

Immer mehr Unternehmen rücken von einer Datensammlung an zentraler Stelle ab und setzen stattdessen auf eine verteilte Data-Mesh-Architektur. Anders als bei einem zentralisierten Data Lake zielt dieser Ansatz darauf ab, Datenverantwortung auf verschiedene Teams zu verteilen. Hier handelt es sich also primär um einen organisatorischen Wandel und weniger um einen technologischen. Es geht darum, Data-Analytics-Herausforderungen mit Domain-Driven Design zu begegnen – sprich: Die Datenverantwortlichkeit liegt hauptsächlich in den Teams, die die Daten selbst erzeugen und sie damit am besten kennen.
Das ist aus zahlreichen Gründen eine sinnvolle Entwicklung, doch auch ein Data Mesh kann an seine Grenzen stoßen. So ist eine solche Architektur etwa darauf ausgelegt, innerhalb eines Unternehmens zu fungieren. Für eine Firmengruppe mit unterschiedlichen Unternehmen ergeben sich allerdings andere Herausforderungen, ebenso für unterschiedliche Akteure, die Daten miteinander teilen müssen – insbesondere sensible.
Um diese zu lösen, hat Thoughtworks nun mit Anonymesh [2] einen neuen Ansatz als Proof of Concept entwickelt. Anonymesh ist eine Kombination aus den Begriffen „Anonym(ous)“ und „Data Mesh“ – sie signalisiert also bereits den Kontext der Architektur. Anonymesh ist ein Architekturkonzept, das den sicheren und privaten Datenaustausch zwischen Organisationen ermöglicht. Hierbei ist es möglich, aus den Eingaben verschiedener Organisationen Ergebnisse zu ermitteln, ohne dabei Informationen an das jeweilige Gegenüber zu übertragen.
Ähnlich wie Data Mesh ist Anonymesh eine Methode, um Daten dezentralisiert zu nutzen und sie möglichst nah an deren Ursprung vorzuhalten. Es verwendet Domain-Driven Design, um Aspekte wie Vertrauensgrenzen, kosteneffizientes Datenmanagement und Datenschutz anzugehen. Beide Ansätze ermöglichen Teams, domänenübergreifende Datenanalysen durchzuführen. Bei Anonymesh funktioniert das jedoch auch organisationsübergreifend sowie für hochvertrauliche Daten innerhalb eines Unternehmens. Es stellt sichere Verbindungen zwischen unterschiedlichen Datensätzen her und hält dabei sämtliche Datenschutzrichtlinien ein.
Wofür braucht es einen neuen Ansatz?
Für zahlreiche wichtige Projekte weltweit müssen unterschiedliche Organisationen hochsensible Daten gemeinsam nutzen, etwa in der Forschung, im Gesundheitswesen oder in der öffentlichen Verwaltung. Berechtigte Bedenken bezüglich des Datenschutzes und der Datensicherheit haben hier jedoch in der Vergangenheit wertvolle Anwendungsfälle immer wieder blockiert. Strengere Regulierungen machen es zudem zunehmend schwierig für Mitarbeitende, einzuordnen, welche Daten sie teilen dürfen und in welcher Form.
Darüber hinaus nimmt der Druck durch die Aufsichtsbehörden immer mehr zu. Sie kontrollieren häufiger und gründlicher, ob Unternehmen ihre Daten vorschriftsgemäß speichern und weitergeben, sodass Fehler kostspielig werden können. Für Organisationen ist es also wichtig, Daten möglichst effizient, sicher und im Einklang mit Datenschutzregeln zu nutzen und zu teilen, um Geldstrafen zu verhindern und so den eigenen Profit zu schützen.
Wie ist Anonymesh aufgebaut?
Aus technischer Sicht handelt es sich um einen Ansatz der Datensparsamkeit. Es sollen also nur Daten und Informationen geteilt werden, die unbedingt nötig sind, um den Anwendungszweck zu erfüllen. Zudem teilt Anonymesh – wie der Name schon verrät – die Inhalte in anonymisierter, verschlüsselter Form, sodass niemand die jeweils von der anderen Seite beigesteuerten Inhalte direkt einsehen kann.
Der Kern der Architektur liegt dabei in einer sicheren Kommunikation zwischen hochvertraulichen und weniger sensiblen Systemen. Eine mögliche Lösung dafür ist ein privates Schnittmengenprotokoll (Private Set Intersection). Dieses Verschlüsselungsprotokoll ermöglicht es, Übereinstimmungen zwischen zwei Datensätzen aufzudecken, ohne dabei alle Daten offenzulegen – manchmal auch privater Join genannt. Dieser bietet zwei Datenhaltern die Möglichkeit, ihre Datensätze zu vergleichen, indem sie nur verschlüsselte Versionen ihrer Daten teilen und dennoch Überlappungen zwischen diesen Datensätzen finden, die sie für spätere Analysen verwenden können. Wichtig dabei: Die einzigen Daten, die sichere Systeme verlassen, sind verschlüsselt. Dieses architektonische Muster ist ideal für den Datenaustausch zwischen zwei oder mehr Datenquellen, bei denen hohe Datenschutzanforderungen bestehen.
Die Funktionsweise der Verschlüsselung veranschaulicht eine Analogie: Man möchte das Durchschnittsgehalt von Personen ermitteln, ohne deren einzelne Beiträge offenzulegen. Also erzeugt man eine große Zahl als geheime Basis und bittet dann jede Person, ihr Gehalt zu dieser Zahl zu addieren und sie an die nächste Person weiterzugeben. Am Ende zieht man die Ausgangszahl von der Summe ab und teilt das Ergebnis durch die Anzahl der beitragenden Personen. So erhält man ein Durchschnittsgehalt, ohne selbst Einblicke in die Einzelwerte zu erlangen – und ohne, dass die beitragenden Personen etwas über die Gehälter der anderen erfahren. Wieder auf Anonymesh übertragen bedeutet das: Zu jedem Zeitpunkt sind sämtliche Informationen verschlüsselt, und das finale Ergebnis lässt keine Rückschlüsse auf die einzelnen Beiträge zu. Abbildung 1 zeigt die Hauptkomponenten der Architektur von Anonymesh.
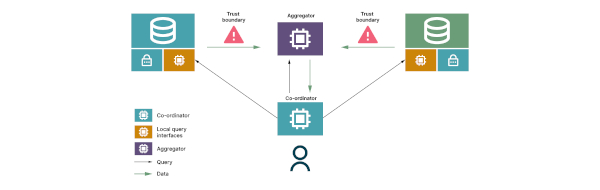
Abb. 1: Aufbau einer Anonymesh-Architektur
Lokale Abfrage-Interfaces (LQI)
Jeder Datenproduzent, der Teil des Netzes ist, kann eine eigene individuelle Architektur haben. LQIs erleichtern die Interaktion zwischen diesen Architekturen und ermöglichen es, Anfragen zu empfangen und zu interpretieren. Sie ermöglichen zudem Verschlüsselung und Datenminimierung, um den Datenschutz weiter zu stärken. Dafür führen sie einen detaillierten Abfragetyp aus, um eine einzelne, präzise Antwort zu liefern.
Koordinator
Ein Datenökosystem muss eine Vielzahl von Benutzerinnen und Benutzern mit unterschiedlichen Anfragen verwalten. Der Koordinator verwaltet Anfragen innerhalb der Architektur und dient als Router innerhalb des Netzes. Für jede erhaltene Benutzeranfrage kann der Koordinator LQI-spezifische Anfragen generieren. Dabei erhält jedes Interface nur die Daten, die es unbedingt benötigt, um seinen Teil der Anfrage zu erfüllen, was die Datensicherheit weiter erhöht.
Aggregator und Vertrauensgrenzen
Schließlich haben wir einen zentralen Ort, an dem die Berechnung stattfindet. Dies existiert einerseits, weil die Anwendungsfälle erfordern, Daten aus verschiedenen Quellen zu kombinieren, um eine Abfrage zu beantworten. Andererseits sollen die Benutzerinnen und Benutzer aufgrund der sensiblen Informationen keinen Zugriff auf die Daten haben, bis die Abfrage ausgeführt wurde. Daher sind der Aggregator und der Koordinator separate Komponenten: Der Aggregator ist die Umgebung, in der die Ver- und Entschlüsselung sowie die Kalkulationen durchgeführt werden, während der Koordinator als eine Art Steuereinheit dient, um die Anfragen an die passenden LQIs weiterzuleiten.
Ein weiteres Konzept ist noch zu berücksichtigen, obgleich es nicht als eigene Komponente gilt: Vertrauensgrenzen. Für jeden Anwendungsfall in dieser Architektur müssen Unternehmen gewährleisten, dass Daten auch dann sicher sind, wenn sie eine Vertrauensgrenze überschreiten.
Welchen Praxisnutzen hat die Architektur?
Gesetzliche Vorschriften über eine gemeinsame Datennutzung sollen Rechtssicherheit für alle Beteiligten schaffen. Doch leider sind sie häufig so komplex, dass sie für eine große Unsicherheit sorgen – erinnert sei etwa an die zahlreichen Missverständnisse rund um die DSGVO.
Die Prozesse, zum Beispiel in Behörden, beruhen zudem häufig auf E-Mail-Verkehr. Das erschwert die Aufrechterhaltung der Rechenschaftspflicht und bürdet oft weniger erfahrenen Mitarbeitenden die Pflicht auf, anhand dieser komplexen Vereinbarungen zu entscheiden, ob sie bestimmte Daten offenlegen können oder nicht. Im gesamten öffentlichen Sektor besteht die größte Herausforderung zumeist darin, einen rechtssicheren Weg zu finden, um bei der gemeinsamen Nutzung sensibler Informationen mit einer einmaligen Interpretation komplexer rechtlicher Vereinbarungen auszukommen.
Ein Beispiel: Wenn die Kommunikation mit dem Partnerunternehmen oder einer Behörde anstatt per Mail über ein Portal läuft, ist es möglich, dort standardisierte Informationen und Entscheidungsrichtlinien zu hinterlegen. Statt sich also auf die eigenen Interpretationen der Richtlinien verlassen zu müssen, erhalten die Mitarbeitenden klare, standardisierte Vorgaben zu jeder nötigen Begründung, die ihre Entscheidungsfindung erleichtert. In einem Dropdown-Menü können sie beispielsweise auswählen, weshalb sie Daten mit Dritten teilen wollen oder müssen – und in einer Infobox werden sie darüber informiert, was und in welcher Form sie das tun dürfen. Dies nimmt das Risiko von den Mitarbeitenden und bietet ihnen die notwendige Einordnung.
Grundsätzlich werden Informationen mit viel weniger überflüssigem Kontext gemeinsam genutzt, das Fachwissen verbleibt damit näher an den erzeugten Daten. Gegenüber Entscheidungsträgern beispielsweise können die Mitarbeitenden die Bedeutung dieser Daten auf hoher, für sie relevanter Ebene präsentieren. Gegebenenfalls nötige Änderungen können die Expertinnen und Experten dann selbst vornehmen. Das senkt auch die Herausforderungen bei der Umsetzung, da sich die unterschiedlichen Stakeholder nur noch um die für sie relevanten Probleme kümmern müssen.
Die Ausarbeitung rechtlicher Vereinbarungen liegt häufig in der Verantwortung von Führungskräften der internen Rechtsabteilungen. Oft reflektieren so abgestimmte Datenweitergabevereinbarungen allerdings nicht, wie die Daten in der Praxis tatsächlich gespeichert oder technisch weitergegeben werden können. Das kann die Mitarbeitenden an der Front in eine Zwickmühle bringen, denn es gibt durchaus Anreize oder sogar Vorgaben, Daten zu teilen.
Kinderschutz durch verbesserten Datenaustausch
In der Sozialfürsorge des Vereinigten Königreichs gibt es beispielsweise im Children Act von 2004 eine Anforderung für öffentliche Stellen, Informationen zum Zweck des Schutzes zu teilen, solange dabei das Gebot der Datenminimierung sowie die Beachtung relevanter Datenschutzgesetze Anwendung finden. Eine Kommission untersuchte 2022 im Auftrag des UK Childrens’ Commissioner, warum es trotz vorhandener Beweise und rechtlicher Vereinbarungen zur Datenweitergabe so viele Fälle von misshandelten Babys und Kindern gab. Sie stellte fest, dass „trotz Bemühungen, den Datenaustausch als Standard zu etablieren, viele immer noch zögerten, Informationen zu teilen, aus Angst, zu viele Details preiszugeben und rechtliche Konsequenzen befürchten zu müssen“. Diese Herausforderung ist bislang immer noch nicht gelöst.
Um den Anonymesh-Ansatz zu veranschaulichen, betrachten wir das oben genannte Problem (siehe Abbildung 2).
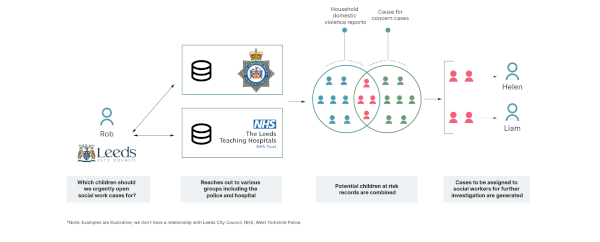
Abb. 2: Illustratives Beispiel für den Einsatz eines Anonymesh-Ansatzes
Eine Sozialarbeiterin möchte dringende Fälle identifizieren, in denen sowohl ein Arzt eine potenzielle Gefährdung festgestellt hat als auch das Zuhause mit Berichten über häusliche Gewalt in Verbindung gebracht wird. Sowohl die Polizei als auch die NHS-Gruppen (National Health Service im Vereinigten Königreich) besitzen relevante Daten. Da allerdings einerseits nur diejenigen Kinder als hochgefährdet gelten, die zu beiden Risikogruppen gehören, und andererseits gerade die medizinischen Informationen hochsensibel sind, sind die verantwortlichen Mitarbeitenden sehr zögerlich dabei, vollständige Listen zu teilen. Die große Herausforderung besteht also darin, die Liste der Kinder mit hohem Risiko teilen zu können, ohne dabei auch Informationen über Kinder mit deutlich niedrigerem Risikoprofil preiszugeben.
Wie kann man diese Daten in einer solchen Abfrage nun trennen? In diesem Fall legen wir besonderen Wert auf die Daten, die die Systeme der Datenproduzenten verlassen. Das ist der sensibelste Teil des Systems – dort, wo Daten den hochsicheren Bereich verlassen und in einen Bereich übergehen, der weniger vertrauenswürdig ist. Wie funktioniert das sicher und richtlinienkonform? Abbildung 3 zeigt, wie eine Anonymesh-Architektur im konkreten Fall aussehen könnte.
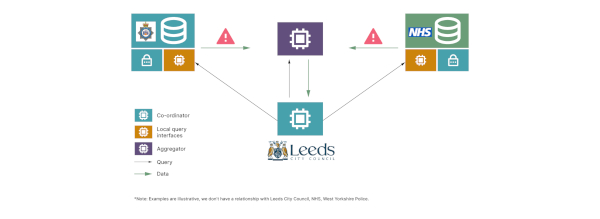
Abb. 3: Wie eine Anonymesh-Architektur im konkreten Fall aussehen könnte
Eine mögliche Lösung ist die Verwendung eines bereits erwähnten Private Joins. Besonders wichtig für diesen Anwendungsfall ist, dass die einzigen Daten, die die Systeme des NHS und der Polizei verlassen, verschlüsselt sind. Abbildung 4 zeigt ein mögliches Vorgehen: Obwohl die Daten verschlüsselt sind, könnte die Sozialarbeiterin mithilfe des privaten Joins die relevanten Fälle identifizieren, wodurch die am stärksten gefährdeten Kinder geschützt werden und gleichzeitig die Anonymität der anderen gewahrt wird.
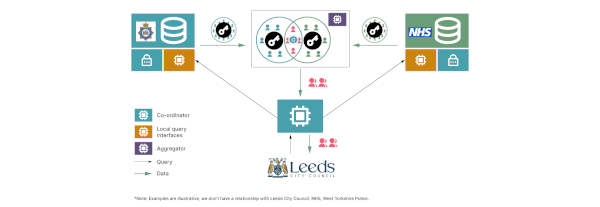
Abb. 4: Beispielhafter Vorgang in der anonymisierten Kommunikation mit Dritten
Skepsis überwinden
Deutschland hinkt bei der Einführung von Datentechnologien gegenüber anderen Ländern noch ein wenig hinterher. So hat der Bitkom in einer Studie 2023 [1] zwar aufgezeigt, dass sich hier etwas bewegt, doch noch immer erklären 64 Prozent der befragten Unternehmen, dass sie das Potenzial der ihnen zur Verfügung stehenden Daten überhaupt nicht oder eher weniger ausschöpfen. Einerseits legen die Entscheidungsträger den Fokus vor allem auf die Kosten und Herausforderungen solch einer Implementierung. Andererseits halten ein hoher Grad an Regulierung und eine geringe Risikobereitschaft sie davon ab, hier voranzuschreiten. Dabei könnte eine Anonymesh-Architektur ihnen helfen, unnötige Schritte aus dem Arbeitsprozess zu entfernen, Unsicherheiten für die Mitarbeitenden zu reduzieren und die Compliance zu verbessern.
Wie schnell man Menschen mit passenden Anwendungsfällen dazu motivieren kann, eine Technologie zu nutzen, hat Generative KI (GenAI) demonstriert. Der Hauptunterschied hier ist allerdings: Die Data-Mesh-Architektur als Grundlage für Anonymesh hat bewiesen, dass sie in einer Unternehmensumgebung funktioniert. Sie beseitigt zudem Sicherheitsprobleme, anstatt sie – wie bei GenAI – mitunter erst zu schaffen oder zu verschärfen.
Verantwortungsbewusst genutzte Technologie
Unternehmen in Deutschland und weltweit stehen einerseits vor der Herausforderung zunehmender Regulierung und vor immer höheren Datenschutzansprüchen sowie einer immer bedrohlicheren Cyber-Gefährdungslage andererseits. Umso wichtiger wird es, einen sicheren, datenschutz- und regulierungskonformen Austausch von Daten auch zwischen unterschiedlichen Organisationen zu gewährleisten. Eine Anonymesh-Architektur kann ihnen hier dabei helfen, die eigene Compliance zu maximieren und die Entscheidungsprozesse für alle Mitarbeitenden rechtssicher zu unterstützen. Das erhöht am Ende die Privatsphäre und Sicherheit sensibler Informationen für alle Beteiligten.
Literaturangaben
[1] A. Berg, Datenökonomie: Wo steht die deutsche Wirtschaft?, Bitkom, 2023, siehe: www.bitkom.org/Presse/Presseinformation/Datenoekonomie-Unternehmen-nutzen-Daten
[2] R. K. Jain, Anonymesh: Data Sharing Meets Privacy and Security, Thoughtworks, 2023, siehe: www.thoughtworks.com/insights/articles/anonymesh-data-sharing-meets-privacy-and-security









