

Die Qualität von Programmcode spielt in der Softwareentwicklung eine elementare Rolle: Wartung und Weiterentwicklung sind oft mit einem hohen Aufwand verbunden. Während der Programmierung werden durchschnittlich 58 Prozent der Zeit für das Verstehen des Programmcodes aufgewendet [1]; insbesondere im Rahmen der Wartung. Der Aufwand steigt dabei mit sinkender Codequalität. Das Refactoring, also das Überarbeiten von bestehendem, älteren Programmcode, um die Codequalität zu steigern, ist so ein wichtiger Bestandteil in der Softwareentwicklung. Hohe Codequalität und im Allgemeinen einfache Wartbarkeit eines Programmcodes besitzen somit das Potenzial, Zeit und Kosten der Softwareentwicklung zu reduzieren.
Eine Unterstützung oder Automatisierung durch ChatGPT bei der Erhöhung der Codequalität kann in zwei Hinsichten Aufwände in der Entwicklung reduzieren: Zum einen bietet eine mögliche Unterstützung während des Refactorings eine Zeitersparnis, zum anderen wirkt sich eine verbesserte Codequalität positiv auf zukünftige Arbeiten an der Codebasis aus. Entscheidend ist dabei, ob der Code durch den Einsatz von ChatGPT tatsächlich besser wird. Dabei kommt es nicht nur auf die Codequalität an. Ebenso wichtig ist, dass der Programmcode syntaktisch korrekt ist – und vor allem fachlich identische Ergebnisse liefert wie der ursprüngliche Code.
Anwendung von ChatGPT in Praxisbeispielen
Es existieren diverse Publikationen, die aufzeigen, dass ChatGPT Code generieren und beim Bugfixing helfen kann. Oftmals handelt es sich dabei um kleinere, in sich geschlossene Codeausschnitte und geläufige Algorithmen. Wie aber schlägt sich ChatGPT in realen Projekten mit komplexeren Codestrukturen und externen Abhängigkeiten?
Um die Auswirkungen auf die Codequalität systematisch zu untersuchen, wurde eine Versuchsreihe mit Codeausschnitten aus Open-Source-Projekten von GitHub durchgeführt. Betrachtet wurden vier verschiedene Java-Projekte ([2, 3, 4, 5]). Zu jedem Ausschnitt wurde ChatGPT die Aufgabe gestellt, den mitgegebenen Code zu verbessern. Im Anschluss wurden die Ergebnisse ausgewertet und die Auswirkungen auf die Qualität untersucht. Abbildung 1 zeigt den Versuchsaufbau.
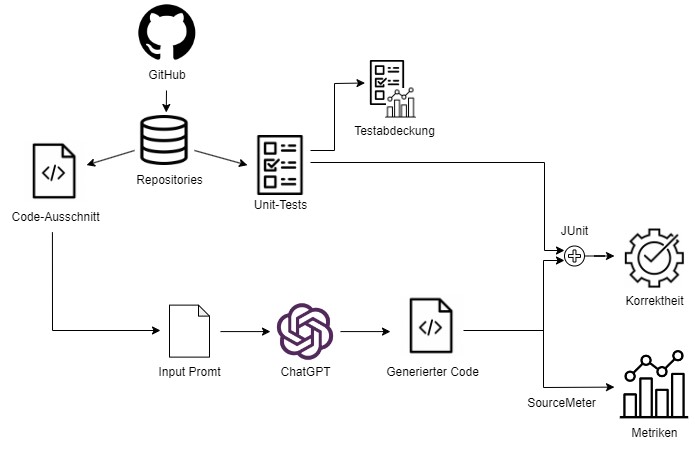
Abb. 1: Vorgehen der Versuchsreihe
Als Prompt, also als Fragestellung, wurde eine sehr direkte Herangehensweise gewählt, die in Listing 1 zu sehen ist: Die zu verbessernden Codezeilen werden in die Eingabe kopiert zusammen mit einer kurzen Anweisung, was das gewünschte Ergebnis ist.
1 Frage (1):
2 Improve the following code.
3
4 private DeployState calculateApplicationDeployState() {
5 int numPending = 0, numStarting = 0,
numStarted = 0, numStopping = 0;
6 [...]
7 }
8 Antwort ChatGPT (1):
9 [...]Insgesamt wurden aus jedem Projekt jeweils vier Ausschnitte ausgewählt, die in je vier separaten Chats mit identischen Prompts an ChatGPT übergeben wurden. Aus jedem Projekt ergaben sich somit 16 Eingaben und Ausgaben, also insgesamt 64.
Verbesserungsvorschläge von ChatGPT
Die Versuche bieten bereits vielversprechende Ergebnisse. Allgemein wirken die Anpassungen sinnvoll und nachvollziehbar. Die Vorschläge von ChatGPT sind dabei vielseitig und folgen bekannten Best Practices und Konventionen. Meistens handelt es sich um strukturelle Änderungen, die die Lesbarkeit steigern und Codesmells eliminieren, indem zusammenhängende Codeblöcke ausgelagert, zusammengefasst oder restrukturiert werden.
Ein häufig zu beobachtendes Verhalten ist zum Beispiel, dass ChatGPT mehrere kleinere Methoden einer einzelnen großen Methode vorzieht. Eine große, komplexe Methode wird dabei sinnvoll in einzelne Methoden aufgeteilt. Eine andere Maßnahme besteht darin, wiederkehrenden Code zu einer Methode zusammenzufassen, um Duplikate zu vermeiden. ChatGPT berücksichtigt dabei ebenfalls Kommentare im Quellcode und ist sogar in der Lage, Kommentare selbstständig einzufügen. Ebenso achtet ChatGPT auf sprechende Variablen- und Methodennamen. Aus Subscriber s = new Subscriber(); wird beispielsweise Subscriber subscriber = new Subscriber();. Weitere Vorschläge umfassen unter anderem das Ersetzen von langen If-Else-Fallunterscheidungen durch Switch-Case-Anweisungen oder Lookup-Tables. Ein vereinfachtes Beispiel dafür zeigen Listing 2 und Listing 3.
public int compute(int a) {
if(a == 1) {
return 123;
} else if(a == 2) {
return 321;
} else if(a == 3) {
return 213;
} else if(a == 4) {
return 0;
} else {
return -1;
}
}private static final HashMap<Integer, Integer> map =
new HashMap<>();
static {
map.put(1, 123);
map.put(2, 321);
map.put(3, 213);
map.put(4, 0);
}
public static int compute(int a) {
return map.getOrDefault(a, -1);
}Veränderung der Codequalität
Um fundierte Aussagen treffen zu können, ob sich der Code durch ChatGPT letzten Endes verbessert oder verschlechtert hat, reicht es nicht aus, sich einfach auf das Bauchgefühl zu verlassen. Es müssen Messwerte her. Zur Messung der Codequalität einer Software existieren diverse Metriken ([6, 7]). Ein Blick auf die Messwerte ermöglicht es, die Verbesserung oder Verschlechterung der Codeausschnitte hinsichtlich verschiedener Qualitätsaspekte zu quantifizieren. Zu beachten ist, dass die Metriken nur Teilaspekte des Codes betrachten können und einen vereinfachten Überblick über die Qualität des Codes geben. Metriken geben also nur einen groben Anhaltspunkt zur Bewertung der Codequalität und sind kein Maß zur eindeutigen Qualitätsbewertung.
Tabelle 1 zeigt geläufige Metriken, die im Rahmen der Versuchsreihe angewendet wurden.
| Kategorie | Metrik | Abk. |
|---|---|---|
| Programmlänge | Logical Lines of Code | LLOC |
| Komplexität | McCabe’s Cyclomatic Complexity | McCC |
| Halstead Number of Delivered Bugs | HNDB | |
| Halstead Time Required to Program | HTRP | |
| Halstead Volume | HVOL | |
| Nesting Level | NL | |
| Nesting Level Else-If | NLE | |
| Wartbarkeit |
Maintainability Index (Original Version) |
MI |
|
Maintainability Index (Microsoft-Version) |
MIMS |
Die Metriken lassen sich in drei Kategorien aufteilen:
- 1. Kategorie – Programmlänge: Die Größe des Programmcodes anhand der Anzahl an Zeilen ohne Leerzeilen und Kommentare (LLOC).
- 2. Kategorie – Komplexität: Die Komplexität, insbesondere:
- Komplexität des Kontrollflusses (McCC),
- Komplexität basierend auf der Anzahl von Operanden und Operatoren (Halstead-Metriken),
- Grad der Verschachtelung (NL, NLE).
- 3. Kategorie – Wartbarkeit: Die allgemeine Wartbarkeit des Codes, die auf den beiden zuvor genannten Metrik-Kategorien aufbaut (MI, MIMS) [8].
Abbildung 2 zeigt zu den einzelnen Codeausschnitten die jeweiligen durchschnittlichen Wertänderungen der Metriken nach Bearbeitung durch ChatGPT.
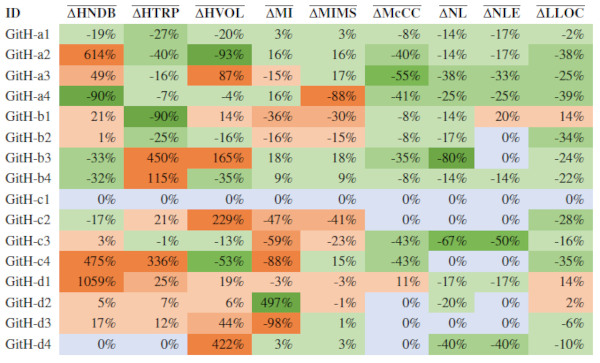
Abb. 2: Gemessene Qualitätsänderungen auf Basis der Metriken
Grüne Felder zeigen dabei eine Verbesserung im Sinne der Metrik, rote Felder eine Verschlechterung. Es wird deutlich, dass die Messwerte überwiegend auf Verbesserungen der Codequalität hinweisen. Zu beachten ist dabei, dass in diese Auswertung nur Ausgaben einbezogen wurden, die kompilierbar waren und fachlich korrekte Ergebnisse liefern. Es konnten somit nur 29 Ausgaben hinsichtlich der Qualität untersucht werden. Für syntaktisch oder fachlich falsche Ausgaben, die nicht durch triviale Anpassungen zu korrigieren sind, wurde keine Qualitätsmessung durchgeführt, da diese das Gesamtergebnis verfälschen würden.
Korrektheit der generierten Ausschnitte
Dies führt zum letzten wichtigen Aspekt: Code mit hoher Codequalität nützt nichts, wenn er fachlich falsche Ergebnisse liefert. Bei der Verbesserung von Programmcode stellt sich also immer die Frage, ob der generierte Code tatsächlich noch die gewollten Ergebnisse liefert. Nicht immer verhält sich das Programm nach der Überarbeitung durch ChatGPT noch fachlich korrekt – und wenn der Code nicht funktioniert, ist es egal, wie gut und performant er nicht funktioniert. Der Teufel steckt dabei wie so oft im Detail und die Fehler werden unter Umständen erst auf den zweiten oder dritten Blick ersichtlich. In diesem Kontext sind Unittests und eine ausreichend hohe Testabdeckung empfehlenswert. Von der Fachlichkeit abgesehen, schleichen sich gerade bei etwas umfangreicherem Code nicht selten auch technische Fehler ein.
Abbildung 3 zeigt die Ergebnisse der Versuchsreihe.
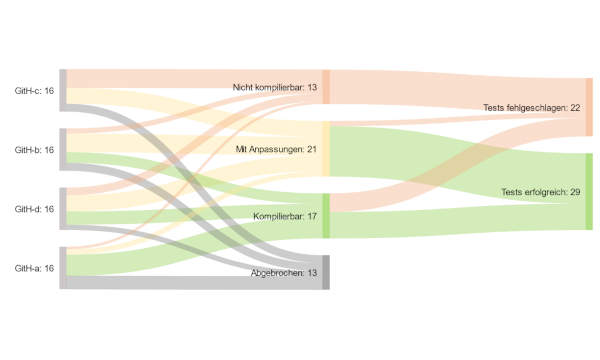
Abb. 3: Korrektheit des generierten Codes
Von den insgesamt 64 generierten Ausschnitten liefen 29 mit teilweise geringfügigen, manuellen Anpassungen erfolgreich durch die Tests.
Die Ergebnisse zeigen, dass weniger als die Hälfte der generierten Ausschnitte ohne manuelle Anpassungen technisch und fachlich korrekt sind. Einfache Codeausschnitte ohne starke Abhängigkeiten zeigen zu 45 Prozent eine fachliche Korrektheit, komplexere Ausschnitte gerade einmal zu 16 Prozent. Vor allem auf den zweiten Blick fallen Unstimmigkeiten gegenüber den originalen Ausschnitten auf.
Ausblick
Die Versuche wurden mit einem recht einfachen Prompt durchgeführt. Bei Ausschnitten aus größeren, komplexeren Softwaresystemen sollte mehr Augenmerk auf die Formulierung der Fragestellung – das Prompt Engineering – gelegt werden [9].
Einen hilfreichen Ansatz im Umgang mit ChatGPT stellen dabei sogenannte Prompt Patterns dar. Ein hilfreiches Muster ist das Flipped Interaction Pattern, bei welchem dem Large Language Model (LLM) die Aufgabe gegeben wird, selbstständig Informationen zu erfragen, die es zur Bearbeitung einer bestimmten Aufgabe benötigt [10]. Dieses Pattern kann dazu eingesetzt werden, ChatGPT nach und nach den benötigten Kontext zu einem zu verbessernden Codeausschnitt zur Verfügung zu stellen. Ein wesentlicher Vorteil dieser Vorgehensweise besteht darin, dass somit auch relevante Ausschnitte aus anderen Klassen und Methoden zum Verständnis des Programmcodes gegeben werden können, ohne das Zeilenlimit der Eingabe zu überschreiten. Ein mögliches Anwendungsbeispiel zeigt Listing 4.
1 Frage (1):
2 I want to improve the code quality of the following Java method.
3 From now on, I would like you to ask me questions about the code.
4 When you have enough information to improve the code, give me the
5 complete implementation of the method.
6
7 public PredictionDataTo getNextWeekPrediction(
PredictionSearchCriteriaTo criteria) {
8 [...]
9 }
10 Antwort ChatGPT (1):
11 [...]
12 What is the purpose of the getNextWeekPrediction method?
13 What does the PredictionSearchCriteriaTo class represent,
14 and what information does it contain?
15 What is the purpose of the LOG.debug statement?
16 What does the deletePredictionForecastData method do?
17 [...]Durch dieses Vorgehen kann das Problem des fehlenden Kontexts reduziert werden; ChatGPT muss somit weniger Annahmen über den Code treffen und liefert stabilere Ergebnisse. Diese Vorteile müssen aber gegen den steigenden Aufwand für den Einsatz von ChatGPT abgewogen werden.
Fazit
Auch wenn die generierten Ausschnitte nicht ohne einen prüfenden Blick übernommen werden sollten, so liefert ChatGPT in sehr vielen Fällen zumindest gute Lösungsansätze und die meisten Fehler sind oft kontextabhängig und mit verhältnismäßig geringem Aufwand zu beheben. Es ist daher empfehlenswert, die vorgenommenen Anpassungen genau zu prüfen und durch Maßnahmen der Qualitätssicherung die unveränderte Funktionsweise des Codes zu verifizieren.
Richtig eingesetzt, kann ChatGPT somit in der Softwareentwicklung als effektives Werkzeug unterstützend eingesetzt werden, um die Codequalität von Programmcode zu verbessern und die Wartbarkeit einer Software zu erhöhen. Die Validierung und Anpassung an den jeweiligen Kontext erfordert jedoch Expertise und manuelle Eingriffe. Durch den Einsatz von LLM wie ChatGPT kann die Codequalität also nicht automatisch erhöht werden. Entwicklerinnen und Entwickler haben aber ein neues und durchaus mächtiges Werkzeug, mit dessen Hilfe sie effizient eine substanzielle Erhöhung der Codequalität erreichen können.
Weitere Informationen
[1] X. Xia et al., Measuring program comprehension: A largescale field study with professionals, in: IEEE Transactions on Software Engineering, 44(10), 951–976, 2017
[2] CobiGen, https://github.com/devonfw/cobigen
[3] Apache Dubbo, https://github.com/apache/dubbo
[4] My Thai Star, https://github.com/devonfw/my-thai-star
[5] RxJava, https://github.com/ReactiveX/RxJava
[6] S. Pargaonkar, Quality and Metrics in Software Quality Engineering, in: Journal of Science & Technology, 2.1, 62–69, 2021
[7] M. C. Lee, Software quality factors and software quality metrics to enhance software quality assurance, in: British Journal of Applied Science & Technology, 4.21, 3069–3095, 2014
[8] M. Jones et al., Code metrics – Maintainability index range and meaning,
https://learn.microsoft.com/en-us/visualstudio/code-quality/code-metrics-maintainability-index-range-and-meaning?view=vs-2022&viewFallbackFrom=vs-2022%27
[9] J. Cao, M. Li, M. Wen, S.-C. Cheung, A study on Prompt Design, Advantages and Limitations of ChatGPT for Deep Learning Program Repair. arXiv preprint arXiv:2304.08191, 2023
[10] J. White et al., A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT, 2023, https://arxiv.org/abs/2302.11382









