

Die großen Technologiewellen der letzten 30 Jahre haben uns der Reihe nach Desktop-Betriebssysteme, Networking, Web-Browser, Mobile Apps, Soziale Netze, Cloud-Computing, das Internet der Dinge (Internet of Things, kurz IoT) und Künstliche Intelligenz (KI) beschert. Jede dieser Entwicklungen hat uns mit spezifischen Herausforderungen konfrontiert. So ging es beispielsweise beim Networking um Protokolle oder beim Cloud-Computing um Fragen der Migration und der Sicherheit von ausgelagerten Daten und Anwendungen.
Aktuell müssen wir uns mit einem Sprachenwirrwarr im Bereich IoT sowie mit der Erkennung von Propaganda und Falschnachrichten in Sozialen Netzen und an anderen Stellen im Internet auseinandersetzen. Alle Welt redet vom Fachkräftemangel speziell in datenintensiven Anwendungen, weshalb man sich um eine Automatisierung („Demokratisierung“) von Data Science bemüht. Auch die Erklärbarkeit von KI-Methoden, insbesondere im Bereich des Deep Learning, bei dem mehrstufige neuronale Netze zum Einsatz kommen, beschäftigt immer mehr Forscher sowie Anwender. Schließlich sind wir mit einer seit Jahren immer schneller verlaufenden
Entwicklung konfrontiert, die uns kaum Zeit lässt, die Möglichkeiten der aktuellen Technik vollständig auszuloten, bevor sie bereits wieder durch eine neue ersetzt wird.
Vor diesem Hintergrund stellen sich viele heute die Frage, ob man vor der Zukunft Angst haben muss oder ob wir rosigen Zeiten entgegengehen, da durch die zunehmende Technisierung unserer Welt vieles leichter, schneller und komfortabler wird. Dies soll im Folgenden an verschiedenen Bereichen durchleuchtet werden. In allen diesen Bereichen geht es um den zunehmenden Einsatz von KI und um die sich dadurch ergebenden Möglichkeiten; daher sei hier zunächst das praktisch allen KI-Anwendungen zugrunde liegende Paradigma erläutert (siehe Abbildung 1).
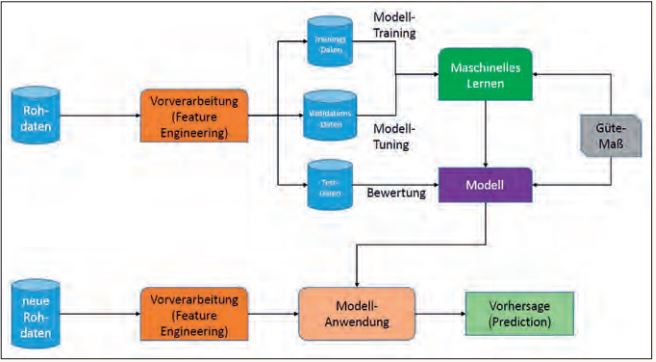
Abb. 1: Paradigma, das allen KI-Anwendungen zugrunde liegt
Zentral ist jeweils das Sammeln von (Roh-) Daten, was aktiv oder passiv erfolgen kann. Diese werden zunächst einer Vorverarbeitung (einem Preprocessing) unterzogen, bei der es einerseits um die Extraktion der für die betreffende Anwendung relevanten Anteile beziehungsweise Dateneigenschaften geht (man spricht von Feature Engineering), andererseits aber auch zum Beispiel um Qua-
litätsverbesserung („Data Cleansing“). Die Rohdaten werden anschließend zwei-, häufig sogar dreigeteilt: Ein Teil, die Trainingsdaten, dient zur Bildung eines initialen Modells, was sich anhand von Validationsdaten tunen lässt. Der dritte Teil umfasst die Testdaten; durch sie wird das zuvor erstellte Modell anhand von anwendungsrelevanten Gütemaßen bewertet.
Eine typische Aufteilung der initial vorliegenden Daten ist im Verhältnis 60:40 bei Zweiteilung oder 50:30:20 bei Dreiteilung. Ein getestetes Modell kann sodann auf neue, unbekannte Rohdaten angewendet werden, wobei diese Daten ebenfalls einen Preprocessing-Schritt durchlaufen; das Ergebnis ist zumeist eine Vorhersage oder Prediction.
In diesem Kontext kommt dem Schritt des Testens eine andere Bedeutung zu als beim
Testen von Software: Es geht hier zwar auch darum, dass die Implementierung eines Modells auf korrektes Funktionieren zu testen ist. Es geht aber primär darum, das jeweilige Modell, also etwa ein flaches oder tiefes neuronales Netz, darauf zu testen, ob es in der Lage ist, im Hinblick auf die betreffende Anwendung sinnvolle Erkenntnisse zu liefern. Was das konkret bedeuten kann, soll in den folgenden Abschnitten deutlich werden.
Informatik
Die Zukunft der Informatik ist insgesamt rosig, denn immer mehr Anwendungen des täglichen Lebens werden durch Algorithmen gesteuert, die Daten aufnehmen und zu nützlichen Aktivitäten oder verwertbaren Entscheidungen verarbeiten, und dank immer weiter verbesserter Rechentechnik, die seit Jahrzehnten dem Mooreschen Gesetz folgt, sind theoretische Grenzen von algorithmischer Machbarkeit immer weniger relevant. NP-vollständige Probleme wie das Problem des Handlungsreisenden (Traveling Salesman) lassen sich heute bis in hohe Dimensionen exakt lösen (s. z. B. der optimale UK-Pub Crawl mit fast 50.000 Kneipen [TSP]).
Allerdings zeigen uns der Hochgeschwindigkeitshandel an den Börsen und Erfahrungen mit Mobilitätsanbietern wie Uber, dass Algorithmen sich auch verselbstständigen können und dann zum Beispiel enorme Preissteigerungen hervorrufen, wenn etwa durch eine Katastrophe mehr Fahrzeuge als gewöhnlich benötigt werden [BBC]. Auf der anderen Seite gibt es erste Überlegungen zur Ersetzung von Preisen durch Daten, wie etwa bei Bla-BlaCar, wo neben dem Preis für eine Mitfahrt zum Beispiel Information über den Fahrer angeboten wird.
Auch und vor allem die KI zeigt eine deutlich beschleunigte Entwicklung, was sich an der Evolution der Systeme ablesen lässt, die gegen Menschen spielen: Hier fiel 2011 IBM Watson auf, als er Jeopardy gewann. 2016 gewann Google DeepMind im Spiel Go, was in China geradezu einen KI-Boom auslöste, und bereits 2017 gewann das System Libratus der Carnegie Mellon University ein Heads-Up No-Limit Texas Hold‘em Pokerspiel, was zu den schwierigsten Poker-Varianten gehört, gegen zwei Gegner und zwei Jahre später als Pluribus AI bereits gegen sechs [Hea19]. Inzwischen können Roboter Jenga spielen [Pod19] oder in ca. 35 Stunden sich selbst beibringen, wie sie aussehen und was sie können [Kow19].
Aber was genau passiert in einem neuronalen Netz? Was passiert in der „Black Box“ eines tiefen neuronalen Netzes? Dies sind die Fragen, die „erklärbare KI“ beantworten möchte. Zwei Ansätze in dieser Richtung seien hier genannt: Das japanische Unternehmen dotData [dD] sorgt dafür, dass seine Software stets Erklärungen generiert, warum bestimmte Features beim maschinellen Lernen benutzt wurden. Die weltweite Aktivität „School of AI“ [SofAI] oder auch „The Elements of AI“ [EofAI] möchte für jeden auf der Welt kostenlose KI-Kurse anbieten, sodass niemand mehr zurückbleibt; ob das funktioniert, bleibt abzuwarten.
Autofahren
Über kein Anwendungsgebiet für Daten, Data Analytics und KI wird derzeit so intensiv diskutiert wie über die Zukunft des Autofahrens. Fahrassistenzsysteme wie ABS oder
ESP gibt es schon lange, aber inzwischen strebt man an, dem Fahrer das Steuer aus der Hand zu nehmen und Autos autonom fahren zu lassen. Im Hinblick auf das eingangs beschriebene Vorgehen bei der Entwicklung einer KI-Anwendung lernt ein Auto dabei, auf alle möglichen Situationen im Verkehr angemessen zu reagieren; erst nach umfangreichen Tests wird das Auto als autonomes Fahrzeug auf die Straße gelassen.
Nebenbei bemerkt funktioniert dies offensichtlich nur, wenn alle fahrenden Verkehrsteilnehmer ständig miteinander kommunizieren, etwa bezüglich Abstand oder Geschwindigkeit. Ob eine 5G-Netzinfrastruktur für das hier zu erwartende Datenvolumen ausreichen wird, ist abzuwarten; dennoch werden sowohl von Automobilherstellern, Zulieferern wie auch von etlichen Start-ups Ideen und Geld en masse investiert, um diese Vision bereits in wenigen Jahren Wirklichkeit werden lassen. Nahezu täglich erreichen uns dazu neue Meldungen, allerdings bleibt hier eine Frage offen, die in der Literatur als das Trolley-Problem bekannt ist [Wiki-a]: Eine defekte Straßenbahn rollt auf eine Menschenmenge zu. Ein Weichensteller könnte die Bahn auf ein anderes Gleis umleiten, auf dem jedoch Kinder spielen. Wie soll er entscheiden? Aus der Sicht der Informatik kommen wir hier mit Rechenpower wie bei TSP nun doch nicht weiter, denn das Trolley-Problem ist unentscheidbar, das heißt, es kann keine algorithmische Lösung geben.
Eine andere Entwicklung auf diesem Gebiet ist eine Ersetzung des Konzepts „Autofahren“ durch Mobilität. Dabei steht also nicht der Besitz eines Fortbewegungsmittels im
Vordergrund, sondern lediglich die Möglichkeit eines Zugriffs darauf nach Bedarf, was der On-Demand-Society (siehe unten) entgegen kommt. Hier wird mit ganz unterschiedlichen Ansätzen experimentiert, darunter Abonnieren [cluno], Carsharing oder Transportieren lassen [Arr]; Versicherungen arbeiten bereits mit Hochdruck daran, jeweils passende Modelle zu entwickeln.
Sport und Medizin
Im Sport hat die Anwendung von Data Science eine Tradition spätestens seit Billie Beane, dem legendären Manager der Baseball-Mannschaft Oakland Athletics, der bereits Ende der 1990er mit Einführung der sogenannten Sabermetrics für einen Siegeszug der objektiven Spieleranalyse und -bewertung sorgte. Seitdem kommt praktisch keine Sportart mehr ohne derartige Bewertungssysteme aus; im Baseball sind Programme wie Statcast im Einsatz und auch die amerikanische Super Bowl oder die Formel 1 nutzen Datentechnik im großen Stil [Cla18, McD17]. Auch hier geht es darum, aus einer Fülle vorhandener Daten ein Modell zu entwickeln, mit welchem sich Spieleroder Rennwagen-Performance zuverlässig vorhersagen lässt.
Nützlich ist Big Data ebenfalls im Gesundheitswesen; jeder Einzelne kann seit Jahren seine persönlichen sportlichen Aktivitäten verfolgen, sich Ziele setzen, mit anderen vergleichen usw. Hier setzt die professionelle Auswertung gerade erst ein, etwa in Form von angepassten Versicherungstarifen, wichtiger allerdings in medizinischen Anwendungen, in denen man sich patientenzen trierte Behandlungen durch immer genauere Analyse von Historien, Predictive Analytics zur Verbesserung von Behandlungsergebnissen, Realzeit-Überwachung von Patienten, eine Reduktion von Nebenwirkungen, Fehlverhalten und Missbrauch und letztlich Kostensenkungen auf allen Ebenen verspricht. Im anfänglichen Einsatz ist die digitale Pille [NYT]; KI wird inzwischen verwendet zur Früherkennung von genetischen Krankheiten durch Analyse des Gesichts, und erste Anwendungen der CRISP-Technik, welche eine Veränderung von Gen-Abschnitten erlaubt, werden gerade kommerzialisiert.
Arbeit
Werden Jobs durch Roboter verschwinden? Wenn ja, welche wird es zuerst treffen, welche erst später? Wer wird überflüssig, wer nicht? Einerseits wird diese Diskussion beflügelt durch immer neue Roboterentwicklungen, die immer geschickter werden im Ausführen manueller (wie dem Zubereiten von Hamburgern [Cal] oder dem Einparken von Autos [Exp19]) und anderer Tätigkeiten; so sprach die New York Times im Februar 2019 von „The Rise of the Robot Reporter“.
Andererseits laufen viele Entwicklungen darauf hinaus, eine Zusammenarbeit von Men-
schen und Robotern zu erzielen, bei welchen letzteren bestimmte Aufgabenteile übertragen werden, erstere jedoch die Kontrolle behalten. Was wir in Zukunft am ehesten sehen werden, ist eine Zerlegung klassischer Tätigkeiten in kleinere Teilaufgaben, die dann durch Mensch und Maschine neu kombiniert werden und den Menschen dadurch keineswegs überflüssig machen. Man denke an einen Restaurantbesuch, der im Wesentlichen drei Phasen umfasst: bestellen, Essen serviert bekommen, bezahlen. Erste und dritte Phase können locker durch einen Roboter oder automatisiert erledigt werden, aber das Essen darf immer noch der Kellner servieren.
Gesellschaft
Ich erwähnte im Zusammenhang mit dem Autofahren bereits die Entwicklung hin zur On-Demand-Gesellschaft, die Dienste (z. B. zur Mobilität) und Anwendungen nutzen möchte, wenn sie gebraucht werden, sie darum aber nicht unbedingt besitzen muss. Angesichts der weltweiten Verstädterung mit den zunehmenden Verkehrsproblemen leuchtet dies in Bezug auf Autos unmittelbar ein. Es betrifft aber auch viele andere Lebensbereiche, denn dank Anbietern wie Amazon haben wir uns auch zu einer Convenience-Gesellschaft entwickelt, die es gewohnt ist, vieles vom Laptop aus erledigen zu können oder zum Beispiel bestellte Ware innerhalb von Stunden geliefert zu bekommen. Wir leben derzeit in einer „technologischen Übergangszeit“, in welcher die jüngeren Mitbürger quasi mit dem Smartphone in der Hand auf die Welt kommen, die älteren zum Teil nicht mehr in der Lage sind, mit der aktuellen Technik umzugehen, und die „mittleren“ den Umgang im Laufe der Zeit gelernt haben. Wie wird also unsere Zukunft?
Fazit
Um die im Titel gestellte Frage zu beantworten, stelle ich eine SWOT-Analyse [Wiki-b] an (Akronym für Strengths/Stärken und Weaknesses/Schwächen sowie Opportunities/ Chancen und Threats/Risiken). Ich beginne mit den Schwächen: Wir beobachten beim Menschen eine abnehmende Aufmerksamkeitsspanne, die inzwischen mit 8 s unter der des Goldfischs (9 s) liegt [Wyz]. Dies hat unmittelbaren Einfluss zum Beispiel auf Lernfähigkeit, die heute ja lebenslang gefordert wird.
Unsere Stärken sehe ich vor allem in der Tatsache, dass der menschliche Erfindungsreichtum ungebrochen ist. Auch die deutsche Start-up-Szene ist aktiver denn je, wie sich in den zahlreichen einschlägigen Wettbewerben hierzu deutlich zeigt (wenngleich Deutschland hier nicht das Investitionsvolumen der USA oder das Chinas erreicht).
Unsere Risiken bestehen unter anderem darin, dass Orwells 1984-Vision bereits Wirklichkeit ist und mit dem in China betriebenen Sozialkredit-System sogar weitergedacht wird. Technik überfordert viele Menschen, da die Entwicklung immer schneller verläuft, und einige wenige Konzerne besitzen sämtliche Daten. Es sei nicht unerwähnt, dass hier neben der öffentlichen Diskussion auch konkrete Abhilfe in Sicht ist [Bri].
Auf der Seite der Chancen sehe ich eine Vereinfachung vieler Abläufe durch Digitalisierung (z. B. in den Bereichen C2G oder B2B), eine bessere Anpassung von Dingen und Prozessen an die einzelne Person, eine Schonung von Ressourcen (die hoffentlich endlich das papierlose Büro Realität werden lässt), und wie bereits erwähnt, sind Roboter allein nicht die Lösung am Arbeitsmarkt.
Wenn wir nun zurückdenken an die Zeit des Eisenbahnbaus im 19. Jahrhundert, als Kutscher und Stallburschen um ihren Job bangten und man befürchtete, dass Qualm Fahrgäste und grasendes Vieh vergiften würde, an die Einführung der Autos zu Beginn des 20. Jahrhunderts, als man ähnliche Bedenken hegte, oder an die Einführung des Handys, als man Angst vor krebserregender Funkstrahlung hatte, so stellt man fest: Das erleben wir gerade erneut; darum sollten wir einen klaren Kopf behalten, denn die Zukunft wird rosig.









