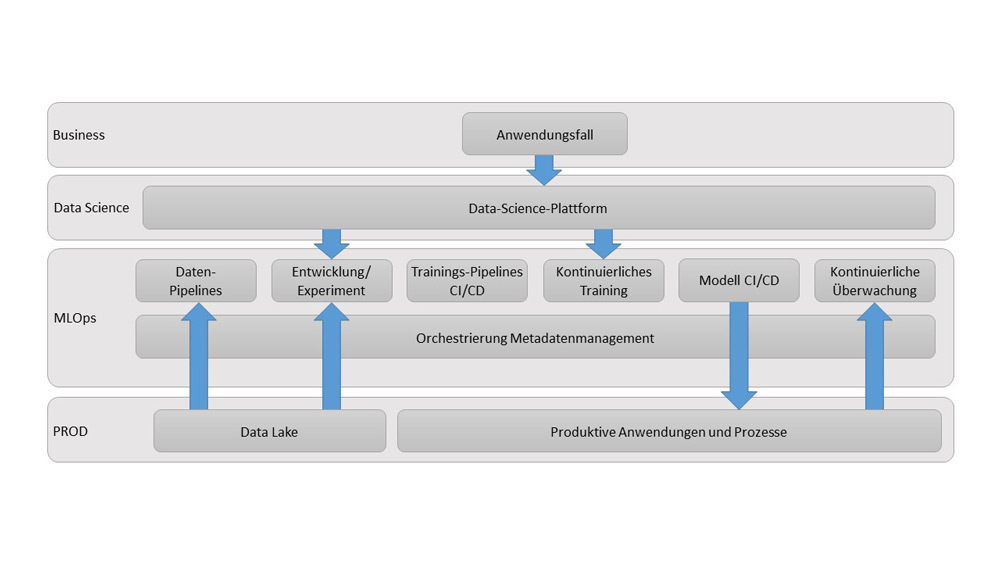
Abb. 3: Schematische Darstellung der technischen Building Blocks eines ML-Systems
Fazit
ML-Lösungen müssen sorgfältig vorbereitet und von eigenen Teams betreut werden, damit sie produktiv eingesetzt werden können. Der Aufwand für ML entsteht nicht nur in der Entwicklung der ML-Modelle, vielmehr liegt er in der für den Betrieb nötigen Infrastruktur und der Bereitstellung der notwendigen Capabilities im Unternehmen. Diese reichen weit über die Technologie hinaus, berühren viele Prozesse und die Kultur des Unternehmens. Bevor Unternehmen den beträchtlichen Aufwand für ML-Lösungen betreiben, sollten sie sich fragen, wie groß ihr Bedarf an ML tatsächlich ist beziehungsweise welche ihrer Herausforderungen sich überhaupt mit ML lösen lassen.
Weitere Informationen
[Cos21] Costa, D.: Essential Skills for Machine Learning Architects. Gartner 2021, https://www.gartner.com/document/3996709?ref=solrAll&refval=283825147, abgerufen am 2.11.2022
[Jo21] Jo, T.: Machine Learning Foundations: Supervised, Unsupervised, and Advanced Learning. Springer International Publishing 2021, https://doi.org/10.1007/978-3-030-65900-4
[Pol18] Polyzotis, N. et al.: Google Research, Data Lifecycle Challenges in Production Machine Learning: A Survey. Sigmod Record, Vol. 47, Juni 2018









