

CQRS [Wiki-a] wurde ursprünglich von Greg Young definiert und beschreibt ein Entwurfsmuster zur Trennung von verändernden Operationen (Command) und lesenden Zugriffen (Read). Dabei kommen verschiedene Objektmodelle für beide Modi zum Einsatz, ganz im Gegenteil zum sonst sehr verbreiteten Create-Read-Update-Delete-Modell (CRUD-Modell), welches in klassischen Schichtenarchitekturen für Lese- und Schreiboperationen gemeinsam verwendet wird. Der offensichtliche Nachteil des Aufwands zur Pflege verschiedener Modelle wird dabei vor allem durch die Möglichkeit zur unabhängigen Skalierbarkeit der Lese- und Schreibzugriffe aufgewogen.
Warum eigentlich CQRS/ES und welche Vorteile bietet es?
Auch moderne Cloud-Anwendungen müssen oft deutlich häufiger Daten lesen als verändern. Durch eine Trennung der beiden Modelle lassen sich insbesondere für lesende Zugriffe sehr viel besser skalierende Modelle und Technologien nutzen. Zudem lassen sich auch verschiedene Read-Modelle für unterschiedliche Konsumenten ableiten, zum Beispiel optimiert auf Mobil-Geräte oder für Dashboard-Auswertungen. Ein singuläres CRUD-Modell skaliert hier unverhältnismäßig aufwendig.
Die Flexibilität von CQRS, im Bedarfsfall auch neue Read-Modelle zu projizieren – an die man vorab vielleicht noch gar nicht gedacht hat – setzt voraus, dass sich die dafür notwendigen Daten vollständig aus dem Write-Modell ableiten lassen. Je mehr Wissen man hier über vergangene Änderungen am Datenbestand konservieren kann, desto flexibler ist man bei der Projektion. Zustandsbasierte Modelle kommen hier schnell an ihre Grenzen, da man die Änderungshistorie hier nur unzureichend abbilden kann.
Event Sourcing [Wiki-b] hingegen ist ein Verfahren, bei dem stattdessen die Änderungen in Form von Events gespeichert werden. Dabei repräsentieren die Events bereits vollzogene Änderungen im System (basierend auf sämtlichen vorangegangenen Events) und werden daher vornehmlich in der Vergangenheitsform benannt. Zur Wiederherstellung eines Zustands werden diese Events erneut gelesen – daher der Name Event „Sourcing”. Das ist zwar deutlich aufwendiger, wird aber zumeist nur für die Command-Verarbeitung benötigt, welche seltener benötigt wird als die Read-Modelle.
Die Verarbeitung eines Commands (inklusive der daraus resultierenden Events) erfolgt in der Regel transaktional. Das aus dem Domain-Driven Design (DDD) [Wiki-d] bekannte Aggregate bildet hierbei den Rahmen für sämtliche Zustandsdaten, welche im Rahmen der Verarbeitung benötigt und mittels Event Sourcing wiederhergestellt werden. Der erhöhte Speicherbedarf für die Event-Persistierung spielt dabei heutzutage kaum noch eine Rolle. Vielmehr schätzt man beim Event Sourcing die natürliche Form der Speicherung von Änderungen als Events und die vollständige Auditierbarkeit der Event-Historie.
Die so persistierten Events können parallel dazu herangezogen werden, die Read-Modelle abzuleiten. Da es sich bei diesen Modellen in der Regel ebenfalls um persistente Datenmodelle handelt, müssen nicht ständig sämtliche alten Events neu verarbeitet werden, vielmehr folgt eine Projektion eines Read-Modells stetig dem Event-Strom und verarbeitet sämtliche für sie relevanten Events. Dabei unterstützt dieser Ansatz selbstverständlich polyglotte Persistenzanforderungen, das heißt, die für den Event-Strom gewählte Speichertechnologie (zum Beispiel SQL) muss nicht mit der für die Zielprojektion gewählten Technologie übereinstimmen (zum Beispiel einem Suchindex oder einer Message Queue).
Dass neue Events im Rahmen der Command-Verarbeitung zumeist in einer vorgelagerten Transaktion geschrieben werden, die Projektionen der Read-Modelle jedoch in nachgelagerten separaten Transaktionen erfolgen, hat zudem den Vorteil, dass transaktionale Ressourcen nicht unnötig miteinander verknüpft werden. CQRS/ES unterstützt somit auf natürliche Weise das Pattern „Transactional Outbox” [Rich-a] und kann für eine garantierte Verarbeitung der Events sorgen. CQRS und Event Sourcing unterstützen und ergänzen sich stark gegenseitig (siehe Abbildung 1). Event Sourcing ermöglicht es, jederzeit neue Read-Modelle anhand der Event-Historie zu erstellen und im Bedarfsfall bestehende Read-Modelle zu ändern, indem man zum Beispiel die Event-Historie erneut verarbeitet (Replay). Im Gegenzug kann CQRS als Enabler für Event Sourcing gesehen werden, da dieses ungeeignet für generische Abfragen des aktuellen Zustands ist. Die strikte Separation der Read-Modelle kompensiert diesen Aspekt, indem abfrageoptimierte Projektionen aus den Events erstellt werden.
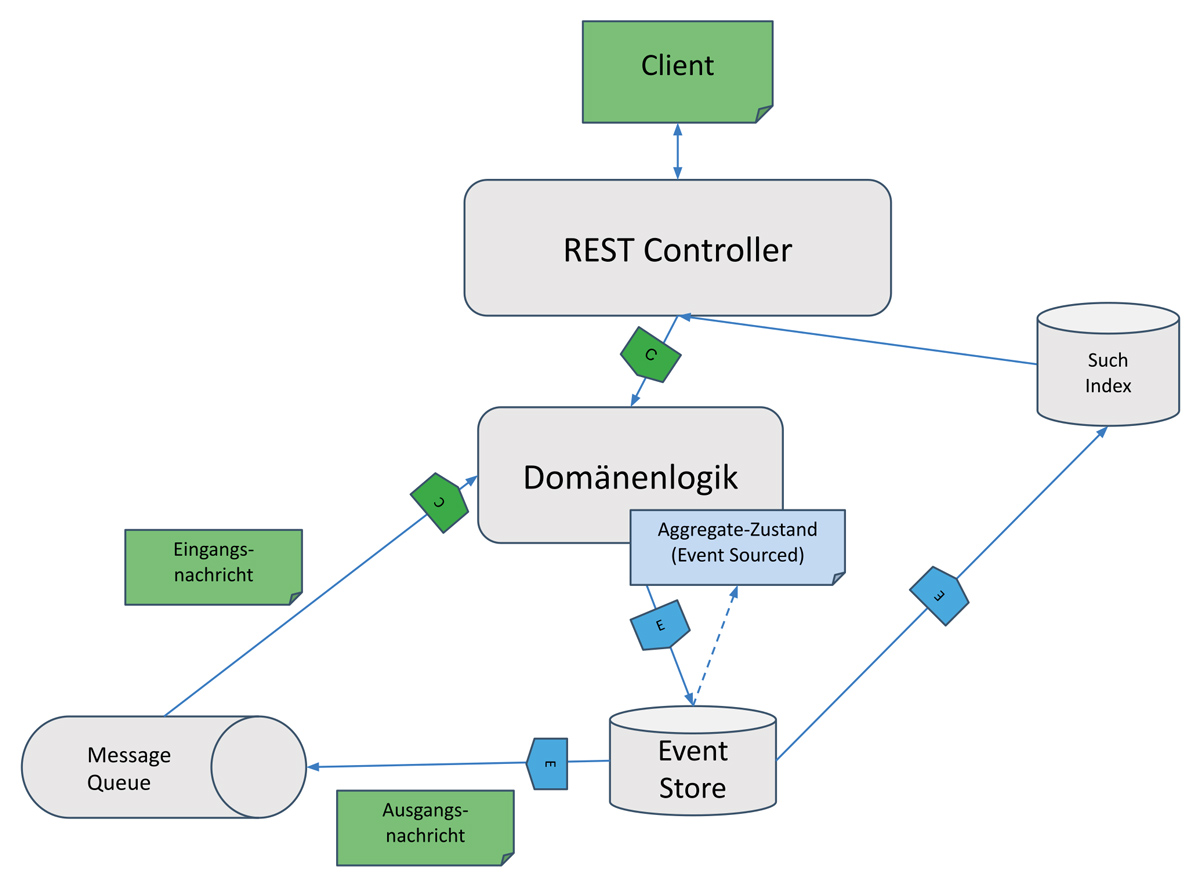
Abb. 1: Beispiel eines CQRS/ES-basierten Architekturentwurfs
CQRS/ES mit dem Axon-Framework umsetzen
Hat man sich für die Umsetzung einer CQRS/ES-basierten Anwendungsarchitektur entschieden, gilt es, geeignete unterstützende Frameworks für CQRS und/oder Event Sourcing auszuwählen. Im Vergleich zu diversen – teils sogar cloud-gehosteten – ES-Frameworks mit entsprechenden Event-Stores ist die Auswahl von CQRS/ES-Frameworks deutlich überschaubarer. Im Umfeld JVM-basierter Entwicklungen hat sich das Open-Source-Framework Axon von AxonIQ etabliert. Es zeichnet sich insbesondere durch seine Integration mit Spring Boot aus. Zudem kann Axon in einer Spring-Boot-Anwendung sowohl einen eingebetteten Event-Store (zum Beispiel eine SQL-Datenbank) als auch den von AxonIQ angebotenen Axon-Server als Event-Store nutzen. Letzterer bietet neben der reinen Event-Persistierung weitere Funktionen für den produktiven Einsatz: So kann das für die Command-Verarbeitung zwingend benötigte Event-Sourcing in verteilten Umgebungen durch eindeutige Zuordnung des verarbeitenden Cluster-Knotens und zusätzliches Caching des Aggregate-Zustands hinsichtlich der Performanz optimiert werden. Ebenso kann der Axon-Server für die Verschlüsselung GDPR-relevanter Eventinhalte konfiguriert werden, um diese im Bedarfsfall im Event-Strom unkenntlich zu machen, ohne die Events selbst löschen zu müssen. Informationen in einer Axon-basierten Anwendung werden ausschließlich über Commands, Exceptions und Events transportiert. Commands bündeln die im Rahmen einer Transaktion zu verarbeitenden Informationen. Events repräsentieren persistente Änderungen und die damit verbundenen Daten. Die meisten Commands beziehen sich auf Aggregate-Instanzen, das heißt, sie erzeugen diese oder werden von ihnen verarbeitet.
Wie in Listing 1 zu sehen ist, können beliebige DTO-artige Klassen (in Kotlin vornehmlich Data-Classes) als Commands und Events eingesetzt werden. Einzige Anforderung an die Command-Klasse ist die Annotation des TargetAggregate Identifiers, damit Axon das Command dem richtigen Aggregate-Typ und der entsprechenden Aggregate-Instanz zuordnen kann.
Die Zustellung des Commands an den CommandHandler innerhalb eines Aggregates wird von Axon gekapselt, da der Aggregate-Zustand vor der Command-Ausführung aus den historischen Events wiederhergestellt werden muss (Event Sourcing). Dazu stellt die Axon-Konfiguration ein CommandGateway-Spring-Bean bereit, welches aus beliebigen Teilen der Anwendung aufgerufen werden kann, zum Beispiel dem REST-Controller einer Webanwendung. Das Aggregate selbst ist somit weitgehend von technologischen Aspekten entkoppelt. Es muss sich insbesondere nicht aktiv um das Laden des aktuellen Zustands kümmern; dies erfolgt automatisch über den Axon Event-Store und die im Aggregate definierten EventSourcing-Handler. Dabei werden sämtliche Events der jeweiligen Aggregate-Instanz geladen und in der Originalreihenfolge den Handlern übergeben.
Anhand des so rekonstruierten In-Memory-Zustands entscheidet der Command Handler dann, ob und welche Events emittiert werden sollen oder ob die Command-Ausführung abgewiesen wird, zum Beispiel durch Werfen einer Exception.

Listing 1: Beispiel Commands und Events
Benötigt die Command-Ausführung neben dem wiederhergestellten Zustand des Aggregates weitere Informationen, so kann sie diese selbstverständlich aus Drittsystemen beziehen. Da es sich dabei aber um rein lesende Zugriffe handelt, werden Seiteneffekte vermieden. Listing 2 zeigt ein ShoppingCart-Aggregate mit seinen verschiedenen Handler-Methoden. Neue Events werden im Kontext der Command-Verarbeitung durch den Aufruf von AggregateLifecycle.apply() emittiert. Dabei erfolgt die Command-Verarbeitung inklusive der Event-Erzeugung transaktional, das heißt, man kann sich darauf verlassen, dass mehrere Events ganz oder gar nicht persistiert werden. Race Conditions durch nebenläufige Command-Verarbeitungen ein und derselben Aggregate-Instanz werden durch eine implizite Sequenznummer der Aggregate-Events vermieden. Somit ist auch die Isolation paralleler Commands garantiert.

Listing 2: Beispiel “ShoppingCart” Aggregate
Die Umsetzung der Fachlogik wird somit auf zwei wesentliche Aspekte reduziert: die Prüfung der Gültigkeit des Commands anhand des aktuellen Aggregate-Zustands und die Protokollierung der Änderung in Form neuer Events. Diese Reduktion vereinfacht vor allem auch die Testbarkeit. Axon bietet dafür, wie in Listing 3 zu sehen, die sogenannte AggregateTest Fixture, welche im Given-When-Then-Stil den automatisierten Test eines Aggregates unterstützt.
Hierbei zahlt es sich aus, dass sämtliche technologischen Aspekte zum Laden und Persistieren von Events sowieso vom Framework gekapselt werden und somit für die Testausführung durch die Test-Fixture simuliert werden können. Die Domain-Tests lassen sich folglich ideal als schnell ausführbare Unit-Tests implementieren.

Listing 3: Aggregate Unit-Test
Die aus der Domänenlogik entstehenden Events werden nicht nur für die Rekonstruktion des Aggregate-Zustands herangezogen, sondern lassen sich mit Axon beliebig weiterverarbeiten. Man spricht hierbei auch von Projektionen, da die Events dabei in spezifische Read-Modelle überführt werden. Insofern sind die dafür verantwortlichen Event-Handler meistens technologiebehaftet und zählen streng genommen nicht zur Domänenlogik.
EventHandler annotierte Methoden in Spring-Beans werden von Axon anhand des zugehörigen Java-Packages oder anhand der ProcessingGroup-Annotation gruppiert und asynchron verarbeitet. Dabei werden sämtliche Events des gesamten Event-Stroms je Gruppe verarbeitet, sodass es über unterschiedliche Gruppen möglich ist, (parallel) verschiedene Projektionen aufzubauen. Jede Gruppe folgt dem Event-Strom anhand eines persistenten Tracking-Tokens, sodass auch bei temporär deaktivierter Projektion oder in Fehlersituationen, zum Beispiel bei Nichterreichbarkeit von Drittsystemen, keine Events „verloren” gehen. Axon spricht in diesem Kontext von sogenannten Tracking-Event-Prozessoren. Listing 4 zeigt beispielhaft eine relationale Datenbankprojektion mit Spring Data JPA. Der Vollständigkeit halber sei erwähnt, dass sich auch Subscribing-Event-Prozessoren konfigurieren lassen. Deren Event Handler werden synchron (im selben Thread) in Folge eines im Aggregate emittierten Events ausgeführt, partizipieren also direkt an der Command-Ausführung. Subscribing-Prozessoren lassen sich folglich nicht nachträglich auf die bereits bestehende Event-Historie anwenden.

Listing 4: Spring Data JPA Projektor
Axon im produktiven Einsatz
Axon deckt mit den hier vorgestellten Elementen vollständig die für CQRS/ES erforderlichen Aspekte einer Anwendung ab. Besonders hervorzuheben sind dabei die sehr gute Integration in den Spring-Kontext und der Fokus auf einfache Testbarkeit durch AggregateTestFixture oder auch SagaTestFixture für die hier nicht weiter ausgeführten SAGA-Implementierungen [Rich-b].
Für den produktiven Einsatz gilt es – wie bei jedem Framework – auch bei Axon einige Dinge zu beachten. Hervorzuheben ist hier in erster Linie, dass man im Sinne einer garantierten Event-Verarbeitung in der Regel auf einen automatischen Retry fehlerhafter Event-Handler setzen wird. Axon unterstützt dies, bietet an dieser Stelle jedoch keinerlei Aussteuerungsmöglichkeiten für wiederholt fehlerhafte Event-Handler an (vergleichbar zum Dead-Letter-Queueing). Programmierfehler in Event-Handlern führen somit unweigerlich zu Endlos-Retry-Schleifen, bis der Event-Handler entsprechend angepasst wurde.
Ein weiterer wichtiger Aspekt betrifft das Persistenzformat von Events. Da Events als unveränderlich gelten, sollte hier unbedingt ein ausreichend flexibles Serialisierungsformat gewählt werden. JSON bietet sich hier vor allem wegen seiner schwachen Typisierung an, da Events deutlich langlebiger als zum Beispiel Klassennamen sind. Zudem sollte man sich vor Produktivnahme unbedingt mit dem Event-Upcasting solcher Events beschäftigen. Strukturelle Änderungen an Events sind auch im CQRS/ES-Umfeld unvermeidlich. Historische Events müssen daher durch entsprechende Upcaster in das neue Format überführt werden können. Zu guter Letzt sei darauf hingewiesen, dass die Parallelisierung der Eventverarbeitung innerhalb eines Tracking-Event-Prozessors aktuell noch kein Auto-Scaling unterstützt. Das bedeutet, dass man sich bei der Definition der jeweiligen Processing-Groups darüber im Klaren sein sollte, welcher Parallelisierungsgrad bei der Eventverarbeitung notwendig ist und wie dieser durch ein geeignetes Deployment auch beim Down-Scaling von JVMs sichergestellt werden kann.
Vorteile von hexagonalen Architekturen
CQRS und Event Sourcing fördern auf natürliche Weise hexagonale Anwendungsarchitekturen [Wiki-c], auch bekannt als „Ports und Adapters”. Dabei bildet die Domänenlogik den Kern der Anwendung, welche über Commands und Events (ihren Ports) mit den umgebenden Komponenten (den Adaptern) kommuniziert. Letztere adaptieren diese an die jeweiligen technologischen Anforderungen. Ports nehmen entweder Änderungsanforderungen (Commands) für die Domäne entgegen oder kommunizieren erfolgreich vollzogene Änderungen (Events) an die umgebenden Adapter. So erzeugt ein REST-Controller zum Beispiel Commands aus eingehenden HTTP-Requests, während ein Datenbank-Projektor Events in relationale Tabellen projiziert. Ein Adapter kann sich dabei auch auf mehrere Ports beziehen, zum Beispiel für eingehende Nachrichten (Commands) und ausgehende Nachrichten (Events).
Abbildung 2 zeigt beispielhaft eine hexagonale Anwendungsarchitektur auf Basis von CQRS und Event Sourcing. Dabei handelt es sich um eine Webanwendung welche Commands per HTTP/REST überträgt und das resultierende Read-Modell vollständig über eine dokumentenbasierte Datenbank (Google Firestore) konsumiert. Weitere Ports und Adapter veranschaulichen die Kommunikation mit verschiedenen Umsystemen und Technologien.
Die Vorteile einer solchen Architektur liegen klar auf der Hand. Zum einen bleibt die Fachlogik weitgehend befreit von technologischen Abhängigkeiten und somit fokussiert auf die Domäne selbst. Durch die zusätzliche Trennung von Commands und Events lässt sich die Fachlogik dadurch hervorragend Unit-testen. Zum anderen sind die Adapter flexibler austausch- und anpassbar vor dem Hintergrund sich ändernder Anforderungen. Insbesondere eventbasierte Adapter lassen sich zudem auch nachträglich hinzufügen und so anhand der bestehenden Event-Historie neue Projektionen erstellen.
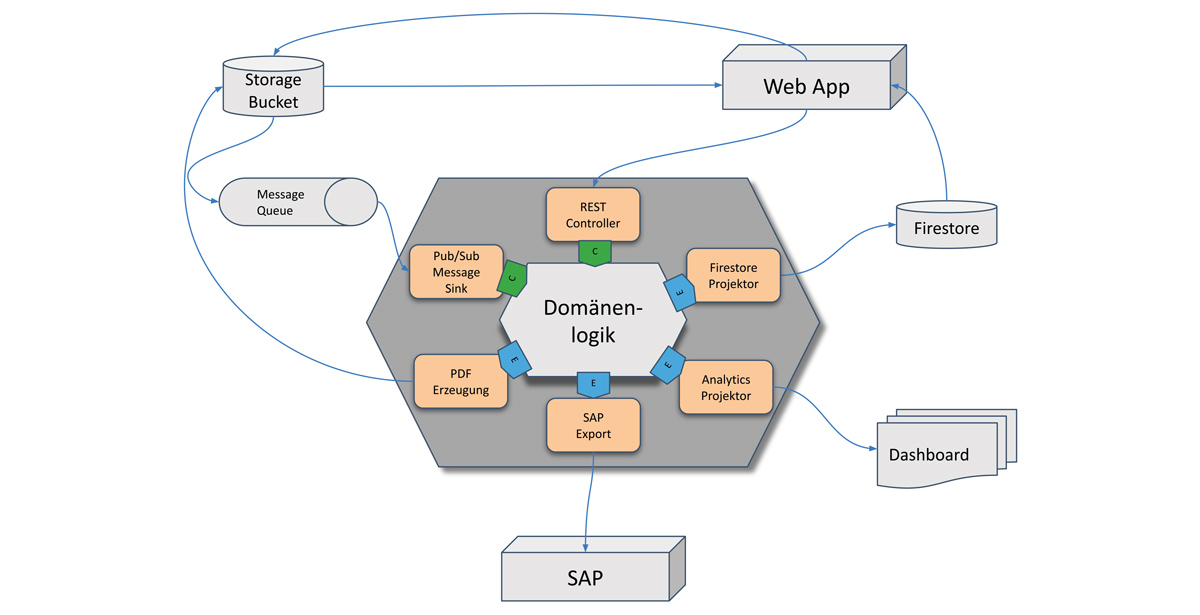
Abb. 2: Beispiel einer hexagonalen Architektur auf Basis von CQRS/ES
Fazit
CQRS und Event Sourcing mag aus Entwicklerperspektive – im Vergleich zu klassischen Schichtenarchitekturen – anfangs ungewohnt sein. Die eventbasierte Persistenz von Änderungen erfordert ein gewisses Umdenken. Die strikten Regeln im Zusammenspiel zwischen Commands und Events wirken am Anfang oft unnötig einschränkend. Doch genau hieraus ergeben sich die großen Vorteile dieser Architektur: die klare Trennung von Fachlogik und Technologie, die Auditierbarkeit und Erweiterbarkeit sowie die hervorragende Testbarkeit. All diese Aspekte werden vom Open-Source-Framework Axon gefördert und unterstützt. Einem produktiven Einsatz von CQRS/ES im JVM-Umfeld steht somit nichts mehr im Wege.
Weitere Informationen
[Rich-a] Ch. Richardson, Pattern: Transactional outbox, siehe: https://microservices.io/patterns/data/transactional-outbox.html
[Rich-b] Ch. Richardson, Pattern: Saga, siehe: https://microservices.io/patterns/data/saga.html
[Wiki-a] https://de.wikipedia.org/wiki/Command-Query-Responsibility-Segregation
[Wiki-b] https://de.wikipedia.org/wiki/Event_Sourcing
[Wiki-c] https://en.wikipedia.org/wiki/Hexagonal_architecture_(software)









